


Cet article vous apporte des connaissances pertinentes sur Redis, qui présente principalement des problèmes liés aux verrous distribués. Nous appelons généralement des threads pour appeler des verrous et libérer des verrous. En fait, un thread appelle pour ajouter des verrous. la valeur de la variable de verrouillage est 0. J'espère que cela sera utile à tout le monde.

Apprentissage recommandé : Tutoriel d'apprentissage Redis
Regardons d'abord les verrous sur une seule machine.
Pour les programmes multithread exécutés sur une seule machine, le verrou lui-même peut être représenté par une variable.
On dit généralement qu'un thread appelle une opération de verrouillage et de libération. En fait, lorsqu'un thread appelle une opération de verrouillage, il vérifie en fait si la valeur de la variable de verrouillage est 0. S'il est 0, définissez la valeur de la variable de verrouillage sur 1, indiquant que le verrou a été acquis. Si ce n'est pas 0, un message d'erreur sera renvoyé, indiquant que le verrou a échoué et qu'un autre thread a acquis le verrou. Lorsqu'un thread appelle l'opération de libération du verrou, il définit en fait la valeur de la variable de verrouillage sur 0 afin que d'autres threads puissent acquérir le verrou.
J'utilise un morceau de code pour démontrer les opérations de verrouillage et de déverrouillage des verrous, où lock est la variable de verrouillage.
acquire_lock(){
if lock == 0
lock = 1
return 1
else
return 0
}
release_lock(){
lock = 0
return 1
} Semblable au verrouillage sur une seule machine, le verrouillage distribué peut également être implémenté à l'aide d'une variable. La logique de fonctionnement du verrouillage et du déverrouillage sur le client est également cohérente avec la logique de fonctionnement du verrouillage et du déverrouillage sur une seule machine : Lors du verrouillage, vous devez également juger de la valeur de la variable de verrouillage et juger si le verrou peut être verrouillé avec succès en fonction de la valeur de la variable de verrouillage ; libération Lors du verrouillage, la valeur de la variable de verrouillage doit être définie sur 0, indiquant que le client ne détient plus le verrou.
Cependant, contrairement aux threads exploitant des verrous sur une seule machine, dans un scénario distribué, les variables de verrouillage doivent être conservées par un système de stockage partagé Ce n'est qu'ainsi que plusieurs clients peuvent accéder au système de stockage partagé. De manière correspondante, les opérations de verrouillage et de libération de verrous deviennent une lecture, une évaluation et un réglage de la valeur variable de verrouillage dans le système de stockage partagé.
Exigence 2 : le système de stockage partagé enregistre les variables de verrouillage. Si le système de stockage partagé tombe en panne ou est en panne, le client ne pourra pas effectuer de verrouillage. opérations. Lors de la mise en œuvre de verrous distribués, nous devons veiller à garantir la fiabilité du système de stockage partagé et donc la fiabilité du verrou.
Implémentation de verrous distribués basés sur un seul nœud Redis En tant que système de stockage partagé dans la mise en œuvre de verrous distribués, Redis peut utiliser des paires clé-valeur pour enregistrer les variables de verrouillage, puis recevoir et traiter les verrous et libérer les verrous envoyés par différents demande d'opération des clients. Alors, comment la clé et la valeur de la paire clé-valeur sont-elles déterminées ?
Nous devons donner à la variable de verrouillage un nom de variable, utiliser ce nom de variable comme clé de la paire clé-valeur, et la valeur de la variable de verrouillage est la valeur de la paire clé-valeur de cette façon, Redis peut enregistrer. la variable de verrouillage, et le client peut également Vous pouvez implémenter des opérations de verrouillage via des opérations de commande Redis.
Pour vous aider à comprendre, j'ai dessiné une image qui montre Redis utilisant des paires clé-valeur pour enregistrer les variables de verrouillage et le processus de fonctionnement de deux clients demandant des verrous en même temps. 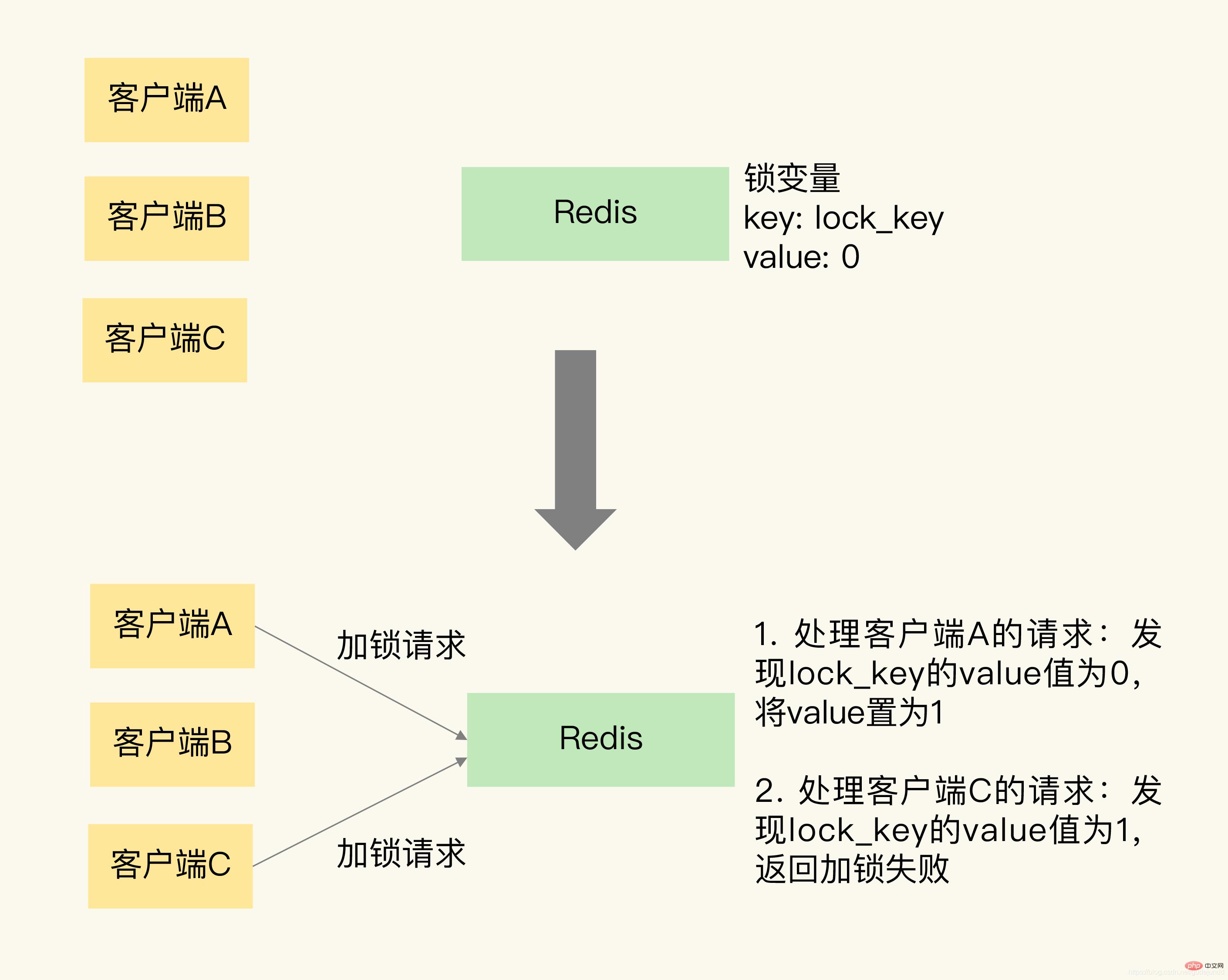
我还是借助一张图片来解释一下。这张图片展示了客户端 A 请求释放锁的过程。当客户端 A 持有锁时,锁变量 lock_key 的值为 1。客户端 A 执行释放锁操作后,Redis 将 lock_key 的值置为 0,表明已经没有客户端持有锁了。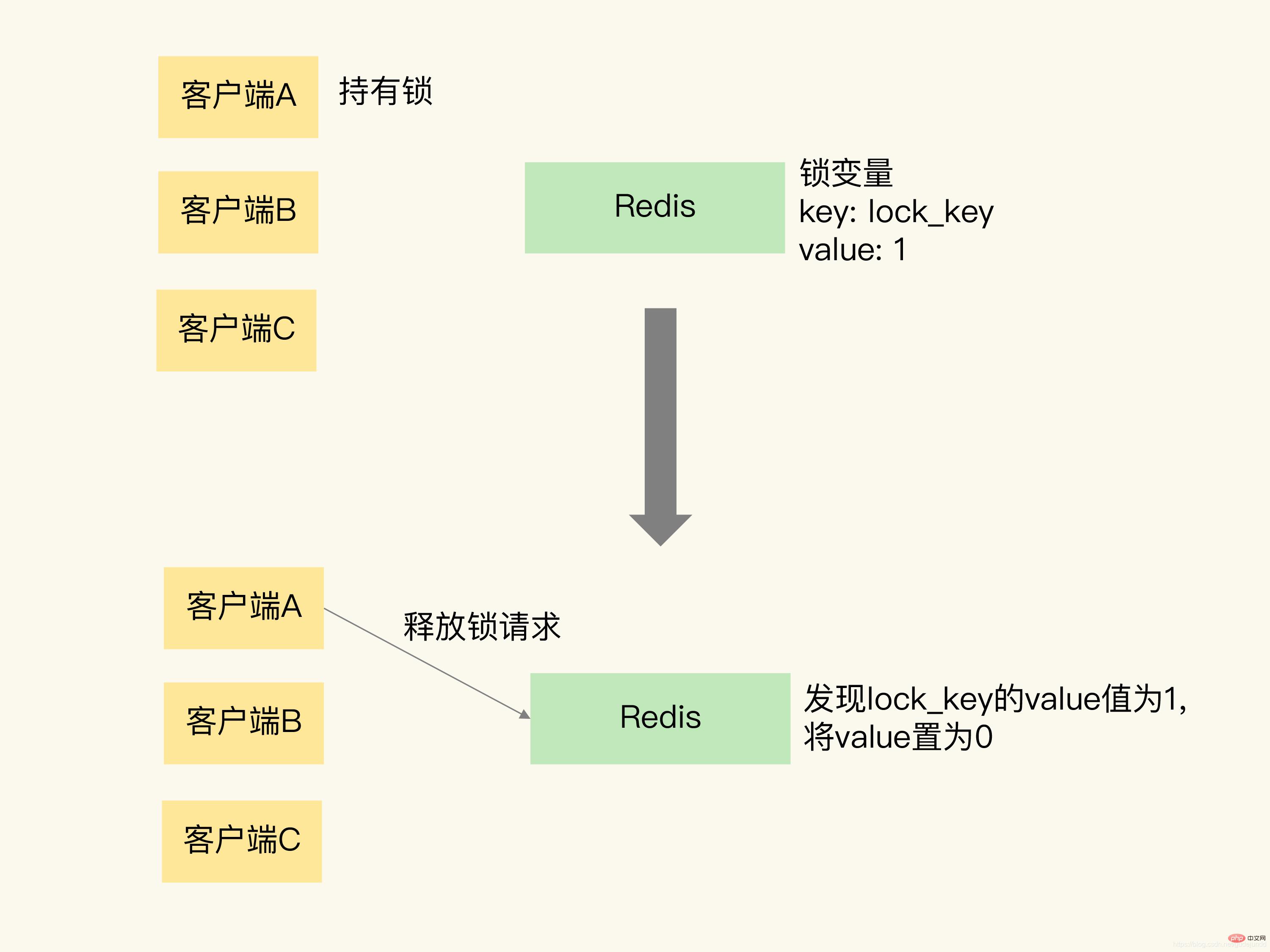
因为加锁包含了三个操作(读取锁变量、判断锁变量值以及把锁变量值设置为 1),而这三个操作在执行时需要保证原子性。那怎么保证原子性呢?
要想保证操作的原子性,有两种通用的方法,分别是使用 Redis 的单命令操作和使用 Lua 脚本。那么,在分布式加锁场景下,该怎么应用这两个方法呢?
我们先来看下,Redis 可以用哪些单命令操作实现加锁操作。
首先是 SETNX 命令,它用于设置键值对的值。具体来说,就是这个命令在执行时会判断键值对是否存在,如果不存在,就设置键值对的值,如果存在,就不做任何设置。
举个例子,如果执行下面的命令时,key 不存在,那么 key 会被创建,并且值会被设置为 value;如果 key 已经存在,SETNX 不做任何赋值操作。
SETNX key value
对于释放锁操作来说,我们可以在执行完业务逻辑后,使用 DEL 命令删除锁变量。不过,你不用担心锁变量被删除后,其他客户端无法请求加锁了。因为 SETNX 命令在执行时,如果要设置的键值对(也就是锁变量)不存在,SETNX 命令会先创建键值对,然后设置它的值。所以,释放锁之后,再有客户端请求加锁时,SETNX 命令会创建保存锁变量的键值对,并设置锁变量的值,完成加锁。
总结来说,我们就可以用 SETNX 和 DEL 命令组合来实现加锁和释放锁操作。下面的伪代码示例显示了锁操作的过程,你可以看下。
// 加锁 SETNX lock_key 1 // 业务逻辑 DO THINGS // 释放锁 DEL lock_key
不过,使用 SETNX 和 DEL 命令组合实现分布锁,存在两个潜在的风险。
第一个风险是,假如某个客户端在执行了 SETNX 命令、加锁之后,紧接着却在操作共享数据时发生了异常,结果一直没有执行最后的 DEL 命令释放锁。因此,锁就一直被这个客户端持有,其它客户端无法拿到锁,也无法访问共享数据和执行后续操作,这会给业务应用带来影响。
针对这个问题,一个有效的解决方法是,给锁变量设置一个过期时间。这样一来,即使持有锁的客户端发生了异常,无法主动地释放锁,Redis 也会根据锁变量的过期时间,在锁变量过期后,把它删除。其它客户端在锁变量过期后,就可以重新请求加锁,这就不会出现无法加锁的问题了。
我们再来看第二个风险。如果客户端 A 执行了 SETNX 命令加锁后,假设客户端 B 执行了 DEL 命令释放锁,此时,客户端 A 的锁就被误释放了。如果客户端 C 正好也在申请加锁,就可以成功获得锁,进而开始操作共享数据。这样一来,客户端 A 和 C 同时在对共享数据进行操作,数据就会被修改错误,这也是业务层不能接受的。
为了应对这个问题,我们需要能区分来自不同客户端的锁操作,具体咋做呢?其实,我们可以在锁变量的值上想想办法。
在使用 SETNX 命令进行加锁的方法中,我们通过把锁变量值设置为 1 或 0,表示是否加锁成功。1 和 0 只有两种状态,无法表示究竟是哪个客户端进行的锁操作。所以,我们在加锁操作时,可以让每个客户端给锁变量设置一个唯一值,这里的唯一值就可以用来标识当前操作的客户端。在释放锁操作时,客户端需要判断,当前锁变量的值是否和自己的唯一标识相等,只有在相等的情况下,才能释放锁。这样一来,就不会出现误释放锁的问题了。
知道了解决方案,那么,在 Redis 中,具体是怎么实现的呢?我们再来了解下。
在查看具体的代码前,我要先带你学习下 Redis 的 SET 命令。
我们刚刚在说 SETNX 命令的时候提到,对于不存在的键值对,它会先创建再设置值(也就是“不存在即设置”),为了能达到和 SETNX 命令一样的效果,Redis 给 SET 命令提供了类似的选项 NX,用来实现“不存在即设置”。如果使用了 NX 选项,SET 命令只有在键值对不存在时,才会进行设置,否则不做赋值操作。此外,SET 命令在执行时还可以带上 EX 或 PX 选项,用来设置键值对的过期时间。
举个例子,执行下面的命令时,只有 key 不存在时,SET 才会创建 key,并对 key 进行赋值。另外,key 的存活时间由 seconds 或者 milliseconds 选项值来决定。
SET key value [EX seconds | PX milliseconds] [NX]
有了 SET 命令的 NX 和 EX/PX 选项后,我们就可以用下面的命令来实现加锁操作了。
// 加锁, unique_value作为客户端唯一性的标识
SET lock_key unique_value NX PX 10000
其中,unique_value 是客户端的唯一标识,可以用一个随机生成的字符串来表示,PX 10000 则表示 lock_key 会在 10s 后过期,以免客户端在这期间发生异常而无法释放锁。
因为在加锁操作中,每个客户端都使用了一个唯一标识,所以在释放锁操作时,我们需要判断锁变量的值,是否等于执行释放锁操作的客户端的唯一标识,如下所示:
//释放锁 比较unique_value是否相等,避免误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end这是使用 Lua 脚本(unlock.script)实现的释放锁操作的伪代码,其中,KEYS[1]表示 lock_key,ARGV[1]是当前客户端的唯一标识,这两个值都是我们在执行 Lua 脚本时作为参数传入的。
最后,我们执行下面的命令,就可以完成锁释放操作了。
redis-cli --eval unlock.script lock_key , unique_value
你可能也注意到了,在释放锁操作中,我们使用了 Lua 脚本,这是因为,释放锁操作的逻辑也包含了读取锁变量、判断值、删除锁变量的多个操作,而 Redis 在执行 Lua 脚本时,可以以原子性的方式执行,从而保证了锁释放操作的原子性。
好了,到这里,你了解了如何使用 SET 命令和 Lua 脚本在 Redis 单节点上实现分布式锁。但是,我们现在只用了一个 Redis 实例来保存锁变量,如果这个 Redis 实例发生故障宕机了,那么锁变量就没有了。此时,客户端也无法进行锁操作了,这就会影响到业务的正常执行。所以,我们在实现分布式锁时,还需要保证锁的可靠性。那怎么提高呢?这就要提到基于多个 Redis 节点实现分布式锁的方式了。
基于多个 Redis 节点实现高可靠的分布式锁
当我们要实现高可靠的分布式锁时,就不能只依赖单个的命令操作了,我们需要按照一定的步骤和规则进行加解锁操作,否则,就可能会出现锁无法工作的情况。“一定的步骤和规则”是指啥呢?其实就是分布式锁的算法。
为了避免 Redis 实例故障而导致的锁无法工作的问题,Redis 的开发者 Antirez 提出了分布式锁算法 Redlock。
Redlock 算法的基本思路,是让客户端和多个独立的 Redis 实例依次请求加锁,如果客户端能够和半数以上的实例成功地完成加锁操作,那么我们就认为,客户端成功地获得分布式锁了,否则加锁失败。这样一来,即使有单个 Redis 实例发生故障,因为锁变量在其它实例上也有保存,所以,客户端仍然可以正常地进行锁操作,锁变量并不会丢失。
我们来具体看下 Redlock 算法的执行步骤。Redlock 算法的实现需要有 N 个独立的 Redis 实例。接下来,我们可以分成 3 步来完成加锁操作。
第一步是,客户端获取当前时间。
第二步是,客户端按顺序依次向 N 个 Redis 实例执行加锁操作。
这里的加锁操作和在单实例上执行的加锁操作一样,使用 SET 命令,带上 NX,EX/PX 选项,以及带上客户端的唯一标识。当然,如果某个 Redis 实例发生故障了,为了保证在这种情况下,Redlock 算法能够继续运行,我们需要给加锁操作设置一个超时时间。
如果客户端在和一个 Redis 实例请求加锁时,一直到超时都没有成功,那么此时,客户端会和下一个 Redis 实例继续请求加锁。加锁操作的超时时间需要远远地小于锁的有效时间,一般也就是设置为几十毫秒。
第三步是,一旦客户端完成了和所有 Redis 实例的加锁操作,客户端就要计算整个加锁过程的总耗时。
客户端只有在满足下面的这两个条件时,才能认为是加锁成功。
在满足了这两个条件后,我们需要重新计算这把锁的有效时间,计算的结果是锁的最初有效时间减去客户端为获取锁的总耗时。如果锁的有效时间已经来不及完成共享数据的操作了,我们可以释放锁,以免出现还没完成数据操作,锁就过期了的情况。
当然,如果客户端在和所有实例执行完加锁操作后,没能同时满足这两个条件,那么,客户端向所有 Redis 节点发起释放锁的操作。
Dans l'algorithme Redlock, l'opération de libération du verrou est la même que l'opération de libération du verrou sur une seule instance. Il suffit d'exécuter le script Lua qui libère le verrou. De cette façon, tant que plus de la moitié des N instances Redis peuvent fonctionner normalement, le fonctionnement normal du verrou distribué peut être garanti.
Ainsi, dans les applications métier réelles, si vous souhaitez améliorer la fiabilité des verrous distribués, vous pouvez y parvenir grâce à l'algorithme Redlock.
Apprentissage recommandé : Tutoriel d'apprentissage Redis
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
 Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
 Quelles données le cache Redis stocke-t-il généralement ?
Quelles données le cache Redis stocke-t-il généralement ?
 Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



