Cet article vous apporte des connaissances pertinentes sur java, qui règle principalement les problèmes liés aux garbage collectors JVM, notamment les collecteurs Serial et Serial Old, les collecteurs ParNew, les collecteurs Parallel et Parallel Old, etc. Jetons un coup d'œil au contenu ci-dessous. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : "Tutoriel vidéo Java"
Concurrence et parallélisme
- Parallèle (Parallèle) : Parallel décrit la relation entre plusieurs threads de garbage collector, indiquant qu'il existe plusieurs threads de garbage collector en même temps À ce moment-là, les threads travaillent ensemble et, généralement, par défaut, le thread utilisateur est en attente à ce moment-là.
- Concurrence (concurrente) : la concurrence décrit la relation entre le thread du garbage collector et le thread utilisateur, indiquant que le thread du garbage collector et le thread utilisateur s'exécutent en même temps. Étant donné que le thread utilisateur n'est pas gelé, le programme peut toujours répondre aux demandes de service, mais comme le thread du garbage collector occupe une partie des ressources système, le débit de traitement de l'application sera affecté dans une certaine mesure à ce moment-là.
Classification des garbage collector
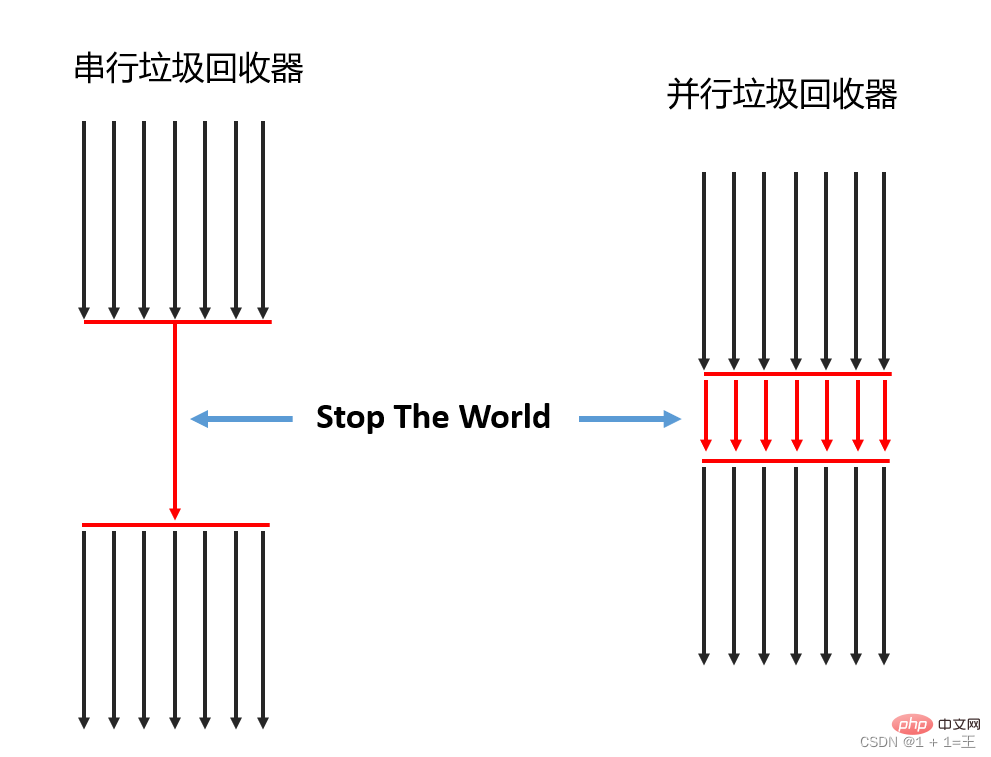
1. Selon le nombre de threads
Selon le nombre de threads (utilisés pour le garbage collection), il peut être divisé en garbage collector en série et garbage collector en parallèle.
- Récupérateur de mémoire série : un seul processeur est autorisé à effectuer des opérations de récupération de place en même temps. À ce stade, le thread de travail est suspendu jusqu'à ce que le travail de récupération de place soit terminé.
- Corbeille parallèle : plusieurs processeurs peuvent être utilisés pour effectuer simultanément la récupération de place.
2. Selon le mode de travail
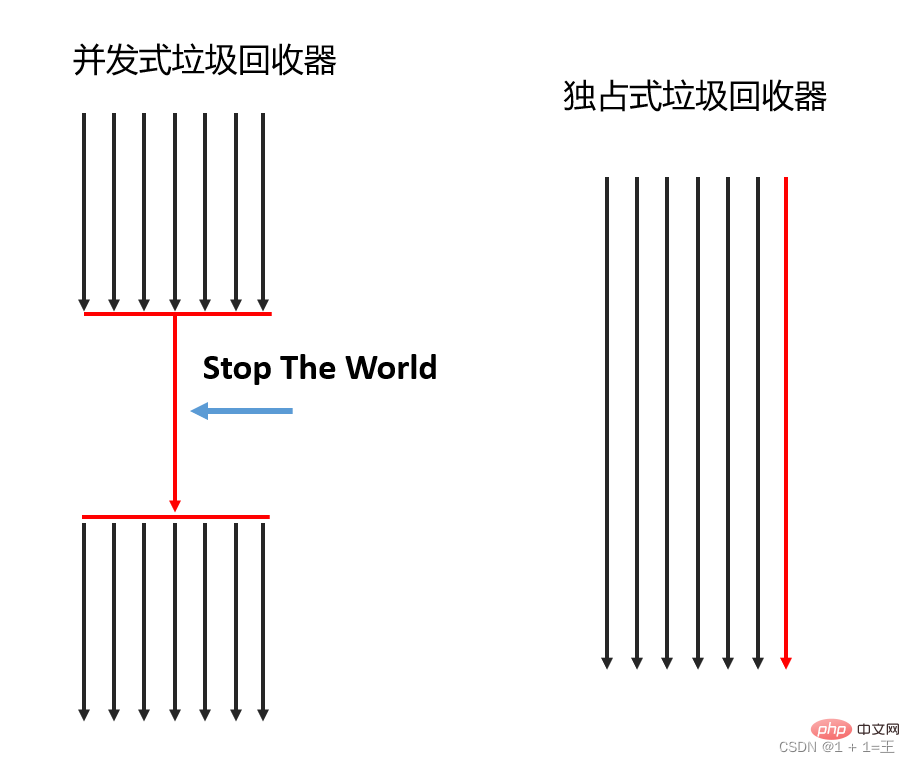
Selon le mode de travail, il peut être divisé en garbage collector simultané et garbage collector exclusif.
- Corbeille simultanée : un seul processeur est autorisé à effectuer des opérations de récupération de place en même temps. À ce stade, le thread de travail est suspendu jusqu'à ce que le travail de récupération de place soit terminé.
- Garbage collector exclusif : plusieurs processeurs peuvent être utilisés pour effectuer le garbage collection simultanément.
3. Selon la méthode de traitement de fragmentation
Selon le mode de fonctionnement, il peut être divisé en garbage collector compressé et garbage collector non compressé.
Le collecteur de déchets compressé compressera et organisera les objets survivants une fois le recyclage terminé pour éliminer les fragments après le recyclage.
7 éboueurs classiques
- Collecteur en série : serial, serial old
- Collecteur parallèle : ParNew, Parallel scavenge, Parallel old
- Concurrent collecteur : CMS, G1
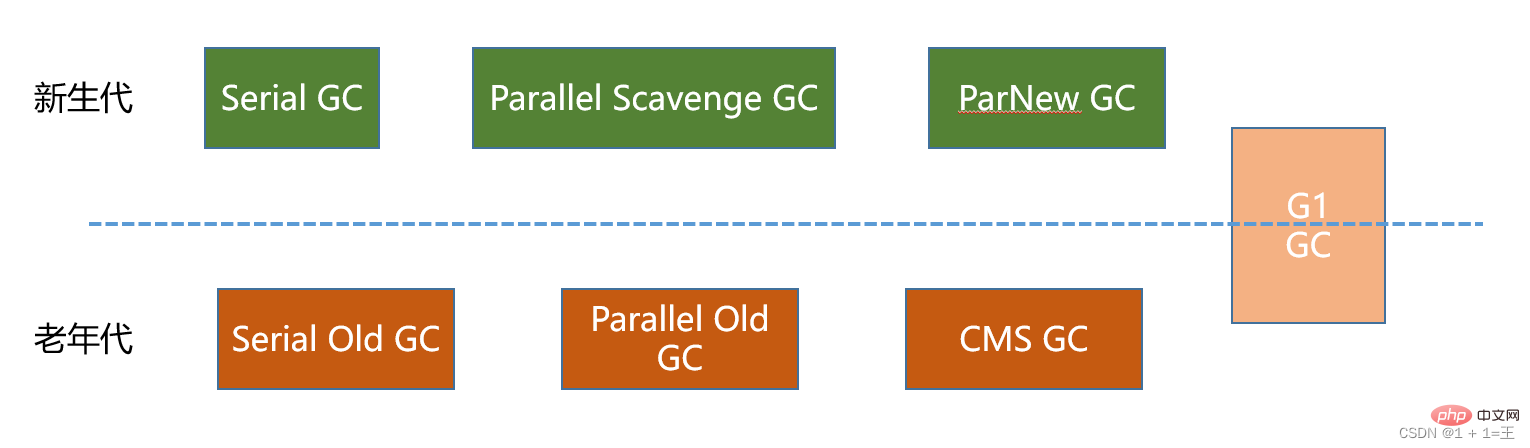
- Collecteur de nouvelle génération : série, ParNew, Parallel scavenge ;
- Collecteur d'ancienne génération : Serial old, Parallel old, CMS
- Full stack collector : G1 ; Ancien collecteur
Le collecteur série est le collecteur le plus basique et le plus ancien. Il était autrefois (avant JDK 1.3.1) le seul choix pour le collecteur nouvelle génération de la machine virtuelle HotSpot. Le collecteur série est un collecteur fonctionnel
à thread unique
Lorsqu'il effectue un garbage collection, tous les autres threads de travail doivent être suspendus jusqu'à ce qu'il termine la collecte.
Serial Old est la version ancienne génération du Serial collector.
Serial Collector utilise un algorithme de copie, un recyclage en série et un mécanisme "Stop The World"
pour effectuer la collecte des déchets.
Serial Old collector- marks : algorithme de compression, collecte en série et mécanisme « Stop The World »effectuent le ramassage des ordures.
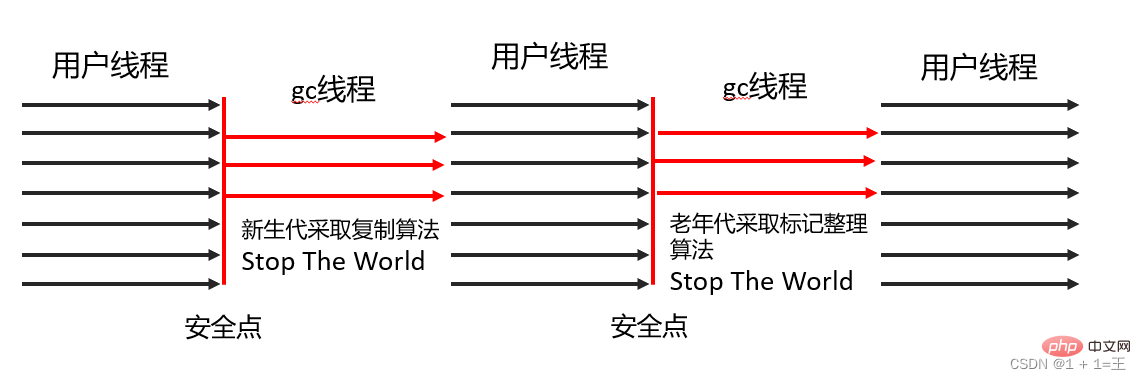
Le collecteur ParNew est essentiellement une version parallèle multithread du collecteur Serial En plus d'utiliser plusieurs threads pour le garbage collection en même temps, le reste du comportement inclut tous les paramètres de contrôle. disponibles pour le collecteur Serial, l'algorithme de collecte, Stop The World, les règles d'allocation des objets, la stratégie de recyclage, etc. sont totalement cohérents avec le collecteur Serial. 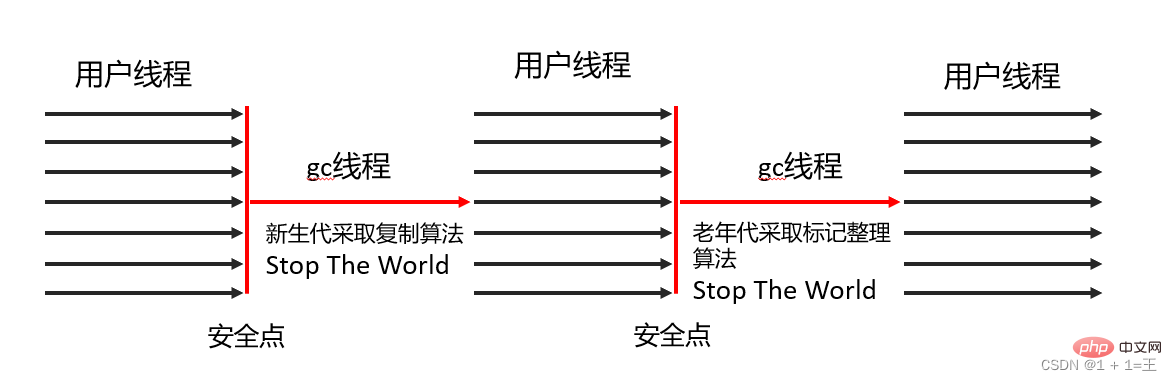
Collecteur Parallel et Parallel Old
Le collecteur Parallel Scavenge est également un collecteur de nouvelle génération. C'est également un collecteur basé sur l'algorithme de marquage-copie et est également un collecteur multithread qui peut collecter en parallèle. 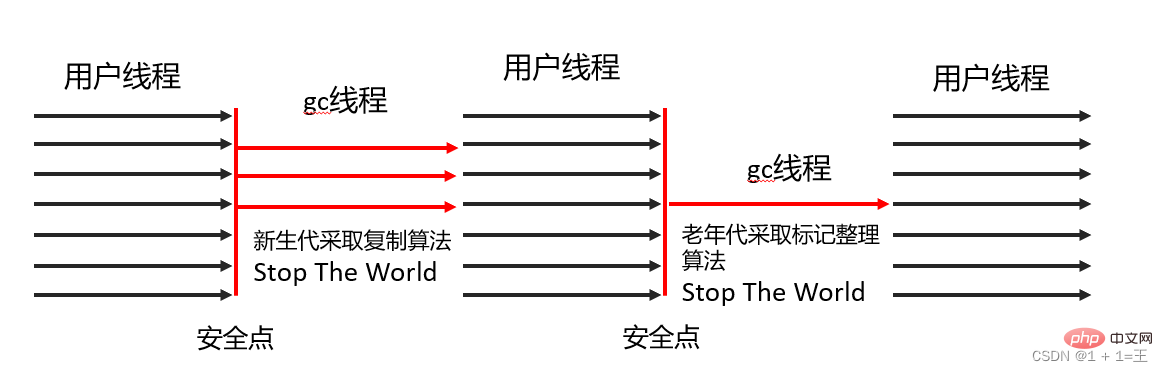 Différent du collecteur ParNew, l'objectif du collecteur de récupération Parallel est d'atteindre un
Différent du collecteur ParNew, l'objectif du collecteur de récupération Parallel est d'atteindre un
débit
contrôlable. Il est également appelé un ramasse-miettes axé sur le débit.
Débit : rapport entre le temps passé par le processeur à exécuter le code utilisateur et le temps total du processeur consommé.
Le haut débit permet d'utiliser le plus efficacement possible les ressources du processeur et d'accomplir les tâches informatiques du programme le plus rapidement possible. Il convient principalement aux tâches d'analyse qui fonctionnent en arrière-plan et ne nécessitent pas trop d'interaction.
Parallel Old est la version d'ancienne génération du collecteur Parallel Scavenge, prend en charge la collecte simultanée multithread et est implémentée sur la base de l'algorithme de marquage-collation.
CMS Collector
Le collecteur CMS (Concurrent Mark Sweep) est un collecteur qui vise à obtenir le temps de pause de recyclage le plus court.
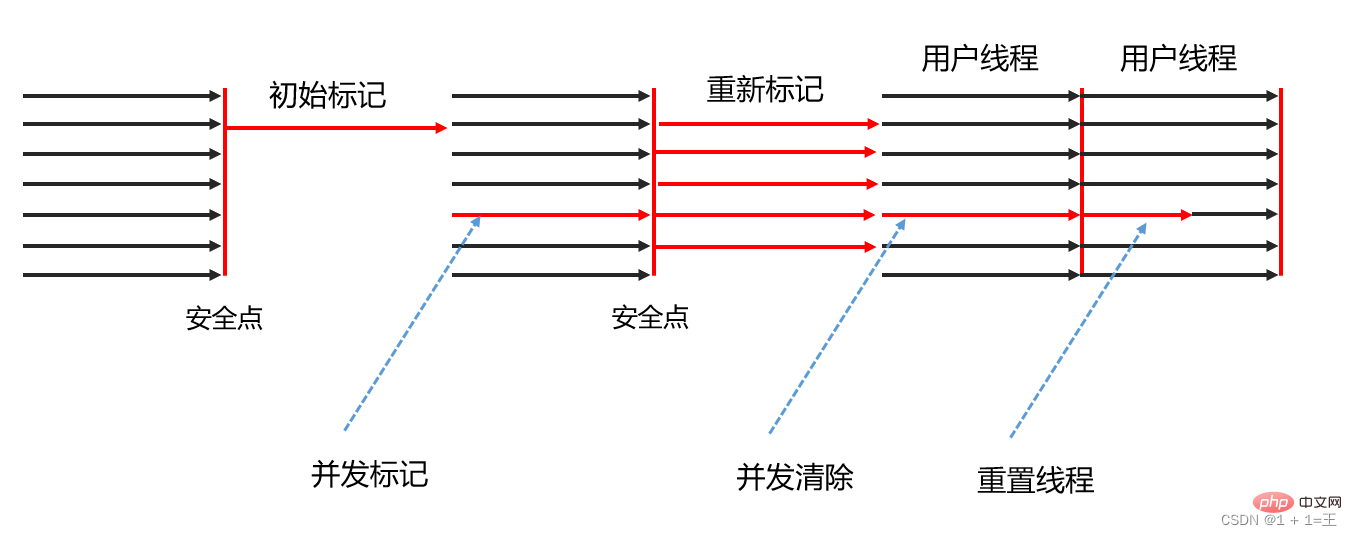
Le collecteur CMS est implémenté sur la base de l'algorithme mark-clear. Son fonctionnement peut être divisé en quatre étapes, dont :
- Marquage initial
Le marquage initial ne marque que les objets auxquels GC Roots peut directement s'associer, vitesse très élevée. rapide ;
- Marquage simultané
La phase de marquage simultané est le processus de parcours de l'ensemble du graphe d'objets à partir des objets directement associés de GC Roots. Ce processus prend beaucoup de temps mais ne nécessite pas l'arrêt du thread utilisateur et peut s'exécuter simultanément avec. le fil de récupération de place ; - Re-marquage
La phase de re-marquage consiste à corriger les enregistrements de marquage de la partie des objets qui ont changé en raison du fonctionnement continu du programme utilisateur pendant le marquage simultané. est généralement légèrement plus longue que la phase de marquage initiale, mais elle est également beaucoup plus courte que la phase de marquage simultanée
- Effacement simultané
Nettoie et supprime les objets morts jugés lors de la phase de marquage puisqu'il n'est pas nécessaire de déplacer les objets survivants ; , cette phase peut également être concurrente avec le thread utilisateur.
Le collecteur CMS est incapable de gérer les "Floating Garbage", et un "échec du mode simultané" peut échouer, ce qui peut conduire à un autre GC complet "Stop The World".
Pendant les phases de marquage simultané et de nettoyage simultané du CMS, le thread utilisateur est toujours en cours d'exécution. De nouveaux objets poubelles seront naturellement générés pendant l'exécution du programme, mais cette partie des objets poubelles apparaîtra une fois le processus de marquage terminé. être éliminés lors de la collecte en cours et devront être nettoyés lors de la prochaine collecte des déchets. Cette partie des déchets est appelée « déchets flottants ».
C'est aussi parce que le thread utilisateur doit continuer à s'exécuter pendant la phase de garbage collection, donc suffisamment d'espace mémoire doit être réservé pour que le thread utilisateur puisse l'utiliser, de sorte que le collecteur CMS ne peut pas attendre que l'ancienne génération soit presque complètement remplie comme les autres collecteurs. Afin de collecter à nouveau, un certain espace doit être réservé pour le fonctionnement du programme pendant la collecte simultanée.
CMS est un collecteur basé sur l'algorithme "mark-and-clear", ce qui signifie qu'un grand nombre de fragments d'espace sera généré à la fin de la collection. Lorsqu'il y aura trop de fragments d'espace, cela causera de gros problèmes. pour l'allocation d'objets volumineux.
Pourquoi ne pas utiliser un algorithme de compression de balises pour éviter la fragmentation ?
Parce que lorsque l'effacement simultané est utilisé pour organiser la mémoire avec la compression de marques, la mémoire utilisée par le thread utilisateur d'origine ne peut pas être utilisée. Pour garantir que le thread utilisateur continue de s'exécuter, le principe est que les ressources sur lesquelles il s'exécute ne sont pas affectées. La compression des drapeaux est plus adaptée aux scénarios « Stop The World ».
G1 (Garbage First) collector
Garbage First a été le pionnier de l'idée de conception du collecteur pour la collecte locale et du formulaire de disposition de la mémoire basé sur la région. Il s'agit d'un garbage collector principalement pour les applications côté serveur, principalement pour les multi-. équipement de base. Les machines dotées d'un processeur et d'une mémoire de grande capacité peuvent respecter le temps de pause du GC avec une très forte probabilité et ont également des caractéristiques de performances de débit élevées.
Pour tous les autres collecteurs avant le collecteur G1, la plage cible du garbage collection était soit l'intégralité de la nouvelle génération, l'intégralité de l'ancienne génération ou l'intégralité du tas Java. G1 peut former un ensemble de collecte pour n'importe quelle partie de la mémoire tas à recycler. Le critère de mesure n'est plus la génération à laquelle il appartient, mais quelle partie de la mémoire stocke la plus grande quantité de déchets et présente les plus grands avantages de recyclage. Caractéristiques du collecteur G1
1. Parallélisme et concurrence
Parallélisme : pendant le recyclage G1, plusieurs threads GC peuvent fonctionner en même temps et le thread utilisateur arrête le monde à ce moment-là.
- Concurrency : G1 a la capacité de s'exécuter en alternance avec l'application, et une partie du travail peut être exécutée en même temps que l'application. Par conséquent, d'une manière générale, l'application ne sera pas complètement bloquée pendant toute la phase de recyclage.
-
2. Collecte par générations
- G1 est toujours conçu selon la théorie des collections générationnelles, mais sa disposition de mémoire de tas est très évidemment différente des autres collecteurs : G1 n'insiste plus sur une taille fixe et un nombre fixe de divisions de zone générationnelles, mais contigu Le tas Java est divisé en plusieurs régions indépendantes (régions) de taille égale. Chaque région peut servir d'espace Eden, d'espace Survivant ou d'espace d'ancienne génération de la nouvelle génération, selon les besoins. Le collectionneur peut utiliser différentes stratégies pour traiter les régions qui jouent des rôles différents, de sorte que les objets nouvellement créés et les objets anciens qui ont survécu pendant un certain temps et ont survécu à plusieurs collections puissent obtenir de bons résultats de collecte.
- Region possède également un type spécial de Humongousregion, qui est spécialement utilisé pour stocker de gros objets. G1 estime que tant que la taille d'un objet dépasse la moitié de la capacité d'une région, il peut être déterminé comme un objet de grande taille.
3. Intégration spatiale
- G1 utilise la région comme unité de base lors du recyclage de la mémoire et utilise un algorithme de copie entre les régions, mais dans l'ensemble, il peut être considéré comme un algorithme de compression de marques.
4. Modèle de temps de pause prévisible
- Le collecteur G1 peut établir un modèle de temps de pause prévisible. Il utilise la région comme la plus petite unité d'un seul recyclage, c'est-à-dire que l'espace mémoire collecté à chaque fois est la région An. un multiple entier de la taille, de sorte qu'un garbage collection complet de l'ensemble du tas Java puisse être évité de manière planifiée.
- Le collecteur G1 suit la « valeur » de l'accumulation de déchets dans chaque région La valeur est la quantité d'espace obtenu pour le recyclage et la valeur d'expérience du temps requis pour le recyclage, puis maintient une liste de priorités en arrière-plan, à chaque fois en fonction de L'utilisateur définit le temps de pause de collecte autorisé et donne la priorité aux régions ayant la plus grande valeur de récupération.
- Cette méthode d'utilisation de la région pour diviser l'espace mémoire et le recyclage des régions prioritaires garantit que le collecteur G1 obtient la plus grande efficacité de collecte possible dans un temps limité.
- Le modèle de prédiction de pause est mis en œuvre sur la base théorique de la moyenne d'atténuation. Pendant le processus de récupération de place, le collecteur G1 enregistrera le temps de récupération de chaque région, le nombre de cartes sales dans la mémoire de chaque région et d'autres paramètres mesurables. Le coût des étapes est analysé et des informations statistiques telles que la moyenne, l'écart type et le niveau de confiance sont obtenues. Utilisez ensuite ces informations pour prédire quelles régions constitueront la collecte de recyclage si le recyclage commence maintenant afin que les revenus les plus élevés puissent être obtenus sans dépasser le temps de pause prévu.
Comment résoudre les objets de référence inter-Régions qui existent dans Région ?
Utilisez des jeux de mémoire pour éviter d'analyser l'intégralité du tas en tant que racines GC. Chaque région conserve son propre jeu de mémoire. Ces jeux de mémoire enregistrent les pointeurs pointés par d'autres régions et marquent les plages de pages de carte de ces pointeurs. L'ensemble de mémoire de G1 est essentiellement une table de hachage en termes de structure de stockage. La clé est l'adresse de départ des autres régions, la valeur est un ensemble et les éléments qui y sont stockés sont les numéros d'index de la table de cartes.
Le processus de fonctionnement du collecteur G1
-
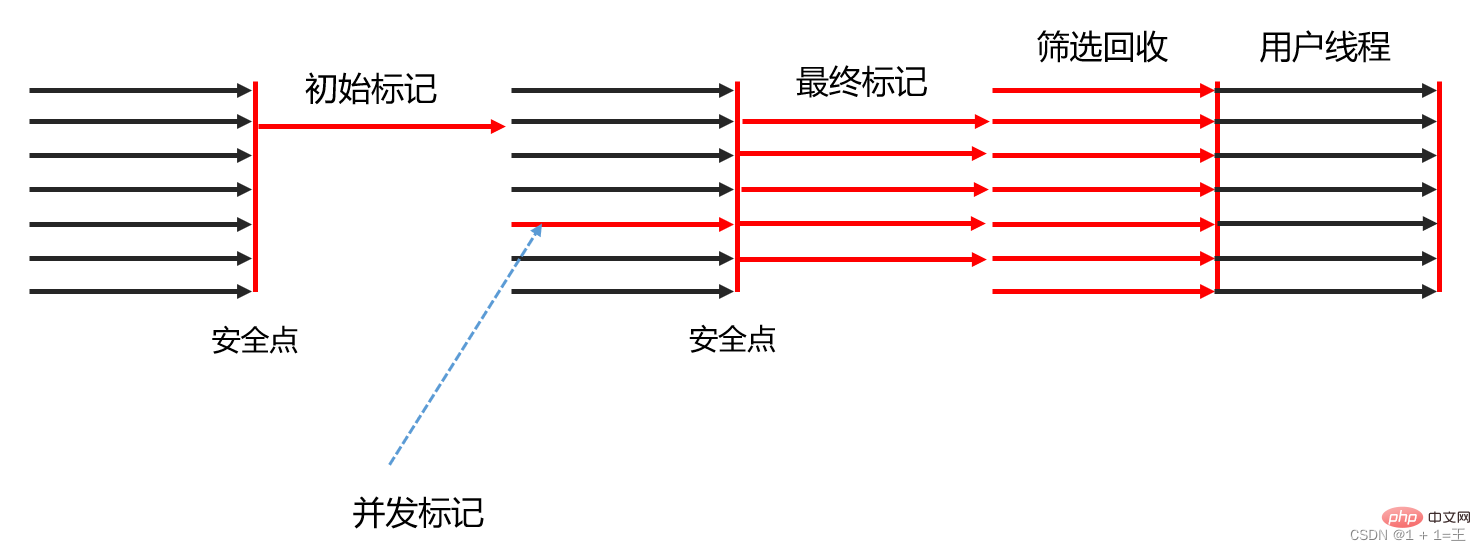
Marquage initial (Marquage initial) : marquez simplement les objets auxquels les racines GC peuvent être directement associées et modifiez la valeur du pointeur TAMS pour permettre la phase suivante des threads utilisateur pour s'exécuter simultanément. Peut allouer correctement de nouveaux objets dans les régions disponibles. Cette étape nécessite des pauses dans le thread, mais elle prend très peu de temps et s'effectue de manière synchrone pendant le GC mineur, de sorte que le collecteur G1 n'a en fait pas de pauses supplémentaires à ce stade.
-
Concurrent Marking (Concurrent Marking) : à partir de la racine GC, l'analyse d'accessibilité des objets dans le tas est effectuée et le graphe d'objets dans l'ensemble du tas est analysé de manière récursive pour trouver les objets à recycler à cette étape. prend beaucoup de temps, mais il peut être exécuté simultanément avec les programmes utilisateur. Une fois l'analyse du graphique d'objets terminée, les objets enregistrés par SATB qui ont des changements de référence pendant la concurrence doivent être retraités.
-
Marquage Final (Marquage Final) : Faites une autre courte pause sur le fil utilisateur pour traiter les derniers enregistrements SATB restants après la phase simultanée.
-
Criblage et recyclage (Comptage et évacuation des données en direct) : Responsable de la mise à jour des statistiques de la région, du tri de la valeur et du coût du recyclage de chaque région et de la formulation d'un plan de recyclage basé sur le temps de pause attendu par l'utilisateur. Vous pouvez sélectionner librement. autant que vous le souhaitez. La Région forme une collection de recyclage, puis copie les objets survivants de la partie de la Région décidée à être recyclée dans la Région vide, puis nettoie tout l'espace de l'ancienne Région. L'opération implique ici le déplacement d'objets vivants, qui doivent suspendre le thread utilisateur et être complétés par plusieurs threads collecteurs en parallèle.
Comparaison de 7 éboueurs classiques
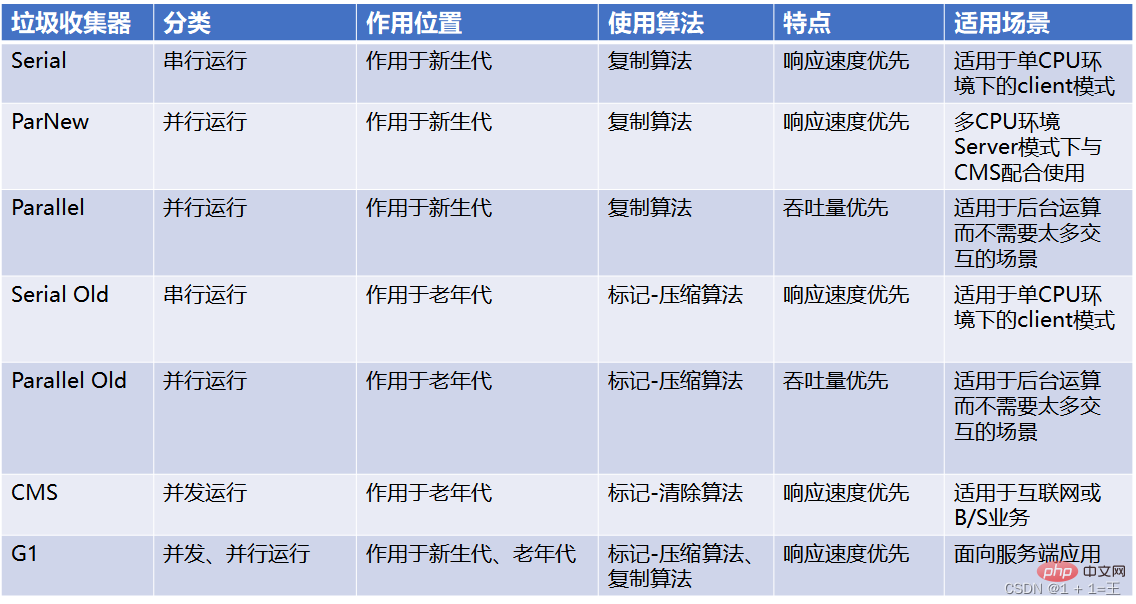
Combinaisons d'éboueurs
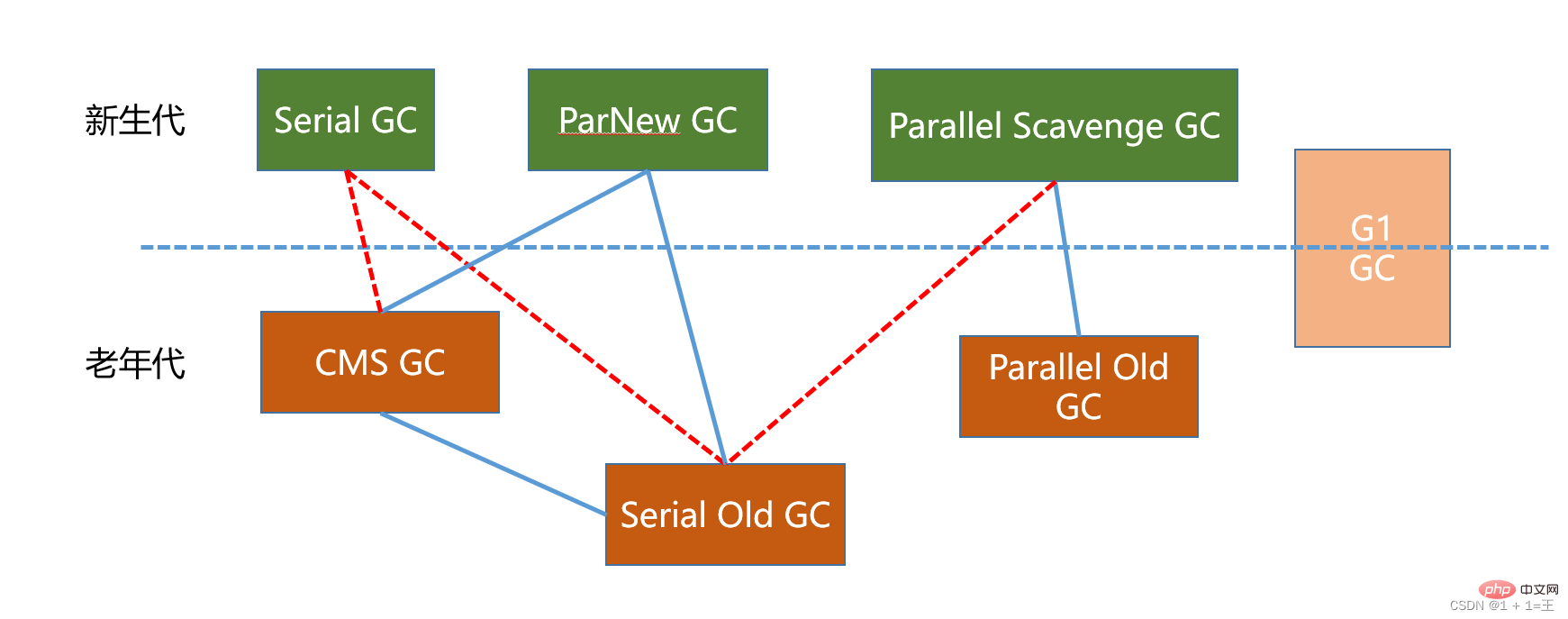
Récupérateur de déchets à faible latence
Collecteur Shenandoah
Shenandoah utilise également une disposition de mémoire de tas basée sur les régions. Il dispose également de régions gigantesques pour stocker les objets volumineux. La stratégie de recyclage par défaut consiste également à donner la priorité aux régions ayant la plus grande valeur de recyclage. Mais en termes de gestion de la mémoire tas, il présente au moins trois différences évidentes par rapport au G1.
- La phase de recyclage de G1 peut être parallélisée par plusieurs threads, mais elle ne peut pas être concurrente avec les threads utilisateur. Shenandoah prend en charge les algorithmes de tri simultanés.
- La collection générationnelle n'est pas utilisée par défaut. En d'autres termes, il n'y aura pas de région dédiée à la nouvelle génération ou la région de l'ancienne génération n'est pas implémentée. Cela ne signifie pas que la collection générationnelle n'a aucune valeur pour Shenandoah. rapport coût-efficacité, en le plaçant à une priorité inférieure en fonction de considérations liées à la charge de travail.
- Shenandoah a abandonné l'ensemble de mémoire qui consommait beaucoup de mémoire et de ressources informatiques à maintenir dans G1, et a utilisé à la place une structure de données globale appelée « matrice de connexion » pour enregistrer les relations de référence entre régions, réduisant ainsi l'ensemble de mémoire lors du traitement des relations inter-régions. pointeurs de génération. La consommation de maintenance réduit également la probabilité de problèmes de pseudo-partage. La matrice de connexion peut être simplement comprise comme un tableau bidimensionnel. S'il y a un objet dans la Région N pointant vers la Région M, une marque sera placée dans les N lignes et M colonnes du tableau. Lors du recyclage, ce tableau pourra être placé. utilisé pour déterminer quelles régions ont des citations croisées.
Le processus de travail du collectionneur Shenandoah peut être grossièrement divisé en neuf étapes suivantes :
-
Marquage initial : Comme G1, les objets directement liés à GC Roots sont d'abord marqués. Cette étape est toujours "Stop The World". , mais le temps de pause n'a rien à voir avec la taille du tas, seulement avec le nombre de racines GC.
-
Marquage simultané : comme G1, parcourez le graphe d'objets et marquez tous les objets accessibles. Cette étape est concurrente avec le thread utilisateur. La durée dépend du nombre d'objets survivants dans le tas et de la complexité structurelle de l'objet. graphique.
-
Note finale : identique à G1, traitez les scans SATB restants, comptez les régions avec la valeur de recyclage la plus élevée à ce stade, et formez ces régions dans un ensemble de collections de recyclage. Il y aura également une courte pause pendant la phase de notation finale.
-
Nettoyage simultané : Cette étape est utilisée pour nettoyer les régions où aucun objet survivant n'a été trouvé dans toute la région.
-
Recyclage simultané : à ce stade, Shenandoah copiera les objets survivants de la collection vers d'autres régions inutilisées. La durée d’exécution de la phase de collecte simultanée dépend de la taille de la collection.
-
Mise à jour initiale des références : Une fois l'objet copié dans la phase de recyclage simultanée, toutes les références aux anciens objets du tas doivent être corrigées vers les nouvelles adresses après la copie. La phase d'initialisation de la mise à jour des références n'effectue en réalité aucun traitement spécifique. Cette phase est uniquement établie pour établir un point de rendez-vous des threads afin de garantir que tous les threads du collecteur dans la phase de recyclage simultanée ont terminé les tâches de déplacement d'objets qui leur sont assignées. Le temps initial de mise à jour de la référence est très court, ce qui entraîne une très brève pause.
-
Mise à jour simultanée des références : L'opération de mise à jour des références commence réellement. Cette étape est concurrente du thread utilisateur. La durée dépend du nombre de références impliquées dans la mémoire. La mise à jour simultanée des références est différente du marquage simultané. Elle n'a plus besoin de rechercher le long du graphique d'objet, il suffit de rechercher linéairement le type de référence dans l'ordre de l'adresse physique de la mémoire et de remplacer l'ancienne valeur par la nouvelle valeur.
-
Mise à jour finale des références : Après avoir résolu la mise à jour des références dans le tas, les références existantes dans GC Roots doivent également être corrigées. Cette étape est la dernière pause de Shenandoah, et le temps de pause n'est lié qu'au nombre de racines GC.
-
Nettoyage simultané : après le recyclage et la mise à jour simultanés des références, toutes les régions de l'ensemble de recyclage n'ont plus d'objets vivants, et ces régions sont devenues des régions de déchets immédiats. Enfin, le processus de nettoyage simultané est à nouveau appelé pour récupérer la mémoire de. ces régions. Espace pour l’attribution future de nouveaux objets.
ZGC Collector
Les objectifs de ZGC et de Shenandoah sont très similaires. Ils espèrent tous deux limiter le temps de pause du garbage collection quelle que soit la taille de la mémoire tas sans affecter autant que possible le débit. Faible latence en dix millisecondes.
Le collecteur ZGC est basé sur la disposition de la mémoire Région, (temporairement) sans génération. Il utilise des technologies telles que des barrières de lecture, des pointeurs colorés et un mappage multiple de mémoire pour implémenter des algorithmes de tri par marques simultanés, à faible coût. comme son objectif premier.
ZGC utilise également une disposition de mémoire de tas basée sur la région, mais contrairement à eux, la région de ZGC est dynamique - création et destruction dynamiques, ainsi que taille de capacité de région dynamique.
Le processus de fonctionnement de ZGC peut être divisé en quatre étapes :
-
Marquage simultané( : comme G1 et Shenandoah, le marquage simultané est une étape de traversée du graphe d'objet pour l'analyse d'accessibilité. Il passe également par un marquage initial et un marquage final similaires à G1 et Shenandoah (bien que les noms dans ZGC soient différents) . C'est ce qu'on appelle des pauses courtes, et les choses effectuées dans ces phases de pause sont similaires sur la cible. Contrairement à G1 et Shenandoah, le marquage de ZGC est effectué sur le pointeur au lieu de l'objet, et la phase de marquage sera mise à jour. Marqué 1 drapeaux dans le pointeur de teinture.
-
Préparation simultanée pour la réallocation : Cette étape doit calculer quelles régions seront nettoyées dans ce processus de collecte en fonction de conditions de requête spécifiques, et former ces régions dans un ensemble de réallocation
. Réallocation simultanée- : La réallocation est l'étape principale du processus d'exécution de ZGC. Ce processus implique la copie des objets survivants dans l'ensemble de réallocation vers de nouvelles régions, et la gestion d'une table de transfert et d'un enregistrement pour chaque région dans l'ensemble de réallocation de la relation de pilotage à partir des anciens objets. vers de nouveaux objets.
Remappage simultané- : le remappage consiste à corriger toutes les références de l'ensemble du tas qui pointent vers les anciens objets de l'ensemble de réallocation. ZGC le fait intelligemment dans la phase de remappage simultané. Phase de marquage simultanée dans le prochain cycle de garbage collection. Quoi qu'il en soit, ils doivent parcourir tous les objets, donc la fusion permet d'économiser le coût de parcours du graphe d'objets une fois que tous les pointeurs ont été corrigés. La table de transfert des anciennes et des nouvelles relations d'objets peut être publiée.
Choisissez un garbage collector approprié
Considérez les trois questions suivantes :
Quel est l'objectif principal de l'application
S'il s'agit d'analyse de données ou de calcul scientifique Pour des tâches comme celle-ci, l'objectif est de calculer les résultats ? le plus rapidement possible, le débit est donc l'objectif principal ;
- S'il s'agit d'une application SLA, le temps de pause affecte directement la qualité du service, et dans les cas graves, cela peut même entraîner un délai d'attente des transactions, le retard est donc l'objectif principal ;
S'il s'agit d'une application client ou d'une application intégrée, l'utilisation de la mémoire par le garbage collection ne peut pas être ignorée. -
- Quelle est l'infrastructure pour exécuter l'application ?
L'architecture système impliquée est x86-32/64. ARM/Aarch64 ;
Le nombre de processeurs et la taille de la mémoire allouée ; - Que le système d'exploitation sélectionné soit Linux, Solaris ou Windows, etc.
-
- Quel est le numéro de version du JDK ? ZingJDK/Zulu, OracleJDK, Open-JDK ou une distribution d'une autre société ? À quelle version de la « Spécification de la machine virtuelle Java » correspond-il ?
Comment choisir le garbage collector
pour ajuster le tas en premier ? Si la mémoire est inférieure à 100 Mo, utilisez le collecteur série
S'il s'agit d'un programme monocœur autonome et qu'il n'y a pas d'exigence de temps de pause, le collecteur série
S'il est multi-CPU, il nécessite une mémoire élevée Débit, laissez le temps de pause dépasser 1 seconde, choisissez le choix parallèle ou JVM- Si vous disposez de plusieurs processeurs, recherchez un temps de pause faible et devez répondre rapidement (par exemple, le délai ne peut pas dépasser 1 seconde pour les applications Internet), utilisez un collecteur simultané
-
- Étude recommandée : "
Tutoriel vidéo Java- "
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



