


Cet article vous apporte des connaissances pertinentes sur mysql, qui introduit principalement les problèmes liés au principe MVCC d'InnoDB MVCC est un contrôle de concurrence multi-version, principalement pour améliorer les performances de concurrence de la base de données. j'espère que cela aide tout le monde.

Apprentissage recommandé : Tutoriel vidéo mysql
MVCC signifie Multi-Version Concurrency Control, qui est un contrôle de concurrence multi-version, principalement destiné à améliorer les performances de concurrence de la base de données. Lorsqu'une demande de lecture ou d'écriture se produit pour la même ligne de données, elle sera verrouillée et bloquée. Mais MVCC utilise une meilleure façon de gérer les requêtes de lecture-écriture, de sorte qu'aucun verrouillage ne se produise lorsqu'un conflit de requêtes de lecture-écriture se produit. Cette lecture fait référence à la lecture de l'instantané, et non à la lecture actuelle. La lecture actuelle est une opération de verrouillage et est un verrou pessimiste. Alors, comment parvient-il à lire et à écrire sans verrouillage ? Que signifient la lecture d'instantané et la lecture actuelle ? Nous l’apprendrons tous plus tard.
MySQL peut largement éviter les problèmes de lecture fantôme sous le niveau d'isolement REPEATABLE READ. Comment MySQL fait-il cela ?
Nous savons que pour les tables utilisant le moteur de stockage InnoDB, ses enregistrements d'index cluster contiennent deux colonnes cachées nécessaires (row_id n'est pas nécessaire, la table que nous avons créée a une clé primaire ou une clé UNIQUE non NULL le fera n'inclut pas la colonne row_id) :
trx_id : chaque fois qu'une transaction modifie un enregistrement d'index clusterisé, l'identifiant de la transaction sera attribué à la colonne cachée trx_id.
roll_pointer : chaque fois qu'un enregistrement d'index clusterisé est modifié, l'ancienne version sera écrite dans le journal d'annulation. Cette colonne cachée équivaut à un pointeur, qui peut être utilisé pour trouver l'enregistrement avant les informations de modification.
Pour illustrer ce problème, nous créons une table de démonstration :
CREATE TABLE `teacher` ( `number` int(11) NOT NULL, `name` varchar(100) DEFAULT NULL, `domain` varchar(100) DEFAULT NULL, PRIMARY KEY (`number`)) ENGINE=InnoDB DEFAULT CHARSET=utf8
Insérons ensuite une donnée dans cette table :
mysql> insert into teacher values(1, 'J', 'Java');Query OK, 1 row affected (0.01 sec)
Les données ressemblent maintenant à ceci :
mysql> select * from teacher; +--------+------+--------+ | number | name | domain | +--------+------+--------+ | 1 | J | Java | +--------+------+--------+ 1 row in set (0.00 sec)
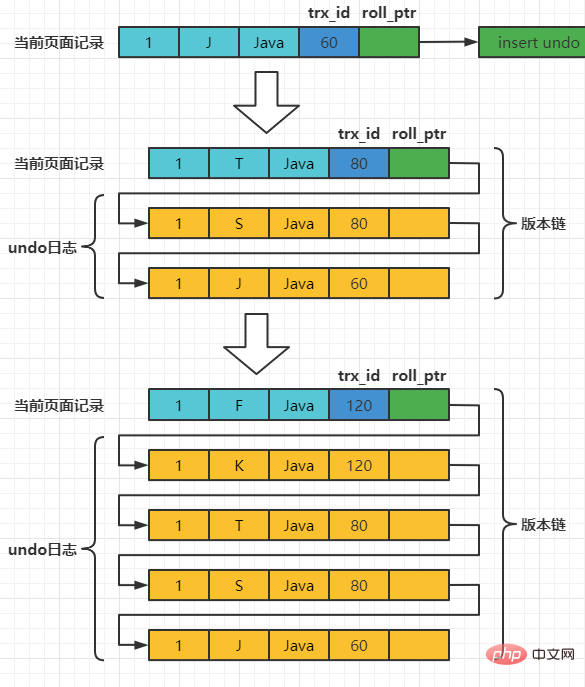
Supposons que l'ID de transaction d'insertion de l'enregistrement est 60 , alors le diagramme schématique de l'enregistrement à ce moment est le suivant :

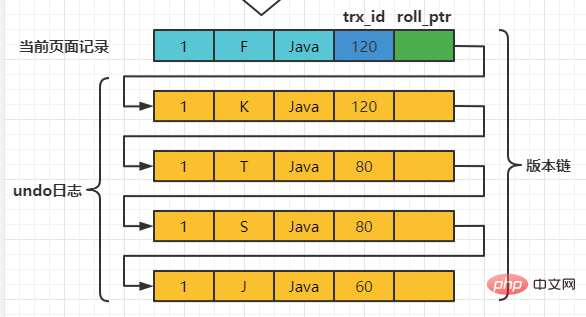
Supposons que deux transactions avec les ID de transaction 80 et 120 effectuent des opérations de MISE À JOUR sur cet enregistrement. Le processus d'opération est le suivant :
| Trx80 | Trx120 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| begin | ||||||||||
| begin | ||||||||||
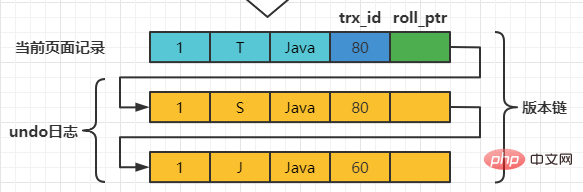
| mettre à jour le nom de l'enseignant = 'S' où numéro = 1; | ||||||||||
| mettre à jour le professeur définir le nom = 'T' où numéro = 1; ; | ||||||||||
| commit |
| T1 | T2 |
|---|---|
| begin; | |
| sélectionner * de l'enseignant où nombre=30 ; | |
|
insérer dans les valeurs de l'enseignant (30, 'X', 'Java') ; enseignant où nombre = 30 ; a des données |
|
|
Eh bien, que se passe-t-il ? La transaction T1 présente évidemment un phénomène de lecture fantôme. Sous le niveau d'isolement REPEATABLE READ, T1 génère un ReadView lors de la première exécution d'une instruction SELECT normale, puis T2 insère un nouvel enregistrement dans la table professeur et le soumet. ReadView ne peut pas empêcher T1 d'exécuter l'instruction UPDATE ou DELETE pour modifier l'enregistrement nouvellement inséré (puisque T2 a déjà soumis, la modification de l'enregistrement ne provoquera pas de blocage), mais de cette façon, la valeur de la colonne cachée trx_id de ce nouvel enregistrement sera be Cela devient l'identifiant de transaction de T1. Après cela, T1 peut voir cet enregistrement lorsqu'il utilise une instruction SELECT ordinaire pour interroger cet enregistrement et peut renvoyer cet enregistrement au client. Du fait de l'existence de ce phénomène particulier, on peut aussi penser que MVCC ne peut pas interdire complètement la lecture fantôme. Résumé MVCCNous pouvons voir dans la description ci-dessus que ce que l'on appelle MVCC (Multi-Version ConcurrencyControl, contrôle de concurrence multi-version) fait référence à l'utilisation des deux niveaux d'isolement de READ COMMITTD et REPEATABLE READ pour exécuter des transactions ordinaires. L'opération SELECT est le processus d'accès à la chaîne de versions enregistrées. Cela permet aux opérations de lecture-écriture et d'écriture-lecture de différentes transactions d'être exécutées simultanément, améliorant ainsi les performances du système. Une grande différence entre les deux niveaux d'isolement de READ COMMITTD et REPEATABLE READ est que le moment de génération de ReadView est différent. READ COMMITTD générera un ReadView avant chaque opération SELECT ordinaire, tandis que REPEATABLE READ ne générera un ReadView que pour la première fois. . Générez simplement un ReadView avant l'opération SELECT et réutilisez ce ReadView pour les opérations de requête ultérieures, évitant ainsi fondamentalement le phénomène de lecture fantôme. Nous avons dit auparavant que l'exécution d'une instruction DELETE ou d'une instruction UPDATE qui met à jour la clé primaire ne supprimera pas immédiatement l'enregistrement correspondant de la page, mais effectuera ce qu'on appelle l'opération de suppression de marque, ce qui équivaut à simplement définir un. supprimer l'indicateur sur l'enregistrement. Ceci est principalement pour MVCC. De plus, ce qu'on appelle MVCC ne prend effet que lorsque nous effectuons des requêtes SEELCT ordinaires. Toutes les instructions SELECT que nous avons vues jusqu'à présent sont des requêtes ordinaires. Quant à ce qu'est une requête extraordinaire, nous en reparlerons plus tard. Apprentissage recommandé : Tutoriel vidéo mysql |
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



