


Cet article vous apporte des connaissances pertinentes sur les journaux MySQL. Ce sur quoi nous devons nous concentrer est le journal binaire (binlog) et le journal des transactions (y compris le journal de rétablissement et le journal d'annulation, j'espère que cela sera utile à tout le monde).

Binlog est utilisé pour enregistrer les informations sur les opérations d'écriture (hors requêtes) effectuées par la base de données et est enregistrée sous forme binaire sur le disque. Binlog est le journal logique de MySQL et est enregistré par la couche serveur. Les bases de données Mysql utilisant n'importe quel moteur de stockage enregistreront les journaux binlog.
Binlog ; est écrit en ajoutant. Vous pouvez définir la taille de chaque fichier binlog via le paramètre max_binlog_size Lorsque la taille du fichier atteint une valeur donnée, un nouveau fichier sera généré pour enregistrer le journal.
Scénarios d'utilisation de Binlog
Projet Dans les applications pratiques, il existe deux principaux scénarios d'utilisation de binlog, à savoir la réplication maître-esclave et la récupération de données.
Principe de synchronisation maître-esclave MySQL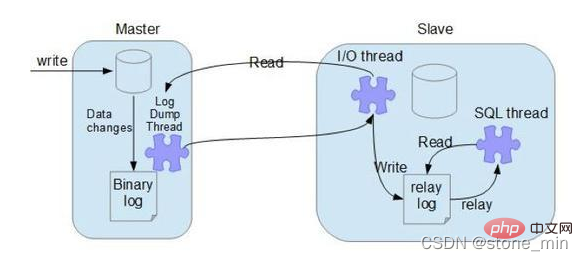
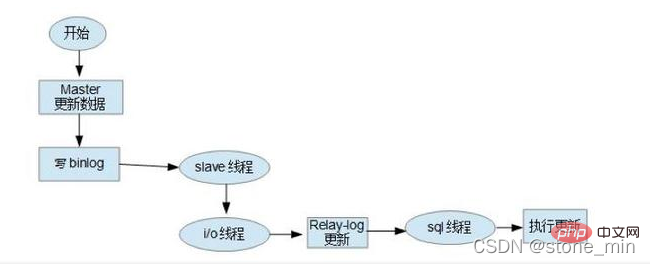
Contenu du binlog
Comme mentionné ci-dessus, binlog est un journal logique, qui peut être simplement compris comme une instruction SQL, mais en fait, cela inclut également l'exécution de la logique inverse de l'instruction SQL. delete correspond à la suppression elle-même et la mise à jour d'insertion inverse contient des informations sur les lignes de données avant et après l'exécution de la mise à jour correspondante, l'insertion contient sa propre insertion et les informations de suppression correspondantes.
format binlog
Il existe trois formats de binlog, à savoir instruction, ligne et mixte. Avant MySQL 5.7.7, l'instruction était utilisée par défaut, et après MySQL 5.7.7, la ligne était utilisée par défaut. Le format du journal peut être modifié via binlog-format dans le fichier de configuration my.ini.
(1) Déclaration : Réplication basée sur les instructions (SBR), chaque instruction SQL qui modifie les données sera enregistrée dans le binlog.
(2)row : réplication basée sur les lignes (RBR), qui n'enregistre pas les informations liées au contexte de l'instruction SQL, mais enregistre les détails de l'enregistrement qui a été modifié.
(3) mixte : selon ce qui précède, l'instruction et la ligne ; Chacun a ses propres avantages et inconvénients, c'est pourquoi la version mixte est apparue, mélangeant les deux. Dans des circonstances normales, le format d'instruction est utilisé pour l'enregistrement. Lorsque l'instruction ne peut pas être résolue, passez au format de ligne pour l'enregistrement.
En particulier, comme mentionné ci-dessus, la nouvelle version (après MySQL 5.7.7) utilise le format de ligne par défaut. La ligne ici a également été optimisée en conséquence. Lors de l'opération de modification de table, le format d'instruction est utilisé pour l'enregistrement. les autres opérations utilisent toujours le format de ligne.
Minutage de vidage du binlog
Pour le moteur de stockage InnoDB, le binlog ne sera enregistré que lorsque la transaction est soumise. À ce moment, l'enregistrement est toujours dans la mémoire. MySQL contrôle le timing de vidage du binlog via sync_binlog, et le. la plage de valeurs est 0-N :
Comme le montre ce qui précède, le paramètre le plus sûr pour sync_binlog est 1, qui est également la valeur par défaut pour les versions MySQL après 5.7.7. Toutefois, la définition d'une valeur plus élevée peut améliorer les performances de la base de données. Par conséquent, dans des situations réelles, vous pouvez également augmenter la valeur de manière appropriée et sacrifier un certain degré de cohérence pour obtenir de meilleures performances.
Taille physique du fichier binlog
Dans le fichier de configuration my.ini, la taille du binlog peut être configurée via max_binlog_size. Lorsque le volume du journal dépasse la taille du fichier binlog, le système régénérera un nouveau fichier pour continuer à enregistrer le fichier. Que dois-je faire lorsqu'une transaction est relativement importante, ou lorsqu'il y a de plus en plus de logs et que l'espace physique qu'elle occupe est trop grand ? MySQL fournit un mécanisme de suppression automatique, qui peut être résolu en configurant le paramètre expire_logs_days dans le fichier de configuration my.ini. L'unité est en jours. Lorsque ce paramètre est à 0, cela signifie qu'il ne sera jamais supprimé ; lorsqu'il est à N, cela signifie qu'il sera automatiquement supprimé après le Nième jour.
redolog est le système de journalisation propriétaire du moteur InnoDB. Il est principalement utilisé pour assurer la durabilité des transactions et des fonctions anti-collision. Redolog est un journal physique qui enregistre les modifications spécifiques sur la page de données après l'exécution de l'instruction SQL.
Nous savons tous que lorsque MySQL est en cours d'exécution, les données seront chargées du disque vers la mémoire. Lorsqu'une instruction SQL est exécutée pour modifier les données, le contenu modifié n'est en fait que temporairement enregistré dans la mémoire. Si l'alimentation est coupée ou si d'autres circonstances se produisent à ce moment-là, ces modifications seront perdues. Par conséquent, après avoir modifié les données, MySQL recherchera des opportunités pour vider ces enregistrements mémoire sur le disque. Mais il existe un problème de performances, principalement sous deux aspects :
InnoDB interagit avec le disque en unités de données de pages, et une transaction ne peut modifier que quelques octets sur une page si le renvoi de pages de données complètes sur le disque est un problème. gaspillage de ressources ;
Une transaction peut impliquer plusieurs pages de données. Ces pages de données ne sont que logiquement continues mais pas physiquement continues. Les performances de l'utilisation d'E/S aléatoires sont trop faibles.
Par conséquent, MySQL a conçu Redolog pour enregistrer les modifications spécifiques apportées ; la page de données par la transaction, puis videz le redolog sur le disque. Vous avez peut-être des doutes. À l’origine, je voulais réduire io. Cela n’ajouterait-il pas un autre io ? Les concepteurs d'InnoDB en ont tenu compte dès le début de la conception. Les fichiers Redolog sont généralement relativement petits et le processus de retour sur disque est une E/S séquentielle, qui offre de meilleures performances qu'une E/S aléatoire.
Concept de base du redo log
redo log se compose de deux parties, l'une est le tampon de journalisation dans la mémoire et l'autre est le fichier de journalisation sur le disque. Chaque fois que l'enregistrement de données est modifié, ces modifications seront d'abord écrites dans le tampon de journalisation, puis attendront l'opportunité appropriée pour vider les modifications de la mémoire dans le fichier de journalisation. Cette technologie consistant à écrire d'abord des journaux, puis à écrire sur le disque, est la technologie WAL (Write-Ahead Logging). Il convient de noter que le redolog est renvoyé sur le disque avant la page de données. Les modifications apportées à l'index clusterisé, à l'index secondaire et à la page d'annulation doivent toutes être enregistrées dans le redolog.
Dans les systèmes d'exploitation informatiques, les données du tampon dans l'espace utilisateur ne peuvent généralement pas être écrites directement sur le disque et doivent passer par le tampon d'espace du noyau du système d'exploitation (OS Buffer). Par conséquent, l'écriture du tampon de journalisation dans le fichier de journalisation l'écrit d'abord dans le tampon du système d'exploitation, puis le vide dans le fichier de journalisation via l'appel système fsync(). Le processus est le suivant : 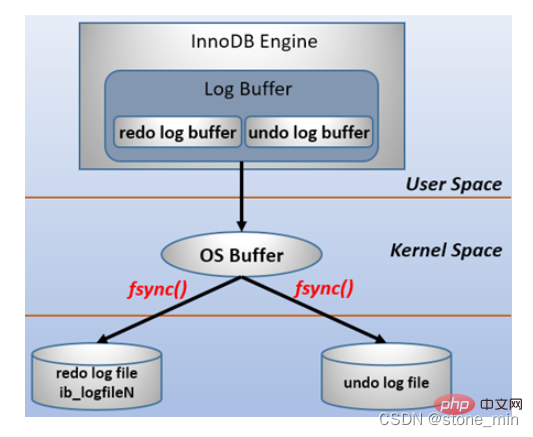
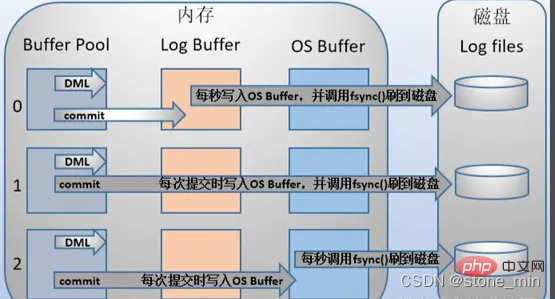
Mysql en prend en charge trois. types de tampon de journalisation Le moment d'écriture du fichier de journalisation peut être configuré via le paramètre innodb_flush_log_at_trx_commit La signification de chaque valeur de paramètre est la suivante :
| Valeur du paramètre | signifiant |
|---|---|
| 0 (retardé). écriture) | La restauration ne sera pas validée lorsque la transaction est soumise. Le journal dans le tampon du journal est écrit dans le tampon du système d'exploitation. Au lieu de cela, le journal est écrit dans le tampon du système d'exploitation toutes les secondes et fsync() est appelé pour l'écrire. le fichier de journalisation. En d'autres termes, lorsqu'il est défini sur 0, les données sont écrites sur le disque (environ) toutes les secondes. Lorsque le système tombe en panne, 1 seconde de données sera perdue. |
| 1 (écriture en temps réel, brossage en temps réel) | Chaque fois qu'une transaction est soumise, le journal dans le tampon de journalisation sera écrit dans le tampon du système d'exploitation et fsync() sera appelé pour le vider le fichier de journalisation. Cette méthode ne perdra aucune donnée même si le système tombe en panne, mais comme chaque soumission est écrite sur le disque, les performances d'E/S sont médiocres. |
| 2 (écriture en temps réel, brossage différé) | Chaque soumission est uniquement écrite dans le tampon du système d'exploitation, puis fsync() est appelée toutes les secondes pour écrire le journal dans le tampon du système d'exploitation dans le fichier de journalisation. |
redo log format d'enregistrement
redolog adopte un format d'écriture cyclique de taille fixe Lorsque le redolog est plein, il sera réécrit depuis le début. Pourquoi est-il conçu ainsi ?
L'objectif principal du redo log est de réduire le besoin de vidage des pages de données. Redolog enregistre les modifications sur la page de données, mais lorsque la page de données est également renvoyée sur le disque, ces enregistrements deviennent inutiles. Par conséquent, lorsque MySQL détermine que le redolog précédent a expiré, les nouvelles données écraseront les données non valides. Alors comment juger si cela doit être couvert ? 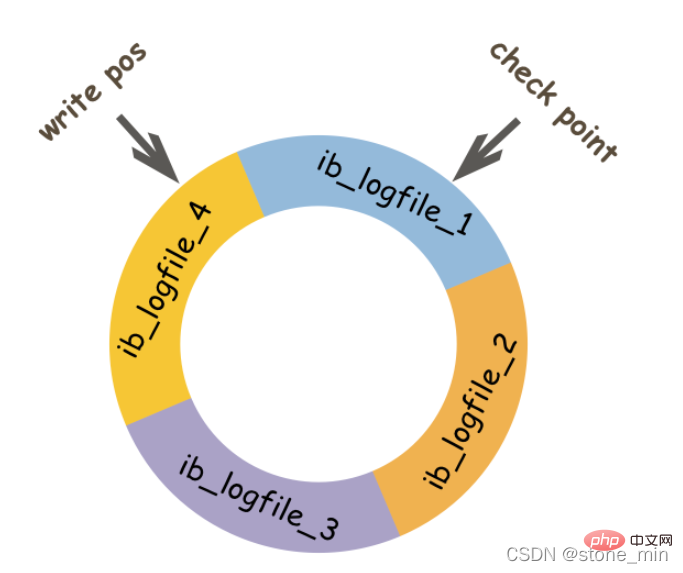
L'image ci-dessus est un diagramme schématique du fichier de journalisation redo. pos représente le numéro de séquence du journal LSN (numéro de séquence du journal) actuellement enregistré par redolog. Lorsque la page de données a été renvoyée sur le disque, le LSN dans le fichier de journalisation sera mis à jour, indiquant que les données avant que ce LSN n'ait été écrite sur le disque. Ce LSN est le point de contrôle. La partie entre le point de contrôle et le point de contrôle est la partie de rechange de redolog, qui est utilisée pour enregistrer de nouveaux enregistrements ; la partie entre le point de contrôle et le point de contrôle est la partie modifiée de la page de données que redolog a enregistrée, mais la page de données ne l'a pas fait. été renvoyé sur le disque à ce moment-là. Lorsque la position d'écriture rattrape le point de contrôle, elle poussera d'abord le point de contrôle vers l'avant, quittera la position, puis enregistrera un nouveau journal.
Lors du démarrage d'innodb, peu importe qu'il ait été arrêté normalement ou anormalement la dernière fois, l'opération de récupération sera toujours effectuée. Lors de la récupération, le LSN dans la page de données sera vérifié en premier. Si ce LSN est plus petit que le LSN dans le redolog, c'est-à-dire la position d'écriture, cela signifie que les opérations inachevées sur la page de données sont enregistrées dans le redolog, puis il commencera à partir du point de contrôle le plus proche, commencera à synchroniser les données.
Est-il possible que le LSN dans la page de données soit supérieur au LSN dans le redolog ? La réponse est bien sûr possible. Lorsque cela se produit, la partie au-delà du redolog ne sera pas refaite, car cela signifie en soi que ce qui a été fait n'a pas besoin d'être refait.
La différence entre le journal redo et le binlog
| redo log | binlog | |
|---|---|---|
| Taille du fichier | La taille du journal redo est fixe. | Binlog peut définir la taille de chaque fichier binlog via le paramètre de configuration max_binlog_size. |
| Méthode d'implémentation | redo log est implémenté par la couche moteur InnoDB, et tous les moteurs ne l'ont pas. | Binlog est implémenté par la couche serveur.Tous les moteurs peuvent utiliser les journaux binlog |
| Méthode d'enregistrement | redo log est enregistré dans une méthode d'écriture en boucle, il reviendra au début pour écrire les journaux. en boucle. | binlog est enregistré en ajoutant. Lorsque la taille du fichier est supérieure à la valeur donnée, les journaux suivants seront enregistrés dans de nouveaux fichiers |
| Scénarios applicables | redo log convient à la récupération en cas de crash (sans crash) | binlog Convient à la réplication maître-esclave et à la récupération de données |
Cela ressort de la différence entre binlog et redo log : le journal binlog est uniquement utilisé pour l'archivage, et s'appuyer uniquement sur binlog n'a pas de fonctionnalités de sécurité en cas de crash. Mais seul le journal redo ne fonctionnera pas, car le journal redo est unique à InnoDB et les enregistrements du journal seront écrasés après avoir été écrits sur le disque. Par conséquent, le binlog et le redo log doivent être enregistrés en même temps pour garantir que les données ne seront pas perdues lors de l'arrêt et du redémarrage de la base de données.
Soumission en deux étapes
Ce qui précède présente brièvement le redolog et le binlog lors de la modification des données, ils enregistreront ces modifications, mais l'un est un journal physique et l'autre est un journal logique. Alors, comment ont-ils effectué le processus de modification ?
Supposons qu'il y ait une instruction de mise à jour à exécuter maintenant, mise à jour à partir de l'ensemble table_name c=c+1 où id=2, le processus d'exécution est le suivant :
Le diagramme schématique est le suivant : 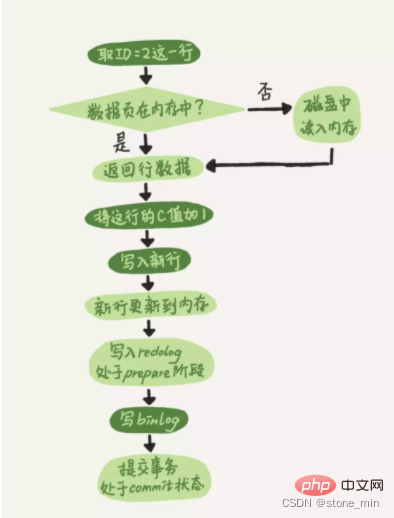
Ce processus de division de l'écriture redolog en deux étapes, préparation et validation, est appelé deux ; soumission en phase.
Redolog et binlog peuvent être utilisés pour représenter le statut de validation d'une transaction, et la validation en deux phases consiste à maintenir les deux états logiquement cohérents. Si vous n'utilisez pas de validation en deux phases, mais écrivez l'une d'abord, puis l'autre, cela peut poser des problèmes.
À l'heure actuelle, la mise à jour est toujours utilisée à titre d'exemple. Supposons que l'identifiant actuel = 2 et qu'il y ait un champ c = 0. Analysez respectivement les situations suivantes :
Écrivez d'abord redolog, puis écrivez binlog
Supposons que redolog soit écrit en premier lorsque redolog est terminé mais que binlog n'est pas terminé, MySQL va Une exception soudaine provoque un redémarrage. Étant donné que le redolog a été écrit auparavant, les enregistrements modifiés existent toujours après le redémarrage du système, donc la valeur de c dans cette ligne après la récupération est 1. Cependant, en raison du redémarrage du système, cet enregistrement n'existe pas dans le binlog. Lors d'une sauvegarde ultérieure du journal, cette instruction n'existe pas dans le journal binaire enregistré. Ensuite, vous constaterez que si vous devez utiliser ce binlog pour restaurer la bibliothèque temporaire, car le binlog de cette instruction est perdu, la bibliothèque temporaire ne sera pas mise à jour cette fois. La valeur de c dans la ligne restaurée est 0, ce qui est. la même chose que la valeur de la bibliothèque d'origine différente.
Écrivez d'abord binlog, puis redolog
Si vous écrivez d'abord binlog, puis redémarrez le système lors de l'écriture de redolog. Après le redémarrage, il n'y a aucun enregistrement de modification de c dans le redolog, et la valeur de c est toujours 0 pour le moment. Mais le journal "Changer c de 0 à 1" a été enregistré dans le binlog. Par conséquent, lorsque binlog est utilisé pour restaurer ultérieurement, une transaction supplémentaire sera générée. La valeur de c dans la ligne restaurée est 1, ce qui est différent de la valeur dans la base de données d'origine.
Donc, pour résumer, si vous écrivez d'abord un certain journal puis écrivez un autre journal, l'état de la base de données sera incohérent avec l'état de la bibliothèque restaurée à l'aide de binlog.
undolog est principalement utilisé pour enregistrer l'état avant qu'un certain enregistrement de ligne ne soit modifié et enregistre les données avant la modification. Dans ce cas, lorsque la transaction est annulée, les enregistrements peuvent être restaurés tels qu'ils étaient avant le démarrage de la transaction via undolog. L'atomicité et la durabilité des transactions sont également obtenues par undolog. Le journal d'annulation enregistre principalement les modifications logiques des données. Par exemple, une instruction INSERT correspond à un journal d'annulation DELETE. Pour chaque instruction UPDATE, elle correspond à un journal d'annulation UPDATE opposé, de sorte que lorsqu'une erreur se produit, il peut être lancé. retour à avant l'état des données. Dans le même temps, lors de la récupération des données, il est utilisé conjointement avec binlog et redolog pour garantir l'exactitude de la récupération des données.
Le processus fonctionnel d'undolog est le suivant : 
Il convient de noter que, comme redolog, l'annulation doit être renvoyée sur le disque avant la page de données. Lors de la récupération des données, si l'annulation de la connexion est terminée, la transaction peut être annulée en fonction de l'annulation de la connexion.
Dans une transaction, la même donnée peut être modifiée plusieurs fois, donc les enregistrements avant chaque modification doivent-ils être enregistrés dans l'undolog ? Dans ce cas, la quantité de journaux d'annulation sera trop importante et la redolog entrera en jeu à ce moment-là. Dans une transaction, si le même enregistrement est modifié, undolog enregistrera uniquement l'enregistrement d'origine avant le début de la transaction. Lorsque cet enregistrement est à nouveau modifié, redolog enregistrera les modifications ultérieures. Pendant la récupération des données, redolog termine la restauration et undolog termine la restauration. Les deux se coordonnent pour terminer la récupération des données. Le processus est le suivant : 
Une autre fonction est la chaîne de contrôle multi-version MVCC. Veuillez vous référer à cet article pour ce
Principe d'implémentation de MySQL MVCC
binlog, redolog et undolog sont les trois journaux les plus importants dans MySQL. récupération des données, les trois parties se coordonnent et coopèrent pour garantir l'exactitude de la récupération des données. 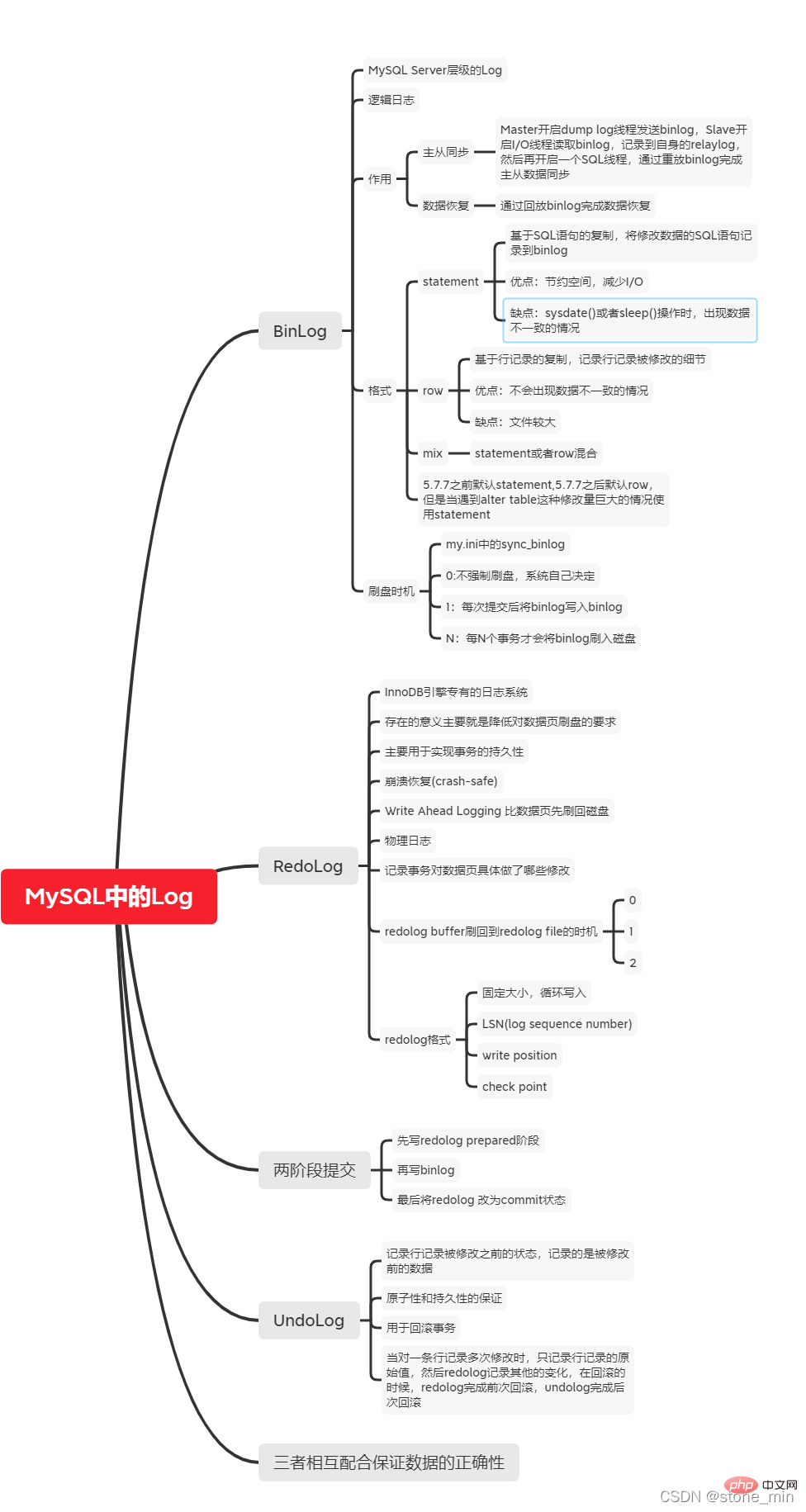
Apprentissage recommandé : Tutoriel vidéo mysql
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysql modifier le nom de la table de données
mysql modifier le nom de la table de données
 MySQL crée une procédure stockée
MySQL crée une procédure stockée
 La différence entre MongoDB et MySQL
La différence entre MongoDB et MySQL
 Comment vérifier si le mot de passe MySQL est oublié
Comment vérifier si le mot de passe MySQL est oublié
 mysql créer une base de données
mysql créer une base de données
 niveau d'isolement des transactions par défaut de MySQL
niveau d'isolement des transactions par défaut de MySQL
 La différence entre sqlserver et mysql
La différence entre sqlserver et mysql
 mysqlmot de passe oublié
mysqlmot de passe oublié









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



