


Cet article vous donnera une compréhension approfondie de la mémoire et du garbage collector (GC) du moteur NodeJS V8. J'espère qu'il vous sera utile !

Garbage Collection Program
(Garbage Collection, ci-après appelé GC) automatiquement alloué et libéré.Au début du développement logiciel ou de certains langages, la mémoire tas était allouée et libérée manuellement, comme C
,C++. Bien qu'il puisse exploiter la mémoire avec précision et obtenir la meilleure utilisation possible de la mémoire, l'efficacité du développement est très faible et il est sujet à un fonctionnement incorrect de la mémoire. [Recommandations de tutoriel associées : Tutoriel vidéo Nodejs, Enseignement de la programmation]Avec le développement de la technologie, les langages de haut niveau(tels que Java
Node) n'exigent pas que les développeurs utilisent manuellement la mémoire , et les langages de programmation alloueront et libéreront automatiquement de l'espace. Dans le même temps, le garbage collector GC (Garbage Collection) est également né pour aider à libérer et à organiser la mémoire. Dans la plupart des cas, les développeurs n’ont pas besoin de se soucier de la mémoire elle-même et peuvent se concentrer sur le développement commercial. L'article suivant traite principalement de la mémoire de tas et de GC. 2. Développement GC
Phase 1 GC monothread (représente : série)
, C'est l'étape initiale de GC, et ses performances sont aussi les piresPhase deux GC multithread parallèle (représenté par : Parallel Scavenge, ParNew)
GC simultané multi-thread de phase 3 ( représentant : CMS (Concurrent Mark Sweep) G1)
Les algorithmes GC des deux étapes de développement précédentes seront entièrement STW, et dans le GC simultané, certaines étapes des threads GC peuvent s'exécuter simultanément avec le code métier, garantissant un temps STW plus court. Cependant, il y aura des erreurs de marquage dans ce mode, car de nouveaux objets peuvent arriver pendant le processus GC. Bien sûr, l'algorithme lui-même corrigera et résoudra ce problèmeLes trois étapes ci-dessus ne signifient pas que GC doit en faire partie. les trois décrits ci-dessus. GC dans différents langages de programmation est implémenté à l'aide d'une combinaison d'algorithmes en fonction de différents besoins.
3. La partition de mémoire v8 et le GC
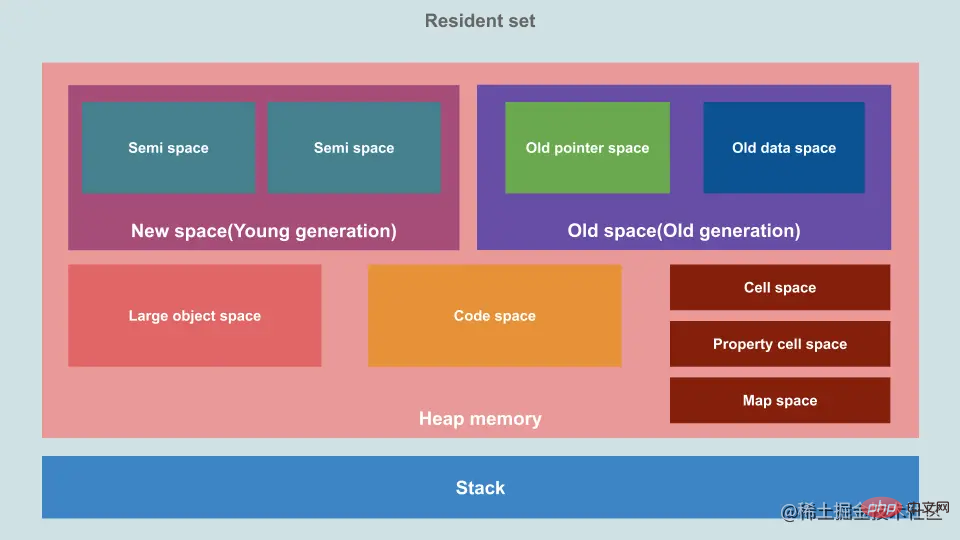
Dans Node.js, GC adopte une stratégie générationnelle et est divisé en zones de nouvelle et d'ancienne génération. La plupart des données de mémoire se trouvent dans ces deux zones.
La nouvelle génération est un petit pool de mémoire rapide qui stocke les jeunes objets. Il est divisé en deux demi-espaces (semi-espace), dont la moitié est libre (appelée à l'espace), l'autre moitié de l'espace stocke les données (appelées depuis l'espace).
Lorsque les objets sont créés pour la première fois, ils sont répartis dans la jeune génération du demi-espace, qui a 1 an. Lorsque l'espace from est insuffisant ou dépasse une certaine taille, Minor GC (en utilisant l'algorithme de copie Scavenge) sera déclenché. A ce moment, le GC suspendra l'exécution de l'application (STW, stop-the). -world) et mark (Tous les objets actifs dans l'espace depuis) sont ensuite triés et déplacés en continu vers un autre espace libre (vers l'espace) dans la nouvelle génération. Enfin, toute la mémoire de l'espace from d'origine sera libérée et deviendra de l'espace libre. Les deux espaces complèteront l'échange de from et to. L'algorithme de copie est un algorithme qui sacrifie l'espace au profit du temps.
L'espace de la nouvelle génération est plus petit, donc cet espace déclenchera GC plus fréquemment. Dans le même temps, l'espace analysé est plus petit, la consommation de performances du GC est également inférieure et le temps d'exécution du GC est également plus court.
Chaque fois qu'un GC mineur est terminé, l'âge des objets survivants est de +1. Les objets qui ont survécu à plusieurs GC mineurs (âge supérieur à N) seront déplacés vers le pool de mémoire d'ancienne génération.
L'ancienne génération est un grand pool de mémoire utilisé pour stocker des objets à longue durée de vie. La mémoire ancienne génération utilise l'algorithme Mark-Sweep et Mark-Compact. Une de ses exécutions s'appelle Mayor GC. Lorsque les objets de l'ancienne génération remplissent une certaine proportion, c'est-à-dire que le rapport entre les objets survivants et le total des objets dépasse un certain seuil, une mark clear ou mark compression sera déclenchée.
Parce que son espace est plus grand, son temps d'exécution GC est également plus long et sa fréquence est inférieure à celle de la nouvelle génération. S'il n'y a toujours pas suffisamment d'espace après que l'ancienne génération ait terminé le recyclage du GC, la V8 demandera plus de mémoire au système.
Vous pouvez exécuter manuellement la méthode global.gc(), définir différents paramètres et déclencher activement GC. Cependant, il convient de noter que cette méthode est désactivée par défaut dans Node.js. Si vous souhaitez l'activer, vous pouvez l'activer en ajoutant le paramètre --expose-gc au démarrage de l'application Node.js, par exemple :
node --expose-gc app.js
V8 Dans l'ancienne génération, Mark-Sweep et Mark -Compact sont principalement utilisés pour la collecte combinée des déchets.
Mark-Sweep signifie marquage par balayage, qui est divisé en deux étapes, marquage et balayage. Mark-Sweep Dans la phase de marquage, il parcourt tous les objets du tas et marque les objets vivants. Dans la phase de nettoyage suivante, seuls les objets non marqués sont effacés.
Mark-Sweep Le plus gros problème est qu'après un balayage et un recyclage des marques, l'espace mémoire deviendra discontinu. Ce type de fragmentation de la mémoire entraînera des problèmes pour l'allocation de mémoire ultérieure, car il est très probable qu'un objet volumineux doive être alloué. À ce stade, tout l'espace fragmenté ne peut pas terminer l'allocation et le garbage collection sera déclenché à l'avance. ce recyclage est inutile.
Afin de résoudre le problème de fragmentation de la mémoire de Mark-Sweep, Mark-Compact a été proposé. Mark-Compact signifie compilation de marques, basée sur Mark-Sweep. La différence entre eux est qu'une fois l'objet marqué comme mort, pendant le processus de nettoyage, les objets vivants sont déplacés vers une extrémité. Une fois le mouvement terminé, la mémoire en dehors de la limite est directement effacée. V8 libérera également une certaine quantité de mémoire libre et la restituera au système selon une certaine logique.
Les grands objets seront créés directement dans l'espace grand objet et ne seront pas déplacés vers d'autres espaces. Alors, combien d'objets seront créés directement dans l'espace des grands objets plutôt que dans la zone from nouvelle génération ? Après avoir consulté les informations et le code source, j'ai enfin trouvé la réponse. Par défaut, il s'agit de 256K, V8 ne semble pas exposer les commandes de modification, la configuration v8_enable_hugepage dans le code source doit être définie lors de l'empaquetage.
// There is a separate large object space for objects larger than // Page::kMaxRegularHeapObjectSize, so that they do not have to move during // collection. The large object space is paged. Pages in large object space // may be larger than the page size.
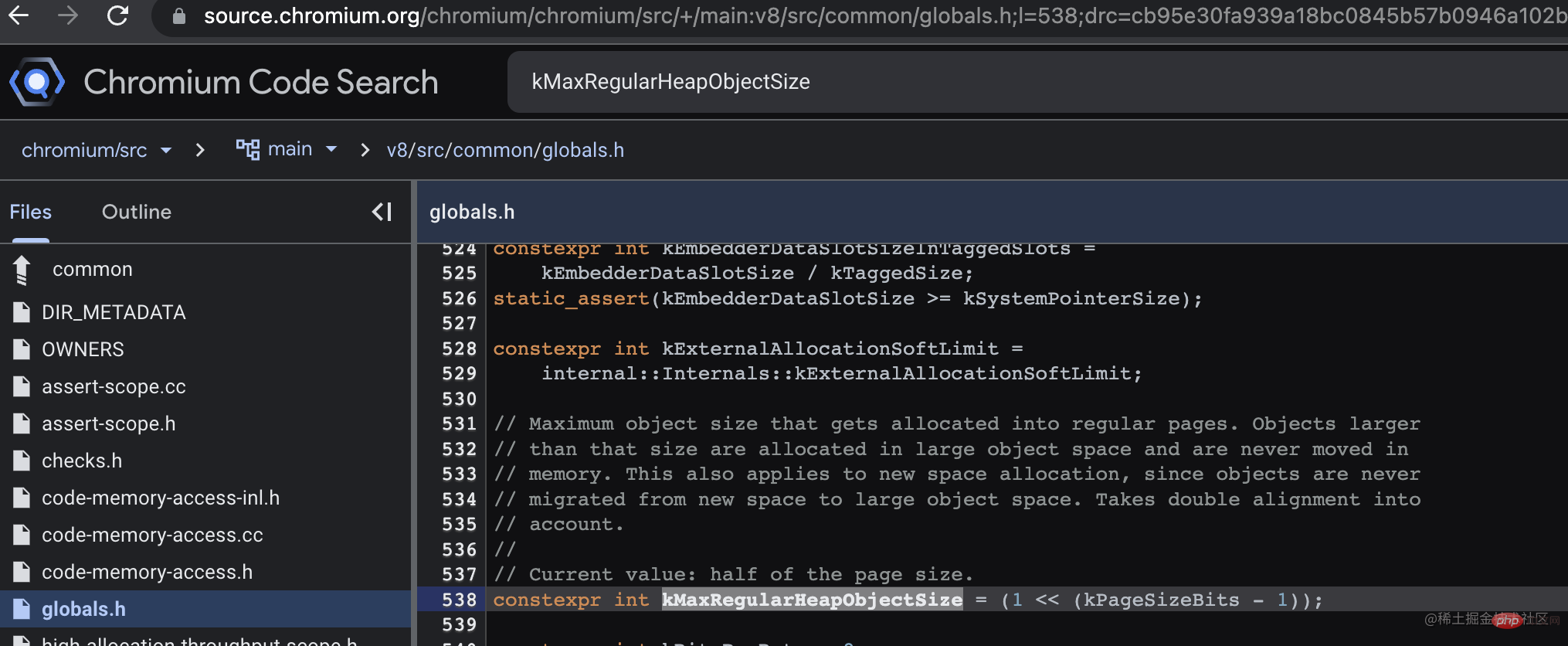
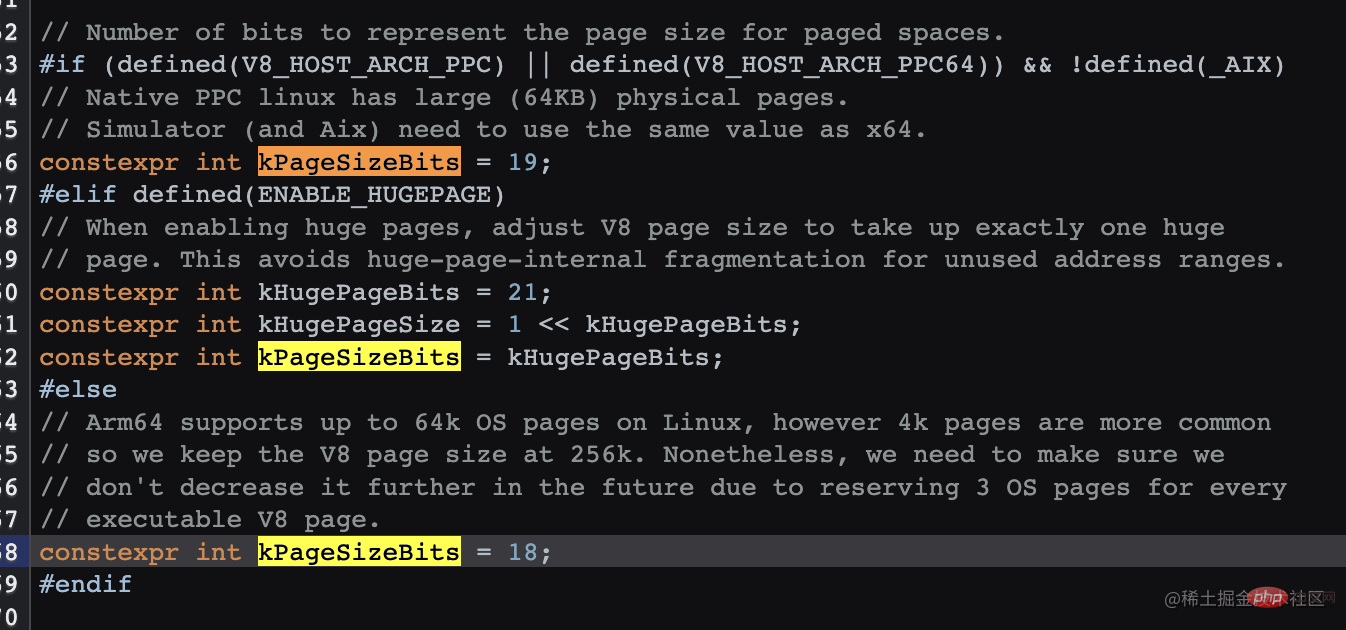
(1 << (18 - 1)) 的结果 256K (1 << (19 - 1)) 的结果 256K (1 << (21 - 1)) 的结果 1M(如果开启了hugPage)
在v12.x 之前:
为了保证 GC 的执行时间保持在一定范围内,V8 限制了最大内存空间,设置了一个默认老生代内存最大值,64位系统中为大约1.4G,32位为大约700M,超出会导致应用崩溃。
如果想加大内存,可以使用 --max-old-space-size 设置最大内存(单位:MB)
node --max_old_space_size=
在v12以后:
V8 将根据可用内存分配老生代大小,也可以说是堆内存大小,所以并没有限制堆内存大小。以前的限制逻辑,其实不合理,限制了 V8 的能力,总不能因为 GC 过程消耗的时间更长,就不让我继续运行程序吧,后续的版本也对 GC 做了更多优化,内存越来越大也是发展需要。
如果想要做限制,依然可以使用 --max-old-space-size 配置, v12 以后它的默认值是0,代表不限制。
参考文档:nodejs.medium.com/introducing…
新生代中的一个 semi-space 大小 64位系统的默认值是16M,32位系统是8M,因为有2个 semi-space,所以总大小是32M、16M。
--max-semi-space-size
--max-semi-space-size 设置新生代 semi-space 最大值,单位为MB。
此空间不是越大越好,空间越大扫描的时间就越长。这个分区大部分情况下是不需要做修改的,除非针对具体的业务场景做优化,谨慎使用。
--max-new-space-size
--max-new-space-size 设置新生代空间最大值,单位为KB(不存在)
有很多文章说到此功能,我翻了下 nodejs.org 网页中 v4 v6 v7 v8 v10的文档都没有看到有这个配置,使用 node --v8-options 也没有查到,也许以前的某些老版本有,而现在都应该使用 --max-semi-space-size。
执行 v8.getHeapStatistics(),查看 v8 堆内存信息,查询最大堆内存 heap_size_limit,当然这里包含了新、老生代、大对象空间等。我的电脑硬件内存是 8G,Node版本16x,查看到 heap_size_limit 是4G。
{
total_heap_size: 6799360,
total_heap_size_executable: 524288,
total_physical_size: 5523584,
total_available_size: 4340165392,
used_heap_size: 4877928,
heap_size_limit: 4345298944,
malloced_memory: 254120,
peak_malloced_memory: 585824,
does_zap_garbage: 0,
number_of_native_contexts: 2,
number_of_detached_contexts: 0
}到 k8s 容器中查询 NodeJs 应用,分别查看了v12 v14 v16版本,如下表。看起来是本身系统当前的最大内存的一半。128M 的时候,为啥是 256M,因为容器中还有交换内存,容器内存实际最大内存限制是内存限制值 x2,有同等的交换内存。
所以结论是大部分情况下 heap_size_limit 的默认值是系统内存的一半。但是如果超过这个值且系统空间足够,V8 还是会申请更多空间。当然这个结论也不是一个最准确的结论。而且随着内存使用的增多,如果系统内存还足够,这里的最大内存还会增长。
| 容器最大内存 | heap_size_limit |
|---|---|
| 4G | 2G |
| 2G | 1G |
| 1G | 0.5G |
| 1.5G | 0.7G |
| 256M | 256M |
| 128M | 256M |
process.memoryUsage()
{
rss: 35438592,
heapTotal: 6799360,
heapUsed: 4892976,
external: 939130,
arrayBuffers: 11170
}通过它可以查看当前进程的内存占用和使用情况 heapTotal、heapUsed,可以定时获取此接口,然后绘画出折线图帮助分析内存占用情况。以下是 Easy-Monitor 提供的功能:
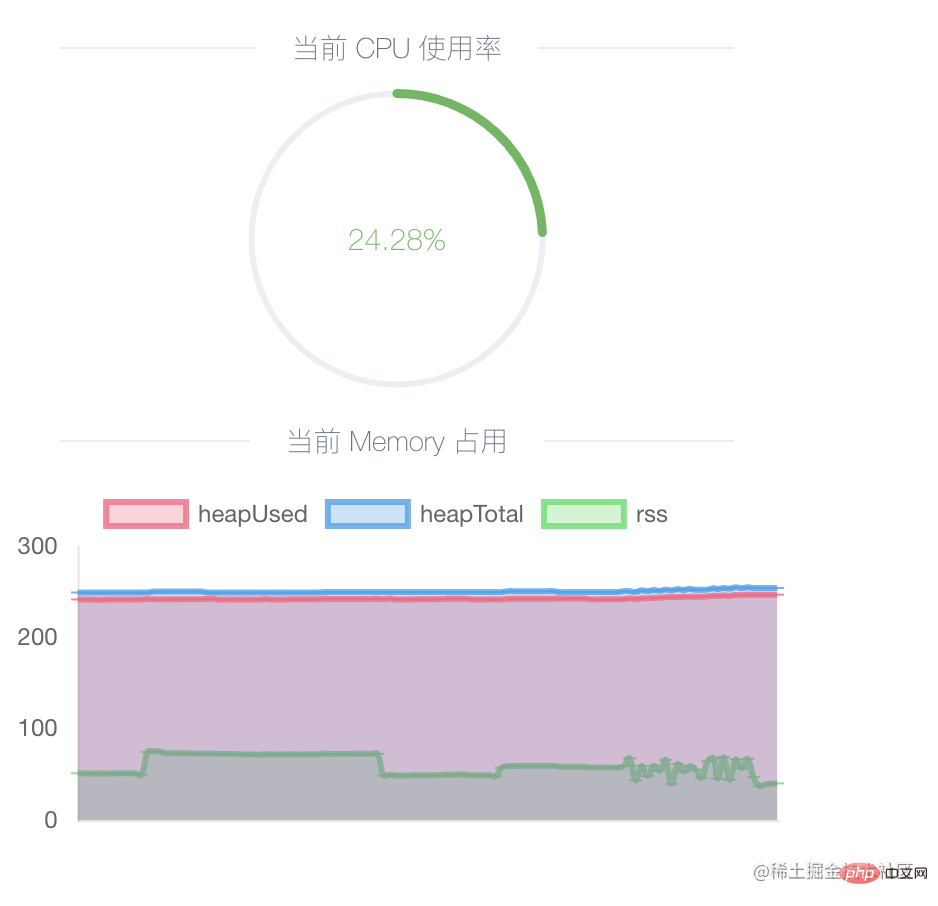
建议本地开发环境使用,开启后,尝试大量请求,会看到内存曲线增长,到请求结束之后,GC触发后会看到内存曲线下降,然后再尝试多次发送大量请求,这样往复下来,如果发现内存一直在增长低谷值越来越高,就可能是发生了内存泄漏。
使用方法
node --trace_gc app.js // 或者 v8.setFlagsFromString('--trace_gc');
[40807:0x148008000] 235490 ms: Scavenge 247.5 (259.5) -> 244.7 (260.0) MB, 0.8 / 0.0 ms (average mu = 0.971, current mu = 0.908) task [40807:0x148008000] 235521 ms: Scavenge 248.2 (260.0) -> 245.2 (268.0) MB, 1.2 / 0.0 ms (average mu = 0.971, current mu = 0.908) allocation failure [40807:0x148008000] 235616 ms: Scavenge 251.5 (268.0) -> 245.9 (268.8) MB, 1.9 / 0.0 ms (average mu = 0.971, current mu = 0.908) task [40807:0x148008000] 235681 ms: Mark-sweep 249.7 (268.8) -> 232.4 (268.0) MB, 7.1 / 0.0 ms (+ 46.7 ms in 170 steps since start of marking, biggest step 4.2 ms, walltime since start of marking 159 ms) (average mu = 1.000, current mu = 1.000) finalize incremental marking via task GC in old space requested
GCType <heapUsed before> (<heapTotal before>) -> <heapUsed after> (<heapTotal after>) MB
上面的 Scavenge 和 Mark-sweep 代表GC类型,Scavenge 是新生代中的清除事件,Mark-sweep 是老生代中的标记清除事件。箭头符号前是事件发生前的实际使用内存大小,箭头符号后是事件结束后的实际使用内存大小,括号内是内存空间总值。可以看到新生代中事件发生的频率很高,而后触发的老生代事件会释放总内存空间。
展示堆空间的详细情况
v8.setFlagsFromString('--trace_gc_verbose'); [44729:0x130008000] Fast promotion mode: false survival rate: 19% [44729:0x130008000] 97120 ms: [HeapController] factor 1.1 based on mu=0.970, speed_ratio=1000 (gc=433889, mutator=434) [44729:0x130008000] 97120 ms: [HeapController] Limit: old size: 296701 KB, new limit: 342482 KB (1.1) [44729:0x130008000] 97120 ms: [GlobalMemoryController] Limit: old size: 296701 KB, new limit: 342482 KB (1.1) [44729:0x130008000] 97120 ms: Scavenge 302.3 (329.9) -> 290.2 (330.4) MB, 8.4 / 0.0 ms (average mu = 0.998, current mu = 0.999) task [44729:0x130008000] Memory allocator, used: 338288 KB, available: 3905168 KB [44729:0x130008000] Read-only space, used: 166 KB, available: 0 KB, committed: 176 KB [44729:0x130008000] New space, used: 444 KB, available: 15666 KB, committed: 32768 KB [44729:0x130008000] New large object space, used: 0 KB, available: 16110 KB, committed: 0 KB [44729:0x130008000] Old space, used: 253556 KB, available: 1129 KB, committed: 259232 KB [44729:0x130008000] Code space, used: 10376 KB, available: 119 KB, committed: 12944 KB [44729:0x130008000] Map space, used: 2780 KB, available: 0 KB, committed: 2832 KB [44729:0x130008000] Large object space, used: 29987 KB, available: 0 KB, committed: 30336 KB [44729:0x130008000] Code large object space, used: 0 KB, available: 0 KB, committed: 0 KB [44729:0x130008000] All spaces, used: 297312 KB, available: 3938193 KB, committed: 338288 KB [44729:0x130008000] Unmapper buffering 0 chunks of committed: 0 KB [44729:0x130008000] External memory reported: 20440 KB [44729:0x130008000] Backing store memory: 22084 KB [44729:0x130008000] External memory global 0 KB [44729:0x130008000] Total time spent in GC : 199.1 ms
每次GC事件的详细信息,GC类型,各种时间消耗,内存变化等
v8.setFlagsFromString('--trace_gc_nvp'); [45469:0x150008000] 8918123 ms: pause=0.4 mutator=83.3 gc=s reduce_memory=0 time_to_safepoint=0.00 heap.prologue=0.00 heap.epilogue=0.00 heap.epilogue.reduce_new_space=0.00 heap.external.prologue=0.00 heap.external.epilogue=0.00 heap.external_weak_global_handles=0.00 fast_promote=0.00 complete.sweep_array_buffers=0.00 scavenge=0.38 scavenge.free_remembered_set=0.00 scavenge.roots=0.00 scavenge.weak=0.00 scavenge.weak_global_handles.identify=0.00 scavenge.weak_global_handles.process=0.00 scavenge.parallel=0.08 scavenge.update_refs=0.00 scavenge.sweep_array_buffers=0.00 background.scavenge.parallel=0.00 background.unmapper=0.04 unmapper=0.00 incremental.steps_count=0 incremental.steps_took=0.0 scavenge_throughput=1752382 total_size_before=261011920 total_size_after=260180920 holes_size_before=838480 holes_size_after=838480 allocated=831000 promoted=0 semi_space_copied=4136 nodes_died_in_new=0 nodes_copied_in_new=0 nodes_promoted=0 promotion_ratio=0.0% average_survival_ratio=0.5% promotion_rate=0.0% semi_space_copy_rate=0.5% new_space_allocation_throughput=887.4 unmapper_chunks=124 [45469:0x150008000] 8918234 ms: pause=0.6 mutator=110.9 gc=s reduce_memory=0 time_to_safepoint=0.00 heap.prologue=0.00 heap.epilogue=0.00 heap.epilogue.reduce_new_space=0.04 heap.external.prologue=0.00 heap.external.epilogue=0.00 heap.external_weak_global_handles=0.00 fast_promote=0.00 complete.sweep_array_buffers=0.00 scavenge=0.50 scavenge.free_remembered_set=0.00 scavenge.roots=0.08 scavenge.weak=0.00 scavenge.weak_global_handles.identify=0.00 scavenge.weak_global_handles.process=0.00 scavenge.parallel=0.08 scavenge.update_refs=0.00 scavenge.sweep_array_buffers=0.00 background.scavenge.parallel=0.00 background.unmapper=0.04 unmapper=0.00 incremental.steps_count=0 incremental.steps_took=0.0 scavenge_throughput=1766409 total_size_before=261207856 total_size_after=260209776 holes_size_before=838480 holes_size_after=838480 allocated=1026936 promoted=0 semi_space_copied=3008 nodes_died_in_new=0 nodes_copied_in_new=0 nodes_promoted=0 promotion_ratio=0.0% average_survival_ratio=0.5% promotion_rate=0.0% semi_space_copy_rate=0.3% new_space_allocation_throughput=888.1 unmapper_chunks=124
const { writeHeapSnapshot } = require('node:v8');
v8.writeHeapSnapshot()打印快照,将会STW,服务停止响应,内存占用越大,时间越长。此方法本身就比较费时间,所以生成的过程预期不要太高,耐心等待。
注意:生成内存快照的过程,会STW(程序将暂停)几乎无任何响应,如果容器使用了健康检测,这时无法响应的话,容器可能被重启,导致无法获取快照,如果需要生成快照、建议先关闭健康检测。
兼容性问题:此 API arm64 架构不支持,执行就会卡住进程 生成空快照文件 再无响应, 如果使用库 heapdump,会直接报错:
(mach-o file, but is an incompatible architecture (have (arm64), need (x86_64))
此 API 会生成一个 .heapsnapshot 后缀快照文件,可以使用 Chrome 调试器的“内存”功能,导入快照文件,查看堆内存具体的对象数和大小,以及到GC根结点的距离等。也可以对比两个不同时间快照文件的区别,可以看到它们之间的数据量变化。
一个 Node 应用因为内存超过容器限制经常发生重启,通过容器监控后台看到应用内存的曲线是一直上升的,那应该是发生了内存泄漏。
使用 Chrome 调试器对比了不同时间的快照。发现对象增量最多的是闭包函数,继而展开查看整个列表,发现数据量较多的是 mongo 文档对象,其实就是闭包函数内的数据没有被释放,再通过查看 Object 列表,发现同样很多对象,最外层的详情显示的是 Mongoose 的 Connection 对象。
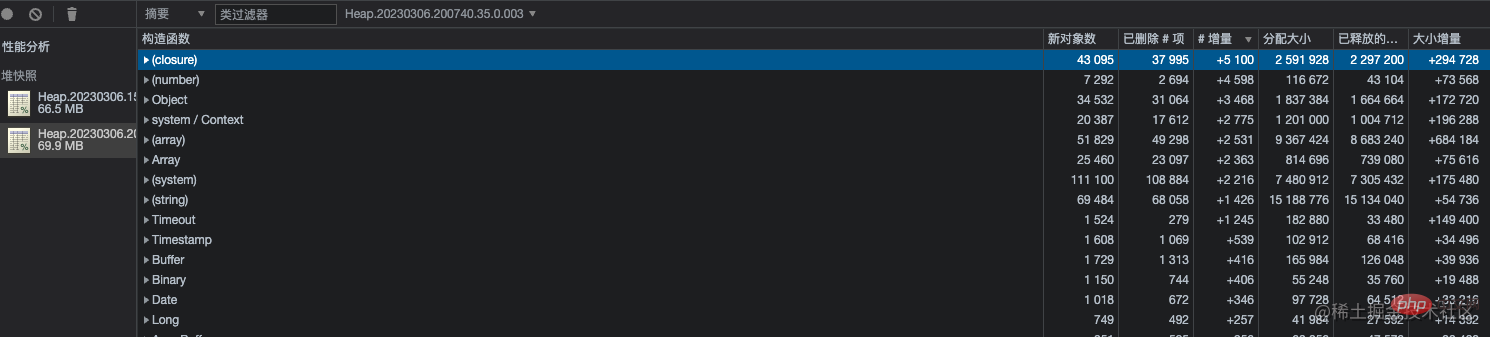
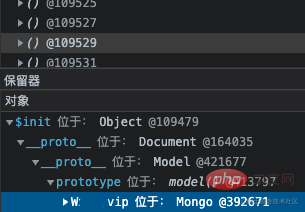
到此为止,已经大概定位到一个类的 mongo 数据存储逻辑附近有内存泄漏。
再看到 Timeout 对象也比较多,从 GC 根节点距离来看,这些对象距离非常深。点开详情,看到这一层层的嵌套就定位到了代码中准确的位置。因为那个类中有个定时任务使用 setInterval 定时器去分批处理一些不紧急任务,当一个 setInterval 把事情做完之后就会被 clearInterval 清除。
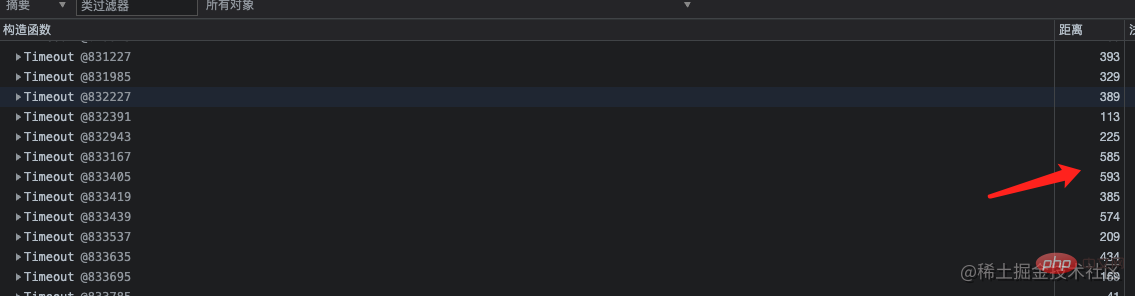
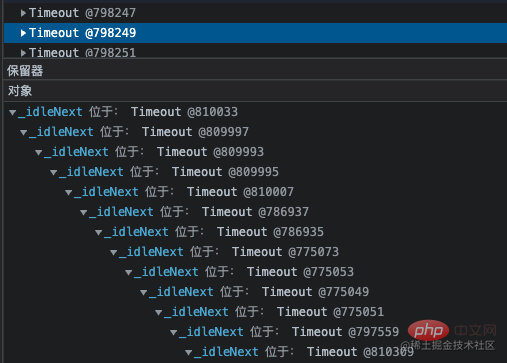
Grâce à l'analyse logique du code, nous avons finalement trouvé le problème. Il s'agissait d'un problème avec la condition de déclenchement de clearInterval, qui empêchait l'effacement du minuteur et la poursuite de la boucle. La minuterie continue de s'exécuter. Ce code et les données qu'il contient sont toujours dans la fermeture et ne peuvent pas être recyclés par GC, donc la mémoire deviendra de plus en plus grande jusqu'à ce qu'elle atteigne la limite supérieure et plante.
La manière d'utiliser setInterval ici est déraisonnable, d'ailleurs, elle a été modifiée pour utiliser pour l'exécution séquentielle de la file d'attente, afin d'éviter un grand nombre de concurrences en même temps, et le code devrait être beaucoup plus grand. plus clair. Étant donné que ce morceau de code est relativement ancien, je ne réfléchirai pas à la raison pour laquelle setInterval a été utilisé en premier lieu.
Après plus de dix jours d'observation après la sortie de la nouvelle version, la mémoire moyenne est restée à un peu plus de 100 Mo. Le GC a normalement recyclé la mémoire temporairement augmentée, montrant une courbe ondulée, et aucune fuite ne s'est produite.
GC Recyclage. 6 Enfin,
Go : Java : Comprendre JVM
(correspondant à Node V8),Java utilise également la génération. Stratégie, il y a aussi un espace eden dans sa nouvelle génération, et de nouveaux objets sont créés dans cet espace. Et V8 nouvelle génération n'a pas de zone eden. Go : Utilisation de l'effacement des marques et d'un algorithme de marquage à trois couleurs
Différentes langues ont des implémentations GC différentes, mais essentiellement, elles sont toutes implémentées à l'aide d'une combinaison d'algorithmes différents. En termes de performances, différentes combinaisons apportent des efficacités de performances différentes dans tous les aspects, mais elles font toutes des compromis et sont simplement orientées vers différents scénarios d'application. Pour plus de connaissances sur les nœuds, veuillez visiter :tutoriel Nodejs
!Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Python est-il front-end ou back-end ?
Python est-il front-end ou back-end ?
 débogage node.js
débogage node.js
 La différence entre front-end et back-end
La différence entre front-end et back-end
 Introduction au contenu principal du travail du backend
Introduction au contenu principal du travail du backend
 Utilisation de la méthode jQuery hover()
Utilisation de la méthode jQuery hover()
 Encyclopédie d'utilisation de Printf
Encyclopédie d'utilisation de Printf
 Utilisation de l'ordinateur Alibaba Cloud
Utilisation de l'ordinateur Alibaba Cloud
 Comment se connecter pour accéder à la base de données en VB
Comment se connecter pour accéder à la base de données en VB













![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



