


Cet article vous apporte des connaissances pertinentes sur Python, qui présentent principalement des connaissances pertinentes sur les robots d'exploration. En termes simples, les robots d'exploration sont le nom du processus d'utilisation de programmes pour obtenir des données sur Internet. J'espère que cela aidera tout le monde. .

Un robot d'exploration est simplement un nom désignant le processus d'utilisation d'un programme pour obtenir des données sur Internet.
Si nous voulons obtenir des données sur Internet, nous devons donner au robot une adresse de site Web (généralement appelée URL dans le programme). Le robot envoie une requête HTTP au serveur de la page Web cible, et le serveur renvoie les données au client (c'est-à-dire notre robot d'exploration), le robot effectue ensuite une série d'opérations telles que l'analyse et la sauvegarde des données.
Les robots peuvent nous faire gagner du temps. Par exemple, si je veux obtenir les 250 meilleurs films Douban, si nous n'utilisons pas de robot, nous devons d'abord saisir l'URL des films Douban sur le navigateur et le client. (navigateur) trouvera Douban grâce à l'analyse. L'adresse IP du serveur Web du film, puis établira une connexion avec celui-ci. Le navigateur crée une requête HTTP et l'envoie au serveur Douban Movie. Une fois que le serveur a reçu la requête, il l'extrait. la liste Top250 de la base de données, l'encapsule dans une réponse HTTP, puis le résultat de la réponse est renvoyé au navigateur, le navigateur affiche le contenu de la réponse et nous voyons les données. Notre robot est également basé sur ce processus, mais il est transformé en forme de code.
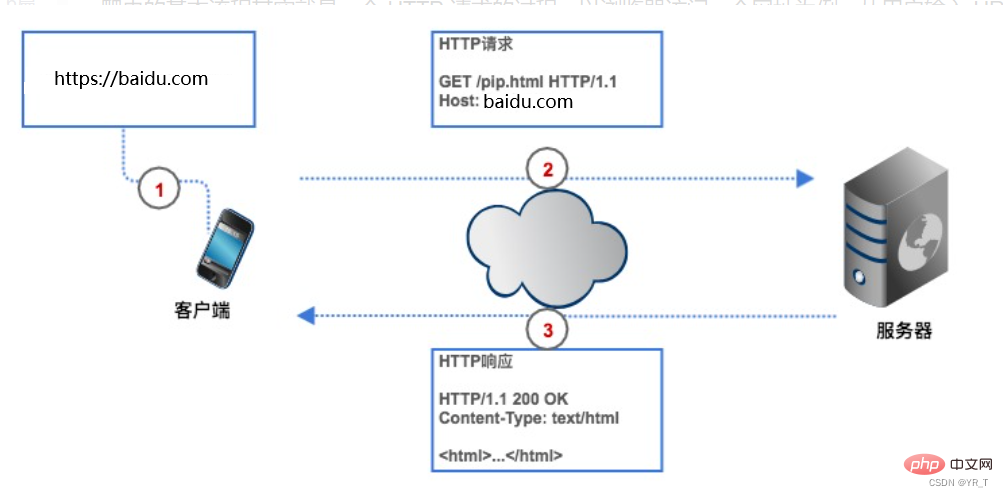
La requête HTTP comprend une ligne de requête, un en-tête de requête, une ligne vierge et un corps de requête.

La ligne de requête se compose de trois parties :
1. Méthode de requête, les méthodes de requête courantes sont GET, POST, PUT, DELETE, HEAD
2. Le chemin de ressource que le client souhaite obtenir
3. Utilisé par le client Le numéro de version du protocole HTTP
L'en-tête de requête est une description supplémentaire de la requête envoyée par le client au serveur, comme l'indication de l'identité du visiteur, qui sera discutée ci-dessous.
Le corps de la requête correspond aux données soumises par le client au serveur, telles que les informations de compte et de mot de passe qui doivent être améliorées lorsque l'utilisateur se connecte. L'en-tête et le corps de la requête sont séparés par des lignes vides. Le corps de la requête n'est pas inclus dans toutes les requêtes. Par exemple, GET général n'a pas de corps de requête.
L'image ci-dessus est la requête HTTP POST envoyée au serveur lorsque le navigateur se connecte à Douban. Le nom d'utilisateur et le mot de passe sont spécifiés dans le corps de la requête.
Le format de réponse HTTP est très similaire au format de demande et comprend également des lignes de réponse, des en-têtes de réponse, des lignes vides et des corps de réponse.

La ligne de réponse contient également trois parties, qui sont le numéro de version HTTP du serveur, le code d'état de la réponse et la description de l'état.
Il y a ici un tableau des codes d'état, qui correspond à la signification de chaque code d'état



La deuxième partie est l'en-tête de réponse L'en-tête de réponse correspond à l'en-tête de requête, et est un complément. des instructions pour la réponse du serveur, telles que quel est le format du contenu de la réponse, quelle est la durée du contenu de la réponse, quand est-il renvoyé au client, et même certaines informations sur les cookies seront placées dans l'en-tête de la réponse.
La troisième partie est le corps de la réponse, qui correspond aux véritables données de la réponse. Ces données sont en fait le code source HTML de la page Web.
Les robots d'exploration peuvent utiliser de nombreux langages tels que Python, C++, etc., mais je pense que Python est le plus simple,
Parce que Python a des bibliothèques prêtes à l'emploi qui ont été packagées presque à la perfection,
Bien que C++ dispose également de bibliothèques prêtes à l'emploi, leurs robots d'exploration sont encore relativement spécialisés. Les seules bibliothèques dont ils disposent ne sont pas assez simples et le code n'est pas très compatible avec différents compilateurs, ni même avec différentes versions du même compilateur. , donc ce n'est pas particulièrement bon à utiliser. Aujourd’hui, nous présentons principalement le robot d’exploration Python.
cmd run : pip install request pour installer les requêtes.
Ensuite, entrez les demandes d'importation
sur IDLE ou sur un compilateur (je recommande personnellement VS Code ou Pycharm) à exécuter. Si aucune erreur n'est signalée, l'installation est réussie.
La méthode pour installer la plupart des bibliothèques est : pip install xxx (nom de la bibliothèque)
| requests.request() | Construire une requête et prendre en charge les méthodes de base de chaque méthode |
| requests.get() | La méthode principale pour obtenir des pages Web HTML, correspondant au GET de HTTP |
requests.head() |
La méthode pour obtenir les informations d'en-tête de la page Web HTML, correspondant au HEAD de HTTP |
| requests.post() | La méthode pour soumettre un POST requête à la page Web HTML, correspondant au HTTP POST |
| requests.put() | Soumettre une requête PUT à une page Web HTML, correspondant au PUT de HTTP |
| requests.patch() | Soumettre une demande de modification partielle à une page Web HTML, correspondant à HTTP PATCT |
| requests.delete() | soumet une demande de suppression à une page Web HTML, correspondant à DELETE de HTTP |
r = requêtes .get(url)
comprend deux objets Importants :
Construire un objet Request pour demander des ressources au serveur ; renvoyer un objet Response contenant les ressources du serveur
| r.status_code | L'état de retour de la requête HTTP, 200 signifie que la connexion est réussie, 404 signifie un échec |
| r.text | La forme de chaîne du contenu de la réponse HTTP, c'est-à-dire le contenu de la page correspondant à l'url |
| r.encoding | Le contenu de la réponse méthode d'encodage devinée à partir de l'en-tête HTTP (si le jeu de caractères n'existe pas dans l'en-tête, envisagez d'encoder ISO-8859-1) |
| r.apparent_encoding | La méthode d'encodage du contenu de la réponse analysée à partir du contenu (méthode d'encodage alternative) |
| r.content | La forme binaire du contenu de la réponse HTTP |
| requests.ConnectionError | Exception d'erreur de connexion réseau, telle qu'un échec de requête DNS, une connexion refusée, etc. |
| requests .HTTPError | Exception d'erreur HTTP |
| requests.URLRequired | Exception d'URL manquante |
| requests.TooManyRedirects | Le nombre maximum de redirections a été dépassé, ce qui a entraîné une exception de redirection |
| requests.ConnectTimeout | Connexion à l'exception de délai d'attente du serveur distant |
| requests.Timeout | L'URL de la requête a expiré, ce qui a entraîné une exception de délai d'attente |
requests est la bibliothèque de robots d'exploration la plus basique, mais nous pouvons faire un simple traduction
Je vais d'abord mettre la structure du projet d'un petit projet de robot que j'ai réalisé. Le code source complet peut être téléchargé en discutant en privé avec moi.
Ce qui suit est le code source de la partie traduction
import requests
def English_Chinese():
url = "https://fanyi.baidu.com/sug"
s = input("请输入要翻译的词(中/英):")
dat = {
"kw":s
}
resp = requests.post(url,data = dat)# 发送post请求
ch = resp.json() # 将服务器返回的内容直接处理成json => dict
resp.close()
dic_lenth = len(ch['data'])
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])Explication détaillée du code :
Importez le module de requêtes et définissez l'URL sur l'URL de la page Web de traduction Baidu.
Envoyez ensuite la demande via la méthode post, puis tapez le résultat renvoyé dans un dic (dictionnaire), mais cette fois nous l'avons imprimé et avons constaté que c'est comme ça.

Voici à quoi ressemble un dictionnaire dans une liste à l'intérieur d'un dictionnaire, probablement comme ceci
{ xx:xx , xx:[ {xx:xx} , {xx:xx} , {xx: xx } , {xx:xx} ] }
L'endroit que j'ai marqué en rouge correspond à l'information dont nous avons besoin.
Supposons qu'il y ait n dictionnaires dans la liste marquée en bleu, nous pouvons obtenir la valeur de n via la fonction len(),
et utiliser la boucle for pour parcourir pour obtenir le résultat.
dic_lenth = len(ch['data']
for i in range(dic_lenth):
print("词:"+ch['data'][i]['k']+" "+"单词意思:"+ch['data'][i]['v'])D'accord, c'est tout pour le partage d'aujourd'hui, au revoir~
Hé ? J'ai oublié une chose, laissez-moi vous donner un autre code pour explorer la météo !
# -*- coding:utf-8 -*-
import requests
import bs4
def get_web(url):
header = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.114 Safari/537.36 Edg/91.0.864.59"}
res = requests.get(url, headers=header, timeout=5)
# print(res.encoding)
content = res.text.encode('ISO-8859-1')
return content
def parse_content(content):
soup = bs4.BeautifulSoup(content, 'lxml')
'''
存放天气情况
'''
list_weather = []
weather_list = soup.find_all('p', class_='wea')
for i in weather_list:
list_weather.append(i.text)
'''
存放日期
'''
list_day = []
i = 0
day_list = soup.find_all('h1')
for each in day_list:
if i <= 6:
list_day.append(each.text.strip())
i += 1
# print(list_day)
'''
存放温度:最高温度和最低温度
'''
tem_list = soup.find_all('p', class_='tem')
i = 0
list_tem = []
for each in tem_list:
if i == 0:
list_tem.append(each.i.text)
i += 1
elif i > 0:
list_tem.append([each.span.text, each.i.text])
i += 1
# print(list_tem)
'''
存放风力
'''
list_wind = []
wind_list = soup.find_all('p', class_='win')
for each in wind_list:
list_wind.append(each.i.text.strip())
# print(list_wind)
return list_day, list_weather, list_tem, list_wind
def get_content(url):
content = get_web(url)
day, weather, tem, wind = parse_content(content)
item = 0
for i in range(0, 7):
if item == 0:
print(day[i]+':\t')
print(weather[i]+'\t')
print("今日气温:"+tem[i]+'\t')
print("风力:"+wind[i]+'\t')
print('\n')
item += 1
elif item > 0:
print(day[i]+':\t')
print(weather[i] + '\t')
print("最高气温:"+tem[i][0]+'\t')
print("最低气温:"+tem[i][1] + '\t')
print("风力:"+wind[i]+'\t')
print('\n')【Recommandations associées : Tutoriel vidéo Python3】
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



