Cet article vous apporte des connaissances pertinentes sur mysql et présente principalement la discussion systématique de l'opération JOIN gênante. Cet article mènera une discussion systématique et approfondie de l'opération JOIN, basée sur ma propre expérience professionnelle et ma référence à l'industrie. Les cas classiques sont utilisés pour proposer des méthodologies de simplification grammaticale et d'optimisation des performances. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
Avant-propos
- J'ai expérimenté des projets de startup de zéro à un, et il y a aussi des projets de données massifs d'une manière générale, comment construire un projet sûr et fiable comme le ; le projet se développe progressivement ? Le stockage stable des données a toujours été la partie centrale, la plus importante et la plus critique du projet, personne d'autre
- Ensuite, je publierai systématiquement la série d'articles sur le stockage dans cet article, dont nous parlerons d'abord ; l'une des connexions les plus gênantes dans les données. Opération—JOIN
- JOIN a toujours été un problème difficile en SQL. Lorsqu'il y a un peu plus de tables liées, l'écriture de code devient très sujette aux erreurs. En raison de la complexité des instructions JOIN, les requêtes associées ont toujours été la faiblesse des logiciels BI. Il n'existe pratiquement aucun logiciel BI permettant aux utilisateurs professionnels d'effectuer des tâches multiples en douceur. -associations de tables. Il en va de même pour l'optimisation des performances. Lorsqu'il existe de nombreuses tables associées ou une grande quantité de données, il est difficile d'améliorer les performances de JOIN
- Sur la base de ce qui précède, cet article mènera une discussion systématique et approfondie de JOIN. opération. Sur la base de ma propre expérience professionnelle et de références à des cas classiques de l'industrie, nous avons présenté la méthodologie de simplification de la syntaxe et d'optimisation des performances de manière ciblée, en espérant qu'elle sera utile à tout le monde
Aperçu avec une seule image
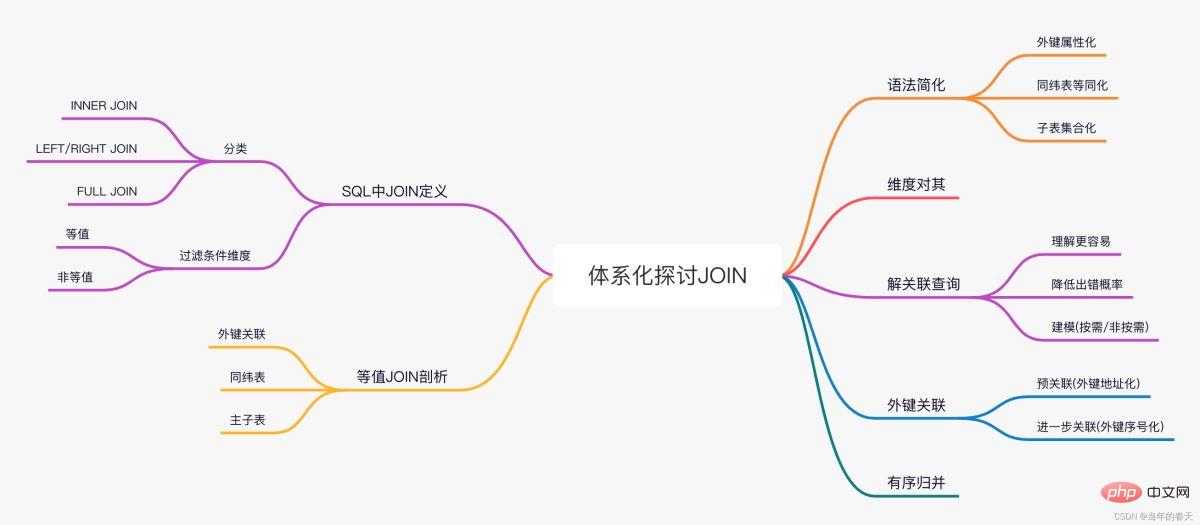
JOIN en SQL
Comment SQL comprend-il l'opération JOIN
Définition SQL de JOIN
Après avoir effectué un produit cartésien de deux ensembles (tables) puis filtré selon certaines conditions, la syntaxe écrite est A JOIN B ON… .
- Théoriquement, l'ensemble de résultats du produit cartésien devrait être un tuple composé de deux membres d'ensemble. Cependant, puisqu'un ensemble en SQL est une table, ses membres ont toujours des enregistrements de champ, et cela n'est pas pris en charge. un tuple dont les membres sont des enregistrements, de sorte que l'ensemble de résultats est simplement traité en une collection de nouveaux enregistrements formés en fusionnant les champs des enregistrements dans les deux tables.
- C'est aussi le sens originel du mot JOIN en anglais (c'est-à-dire relier les champs de deux enregistrements), et ne signifie pas multiplication (produit cartésien). Cependant, le fait que le membre produit cartésien soit compris comme un tuple ou comme un enregistrement d'un champ fusionné n'affecte pas notre discussion ultérieure.
Définition JOIN
- La définition de JOIN ne spécifie pas la forme des conditions de filtre. En théorie, tant que l'ensemble de résultats est un sous-ensemble du produit cartésien de deux ensembles sources, il s'agit d'une opération JOIN raisonnable.
- Exemple : Supposons que l'ensemble A={1,2},B={1,2,3}, le résultat de A JOIN B ON A
Classification JOIN
- Nous appelons la condition de filtre pour l'égalité un JOIN d'équivalence, et le cas où il ne s'agit pas d'une connexion d'équivalence est appelé un JOIN de non-équivalence. Parmi ces deux exemples, le premier est un JOIN non équivalent et le second est un JOIN d’équivalence.
Equal JOIN
- La condition peut être composée de plusieurs équations avec une relation ET, la forme syntaxique est A JOIN B ON A.ai=B.bi AND…, où ai et bi sont respectivement les champs de A et B .
- Les programmeurs expérimentés savent qu'en réalité, la grande majorité des JOIN sont des JOIN équivalents, les JOIN non équivalents sont beaucoup plus rares et la plupart des cas peuvent être convertis en JOIN équivalents, nous nous concentrons donc ici sur les JOIN équivalents, et dans les discussions ultérieures, nous utilisez principalement des tables et des enregistrements au lieu d'ensembles et de membres comme exemples.
Classification selon les règles de traitement des valeurs nulles
- Selon les règles de traitement des valeurs nulles, le JOIN équivalent strict est également appelé INNER JOIN et peut également être dérivé de LEFT JOIN et FULL JOIN. Il existe trois situations (RIGHT JOIN peut. Compris comme l'association inverse de LEFT JOIN, ce n'est plus un type distinct).
- Quand on parle de JOIN, il est généralement divisé en situations un-à-un, un-à-plusieurs, plusieurs-à-un et plusieurs-à-plusieurs en fonction du nombre d'enregistrements associés (c'est-à-dire des tuples qui se rencontrent les conditions de filtrage) dans les deux tableaux. Ces termes généraux sont introduits dans les documents SQL et les bases de données, ils ne seront donc pas répétés ici.
Implémentation de JOIN
Manière stupide
- La façon la plus simple de penser est de faire un parcours dur selon la définition, sans faire de distinction entre JOIN égal et JOIN non équivalent. Supposons que la table A ait n enregistrements et que la table B ait m enregistrements. Pour calculer A JOIN B ON A.a=B.b, la complexité du parcours dur sera de nm, c'est-à-dire que nm fois de calcul des conditions de filtrage seront effectuées.
- Évidemment, cet algorithme sera plus lent. Cependant, les outils de reporting prenant en charge plusieurs sources de données utilisent parfois cette méthode lente pour réaliser l'association, car l'association des ensembles de données dans le rapport (c'est-à-dire les conditions de filtre dans JOIN) sera divisée et définie dans l'expression de calcul de la cellule. On ne voit plus qu'il s'agit d'une opération JOIN entre plusieurs ensembles de données, nous ne pouvons donc utiliser que la méthode de parcours pour calculer ces expressions associées.
Optimisation de la base de données pour JOIN
- Pour un JOIN équivalent, la base de données utilise généralement l'algorithme HASH JOIN. C'est-à-dire que les enregistrements de la table d'association sont divisés en plusieurs groupes en fonction de la valeur HASH de leur clé d'association (correspondant à des champs égaux dans les conditions de filtre, c'est-à-dire A.a et B.b), et des enregistrements avec la même valeur HASH sont regroupés en un seul groupe. Si la plage de valeurs HASH est 1...k, alors les deux tables A et B sont divisées en k sous-ensembles A1,...,Ak et B1,...,Bk. La valeur HASH de la clé associée a enregistrée dans Ai est i, et la valeur HASH de la clé associée b enregistrée dans Bi est également i. Ensuite, établissez simplement une connexion transversale entre Ai et Bi respectivement.
- Parce que les valeurs des champs doivent être différentes lorsque le HASH est différent, lorsque i!=j, les enregistrements dans Ai ne peuvent pas être liés aux enregistrements dans Bj. Si le nombre d'enregistrements de Ai est ni et le nombre d'enregistrements de Bi est mi, alors le nombre de calculs de la condition de filtre est SUM(ni*mi). Dans le cas le plus moyen, ni=n/k, mi=. m/k, alors la complexité totale n'est que de 1/k de la méthode de traversée dure originale, ce qui peut améliorer efficacement les performances informatiques !
- Donc, si vous souhaitez accélérer le rapport de corrélation multi-sources de données, vous devez également effectuer la corrélation lors de la phase de préparation des données, sinon les performances chuteront fortement lorsque la quantité de données est légèrement plus grande.
- Cependant, la fonction HASH ne garantit pas toujours un fractionnement uniforme. Si vous n'avez pas de chance, un certain groupe peut être particulièrement grand et l'effet d'amélioration des performances sera bien pire. Et vous ne pouvez pas utiliser de fonctions HASH trop complexes, sinon le calcul du HASH prendra plus de temps.
- Lorsque la quantité de données dépasse la mémoire, la base de données utilisera la méthode de tas HASH, qui est une généralisation de l'algorithme HASH JOIN. Parcourez le tableau A et le tableau B, divisez les enregistrements en plusieurs petits sous-ensembles en fonction de la valeur HASH de la clé associée et mettez-les en cache dans la mémoire externe, appelée Heaping. Effectuez ensuite les opérations de JOINTURE de mémoire entre les tas correspondants. De la même manière, lorsque la valeur HASH est différente, la valeur de la clé doit également être différente et l'association doit se produire entre les tas correspondants. De cette manière, le JOIN du big data est converti en JOIN de plusieurs small data.
- Mais de la même manière, la fonction HASH a un problème de chance. Il peut arriver qu'un certain tas soit trop volumineux pour être chargé dans la mémoire. À ce moment-là, un deuxième tas HASH peut être exécuté, c'est-à-dire qu'une fonction HASH est utilisée. pour gérer ce groupe. Pour les grands tas, exécutez à nouveau l'algorithme de tas HASH. Par conséquent, l'opération JOIN de la mémoire externe peut être mise en cache plusieurs fois et ses performances de fonctionnement sont quelque peu incontrôlables.
JOIN sous un système distribué
- C'est similaire à faire JOIN sous un système distribué. Les enregistrements sont distribués à chaque machine de nœud en fonction de la valeur HASH de la clé associée, appelée action Shuffle, et puis chaque JOIN se fait sur une machine autonome.
- Lorsqu'il y a de nombreux nœuds, le retard causé par le volume de transmission du réseau compensera les avantages du partage de tâches multi-machines, de sorte que les systèmes de bases de données distribuées ont généralement une limite sur le nombre de nœuds. Après avoir atteint la limite, davantage de nœuds pourront. Je n'obtiens pas de meilleures performances.
Anatomie du JOIN équivalent
Trois types de JOIN équivalent :
Association de clé étrangère
- Un certain champ de la table A est associé au champ de clé primaire de la table B (la soi-disant association de champ est ce qui a été dit dans la section précédente) Les conditions de filtre de valeur égale JOIN doivent correspondre à des champs égaux). Le tableau A est appelé table de faits et le tableau B est appelé table de dimensions. Le champ de la table A qui est associé à la clé primaire de la table B est appelé la clé étrangère de A pointant vers B, et B est également appelé la table de clé étrangère de A.
- La clé primaire mentionnée ici fait référence à la clé primaire logique, c'est-à-dire un champ (groupe) avec une valeur unique dans le tableau qui peut être utilisé pour enregistrer de manière unique un certain enregistrement. Il ne doit pas nécessairement avoir une clé primaire. établi sur la table de la base de données.
- La table de clé étrangère est une relation plusieurs-à-un, et il n'y a que JOIN et LEFT JOIN, et FULL JOIN est très rare.
- Cas typiques : tableau de transactions de produits et tableau d'informations sur les produits.
- Évidemment, les associations de clés étrangères sont asymétriques. Les emplacements des tables de faits et des tables de dimensions ne peuvent pas être interchangés.
Même table de dimensions
- La clé primaire de la table A est liée à la clé primaire de la table B. A et B s'appellent même table de dimensions. Les tables de même dimension ont une relation un-à-un, et JOIN, LEFT JOIN et FULL JOIN existeront tous. Cependant, dans la plupart des solutions de conception de structure de données, FULL JOIN est relativement rare.
- Cas typiques : table des employés et table des managers.
- Les tables de même dimension sont symétriques, et les deux tables ont le même statut. Les tableaux de même dimension forment également une relation d'équivalence. A et B sont des tableaux de même dimension, et B et C sont des tableaux de même dimension. Alors A et C sont également des tableaux de même dimension.
Sous-table principale
- La clé primaire de la table A est liée à certaines des clés primaires de la table B. A est appelée table principale, et B est appelée sous-table. La table maître-enfant a une relation un-à-plusieurs. Il n'y a que JOIN et LEFT JOIN, mais il n'y aura pas de FULL JOIN.
- Cas typique : commande et détails de la commande.
- Les tableaux principaux et sous-tableaux sont également asymétriques et ont des directions claires.
- Dans le système conceptuel de SQL, il n'y a pas de distinction entre les tables de clés étrangères et les tables maître-enfant. Du point de vue SQL, plusieurs-à-un et un-à-plusieurs n'ont que des directions d'association différentes et sont essentiellement les mêmes. même chose. En effet, les commandes peuvent également être comprises comme des tables de clés étrangères contenant les détails des commandes. Cependant, nous souhaitons les distinguer ici, et différents moyens seront utilisés pour simplifier la syntaxe et optimiser les performances à l'avenir.
- Nous disons que ces trois types de JOIN ont couvert la grande majorité des situations de JOIN équivalentes. On peut même dire que presque tous les JOIN équivalents ayant une signification commerciale appartiennent à ces trois catégories. réduisant sa plage d'adaptation.
- Après avoir soigneusement examiné ces trois JOIN, nous avons constaté que toutes les associations impliquent des clés primaires et qu'il n'y a pas de situation plusieurs-à-plusieurs. Cette situation peut-elle être ignorée ?
- Oui ! Les JOINs équivalents plusieurs à plusieurs n’ont presque aucune signification commerciale.
- Si les champs associés lors de la jointure de deux tables n'impliquent aucune clé primaire, une situation plusieurs-à-plusieurs se produira, et dans ce cas, il y aura presque certainement une table plus grande qui utilisera ces deux tables comme tables de dimension de relation. Par exemple, lorsque la table des étudiants et la table des sujets sont dans JOIN, il y aura une table de notes qui utilise la table des étudiants et la table des sujets comme tables de dimensions. Un JOIN avec uniquement la table des étudiants et la table des sujets n'a aucune signification commerciale.
- Lorsque vous trouvez une situation plusieurs-à-plusieurs lors de l'écriture d'une instruction SQL, il y a une forte probabilité que l'instruction soit mal écrite ! Ou il y a un problème avec les données ! Cette règle est très efficace pour éliminer les erreurs JOIN.
- Cependant, nous avons dit « presque » sans utiliser une déclaration tout à fait certaine, c'est-à-dire que plusieurs à plusieurs auront également un sens commercial dans de très rares cas. Par exemple, lors de l'utilisation de SQL pour implémenter la multiplication matricielle, un JOIN équivalent plusieurs à plusieurs se produira. La méthode d'écriture spécifique peut être complétée par le lecteur.
- La définition JOIN du produit cartésien puis le filtrage sont en effet très simples, et la connotation simple aura une plus grande extension, et peut inclure plusieurs à plusieurs JOIN équivalents et même JOIN non équivalents. Cependant, la connotation trop simple ne peut pas refléter pleinement les caractéristiques de fonctionnement de l'équivalent JOIN le plus courant. Cela se traduira par l'impossibilité de tirer parti de ces fonctionnalités lors de l'écriture du code et de la mise en œuvre des opérations. Lorsque l'opération est plus complexe (impliquant de nombreuses tables associées et situations imbriquées), elle est très difficile à écrire ou à optimiser. En utilisant pleinement ces fonctionnalités, nous pouvons créer des formes d'écriture plus simples et obtenir des performances informatiques plus efficaces, ce qui sera progressivement expliqué dans le contenu suivant.
- Plutôt que de définir une opération sous une forme plus générale afin d'inclure des cas rares, il serait plus raisonnable de définir ces cas comme une autre opération.
Simplification de la syntaxe JOIN
Comment utiliser la fonctionnalité selon laquelle les associations impliquent des clés primaires pour simplifier l'écriture du code JOIN ?
Attribution de clé étrangère
Exemple, avec les deux tableaux suivants :
employee 员工表
id 员工编号
name 姓名
nationality 国籍
department 所属部门
department 部门表
id 部门编号
name 部门名称
manager 部门经理Copier après la connexion
- Les clés primaires de la table Employee et de la table Department sont toutes deux le champ id. Le champ Department de la table Employee est une clé étrangère pointant vers la table Department. Le champ Manager de la table Department est une clé étrangère pointant vers. la table des employés (car le manager est aussi un employé). Il s’agit d’une conception de structure de table très conventionnelle.
- Maintenant, nous voulons nous demander : quels employés américains ont un manager chinois ? Écrit en SQL, il s'agit d'une instruction JOIN à trois tables :
SELECT A.*
FROM employee A
JOIN department B ON A.department=B.id
JOIN employee C ON B.manager=C.id
WHERE A.nationality='USA' AND C.nationality='CHN'
Copier après la connexion
- Tout d'abord, FROM employé est utilisé pour obtenir des informations sur l'employé, puis la table employé doit être JOINée avec département pour obtenir les informations sur le service de l'employé, puis la La table du département doit être jointe à la table des employés JOIN doit obtenir les informations du responsable, donc la table des employés doit participer deux fois à JOIN. Elle doit recevoir un alias dans l'instruction SQL pour la distinguer, et la phrase entière devient compliquée et. difficile à comprendre.
- Si nous comprenons directement le champ de clé étrangère comme son enregistrement de table de dimensions associé, nous pouvons l'écrire d'une autre manière :
SELECT * FROM employee
WHERE nationality='USA' AND department.manager.nationality='CHN'
Copier après la connexion
Bien sûr, ce n'est pas une instruction SQL standard.
- La partie en gras dans la deuxième phrase indique la « nationalité du chef de service » du salarié actuel. Après avoir compris le champ de clé étrangère comme l'enregistrement de la table de dimensions, le champ de la table de dimensions est compris comme l'attribut de la clé étrangère Department. Manager est le "responsable du département", et ce champ est toujours étranger. entrez département, puis le champ d'enregistrement de la table de dimensions correspondant peut continuer à être compris comme son attribut, et il y aura également département.manager.nationalité, c'est-à-dire "la nationalité du responsable du département auquel il appartient".
- Attribution de clé étrangère : Cette méthode de compréhension de type objet est l'attribution de clé étrangère, qui est évidemment beaucoup plus naturelle et intuitive que la méthode de compréhension cartésienne par filtrage de produits. JOIN des tables de clés étrangères n'implique pas la multiplication des deux tables. Le champ de clé étrangère est uniquement utilisé pour trouver l'enregistrement correspondant dans la table de clés de dimension et n'implique pas du tout d'opérations avec des caractéristiques de multiplication telles que le produit cartésien.
- Nous avons convenu plus tôt que la clé associée dans la table de dimensions de l'association de clé étrangère doit être la clé primaire. De cette manière, l'enregistrement de la table de dimensions associé au champ de clé étrangère de chaque enregistrement dans la table de faits est unique, c'est-à-dire. disons, chaque enregistrement de la table des employés. Le champ département est associé de manière unique à un enregistrement dans la table des départements, et le champ responsable de chaque enregistrement de la table des départements est également associé de manière unique à un enregistrement de la table des employés. Cela garantit que pour chaque enregistrement de la table des employés, Department.manager.nationality a une valeur unique et peut être clairement défini.
- Cependant, il n'y a pas d'accord de clé primaire dans la définition SQL de JOIN. Si elle est basée sur des règles SQL, les enregistrements de la table de dimensions associés aux clés étrangères dans la table de faits ne peuvent pas être déterminés comme étant uniques et peuvent être associés à. plusieurs enregistrements. Pour les employés En termes d'enregistrements de table, département.manager.nationalité ne peut pas être utilisé s'il n'est pas clairement défini.
- En fait, ce type d'écriture de style objet est très courant dans les langages de haut niveau(tels que C, Java). Dans ces langages, les données sont stockées sous forme d'objets. La valeur du champ département dans la table des employés est simplement un objet, pas un nombre. En fait, la valeur de clé primaire de nombreuses tables elle-même n'a aucune signification commerciale. Il s'agit simplement de distinguer les enregistrements, et le champ de clé étrangère sert simplement à trouver l'enregistrement correspondant dans la table de dimension. Si le champ de clé étrangère est directement un objet, il n'est pas nécessaire d'utiliser la numérotation. Cependant, SQL ne peut pas prendre en charge ce mécanisme de stockage et nécessite l'aide de nombres.
- Nous avons dit que l'association de clé étrangère est asymétrique, c'est-à-dire que la table de faits et la table de dimensions ne sont pas égales, et que les champs de la table de dimensions ne peuvent être trouvés qu'en fonction de la table de faits, et non l'inverse.
Égalisation des tables de même dimension
La situation des tables de même dimension est relativement simple Commençons par l'exemple Il y a deux tables :
employee 员工表
id 员工编号
name 姓名
salary 工资
...
manager 经理表
id 员工编号
allowance 岗位津贴
....Copier après la connexion
- Les clés primaires des deux tables sont id, le gestionnaire. est également un employé, et les deux tables partagent la même chose. Pour les numéros d'employés, les managers auront plus d'attributs que les employés ordinaires, et ils seront stockés dans une autre table de manager.
- Maintenant, nous voulons calculer le revenu total (plus les allocations) de tous les employés (y compris les managers). JOIN sera toujours utilisé lors de l'écriture en SQL :
SELECT employee.id, employee.name, employy.salary+manager.allowance
FROM employee
LEFT JOIN manager ON employee.id=manager.id
Copier après la connexion
Pour deux tables un-à-un, on peut en fait simplement les considérer comme une seule table :
SELECT id,name,salary+allowance
FROM employee
Copier après la connexion
- De même, selon notre accord, la même dimension lors de la jointure de tables , les deux tables sont liées selon la clé primaire et les enregistrements correspondants correspondent de manière unique. Salaire + indemnité est calculable de manière unique pour chaque enregistrement de la table des employés, et il n'y aura aucune ambiguïté. Cette simplification est appelée égalisation de table de même dimension.
- La relation entre les tables de même dimension est égale et les champs d'autres tables de même dimension peuvent être référencés à partir de n'importe quelle table.
Collection de sous-tables
Les commandes et les détails de la commande sont des sous-tables principales typiques :
Orders 订单表
id 订单编号
customer 客户
date 日期
...
OrderDetail 订单明细
id 订单编号
no 序号
product 订购产品
price 价格
...Copier après la connexion
La clé primaire de la table Orders est id, la clé primaire de la table OrderDetail est (id, no) et la clé primaire de le premier fait partie du second.
Maintenant, nous voulons calculer le montant total de chaque commande. Écrit en SQL, cela ressemblerait à ceci :
SELECT Orders.id, Orders.customer, SUM(OrderDetail.price)
FROM Orders
JOIN OrderDetail ON Orders.id=OrderDetail.id
GROUP BY Orders.id, Orders.customer
Copier après la connexion
- 要完成这个运算,不仅要用到JOIN,还需要做一次GROUP BY,否则选出来的记录数太多。
- 如果我们把子表中与主表相关的记录看成主表的一个字段,那么这个问题也可以不再使用JOIN以及GROUP BY:
SELECT id, customer, OrderDetail.SUM(price)
FROM Orders
Copier après la connexion
- 与普通字段不同,OrderDetail被看成Orders表的字段时,其取值将是一个集合,因为两个表是一对多的关系。所以要在这里使用聚合运算把集合值计算成单值。这种简化方式称为子表集合化。
- 这样看待主子表关联,不仅理解书写更为简单,而且不容易出错。
- 假如Orders表还有一个子表用于记录回款情况:
OrderPayment 订单回款表
id 订单编号
date 回款日期
amount 回款金额
....Copier après la connexion
- 我们现在想知道那些订单还在欠钱,也就是累计回款金额小于订单总金额的订单。
- 简单地把这三个表JOIN起来是不对的,OrderDetail和OrderPayment会发生多对多的关系,这就错了(回忆前面提过的多对多大概率错误的说法)。这两个子表要分别先做GROUP,再一起与Orders表JOIN起来才能得到正确结果,会写成子查询的形式:
SELECT Orders.id, Orders.customer,A.x,B.y
FROM Orders
LEFT JOIN ( SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN ( SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x>B.yCopier après la connexion
如果我们继续把子表看成主表的集合字段,那就很简单了:
SELECT id,customer,OrderDetail.SUM(price) x,OrderPayment.SUM(amount) y
FROM Orders WHERE x>y
Copier après la connexion
- 这种写法也不容易发生多对多的错误。
- 主子表关系是不对等的,不过两个方向的引用都有意义,上面谈了从主表引用子表的情况,从子表引用主表则和外键表类似。
- 我们改变对JOIN运算的看法,摒弃笛卡尔积的思路,把多表关联运算看成是稍复杂些的单表运算。这样,相当于把最常见的等值JOIN运算的关联消除了,甚至在语法中取消了JOIN关键字,书写和理解都要简单很多。
维度对齐语法
我们再回顾前面的双子表例子的SQL:
SELECT Orders.id, Orders.customer, A.x, B.y
FROM Orders
LEFT JOIN (SELECT id,SUM(price) x FROM OrderDetail GROUP BY id ) A
ON Orders.id=A.id
LEFT JOIN (SELECT id,SUM(amount) y FROM OrderPayment GROUP BY id ) B
ON Orders.id=B.id
WHERE A.x > B.yCopier après la connexion
- 那么问题来了,这显然是个有业务意义的JOIN,它算是前面所说的哪一类呢?
- 这个JOIN涉及了表Orders和子查询A与B,仔细观察会发现,子查询带有GROUP BY id的子句,显然,其结果集将以id为主键。这样,JOIN涉及的三个表(子查询也算作是个临时表)的主键是相同的,它们是一对一的同维表,仍然在前述的范围内。
- 但是,这个同维表JOIN却不能用前面说的写法简化,子查询A,B都不能省略不写。
- 可以简化书写的原因:我们假定事先知道数据结构中这些表之间的关联关系。用技术术语的说法,就是知道数据库的元数据(metadata)。而对于临时产生的子查询,显然不可能事先定义在元数据中了,这时候就必须明确指定要JOIN的表(子查询)。
- 不过,虽然JOIN的表(子查询)不能省略,但关联字段总是主键。子查询的主键总是由GROUP BY产生,而GROUP BY的字段一定要被选出用于做外层JOIN;并且这几个子查询涉及的子表是互相独立的,它们之间不会再有关联计算了,我们就可以把GROUP动作以及聚合式直接放到主句中,从而消除一层子查询:
SELECT Orders.id, Orders.customer, OrderDetail.SUM(price) x, OrderParyment.SUM(amount) y
FROM Orders
LEFT JOIN OrderDetail GROUP BY id
LEFT JOIN OrderPayment GROUP BY id
WHERE A.x > B.y
Copier après la connexion
- 这里的JOIN和SQL定义的JOIN运算已经差别很大,完全没有笛卡尔积的意思了。而且,也不同于SQL的JOIN运算将定义在任何两个表之间,这里的JOIN,OrderDetail和OrderPayment以及Orders都是向一个共同的主键id对齐,即所有表都向某一套基准维度对齐。而由于各表的维度(主键)不同,对齐时可能会有GROUP BY,在引用该表字段时就会相应地出现聚合运算。OrderDetail和OrderPayment甚至Orders之间都不直接发生关联,在书写运算时当然就不用关心它们之间的关系,甚至不必关心另一个表是否存在。而SQL那种笛卡尔积式的JOIN则总要找一个甚至多个表来定义关联,一旦减少或修改表时就要同时考虑关联表,增大理解难度。
- 维度对齐:这种JOIN称即为维度对齐,它并不超出我们前面说过的三种JOIN范围,但确实在语法描述上会有不同,这里的JOIN不象SQL中是个动词,却更象个连词。而且,和前面三种基本JOIN中不会或很少发生FULL JOIN的情况不同,维度对齐的场景下FULL JOIN并不是很罕见的情况。
- 虽然我们从主子表的例子抽象出维度对齐,但这种JOIN并不要求JOIN的表是主子表(事实上从前面的语法可知,主子表运算还不用写这么麻烦),任何多个表都可以这么关联,而且关联字段也完全不必要是主键或主键的部分。
- 设有合同表,回款表和发票表:
Contract 合同表
id 合同编号
date 签订日期
customer 客户
price 合同金额
...
Payment 回款表
seq 回款序号
date 回款日期
source 回款来源
amount 金额
...
Invoice 发票表
code 发票编号
date 开票日期
customer 客户
amount 开票金额
...Copier après la connexion
现在想统计每一天的合同额、回款额以及发票额,就可以写成:
SELECT Contract.SUM(price), Payment.SUM(amount), Invoice.SUM(amount) ON date
FROM Contract GROUP BY date
FULL JOIN Payment GROUP BY date
FULL JOIN Invoice GROUP BY date
Copier après la connexion
- 这里需要把date在SELECT后单独列出来表示结果集按日期对齐。
- 这种写法,不必关心这三个表之间的关联关系,各自写各自有关的部分就行,似乎这几个表就没有关联关系,把它们连到一起的就是那个要共同对齐的维度(这里是date)。
- 这几种JOIN情况还可能混合出现。
- 继续举例,延用上面的合同表,再有客户表和销售员表
Customer 客户表
id 客户编号
name 客户名称
area 所在地区
...
Sales 销售员表
id 员工编号
name 姓名
area 负责地区
...Copier après la connexion
- 其中Contract表中customer字段是指向Customer表的外键。
- 现在我们想统计每个地区的销售员数量及合同额:
SELECT Sales.COUNT(1), Contract.SUM(price) ON area
FROM Sales GROUP BY area
FULL JOIN Contract GROUP BY customer.area
Copier après la connexion
- 维度对齐可以和外键属性化的写法配合合作。
- 这些例子中,最终的JOIN都是同维表。事实上,维度对齐还有主子表对齐的情况,不过相对罕见,我们这里就不深入讨论了。
- 另外,目前这些简化语法仍然是示意性,需要在严格定义维度概念之后才能相应地形式化,成为可以解释执行的句子。
- 我们把这种简化的语法称为DQL(Dimensional Query Languange),DQL是以维度为核心的查询语言。我们已经将DQL在工程上做了实现,并作为润乾报表的DQL服务器发布出来,它能将DQL语句翻译成SQL语句执行,也就是可以在任何关系数据库上运行。
- 对DQL理论和应用感兴趣的读者可以关注乾学院上发布的论文和相关文章。
解决关联查询
多表JOIN问题
- 我们知道,SQL允许用WHERE来写JOIN运算的过滤条件(回顾原始的笛卡尔积式的定义),很多程序员也习惯于这么写。
- 当JOIN表只有两三个的时候,那问题还不大,但如果JOIN表有七八个甚至十几个的时候,漏写一个JOIN条件是很有可能的。而漏写了JOIN条件意味着将发生多对多的完全叉乘,而这个SQL却可以正常执行,会有以下两点危害:
- 一方面计算结果会出错:回忆一下以前说过的,发生多对多JOIN时,大概率是语句写错了
- 另一方面,如果漏写条件的表很大,笛卡尔积的规模将是平方级的,这极有可能把数据库直接“跑死”!
简化JOIN运算好处:
- 一个直接的效果显然是让语句书写和理解更容易
- 外键属性化、同维表等同化和子表集合化方案直接消除了显式的关联运算,也更符合自然思维
- 维度对齐则可让程序员不再关心表间关系,降低语句的复杂度
- 简化JOIN语法的好处不仅在于此,还能够降低出错率,采用简化后的JOIN语法,就不可能发生漏写JOIN条件的情况了。因为对JOIN的理解不再是以笛卡尔积为基础,而且设计这些语法时已经假定了多对多关联没有业务意义,这个规则下写不出完全叉乘的运算。
- 对于多个子表分组后与主表对齐的运算,在SQL中要写成多个子查询的形式。但如果只有一个子表时,可以先JOIN再GROUP,这时不需要子查询。有些程序员没有仔细分析,会把这种写法推广到多个子表的情况,也先JOIN再GROUP,可以避免使用子查询,但计算结果是错误的。
- 使用维度对齐的写法就不容易发生这种错误了,无论多少个子表,都不需要子查询,一个子表和多个子表的写法完全相同。
关联查询
- 重新看待JOIN运算,最关键的作用在于实现关联查询。
- 当前BI产品是个热门,各家产品都宣称能够让业务人员拖拖拽拽就完成想要的查询报表。但实际应用效果会远不如人意,业务人员仍然要经常求助于IT部门。造成这个现象的主要原因在于大多数业务查询都是有过程的计算,本来也不可能拖拽完成。但是,也有一部分业务查询并不涉及多步过程,而业务人员仍然难以完成。
- 这就是关联查询,也是大多数BI产品的软肋。在之前的文章中已经讲过为什么关联查询很难做,其根本原因就在于SQL对JOIN的定义过于简单。
- 结果,BI产品的工作模式就变成先由技术人员构建模型,再由业务人员基于模型进行查询。而所谓建模,就是生成一个逻辑上或物理上的宽表。也就是说,建模要针对不同的关联需求分别实现,我们称之为按需建模,这时候的BI也就失去敏捷性了。
- 但是,如果我们改变了对JOIN运算的看法,关联查询可以从根本上得到解决。回忆前面讲过的三种JOIN及其简化手段,我们事实上把这几种情况的多表关联都转化成了单表查询,而业务用户对于单表查询并没有理解障碍。无非就是表的属性(字段)稍复杂了一些:可能有子属性(外键字段指向的维表并引用其字段),子属性可能还有子属性(多层的维表),有些字段取值是集合而非单值(子表看作为主表的字段)。发生互相关联甚至自我关联也不会影响理解(前面的中国经理的美国员工例子就是互关联),同表有相同维度当然更不碍事(各自有各自的子属性)。
- 在这种关联机制下,技术人员只要一次性把数据结构(元数据)定义好,在合适的界面下(把表的字段列成有层次的树状而不是常规的线状),就可以由业务人员自己实现JOIN运算,不再需要技术人员的参与。数据建模只发生于数据结构改变的时刻,而不需要为新的关联需求建模,这也就是非按需建模,在这种机制支持下的BI才能拥有足够的敏捷性。
外键预关联
- 我们再来研究如何利用JOIN的特征实现性能优化,这些内容的细节较多,我们挑一些易于理解的情况来举例,更完善的连接提速算法可以参考乾学院上的《性能优化》图书和SPL学习资料中的性能优化专题文章。
全内存下外键关联情况
设有两个表:
customer 客户信息表
key 编号
name 名称
city 城市
...
orders 订单表
seq 序号
date 日期
custkey 客户编号
amount 金额
...Copier après la connexion
- 其中orders表中的custkey是指向customer表中key字段的外键,key是customer表的主键。
- 现在我们各个城市的订单总额(为简化讨论,就不再设定条件了),用SQL写出来:
SELECT customer.city, SUM(orders.amount)
FROM orders
JOIN customer ON orders.custkey=customer.key
GROUP BY customer.city
Copier après la connexion
- 数据库一般会使用HASH JOIN算法,需要分别两个表中关联键的HASH值并比对。
- 我们用前述的简化的JOIN语法(DQL)写出这个运算:
SELECT custkey.city, SUM(amount)
FROM orders
GROUP BY custkey.city
Copier après la connexion
- 这个写法其实也就预示了它还可以有更好的优化方案,下面来看看怎样实现。
- 如果所有数据都能够装入内存,我们可以实现外键地址化。
- 将事实表orders中的外键字段custkey,转换成维表customer中关联记录的地址,即orders表的custkey的取值已经是某个customer表中的记录,那么就可以直接引用记录的字段进行计算了。
- 用SQL无法描述这个运算的细节过程,我们使用SPL来描述、并用文件作为数据源来说明计算过程:
| |
A |
| 1 |
=file(“customer.btx”).import@b() |
| 2 |
>A1.keys@i(key) |
| 3 |
=file(“orders.btx”).import@b() |
| 4 |
>A3.switch(custkey,A1) |
| 5 |
=A3.groups(custkey.city;sum(amount)) |
- A1 lit la table client et A2 définit la clé primaire et crée un index pour la table client.
- A3 lit la table de commande. L'action de A4 est de convertir la clé étrangère du champ de clé de A3 en l'enregistrement correspondant de A1. Après exécution, la clé de champ de la table de commande deviendra un enregistrement de la table client. A2 crée un index pour accélérer le changement, car la table de faits est généralement beaucoup plus grande que la table de dimensions et cet index peut être réutilisé plusieurs fois.
- A5 peut effectuer un résumé de groupe. Lors de la traversée de la table de commande, puisque la valeur du champ custkey est désormais un enregistrement, vous pouvez directement utiliser l'opérateur . pour référencer son champ, et custkey.city peut être exécuté normalement.
- Après avoir terminé l'action de commutation dans A4, le contenu stocké dans le champ custkey de la table de faits A3 en mémoire est déjà l'adresse d'un enregistrement dans la table de dimensions A1. Cette action est appelée adressage de clé étrangère. À ce stade, lors du référencement des champs de la table de dimension, ils peuvent être récupérés directement sans utiliser la valeur de clé étrangère pour rechercher dans A1. Cela équivaut à obtenir les champs de la table de dimension dans un temps constant, évitant ainsi le calcul et la comparaison des valeurs HASH.
- Cependant, A2 utilise généralement la méthode HASH pour créer l'index de clé primaire et calcule la valeur HASH de la clé. Lorsque A4 convertit l'adresse, il calcule également la valeur HASH de la clé client et la compare avec la table d'index HASH de A2. . Si une seule opération de corrélation est effectuée, la quantité de calcul du schéma d'adresse et du schéma de segmentation HASH traditionnel est fondamentalement la même, et il n'y a aucun avantage fondamental.
- Mais la différence est que si les données peuvent être placées en mémoire, cette adresse peut être réutilisée une fois convertie, c'est-à-dire que A1 en A4 ne doit être fait qu'une seule fois, et il n'est pas nécessaire de faire l'opération associée. sur ces deux champs la prochaine fois. Une fois les valeurs de HASH calculées et comparées, les performances peuvent être grandement améliorées.
- Pouvoir faire cela tire parti du caractère unique de l'association de clé étrangère dans la table de dimensions mentionnée précédemment. Une valeur de champ de clé étrangère ne correspondra qu'à un seul enregistrement de la table de dimension, et chaque clé client peut être convertie en sa clé unique correspondante. Dossier A1. Cependant, si nous continuons à utiliser la définition de JOIN en SQL, nous ne pouvons pas supposer que la clé étrangère indique l'unicité de l'enregistrement, et cette représentation ne peut pas être utilisée. De plus, SQL n'enregistre pas le type de données de l'adresse. Par conséquent, la valeur HASH doit être calculée et comparée pour chaque association.
- De plus, s'il y a plusieurs clés étrangères dans la table de faits pointant vers plusieurs tables de dimensions, la solution JOIN segmentée HASH traditionnelle ne peut en analyser qu'une à la fois. S'il y a plusieurs JOIN, plusieurs actions doivent être effectuées après chaque association. Les résultats intermédiaires doivent être conservés pour le prochain tour, le processus de calcul est beaucoup plus complexe et les données seront parcourues plusieurs fois. Face à plusieurs clés étrangères, le schéma d'adressage de clé étrangère n'a besoin de parcourir la table de faits qu'une seule fois, sans résultats intermédiaires, et le processus de calcul est beaucoup plus clair.
- Un autre point est que la mémoire est à l'origine très adaptée au calcul parallèle, mais l'algorithme HASH segmenté JOIN n'est pas facile à paralléliser. Même si les données sont segmentées et que les valeurs HASH sont calculées en parallèle, les enregistrements avec la même valeur HASH doivent être regroupés pour le prochain cycle de comparaison, et une préemption des ressources partagées se produira, ce qui sacrifiera de nombreux avantages du calcul parallèle. Dans le modèle JOIN à clé étrangère, le statut des deux tables liées n'est pas égal. Après avoir clairement distingué la table de dimensions et la table de faits, des calculs parallèles peuvent être effectués en segmentant simplement la table de faits.
- Après avoir transformé la technologie de segmentation HASH en référence au schéma d'attributs de clé étrangère, elle peut également améliorer la capacité d'analyser plusieurs clés étrangères à la fois et de les paralléliser dans une certaine mesure. Certaines bases de données peuvent mettre en œuvre cette optimisation au niveau de l'ingénierie. Cependant, cette optimisation n'est pas un gros problème lorsqu'il n'y a que deux tables JOIN. Lorsqu'il y a de nombreuses tables et diverses JOIN mélangées, il n'est pas facile pour la base de données d'identifier quelle table doit être utilisée comme table de faits pour le parcours parallèle. et d'autres tables doivent être parcourues en parallèle lors de la création d'un index HASH en tant que table de dimensions, l'optimisation n'est pas toujours efficace. Par conséquent, nous constatons souvent que lorsque le nombre de tables JOIN augmente, les performances diminuent fortement (cela se produit souvent lorsqu'il y a quatre ou cinq tables et que l'ensemble de résultats n'augmente pas de manière significative). Une fois le concept de clé étrangère introduit à partir du modèle JOIN, lorsque ce type de JOIN est spécifiquement traité, la table de faits et la table de dimensions peuvent toujours être distinguées. Plus de tables JOIN n'entraîneront qu'une diminution linéaire des performances.
- La base de données en mémoire est actuellement une technologie en vogue, mais l'analyse ci-dessus montre qu'il est difficile pour une base de données en mémoire utilisant le modèle SQL d'effectuer rapidement des opérations de JOIN !
Autre association de clé étrangère
- Nous continuons à discuter de la clé étrangère JOIN et continuons à utiliser l'exemple de la section précédente.
- Lorsque la quantité de données est trop importante pour tenir dans la mémoire, la méthode d'adressage susmentionnée n'est plus efficace, car l'adresse pré-calculée ne peut pas être enregistrée dans la mémoire externe.
- De manière générale, la table de dimensions pointée par la clé étrangère a une capacité plus petite, tandis que la table de faits croissante est beaucoup plus grande. Si la mémoire peut toujours contenir la table de dimensions, nous pouvons utiliser la méthode de pointage temporaire pour gérer les clés étrangères. . curseur@b()
3
| >A2.switch(custkey,A1:#) |
|
4
=A2.groups(custkey.city;sum(amount))
|
- Les deux premières étapes sont les mêmes que celles de la mémoire complète. La conversion d'adresse à l'étape 4 est effectuée pendant la lecture, et les résultats de la conversion ne peuvent pas être conservés et réutilisés. Le HASH et la comparaison devront être recalculés lors de la prochaine association. temps, et les performances seront inférieures à celles de la solution à mémoire complète. En termes de quantité de calcul, par rapport à l'algorithme HASH JOIN, il y a un calcul de moins de la valeur HASH de la table de dimension. Si cette table de dimension est souvent réutilisée, ce sera quelque peu avantageux, mais comme la table de dimension est relativement petite, l'avantage global n'est pas grand. Cependant, cet algorithme présente également les caractéristiques d'un algorithme à mémoire complète qui peut analyser toutes les clés étrangères à la fois et est facile à paralléliser. Dans les scénarios réels, il présente toujours un plus grand avantage en termes de performances que l'algorithme HASH JOIN.
Sérialisation de clé étrangère
Sur la base de cet algorithme, nous pouvons également réaliser une variante : la sérialisation de clé étrangère.
Si nous pouvons convertir les clés primaires de la table de dimensions en nombres naturels à partir de 1, alors nous pouvons utiliser le numéro de série pour localiser directement l'enregistrement de la table de dimensions, sans avoir besoin de calculer et de comparer la valeur HASH, afin de pouvoir obtenir une adresse similaire dans les performances de la mémoire complète.
| |
A |
| 1 |
=file(“customer.btx”).import@b() |
| 2 |
=file(“orders.btx”).cursor@b () |
| 3 |
>A2.switch(custkey,A1:#) |
| 4 |
=A2.groups(custkey.city;sum(amount)) |
- Lorsque la clé primaire de la table de dimensions est le numéro de série, il n'est pas nécessaire de faire la deuxième étape de construction de l'index HASH.
- La sérialisation des clés étrangères équivaut essentiellement à l'adressage dans la mémoire externe. Cette solution nécessite de convertir les champs de clé étrangère de la table de faits en numéros de série, ce qui est similaire au processus d'adressage lors des opérations en mémoire complète. Ce précalcul peut également être réutilisé. Il convient de noter que lorsque des changements majeurs se produisent dans la table de dimensions, les champs de clé étrangère de la table de faits doivent être triés de manière synchrone, sinon ils risquent d'être mal alignés. Cependant, la fréquence des modifications générales de la table de dimensions est faible et la plupart des actions sont des ajouts et des modifications plutôt que des suppressions. Il n'existe donc pas beaucoup de situations dans lesquelles la table de faits doit être réorganisée. Pour plus de détails sur l'ingénierie, vous pouvez également vous référer aux informations de la Cadre Academy.
- SQL utilise le concept d'ensembles non ordonnés. Même si l'on sérialise les clés étrangères à l'avance, la base de données ne peut pas profiter de cette fonctionnalité. Le mécanisme de positionnement rapide des numéros de série ne peut pas être utilisé sur des ensembles non ordonnés. et la base de données ne sait pas si les clés étrangères sont sérialisées, mais la valeur HASH et la comparaison seront toujours calculées.
- Que se passe-t-il si le tableau des dimensions est trop grand pour tenir dans la mémoire ?
- Si nous analysons attentivement l'algorithme ci-dessus, nous constaterons que l'accès à la table de faits est continu, mais que l'accès à la table de dimensions est aléatoire. Lorsque nous avons discuté des caractéristiques de performances des disques durs auparavant, nous avons mentionné que la mémoire externe n'est pas adaptée à l'accès aléatoire, de sorte que les tables de dimensions de la mémoire externe ne peuvent plus utiliser l'algorithme ci-dessus.
- Les tables de dimensions dans la mémoire externe peuvent être triées et stockées par clé primaire à l'avance, afin que nous puissions continuer à utiliser la fonctionnalité selon laquelle la clé associée de la table de dimensions est la clé primaire pour optimiser les performances.
- Si la table de faits est petite et peut être chargée en mémoire, alors l'utilisation de clés étrangères pour associer les enregistrements de la table de dimensions deviendra en fait une opération de recherche de stockage externe (par lots). Tant qu'il existe un index sur la clé primaire sur la table de dimensions, il peut être recherché rapidement. Cela peut éviter de parcourir de grandes tables de dimensions et obtenir de meilleures performances. Cet algorithme peut également résoudre plusieurs clés étrangères simultanément. SQL ne fait pas de distinction entre les tables de dimensions et les tables de faits. Face à deux tables, une grande et une petite, le HASH JOIN optimisé n'effectuera plus de mise en cache du tas. La petite table sera généralement lue dans la mémoire et la grande table le sera. traversé.Cela entraînera toujours S'il y a une action de parcours d'une table de grande dimension, les performances seront bien pires que l'algorithme de recherche de mémoire externe que nous venons de mentionner.
- Si la table de faits est également très grande, vous pouvez utiliser l'algorithme d'empilement unilatéral. Étant donné que la table de dimensions a été classée par clé associée (c'est-à-dire clé primaire), elle peut être facilement divisée logiquement en plusieurs segments et extraire la valeur limite de chaque segment (la valeur maximale et minimale de la clé primaire de chaque segment). , puis divisez la table de faits en piles en fonction de ces valeurs limites, chaque pile peut être associée à chaque segment de la table de dimensions. Dans le processus, seul le côté table de faits doit être physiquement mis en cache, et la table de dimensions n'a pas besoin d'être physiquement mise en cache. De plus, la fonction HASH n'est pas utilisée et la segmentation est utilisée directement. être malchanceux et provoquer une segmentation secondaire du tas, les performances sont contrôlables. L'algorithme de tas HASH de la base de données fera un cache de tas physique pour les deux grandes tables, c'est-à-dire un tas bilatéral. Il peut également arriver que la fonction HASH soit malchanceuse, ce qui entraîne un tas secondaire et que les performances soient trop mauvaises par rapport au tas unilatéral. et toujours incontrôlable.
Utilisez la puissance des clusters pour résoudre des problèmes de tables de grande dimension.
- Si la mémoire d'une machine ne peut pas être hébergée, vous pouvez obtenir plusieurs machines supplémentaires pour l'héberger et stocker les tables de dimensions sur plusieurs machines segmentées par valeurs de clé primaire pour former une table de dimensions de cluster, puis vous peut continuer à utiliser l'algorithme de table de dimension de mémoire mentionné ci-dessus peut également obtenir les avantages d'analyser plusieurs clés étrangères en même temps et d'être facile à paralléliser. De même, les tables de dimensions de cluster peuvent également utiliser la technologie de sérialisation. Avec cet algorithme, la table de faits n'a pas besoin d'être transmise, la quantité de transmission réseau générée n'est pas importante et il n'est pas nécessaire de mettre en cache les données localement sur le nœud. Cependant, les tables de dimensions ne peuvent pas être distinguées sous le système SQL. La méthode de fractionnement HASH nécessite de mélanger les deux tables et la quantité de transmission réseau est beaucoup plus importante.
- Les détails de ces algorithmes sont encore quelque peu compliqués et ne peuvent pas être expliqués en détail ici en raison du manque d'espace. Les lecteurs intéressés peuvent consulter les informations sur Qian Academy.
Fusion ordonnée
Méthode d'accélération de l'optimisation des jointures pour les tables de même dimension et les tables maître-enfant
- Nous avons discuté plus tôt de la complexité de calcul de l'algorithme HASH JOIN (c'est-à-dire le nombre de comparaisons de clés associées) est SUM (nimi), qui est supérieur au full. La complexité du parcours nm est beaucoup plus petite, mais cela dépend de la chance de la fonction HASH.
- Si les deux tables sont triées pour les clés associées, nous pouvons alors utiliser l'algorithme de fusion pour traiter l'association. La complexité à ce moment est n+m ; lorsque n et m sont tous deux grands (généralement beaucoup plus grands que HASH La plage de valeurs). de la fonction), ce nombre sera également bien inférieur à la complexité de l'algorithme HASH JOIN. Il existe de nombreux documents présentant les détails de l’algorithme de fusion, je n’entrerai donc pas dans les détails ici.
- Cependant, cette méthode ne peut pas être utilisée lorsque la clé étrangère JOIN est utilisée, car la table de faits peut avoir plusieurs champs de clé étrangère qui doivent participer à l'association, et il est impossible de commander la même table de faits pour plusieurs champs en même temps. temps.
- La même table de dimensions et la même table maître-enfant peuvent être utilisées ! Étant donné que les tables de même dimension et les tables maître-enfant sont toujours liées à la clé primaire ou à une partie de la clé primaire, nous pouvons trier à l'avance les données de ces tables liées en fonction de leurs clés primaires. Bien que le coût du tri soit plus élevé, il est ponctuel. Une fois le tri terminé, vous pouvez toujours utiliser l'algorithme de fusion pour implémenter JOIN à l'avenir, et les performances peuvent être considérablement améliorées.
- Cela profite toujours de la fonctionnalité selon laquelle la clé associée est la clé primaire (et ses parties).
- La fusion ordonnée est particulièrement efficace pour le big data.Les tables principales et sous-tables telles que les commandes et leurs détails sont des tables de faits croissantes, qui s'accumulent souvent jusqu'à atteindre une taille très importante au fil du temps et peuvent facilement dépasser la capacité de la mémoire.
- L'algorithme de tas HASH pour le stockage externe du Big Data doit générer beaucoup de cache. Les données sont lues deux fois et écrites une fois dans la mémoire externe, ce qui entraîne une surcharge d'E/S élevée. Dans l'algorithme de fusion, les données des deux tables ne doivent être lues qu'une seule fois, sans écriture. Non seulement la quantité de calcul du CPU est réduite, mais la quantité d'E/S de la mémoire externe est également considérablement réduite. De plus, très peu de mémoire est nécessaire pour exécuter l'algorithme de fusion. Tant que plusieurs enregistrements de cache sont conservés en mémoire pour chaque table, cela n'affectera guère les besoins en mémoire des autres tâches simultanées. Le tas HASH nécessite une mémoire plus grande et lit plus de données à chaque fois pour réduire le nombre de fois de tas.
- SQL utilise l'opération JOIN définie par le produit cartésien et ne fait pas de distinction entre les types JOIN. Sans supposer que certains JOIN sont toujours destinés aux clés primaires, il n'y a aucun moyen de profiter de cette fonctionnalité au niveau de l'algorithme et ne peut être optimisé qu'au niveau de l'algorithme. le niveau ingénierie. Certaines bases de données vérifieront si la table de données est physiquement ordonnée pour les champs associés et, si c'est le cas, utiliseront l'algorithme de fusion. Cependant, les bases de données relationnelles basées sur le concept d'ensembles non ordonnés ne garantiront pas délibérément l'ordre physique des données et de nombreuses opérations. détruira la fusion. Conditions de mise en œuvre de l’algorithme. L'utilisation d'index peut permettre d'obtenir un ordre logique des données, mais l'efficacité du parcours sera toujours considérablement réduite lorsque les données sont physiquement désordonnées.
- Le principe de la fusion ordonnée est de trier les données en fonction de la clé primaire, et ce type de données est souvent ajouté en continu. En principe, elles doivent être triées à nouveau après chaque ajout, et nous connaissons le coût du tri du Big Data. est généralement très élevé. Cela entraînera-t-il l'ajout des données ? En fait, le processus d'ajout de données puis d'ajout est également une fusion ordonnée. Les nouvelles données sont triées séparément et fusionnées avec les données historiques ordonnées. La complexité est linéaire, ce qui équivaut à réécrire toutes les données une fois, contrairement au Big conventionnel. le tri des données nécessite une écriture et une lecture en cache. Effectuer certaines actions d'optimisation en ingénierie peut également éliminer le besoin de tout réécrire à chaque fois, améliorant ainsi encore l'efficacité de la maintenance. Ceux-ci sont introduits dans la Cadre Academy.
Parallélisme segmenté
- L'avantage de la fusion ordonnée est qu'il est facile de paralléliser par segments.
- Les ordinateurs modernes disposent tous de processeurs multicœurs et les disques durs SSD disposent également de fortes capacités de concurrence. L'utilisation du calcul parallèle multithread peut améliorer considérablement les performances. Cependant, il est difficile d'atteindre le parallélisme avec la technologie de tas HASH traditionnelle. Lorsque plusieurs threads effectuent un tas HASH, ils doivent écrire des données sur un certain tas en même temps, ce qui provoque des conflits de ressources partagées et dans la deuxième étape, lors de la réalisation du tas. l'association d'un certain groupe de tas, une grande quantité d'argent sera consommée, ne permet pas de mettre en œuvre de plus grandes quantités de parallélisme.
- Lors de l'utilisation d'une fusion ordonnée pour réaliser un calcul parallèle, les données doivent être divisées en plusieurs segments. La segmentation d'une seule table est relativement simple, mais deux tables liées doivent être alignées simultanément lors de la segmentation, sinon les données des deux tables seront mal alignées. pendant la fusion, et le résultat correct ne peut pas être obtenu. Les résultats du calcul et l'ordre des données peuvent garantir une segmentation d'alignement synchrone haute performance.
- Divisez d'abord la table principale (pour les tables de même dimension, utilisez la plus grande, les autres discussions ne seront pas affectées) en plusieurs segments égaux, lisez la valeur de clé primaire du premier enregistrement de chaque segment, puis utilisez ces clés valeurs au sous-tableau Utilisez la méthode de bissection pour trouver le positionnement (car il est également ordonné) pour obtenir le point de segmentation du sous-tableau. Cela garantit que les segments des tables principales et des sous-tables sont alignés de manière synchrone.
- Étant donné que les valeurs clés sont dans l'ordre, les valeurs clés d'enregistrement dans chaque segment de la table principale appartiennent à un certain intervalle continu. Les enregistrements avec des valeurs clés en dehors de l'intervalle ne seront pas dans ce segment. les valeurs clés dans l'intervalle doivent être dans ce segment. Les valeurs clés d'enregistrement correspondant à la segmentation du tableau ont également cette fonctionnalité, donc un mauvais alignement ne se produira pas et aussi parce que les valeurs clés sont dans l'ordre ; , une recherche binaire efficace peut être effectuée dans le sous-tableau pour localiser rapidement le point de segmentation. Autrement dit, l’ordre des données garantit la rationalité et l’efficacité de la segmentation, afin que les algorithmes parallèles puissent être exécutés en toute confiance.
- Une autre caractéristique de la relation d'association de clé primaire entre maître et sous-tables est que la sous-table ne sera associée qu'à une seule table principale sur la clé primaire (en fait, il existe aussi des tables de même dimension, mais c'est plus facile à expliquer en utilisant la table principale-sous-table), et il n'y aura pas de multiples relations mutuelles sans rapport avec la table principale (il peut y avoir une table principale de tables principales). À ce stade, vous pouvez également utiliser le mécanisme de stockage intégré pour stocker les enregistrements de sous-table en tant que valeurs de champ de la table principale. De cette façon, d'une part, la quantité de stockage est réduite (la clé associée ne doit être stockée qu'une seule fois), et cela équivaut également à faire l'association à l'avance, et il n'est pas nécessaire de la comparer à nouveau. Pour le big data, de meilleures performances peuvent être obtenues.
- Nous avons implémenté les méthodes d'optimisation des performances ci-dessus dans esProc SPL et les avons appliquées dans des scénarios réels, et avons obtenu de très bons résultats. SPL est désormais open source. Les lecteurs peuvent se rendre sur les sites Web et forums officiels de la société Shusu ou de la société Runqian pour télécharger et obtenir plus d'informations.
Apprentissage recommandé : Tutoriel vidéo MySQL
|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



