


Cet article vous donnera une analyse approfondie de l'index dans MySQL et vous aidera à comprendre le principe de l'index MySQL. J'espère qu'il vous sera utile !

Un index est une structure de données triée qui aide MySQL à obtenir des données efficacement
Connaissance préalable : plus la hauteur de l'arbre est basse, plus l'efficacité des requêtes est élevée
Site Web de simulation de structure de données : https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
(1) Arbre binaire
Problème : il ne peut pas s'auto-équilibrer, l'inclinaison se produit dans les cas extrêmes, et l'efficacité des requêtes est similaire à celle d'une liste chaînée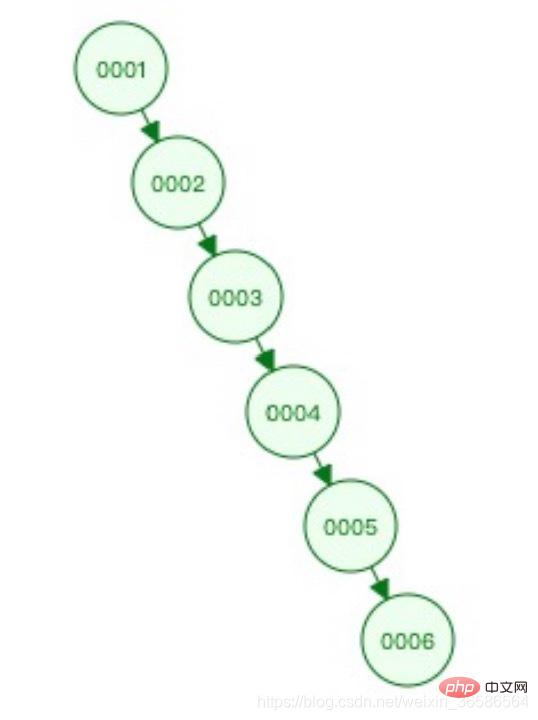
(2) Arbre rouge-noir
L'arbre rouge-noir équilibre les données et résout le problème de la croissance unilatérale
Problème : il ne convient pas à de grandes quantités de données ; données Lorsque la quantité de données est importante, la hauteur de l'arborescence est incontrôlable, du nœud racine aux nœuds feuille, il faut parcourir plusieurs fois pour trouver, ce qui est inefficace. 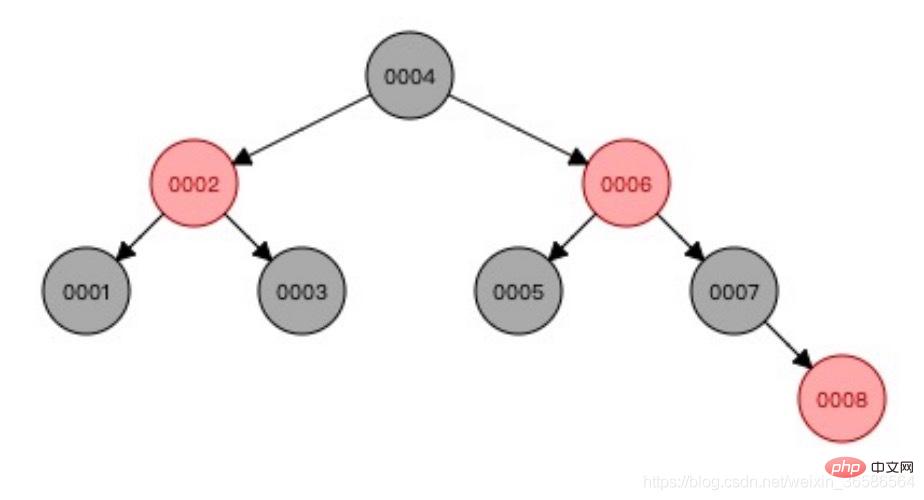
(3) Hash
1. Un calcul de hachage sur la clé d'index peut localiser l'emplacement de stockage des données
2. Dans de nombreux cas, l'index de hachage est plus efficace que l'index d'arbre B+
3. Seul "=" peut être satisfait, "IN", ne prend pas en charge la requête de plage
4. Problème de conflit de hachage 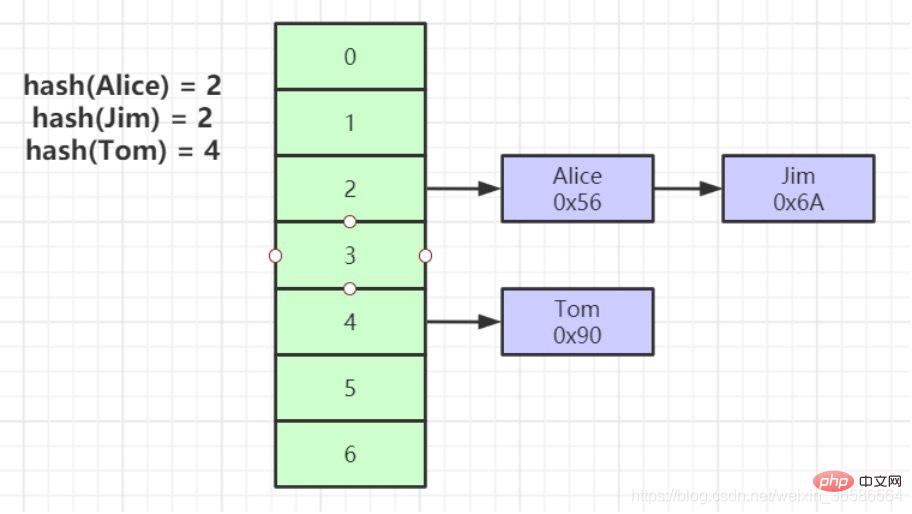
(4) B-Tree
1. Les nœuds feuilles ont la même profondeur et les pointeurs des nœuds feuilles sont vides ; . Tous les éléments d'index ne sont pas répétés ;
3. Les index de données dans les nœuds sont classés par ordre croissant de gauche à droite 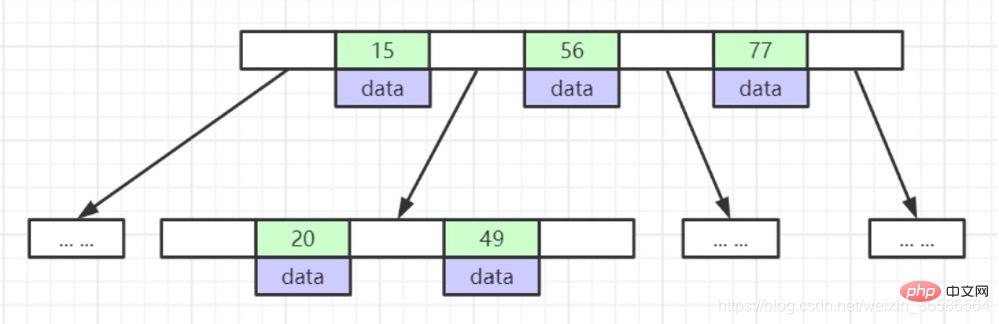
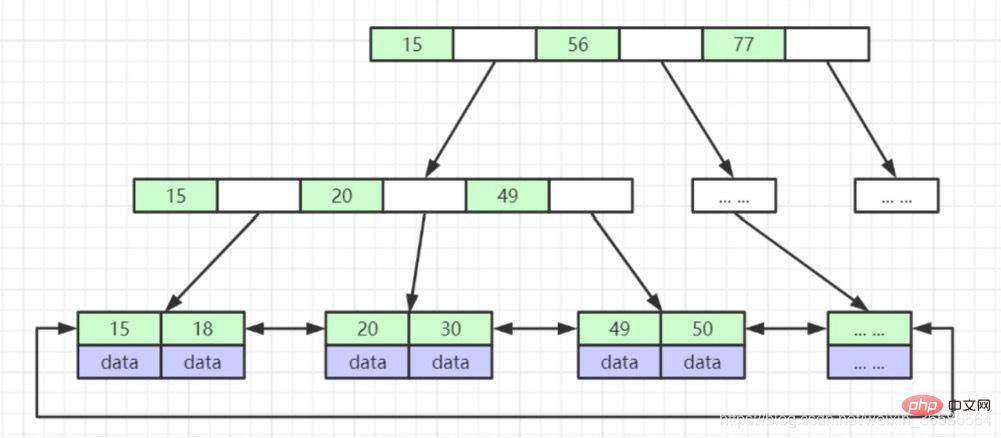
1. Nœuds non-feuilles ; ne stockez pas de données, seuls les index (redondants), Plus d'index peuvent être placés
2. Les nœuds feuilles contiennent tous les champs d'index
3. Les nœuds feuilles sont connectés avec des pointeurs pour améliorer les performances de l'accès par intervalle
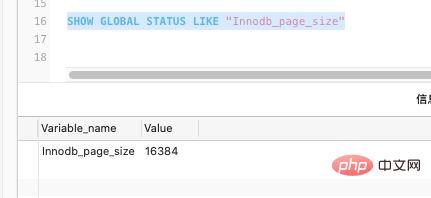
Dans MySQL, la taille par défaut de notre page InnoDB est de 16 Ko. Bien sûr, elle peut également être définie via des paramètres :
SHOW GLOBAL STATUS LIKE "Innodb_page_size"
Parce que nous ne savons pas sur quelle page existent les données que nous voulons trouver, et il est impossible de parcourir toutes les pages, ce qui est trop lent.
Les gens ont donc pensé à un moyen d'organiser ces données en utilisant l'arbre B+. Comme le montre la figure : 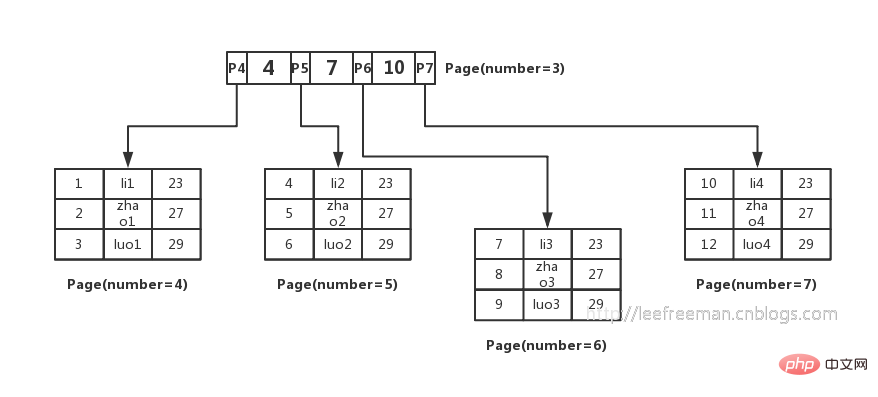
1. La plus petite unité de stockage du moteur de stockage InnoDB est une page. data ou use Pour stocker les valeurs clés + les pointeurs, les nœuds feuilles dans l'arborescence B+ stockent les données et les nœuds non-feuilles stockent les valeurs clés + les pointeurs.
.
Combien pouvons-nous stocker dans une page ? Une telle unité représente en réalité le nombre de pointeurs, c'est-à-dire 16384/14=1170. Ensuite, on peut calculer qu'un arbre B+ d'une hauteur de 2 peut stocker 1170*16=18720 de ces enregistrements de données. Sur la base du même principe, nous pouvons calculer qu'un arbre B+ d'une hauteur de 3 peut stocker : 1170*1170*16=21902400 de tels enregistrements. Donc dans InnoDB, la hauteur de l'arborescence B+ est généralement de 1 à 3 couches, ce qui peut satisfaire des dizaines de millions de stockage de données.Lors de la recherche de données, une recherche sur une page représente une IO, donc l'interrogation via l'index de clé primaire ne nécessite généralement que 1 à 3 opérations IO pour trouver les données.
B-tree
Les nœuds feuilles ont la même profondeur et les pointeurs des nœuds feuilles sont vides
Tous les éléments d'index ne sont pas répétés
Les index de données dans les nœuds sont disposés progressivement de gauche à droite
Indice d'arbre B+
Les nœuds non-feuille ne sont pas des données de stockage, seuls des index (redondants), plus d'index peuvent être placés
Les nœuds feuilles contiennent tous les champs d'index
Les nœuds feuilles sont connectés avec des pointeurs pour améliorer les performances de l'accès par intervalle
Pourquoi les nœuds de données sont déplacés aux nœuds feuilles, un nœud peut stocker plus d'index
16^n=20 millions, n est la hauteur de l'arbre, et les mêmes données sont stockées. La hauteur de l'arbre B+ est beaucoup plus petite que celle de l'arbre B
car le. L'arbre B enregistrera les données indépendamment des nœuds feuilles ou des nœuds non feuilles, ce qui entraîne une diminution du nombre de pointeurs pouvant être enregistrés dans des nœuds non feuilles (certaines données sont également appelées répartition lorsqu'il y a peu de pointeurs). , une grande quantité de données doit être enregistrée, ce qui ne peut qu'augmenter la hauteur de l'arborescence, ce qui entraîne davantage d'opérations d'E/S et des performances de requête inférieures ;
5 Implémentation de l'index du moteur de stockage
(1) Les fichiers d'index MyISAM et les fichiers de données sont séparés (non agrégés)
Les fichiers d'index stockent les index et les données ; magasins de fichiers Les données, l'index et les données ne sont pas stockés ensemble
Requête : interrogez d'abord l'index sur l'arborescence B+, puis interrogez le fichier de données en utilisant l'emplacement interrogé 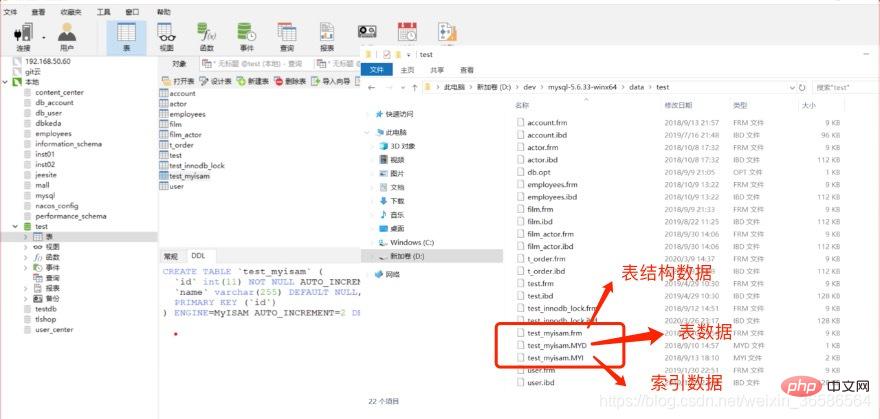
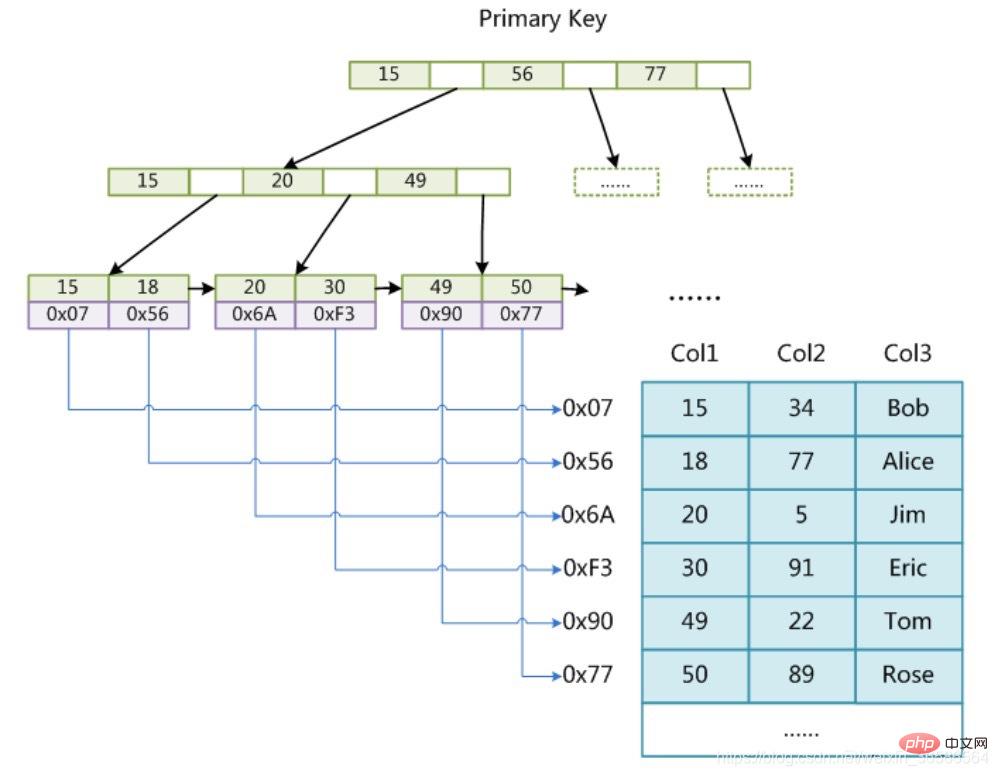 (1) Implémentation de l'index InnoDB
(1) Implémentation de l'index InnoDB
 1. Le fichier de données de table lui-même est un fichier de structure d'index organisé par B+Tree
1. Le fichier de données de table lui-même est un fichier de structure d'index organisé par B+Tree
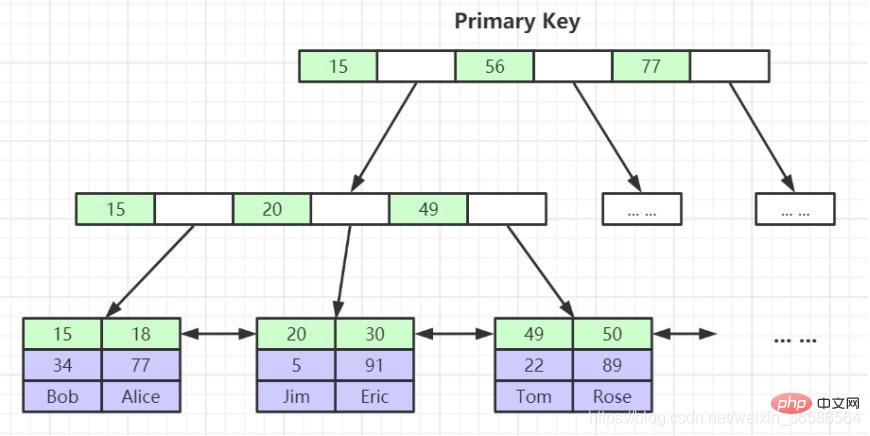
(1) Index de clé primaire :
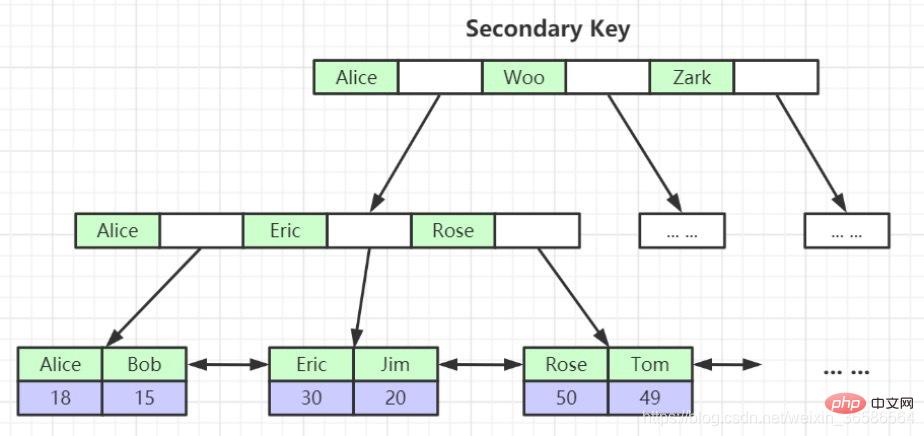
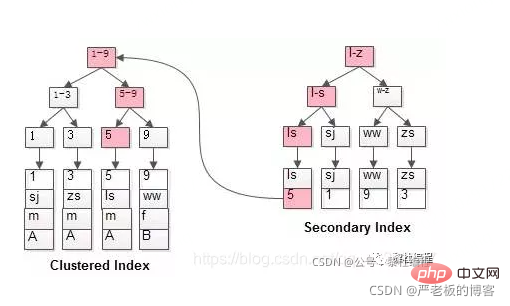
 (2) Index auxiliaire (index secondaire)
(2) Index auxiliaire (index secondaire)
L'index secondaire est différent de l'index clusterisé de plusieurs manières :
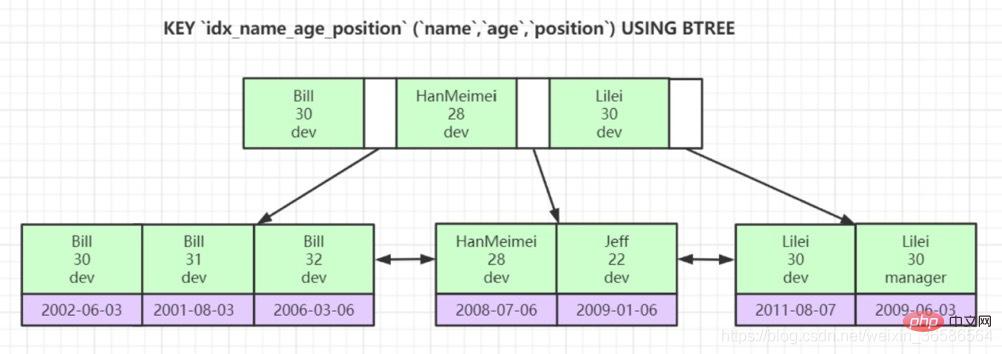
 (3) Index conjoint :
(3) Index conjoint :
 3. Pourquoi est-il recommandé que les tables InnoDB aient une clé primaire, et pourquoi est-il recommandé d'utiliser une clé primaire entière à incrémentation automatique ?
3. Pourquoi est-il recommandé que les tables InnoDB aient une clé primaire, et pourquoi est-il recommandé d'utiliser une clé primaire entière à incrémentation automatique ?
(2) Que se passe-t-il si vous n'utilisez pas de clé primaire entière à incrémentation automatique et que vous utilisez l'UUID comme clé primaire ?
L'UUID est un type de chaîne et les opérations de requête auront des opérations de comparaison. Les opérations de comparaison d'entiers sont plus rapides, les clés primaires entières économisent de l'espace que les UUID et les UUID ne s'incrémentent pas automatiquement
(3) Index HASH : la valeur est hachée et le la valeur calculée est la somme Les emplacements de stockage sont cartographiés un par un
Pourquoi ne pas utiliser Hash ?
Hash ne prend pas bien en charge les requêtes de plage. Les données dans une certaine colonne ne sont pas ordonnées et l'arborescence B+ peut rendre les données ordonnées lors de la construction.
4. Pourquoi les nœuds feuilles des structures d'index de clé non primaire stockent-ils les valeurs de clé primaire ? (Cohérence et gain d'espace de stockage)
1. Chaque index correspond à un arbre B+. Les enregistrements utilisateur sont stockés dans les nœuds feuilles de l'arborescence B+, et tous les enregistrements de répertoire sont stockés dans des nœuds non feuilles.
2. Le moteur de stockage InnoDB créera automatiquement un index clusterisé comme clé primaire (s'il n'existe pas, il l'ajoutera automatiquement pour nous. Les nœuds feuilles de l'index cluster contiennent des enregistrements utilisateur complets).
3. Un index secondaire peut être établi pour la colonne spécifiée. L'enregistrement utilisateur contenu dans le nœud feuille de l'index secondaire est composé de la colonne d'index + clé primaire. Par conséquent, si vous souhaitez trouver l'enregistrement utilisateur complet via le secondaire. index, vous devez renvoyer la table. L'opération consiste à trouver l'enregistrement utilisateur complet dans l'index clusterisé après avoir trouvé la valeur de la clé primaire via l'index secondaire.
4. Les nœuds de chaque niveau de l'arborescence B+ sont triés en fonction de la valeur de la colonne d'index de petit à grand pour former une liste double chaînée, et les enregistrements de chaque page (qu'il s'agisse d'un enregistrement d'utilisateur ou d'une entrée d'annuaire record) sont classés selon l'index. Les valeurs des colonnes forment une liste à chaînage unique par ordre croissant. S'il s'agit d'un index conjoint, les pages et les enregistrements sont triés d'abord par la colonne avant l'index conjoint. Si les valeurs des colonnes sont les mêmes, elles sont ensuite triées par la colonne après l'index conjoint.
La recherche d'enregistrements via l'index commence à partir du nœud racine de l'arborescence B+ et recherche couche par couche vers le bas. Étant donné que chaque page possède un répertoire de pages basé sur la valeur de la colonne d'index, les recherches dans ces pages sont très rapides.
Voir le blog : Résumé de plusieurs situations où l'index Mysql échouera
https://blog.csdn.net/weixin_36586564/article/details/79641748
[Recommandations associées : tutoriel vidéo mysql]
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



