


Cet article vous apporte des connaissances pertinentes sur mysql Il présente principalement certains problèmes de la version avancée de MySQL, notamment ce qu'est un index, l'implémentation sous-jacente de l'index, etc. sera utile à tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
MySQL, un terme familier et inconnu Dès notre apprentissage de Javaweb, nous utilisions la base de données MySQL. À ce stade, MySQL nous semblait C'est juste. un bon outil pour stocker des données lors du stockage, il est constamment rempli lors de l'interrogation, c'est également une requête de table complète aveugle (sans un peu d'optimisation).
Nous nous trompons toujours et pensons que nous pouvons optimiser par d'autres aspects. Nous sommes réticents à affronter MySQL Advanced, et à la place, apprenons quelque chose qui semble être plus "avancé", apprenons Redis, venez partager la pression de MySQL, apprenez les middlewares tels que MyCat et implémentez la réplication maître-esclave, la séparation lecture-écriture, sous-base de données et sous-table, etc. (Je parle de melo, c'est vrai)
Quand je me préparais pour l'interview, j'ai découvert que je ne connaissais pas toutes les questions sur MySQL dans les questions de l'interview~
Et à propos du middleware de pointe que j'ai appris, j'ai posé très peu de questions ! ! Je sais seulement comment l'utiliser. Lors de la rédaction de mon CV, je ne peux écrire que faiblement « comprendre » le middleware xxx...
Bien sûr, l'apprentissage du MySQL Advanced Chapter ne se limite pas aux entretiens. Dans les projets réels, cette partie. L'optimisation est très importante. Après avoir connu des temps d'arrêt du serveur, je ne peux qu'en silence...
Commencer à partir de maintenant, il est encore trop tard pour débarquer ! ! ! En profitant des trois or et des quatre argent, complétez les points de connaissances du MySQL Advanced Chapter et commencez le voyage du MySQL Advanced Chapter sous les aspects suivants
Il est recommandé de rechercher les parties qui vous sont utiles à travers le répertoire de la barre latérale, parmi lesquels sont Le préfixe emoji est une partie importante Si vous le trouvez utile, l'éditeur continuera à améliorer cet article et la colonne MySQL.
La définition officielle de l'index par MySQL est la suivante : L'index (index) est une structure de données (ordonnée) qui aide MySQL à obtenir des données efficacement. Des index sont ajoutés aux champs des tables de base de données afin d'améliorer l'efficacité des requêtes. En plus des données, le système de base de données conserve également des structures de données qui satisfont des algorithmes de recherche spécifiques. Ces structures de données font référence (pointent vers) les données d'une manière ou d'une autre, afin que des algorithmes de recherche avancés puissent être implémentés sur ces structures de données. indice. Comme le montre le schéma ci-dessous :
En fait, pour parler simplement, un index est une structure de données triée
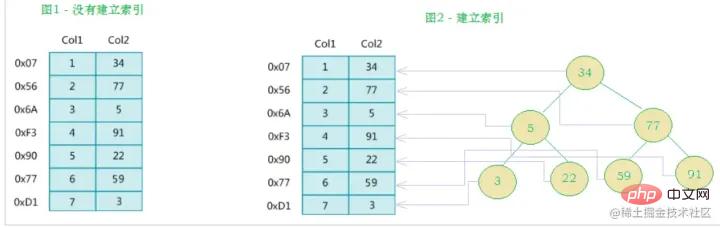
Le côté gauche est la table de données, avec un total de deux colonnes et sept enregistrements, et le côté le plus à gauche l'une est la structure physique de l'adresse de l'enregistrement de données (notez que les enregistrements logiquement adjacents ne sont pas nécessairement physiquement adjacents sur le disque). Afin d'accélérer la recherche de Col2, vous pouvez maintenir un arbre de recherche binaire comme indiqué à droite. Chaque nœud contient valeur de clé d'index et un pointeur vers l'adresse physique de l'enregistrement de données correspondant, afin que vous puissiez. utilisez la recherche binaire pour obtenir rapidement les données correspondantes.
Mais en fait, nous n'utilisons pas arbre de recherche binaire pour le stocker dans MySQL Pourquoi ?
Vous devez savoir que dans un arbre de recherche binaire, un nœud ici ne peut stocker qu'une seule donnée, et un nœud correspond à un bloc de disque dans MySQL. De cette façon, chaque fois que nous lisons un bloc de disque, nous ne pouvons que le faire. obtenir une donnée, l'efficacité est particulièrement faible, on pensera donc à utiliser une structure B-tree pour la stocker.
Les index sont implémentés dans la couche moteur de stockage de MySQL, pas dans la couche serveur. Par conséquent, les index de chaque moteur de stockage ne sont pas nécessairement exactement les mêmes et tous les moteurs ne prennent pas en charge tous les types d’index.
BTREE index
| Supporté | Supporté Non pris en charge |
Supporté |
Index R-tree | ||||||||||||
Non pris en charge |
Supporté |
Non pris en charge |
| Texte intégral||||||||||||
Supporté après la version 5.6 |
Supporté |
Non pris en charge |
Ce que nous appelons habituellement index, sauf indication contraire, fait référence à des index organisés dans une structure arborescente B+ (arbre de recherche multidirectionnel, pas nécessairement binaire). Parmi eux, l'index clusterisé, l'index composé, l'index de préfixe et l'index unique utilisent tous l'index B+tree par défaut, collectivement appelés index. BTREEArbre de recherche équilibré multi-chemins, un ordre m (m-fork) BTREE satisfait :
insérer le mot-clé case
pour garantir que les propriétés de l'arbre B d'ordre m sont pas détruit Puisque le niveau 3 ne peut avoir que 2 nœuds au maximum, 26 et 30 sont ensemble au début, puis 85 commenceront à se diviser, 30 sera la position médiane supérieure, 26 restera et 85 ira à la position médiane supérieure. à droite
Après avoir monté, il doit être divisé
Avantages comparatifs.Par rapport aux arbres de recherche binaires, la hauteur/profondeur est inférieure et l'efficacité naturelle des requêtes est plus élevée. L'arbre B+TREE
Par rapport à l'avantage
B+Tree dans MySQLLa structure de données d'index MySql optimise le B+Tree classique. Sur la base du B+Tree original, un pointeur de liste chaînée pointant vers le nœud feuille adjacent (la structure globale est similaire à une liste doublement chaînée) est ajouté pour former un B+Tree avec un pointeur séquentiel pour améliorer les performances de l'intervalle. accéder.
Indice BTree :Introduction à l'initialisationLe bleu clair s'appelle Un bloc de disque, vous pouvez voir que chaque bloc de disque contient plusieurs éléments de données (indiqués en bleu foncé) et des pointeurs (indiqués en jaune)Par exemple, le bloc de disque 1 contient les éléments de données 17 et 35, y compris les pointeurs P1, P2, P3, P1 représente le disque blocs inférieurs à 17, P2 représente les blocs de disque entre 17 et 35 et P3 représente les blocs de disque supérieurs à 35.
Processus de rechercheSi vous souhaitez trouver l'élément de données 29, alors le bloc de disque 1 sera d'abord chargé du disque vers la mémoire, et une E/S se produira à ce moment-là. Utilisez une recherche binaire dans la mémoire pour déterminer que 29 est compris entre 17 et 35, et verrouillez le pointeur P2 du bloc disque 1. Le temps mémoire est négligeable car très court (par rapport aux IO du disque). L'adresse du pointeur P2 du bloc de disque 1 vers le bloc de disque 3 est chargée du disque dans la mémoire. La deuxième E/S se produit entre 26 et 30. Le pointeur P2 du bloc de disque 3 est verrouillé dans la mémoire. La mémoire via le pointeur. La troisième IO se produit. En même temps, la mémoire passe. La recherche binaire atteint 29 et termine la requête, ce qui donne un total de trois IO. Classification des indexDans InnoDB, les tables sont stockées sous forme d'index selon l'ordre des clés primaires. Les tables ainsi stockées sont appelées tables organisées en index. Et comme nous l'avons mentionné plus tôt, InnoDB utilise le modèle d'index d'arbre B+, donc les données sont stockées dans l'arborescence B+. Chaque index correspond à un arbre B+ dans InnoDB. mysql> create table T( id int primary key, k int not null, name varchar(16), index (k))engine=InnoDB; 复制代码 Copier après la connexion Les valeurs (ID,k)de R1~R5 dans la table sont (100,1), (200,2), (300,3), (500,5) et (600,6), l'exemple de diagramme de deux arbres est le suivant :
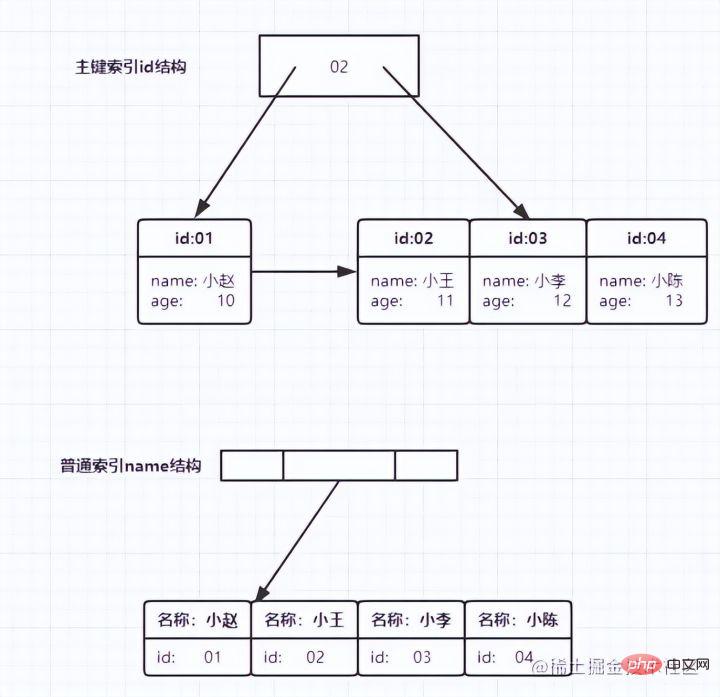
Index de clé primaireLa colonne de clé primaire de la table de données utilise l'index de clé primaire et est créée par défaut. C'est pourquoi, avant d'apprendre l'indexation, le professeur nous disait souvent que la recherche basée sur la clé primaire serait plus rapide. . Il s'avère que la clé primaire elle-même L'index est construit. Le nœud feuille de index auxiliaireindex auxiliaire est la valeur de la clé primaire. Dans InnoDB, l'index auxiliaire est également appelé index secondaire (index secondaire). Comme indiqué ci-dessous :
Selon le au-dessus de la structure de l'index, discutons d'une question : Quelle est la différence entre les requêtes basées sur l'index de clé primaire et l'index secondaire ?
En d'autres termes, les requêtes basées sur des index auxiliaires doivent analyser une arborescence d'index supplémentaire. Par conséquent, nous devrions essayer d’utiliser des requêtes par clé primaire dans nos applications. À moins que les données que nous voulons interroger n'existent dans notre arbre d'index, nous l'appelons actuellement index de couverture, c'est-à-dire que la colonne d'index contient toutes les données que nous voulons interroger.
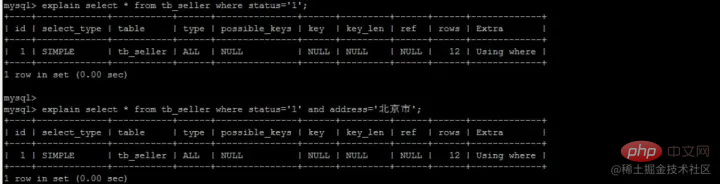
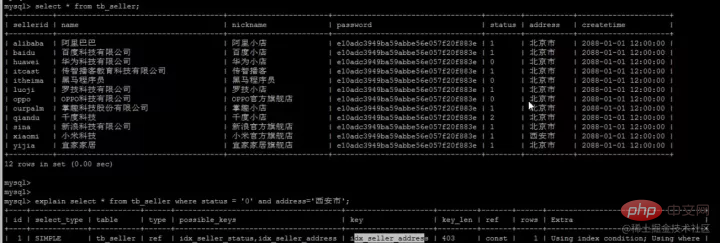
Extension--index pushdownLe soi-disant pushdown, comme son nom l'indique, signifie en faitreport. notre opération de retour de table, MySQL ne le fera pas. Il est facile pour nous de renvoyer la table car c'est du gaspillage. Qu'est-ce que ça veut dire? Considérez l'exemple suivant. Nous avons établi un index composite (nom, statut, adresse), qui est également stocké selon ce champ, similaire à l'image : Arbre d'index composé (stocke uniquement les colonnes d'index et les clés primaires pour le retour de la table)
|
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié


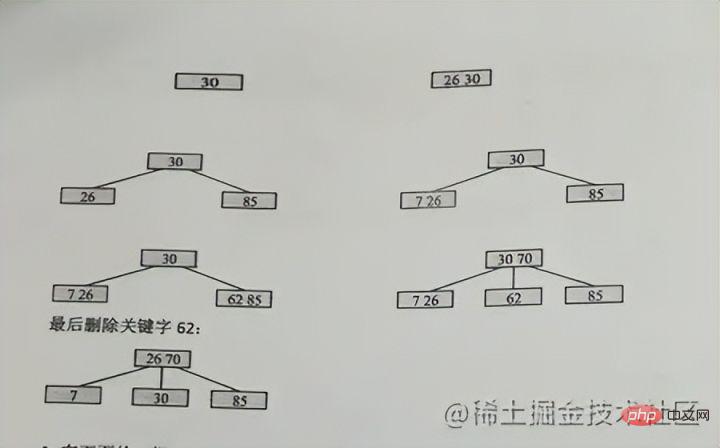
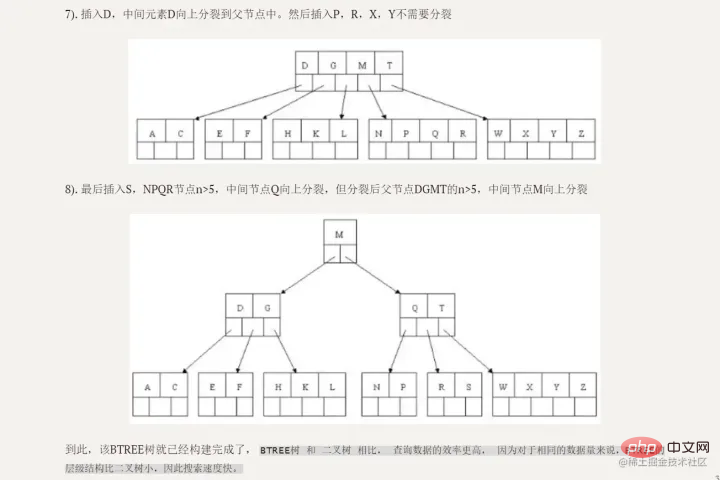
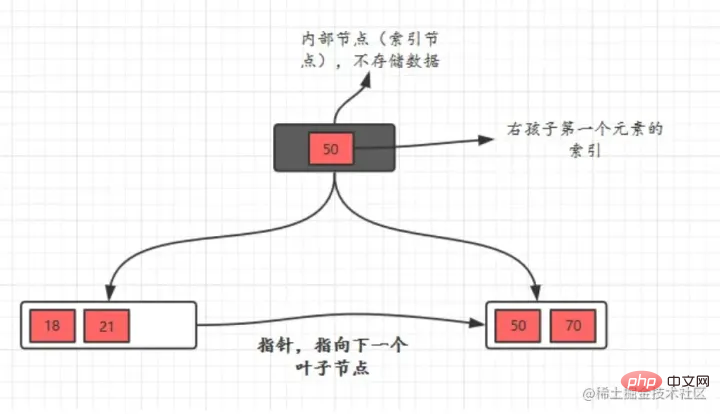
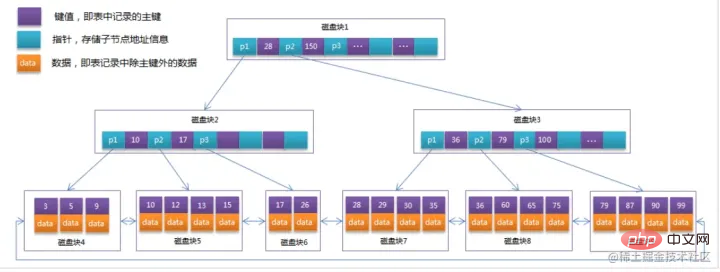 Diagramme d'arbre de recherche binaire :
Diagramme d'arbre de recherche binaire : 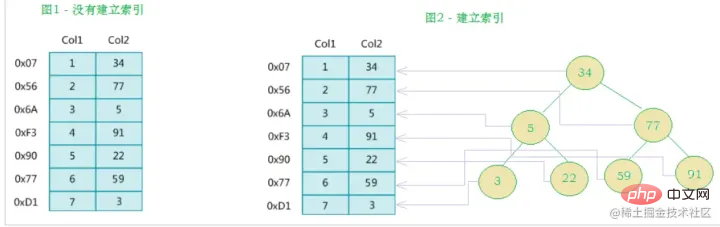 Principe de l'index
Principe de l'index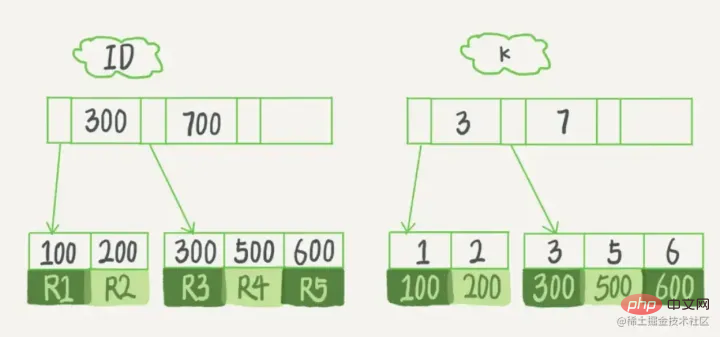










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



