


Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement le contenu pertinent sur la stratégie de persistance RDB fait référence à l'écriture d'un instantané de l'ensemble de données en mémoire dans un intervalle de temps spécifié, jetons-y un coup d'œil. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo Redis
Redis (Remote Dictionary Server), le service de dictionnaire distant, est un service de stockage de données en cache mémoire open source. Écrit en langage ANSI C, il prend en charge le stockage de données réseau, de type journal persistant et basé sur la mémoire, le stockage de données clé-valeur et fournit des API dans plusieurs langues.
Redis est une base de données en mémoire et les données sont stockées en mémoire. Pour éviter la perte permanente de données causée par la sortie du processus, les données dans Redis doivent être enregistrées régulièrement de la mémoire sur le disque dur sous une forme (données ou commandes). Au prochain redémarrage de Redis, utilisez des fichiers persistants pour récupérer les données. De plus, les fichiers persistants peuvent être copiés vers un emplacement distant à des fins de sauvegarde après sinistre. Il existe deux mécanismes de persistance de Redis :
RDB enregistre les données actuelles sur le disque dur et AOF enregistre les données actuelles sur le disque dur à chaque fois. Les commandes d'écriture exécutées sont enregistrées sur le disque dur (similaire au Binlog de MySQL). La persistance AOF offre de meilleures performances en temps réel, c'est-à-dire que moins de données sont perdues lorsque le processus se termine de manière inattendue.
rdb ( redisdata base) fait référence à l'écriture d'un instantané de l'ensemble de données en mémoire sur le disque dans un intervalle de temps spécifié. persisté sous la forme d'instantanés de mémoire (forme sérialisée binaire de données de mémoire). À chaque fois, un instantané est généré à partir de Redis pour sauvegarder entièrement les données.
Avantages :
Inconvénients :
Par défaut, Redis enregistre l'instantané de la base de données dans un fichier binaire nommé dump.rdb. La structure du fichier RDB se compose de cinq parties :
(1) Chaîne constante REDIS d'une longueur de 5 octets. REDIS 常量字符串。
(2)4字节的 db_version,标识 RDB 文件版本。
(3)databases:不定长度,包含零个或多个数据库,以及各数据库中的键值对数据。
(4)1字节的 EOF 常量,表示文件正文内容结束。
(5)check_sum: 8字节长的无符号整数,保存校验和。

数据结构举例,以下是数据库[0]和数据库[3]有数据的情况:

手动指令触发
手动触发 RDB 持久化的方式可以使用 save 命令和 bgsave 命令,这两个命令的区别如下:
save:执行 save 指令,阻塞 Redis 的其他操作,会导致 Redis 无法响应客户端请求,不建议使用。
bgsave:执行 bgsave 指令,Redis 后台创建子进程,异步进行快照的保存操作,此时 Redis 仍然能响应客户端的请求。
自动间隔性保存
在默认情况下,Redis 将数据库快照保存在名字为 dump.rdb的二进制文件中。可以对 Redis 进行设置,让它在“ N 秒内数据集至少有 M 个改动”这一条件被满足时,自动保存一次数据集。
比如说, 以下设置会让 Redis 在满足“ 60 秒内有至少有 10 个键被改动”这一条件时,自动保存一次数据集:save 60 10
🎜🎜Exemple de structure de données, voici la situation où la base de données [0] et la base de données [3] contiennent des données : 🎜🎜 🎜
🎜save et la commande bgsave. Les différences entre ces deux commandes sont les suivantes : 🎜🎜. save : l'exécution de la commande save pour bloquer d'autres opérations de Redis empêchera Redis de répondre aux demandes des clients et n'est pas recommandée. 🎜🎜bgsave : exécutez la commande bgsave, Redis crée un processus enfant en arrière-plan et enregistre l'instantané de manière asynchrone. À ce stade, Redis peut toujours répondre à la demande du client. . 🎜🎜🎜Sauvegarde automatique des intervalles🎜🎜🎜Par défaut, Redis enregistre les instantanés de la base de données dans un fichier binaire nommé dump.rdb. Redis peut être configuré pour enregistrer automatiquement un ensemble de données lorsque la condition « l'ensemble de données comporte au moins M modifications en N secondes » est remplie. 🎜🎜Par exemple, les paramètres suivants amèneront Redis à enregistrer automatiquement un ensemble de données lorsqu'il remplit la condition « au moins 10 clés ont été modifiées dans les 60 secondes » : save 60 10. 🎜La configuration par défaut de Redis est la suivante. La sauvegarde automatique peut être déclenchée si l'un des trois paramètres est respecté :
save 60 10000 save 300 10 save 900 1
La structure de données de la configuration de la sauvegarde automatique
enregistre la condition du serveur déclenchant automatiquement. Attribut <code>BGSAVE saveparams. BGSAVE 条件的saveparams属性。
lastsave 属性:记录服务器最后一次执行 SAVE 或者 BGSAVE 的时间。
dirty
lastsave : enregistre la dernière fois que le serveur a exécuté SAVE ou BGSAVE. 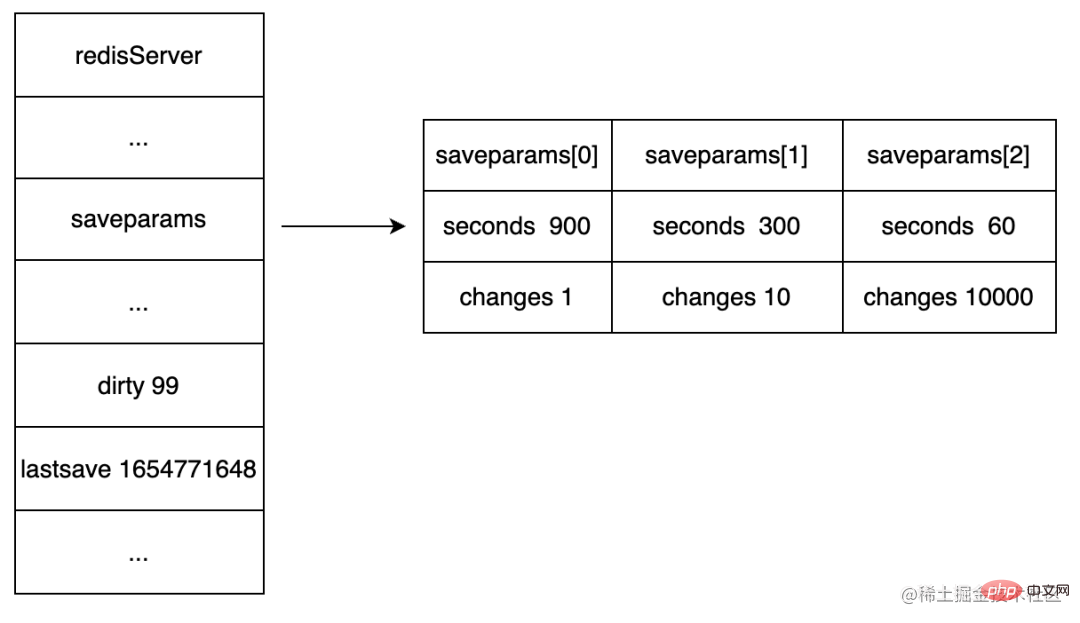 Attribut
Attribut dirty : et combien de fois le serveur a écrit depuis la dernière fois que le fichier RDB a été enregistré.
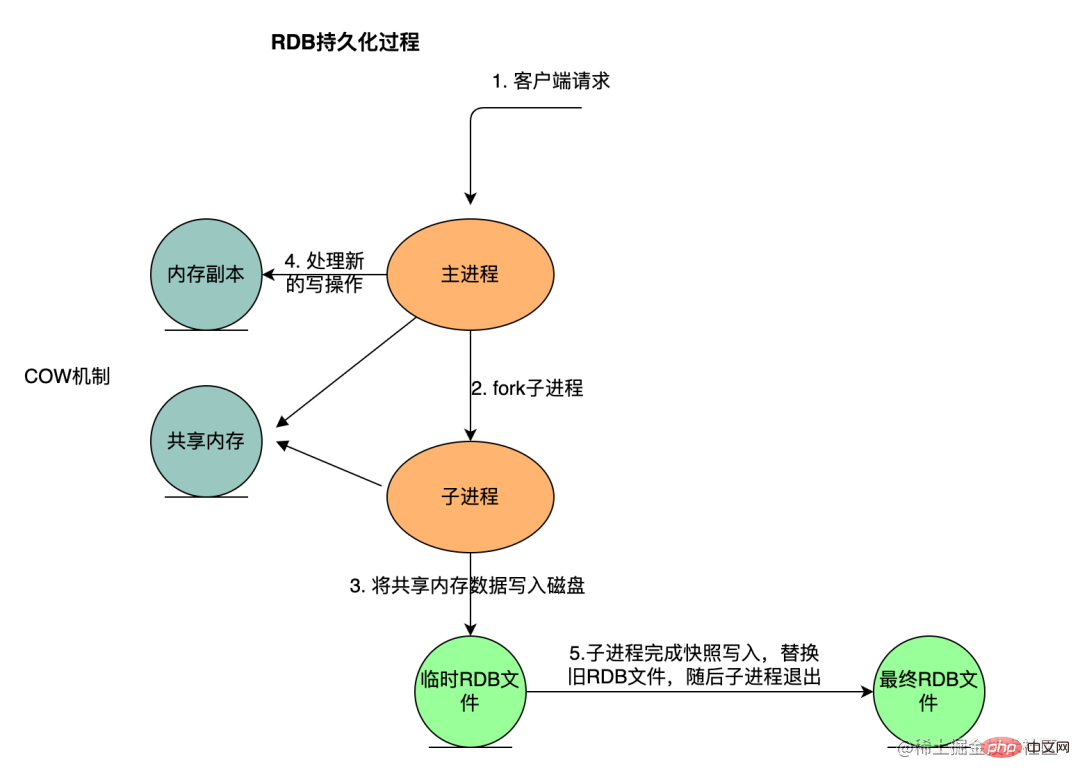 Lors de la sauvegarde du schéma de persistance RDB, Redis créera un sous-processus distinct pour la persistance, écrira les données dans un fichier temporaire et remplacera l'ancien fichier RDB une fois la persistance terminée. Pendant tout le processus de persistance, le processus principal (le processus qui fournit des services au client) ne participe pas aux opérations d'E/S, ce qui garantit les hautes performances du service Redis. Le mécanisme de persistance RDB est adapté à une utilisation qui n'a pas d'exigences élevées. pour l’intégrité des données mais poursuit une scène de récupération efficace. Ce qui suit montre le processus de persistance RDB :
Lors de la sauvegarde du schéma de persistance RDB, Redis créera un sous-processus distinct pour la persistance, écrira les données dans un fichier temporaire et remplacera l'ancien fichier RDB une fois la persistance terminée. Pendant tout le processus de persistance, le processus principal (le processus qui fournit des services au client) ne participe pas aux opérations d'E/S, ce qui garantit les hautes performances du service Redis. Le mécanisme de persistance RDB est adapté à une utilisation qui n'a pas d'exigences élevées. pour l’intégrité des données mais poursuit une scène de récupération efficace. Ce qui suit montre le processus de persistance RDB :
Le processus enfant termine l'écriture de l'instantané, remplace l'ancien fichier RDB, puis se termine.
Le rôle du processus enfant Fork
Pour des raisons d'efficacité, le système d'exploitation Linux utilise le mécanisme de copie sur écriture COW (Copy On Write). Le processus enfant fork utilise généralement une section de mémoire physique avec le processus parent, uniquement lorsque la mémoire est dans le processus. l'espace est modifié, l'espace mémoire sera copié.
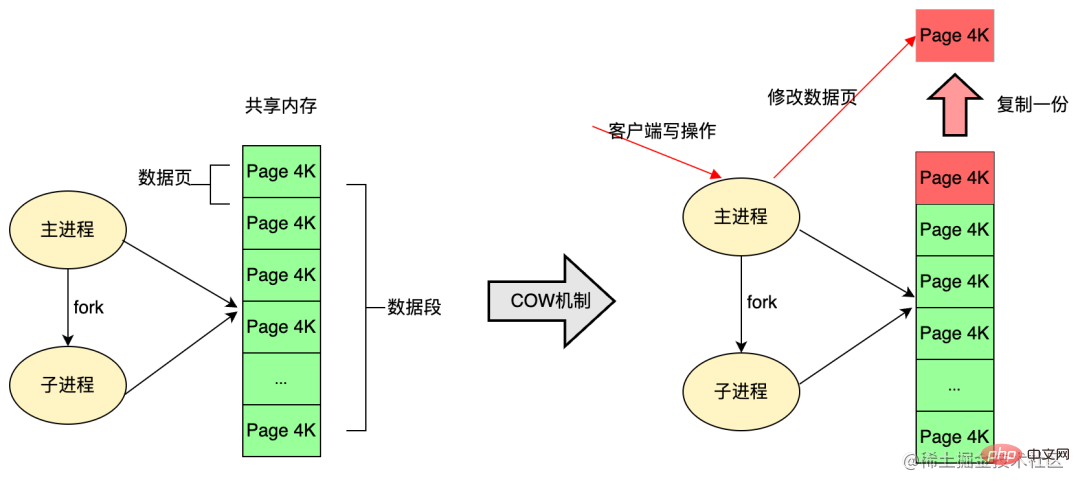 Dans Redis, la persistance RDB utilise pleinement cette technologie. Lors de la persistance, Redis appelle la fonction glibc pour créer un processus enfant et est entièrement responsable du travail de persistance, afin que le processus parent puisse toujours continuer à fournir des services au processus enfant. client. Le processus enfant de fork partage initialement la même mémoire avec le processus parent (le processus principal de Redis) ; lorsque le client demande de modifier les données en mémoire pendant le processus de persistance, le mécanisme COW (Copy On Write) sera utilisé pour modifier les données dans la mémoire. La page de segment de données est séparée, c'est-à-dire qu'un morceau de mémoire est copié pour que le processus principal puisse le modifier.
Dans Redis, la persistance RDB utilise pleinement cette technologie. Lors de la persistance, Redis appelle la fonction glibc pour créer un processus enfant et est entièrement responsable du travail de persistance, afin que le processus parent puisse toujours continuer à fournir des services au processus enfant. client. Le processus enfant de fork partage initialement la même mémoire avec le processus parent (le processus principal de Redis) ; lorsque le client demande de modifier les données en mémoire pendant le processus de persistance, le mécanisme COW (Copy On Write) sera utilisé pour modifier les données dans la mémoire. La page de segment de données est séparée, c'est-à-dire qu'un morceau de mémoire est copié pour que le processus principal puisse le modifier.
AOF (Append Only File) 是把所有对内存进行修改的指令(写操作)以独立日志文件的方式进行记录,重启时通过执行 AOF 文件中的 Redis 命令来恢复数据。类似MySql bin-log 原理。AOF 能够解决数据持久化实时性问题,是现在 Redis 持久化机制中主流的持久化方案。
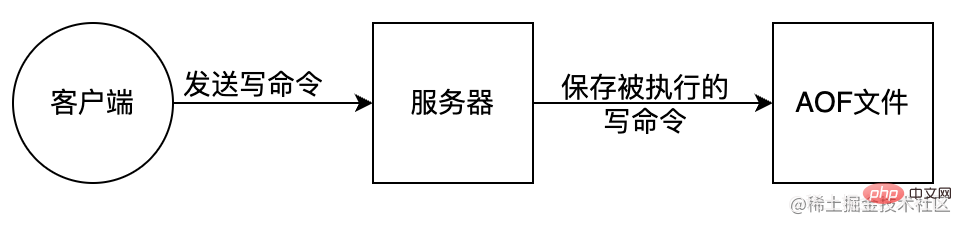
优点:
缺点:
被写入 AOF 文件的所有命令都是以 RESP 格式保存的,是纯文本格式保存在 AOF 文件中。
Redis 客户端和服务端之间使用一种名为
RESP(REdis Serialization Protocol)的二进制安全文本协议进行通信。
下面以一个简单的 SET 命令进行举例:
redis> SET mykey "hello" //客户端命令OK
客户端封装为以下格式(每行用 \r\n分隔)
*3$3SET$5mykey$5hello
AOF 文件中记录的文本内容如下
*2\r\n$6\r\nSELECT\r\n$1\r\n0\r\n //多出一个SELECT 0 命令,用于指定数据库,为系统自动添加 *3\r\n$3\r\nSET\r\n$5\r\nmykey\r\n$5\r\nhello\r\n
AOF 持久化方案进行备份时,客户端所有请求的写命令都会被追加到 AOF 缓冲区中,缓冲区中的数据会根据 Redis 配置文件中配置的同步策略来同步到磁盘上的 AOF 文件中,追加保存每次写的操作到文件末尾。同时当 AOF 的文件达到重写策略配置的阈值时,Redis 会对 AOF 日志文件进行重写,给 AOF 日志文件瘦身。Redis 服务重启的时候,通过加载 AOF 日志文件来恢复数据。
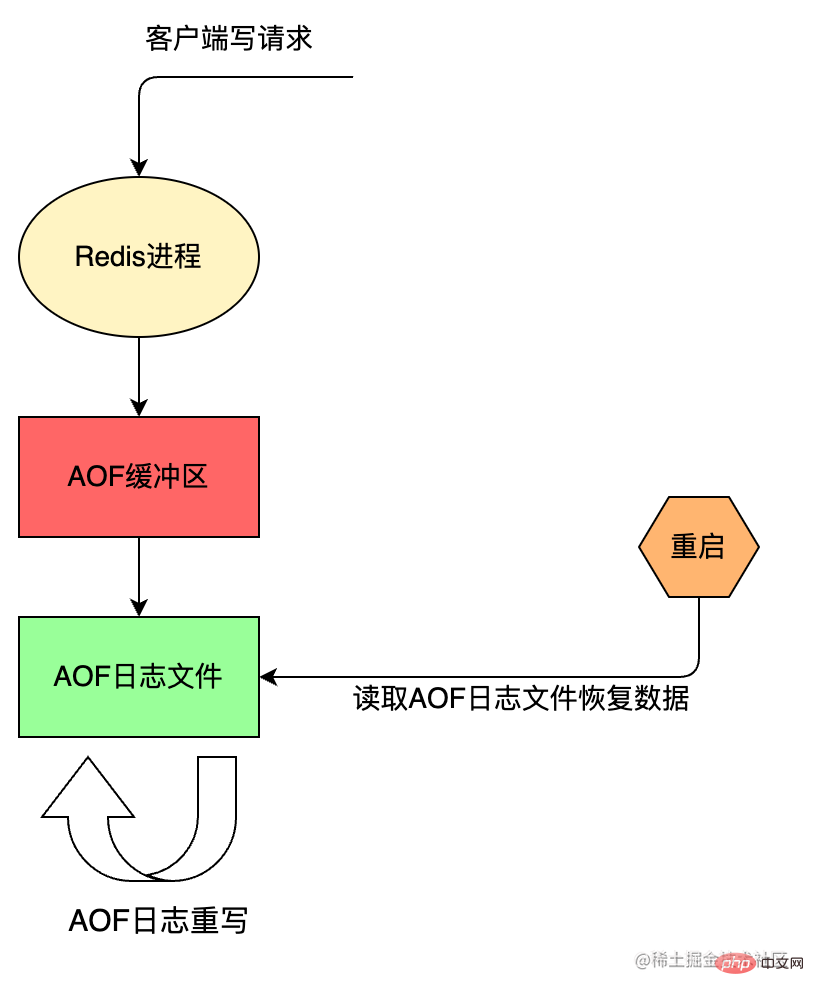
AOF 的执行流程包括:
命令追加(append)
Redis 先将写命令追加到缓冲区 aof_buf,而不是直接写入文件,主要是为了避免每次有写命令都直接写入硬盘,导致硬盘 IO 成为 Redis 负载的瓶颈。
struct redisServer {
//其他域... sds aof_buf; // sds类似于Java中的String //其他域...}文件写入(write)和文件同步(sync)
根据不同的同步策略将 aof_buf 中的内容同步到硬盘;
Linux 操作系统中为了提升性能,使用了页缓存(page cache)。当我们将 aof_buf 的内容写到磁盘上时,此时数据并没有真正的落盘,而是在 page cache 中,为了将 page cache 中的数据真正落盘,需要执行 fsync / fdatasync 命令来强制刷盘。这边的文件同步做的就是刷盘操作,或者叫文件刷盘可能更容易理解一些。
AOF 缓存区的同步文件策略由参数 appendfsync 控制,有三种同步策略,各个值的含义如下:
always:命令写入 aof_buf 后立即调用系统 write 操作和系统 fsync 操作同步到 AOF 文件,fsync 完成后线程返回。这种情况下,每次有写命令都要同步到 AOF 文件,硬盘 IO 成为性能瓶颈,Redis 只能支持大约几百TPS写入,严重降低了 Redis 的性能;即便是使用固态硬盘(SSD),每秒大约也只能处理几万个命令,而且会大大降低 SSD 的寿命。可靠性较高,数据基本不丢失。no:命令写入 aof_buf 后调用系统 write 操作,不对 AOF 文件做 fsync 同步;同步由操作系统负责,通常同步周期为30秒。这种情况下,文件同步的时间不可控,且缓冲区中堆积的数据会很多,数据安全性无法保证。everysec:命令写入 aof_buf 后调用系统 write 操作,write 完成后线程返回;fsync 同步文件操作由专门的线程每秒调用一次。everysec 是前述两种策略的折中,是性能和数据安全性的平衡,因此是 Redis 的默认配置,也是我们推荐的配置。文件重写(rewrite)
定期重写 AOF 文件,达到压缩的目的。
AOF 重写是 AOF 持久化的一个机制,用来压缩 AOF 文件,通过 fork 一个子进程,重新写一个新的 AOF 文件,该次重写不是读取旧的 AOF 文件进行复制,而是读取内存中的Redis数据库,重写一份 AOF 文件,有点类似于 RDB 的快照方式。
文件重写之所以能够压缩 AOF 文件,原因在于:
前面提到 AOF 的缺点时,说过 AOF 属于日志追加的形式来存储 Redis 的写指令,这会导致大量冗余的指令存储,从而使得 AOF 日志文件非常庞大,比如同一个 key 被写了 10000 次,最后却被删除了,这种情况不仅占内存,也会导致恢复的时候非常缓慢,因此 Redis 提供重写机制来解决这个问题。Redis 的 AOF 持久化机制执行重写后,保存的只是恢复数据的最小指令集,我们如果想手动触发可以使用如下指令:
bgrewriteaof
文件重写时机
相关参数:
同时满足下面两个条件,则触发 AOF 重写机制:
AOF 重写流程如下:
bgrewriteaof 触发重写,判断是否存在 bgsave 或者 bgrewriteaof 正在执行,存在则等待其执行结束再执行
子进程遍历 Redis 内存快照中数据写入临时 AOF 文件,同时会将新的写指令写入 aof_buf 和 aof_rewrite_buf 两个重写缓冲区,前者是为了写回旧的 AOF 文件,后者是为了后续刷新到临时 AOF 文件中,防止快照内存遍历时新的写入操作丢失
子进程结束临时 AOF 文件写入后,通知主进程
主进程会将上面 3 中的 aof_rewirte_buf 缓冲区中的数据写入到子进程生成的临时 AOF 文件中
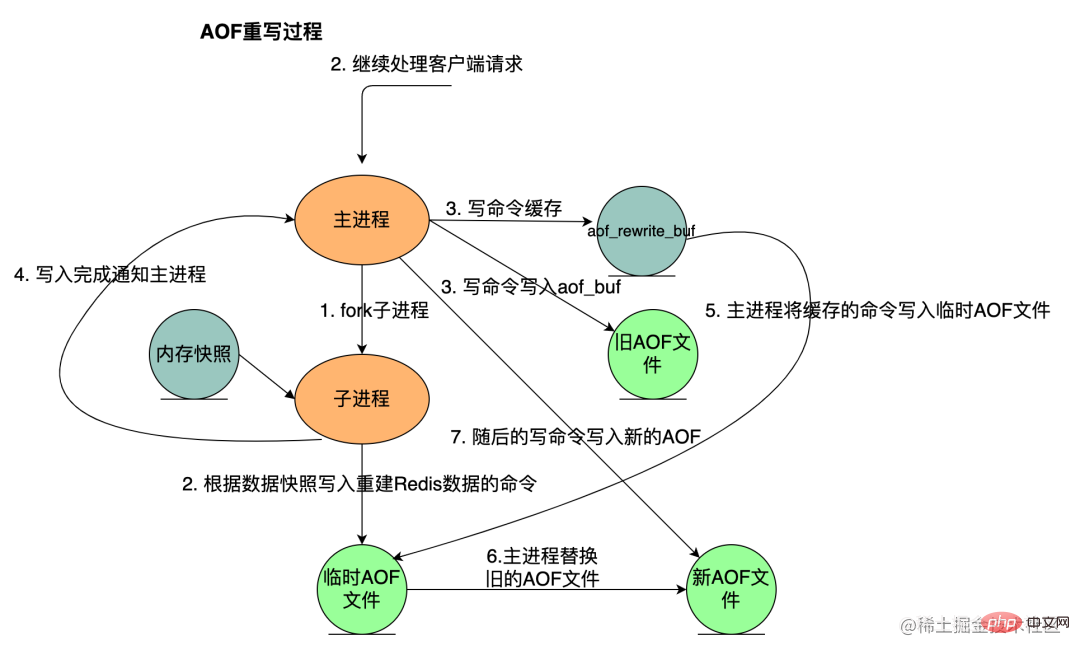
在实际中,为了避免在执行命令时造成客户端输入缓冲区溢出,重写程序会检查集合元素数量是否超过 REDIS_AOF_REWRITE_ITEMS_PER_CMD 常量的值,如果超过了,则会使用多个命令来记录,而不单单使用一条命令。
Redis 2.9版本中该常量为64,如果一个命令的集合键包含超过了64个元素,重写程序会拆成多个命令。

AOF重写是一个有歧义的名字,该功能是通过直接读取数据库的键值对实现的,程序无需对现有AOF文件进行任何读入、分析或者写入操作。
Redis 为什么考虑使用 AOF 而不是 WAL 呢?
很多数据库都是采用的 Write Ahead Log(WAL)写前日志,其特点就是先把修改的数据记录到日志中,再进行写数据的提交,可以方便通过日志进行数据恢复。
但是 Redis 采用的却是 AOF(Append Only File)写后日志,特点就是先执行写命令,把数据写入内存中,再记录日志。
Si vous laissez le système exécuter la commande en premier, seule la commande qui peut être exécutée avec succès sera enregistrée dans le journal. Par conséquent, Redis utilise la journalisation post-écriture pour éviter d'enregistrer des commandes incorrectes.
Une autre raison est qu'AOF n'enregistre le journal qu'après l'exécution de la commande, il ne bloquera donc pas l'opération d'écriture en cours.
Dans Redis avec un numéro de version supérieur ou égal à 2.4, BGREWRITEAOF ne peut pas être exécuté lors de l'exécution de BGSAVE. En revanche, BGSAVE ne peut pas être exécuté lors de l'exécution de BGREWRITEAOF. Cela empêche deux processus d'arrière-plan Redis d'effectuer simultanément des opérations d'E/S lourdes sur le disque.
Si BGSAVE est en cours d'exécution et que l'utilisateur appelle explicitement la commande BGREWRITEAOF, le serveur répondra avec un statut OK à l'utilisateur et l'informera que l'exécution de BGREWRITEAOF a été planifiée : BGREWRITEAOF démarrera officiellement une fois BGSAVE terminé.
Lorsque Redis démarre, si la persistance RDB et la persistance AOF sont activées, le programme donnera la priorité à l'utilisation des fichiers AOF pour restaurer l'ensemble de données, car les données enregistrées dans les fichiers AOF sont généralement les plus complètes.
Après Redis 4.0, la plupart des scénarios d'utilisation n'utiliseront pas RDB ou AOF seuls comme mécanisme de persistance, mais prendront en compte les avantages des deux. La raison en est que bien que RDB soit rapide, il perdra beaucoup de données et ne pourra pas garantir l'intégrité des données ; bien qu'AOF puisse garantir l'intégrité des données autant que possible, ses performances sont en effet une critique, comme la relecture et la récupération des données.
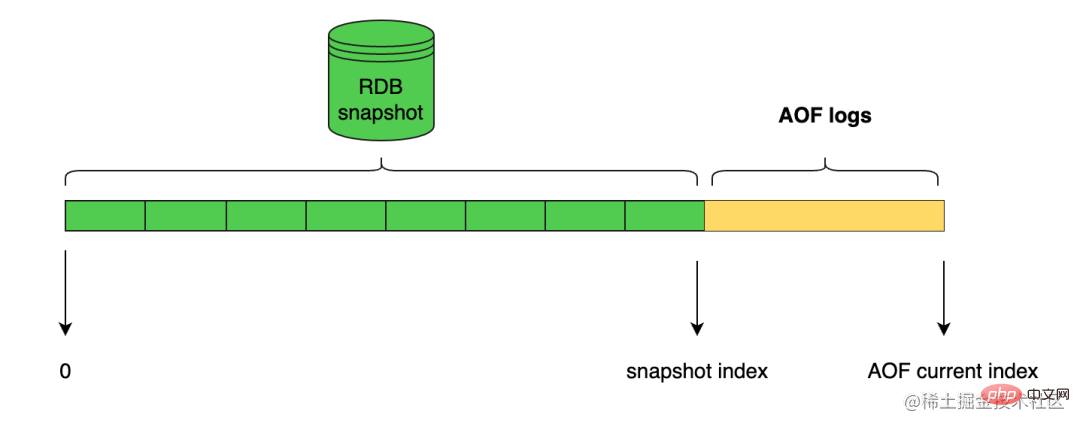
Redis a introduit le mode de persistance hybride RDB-AOF depuis la version 4.0. Ce mode est construit sur la base du mode de persistance hybride AOF activé via aof-use-rdb-preamble yes.
Ensuite, lorsque le serveur Redis effectuera l'opération de réécriture AOF, il générera les données RDB correspondantes en fonction de l'état actuel de la base de données, tout comme l'exécution de la commande BGSAVE, et écrira ces données dans le fichier AOF nouvellement créé. les commandes Redis de réécriture AOF exécutées après le début de l'écriture continueront d'être ajoutées à la fin du nouveau fichier AOF sous la forme d'un texte de protocole, c'est-à-dire après les données RDB existantes.
En d'autres termes, après avoir activé la fonction de persistance hybride RDB-AOF, le fichier AOF généré par le serveur sera composé de deux parties. Les données au début du fichier AOF sont les données au format RDB, et celles qui suivent. Les données RDB sont des données au format AOF.
Lorsqu'un serveur Redis prenant en charge le mode de persistance hybride RDB-AOF démarre et charge un fichier AOF, il vérifie si le début du fichier AOF contient du contenu au format RDB.
La structure du fichier journal est la suivante :
Enfin, pour résumer les deux, lequel est le meilleur ?
Apprentissage recommandé : Tutoriel vidéo Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
 Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
 Quelles données le cache Redis stocke-t-il généralement ?
Quelles données le cache Redis stocke-t-il généralement ?
 Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



