


Cet article vous présentera 15 pièges que vous pouvez rencontrer lors de l'utilisation de Redis. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il sera utile à tout le monde.

Bonjour, je m'appelle Kaito.
Dans cet article, je souhaite vous parler des "fosses" que vous pouvez rencontrer lors de l'utilisation de Redis.
Si vous avez rencontré les scénarios « bizarres » suivants lors de l'utilisation de Redis, il est très probable que vous soyez entré dans un « gouffre » :
Évidemment, si une clé a un délai d'expiration défini, pourquoi n'expire-t-il pas ?
À l'aide de la commande SETBIT de complexité O(1), Redis a-t-il été OOMed ?
Exécutez RANDOMKEY et choisissez au hasard une clé. Cela bloquera-t-il Redis ?
Avec la même commande, pourquoi les données ne peuvent-elles pas être trouvées dans la base de données maître mais peuvent être trouvées dans la base de données esclave ?
Pourquoi la base de données esclave utilise-t-elle plus de mémoire que la base de données maître ?
Pourquoi les données écrites sur Redis sont-elles perdues inexplicablement ?
...
[Recommandations associées : Tutoriel vidéo Redis]
Qu'est-ce que c'est exactement Quelles sont les raisons de ces problèmes ?
Dans cet article, je passerai en revue avec vous les pièges que vous pouvez rencontrer lors de l'utilisation de Redis et comment les éviter.
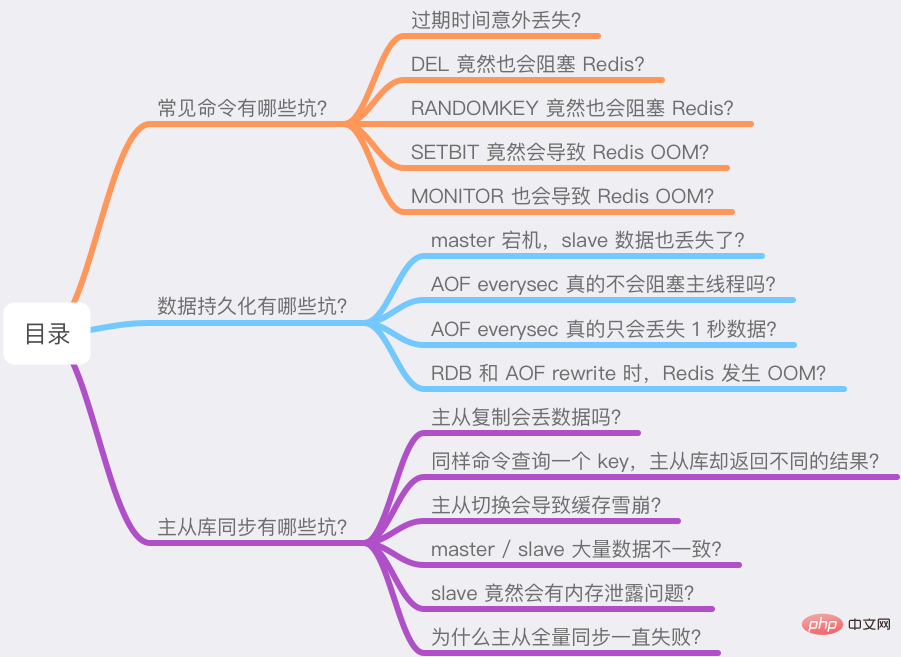
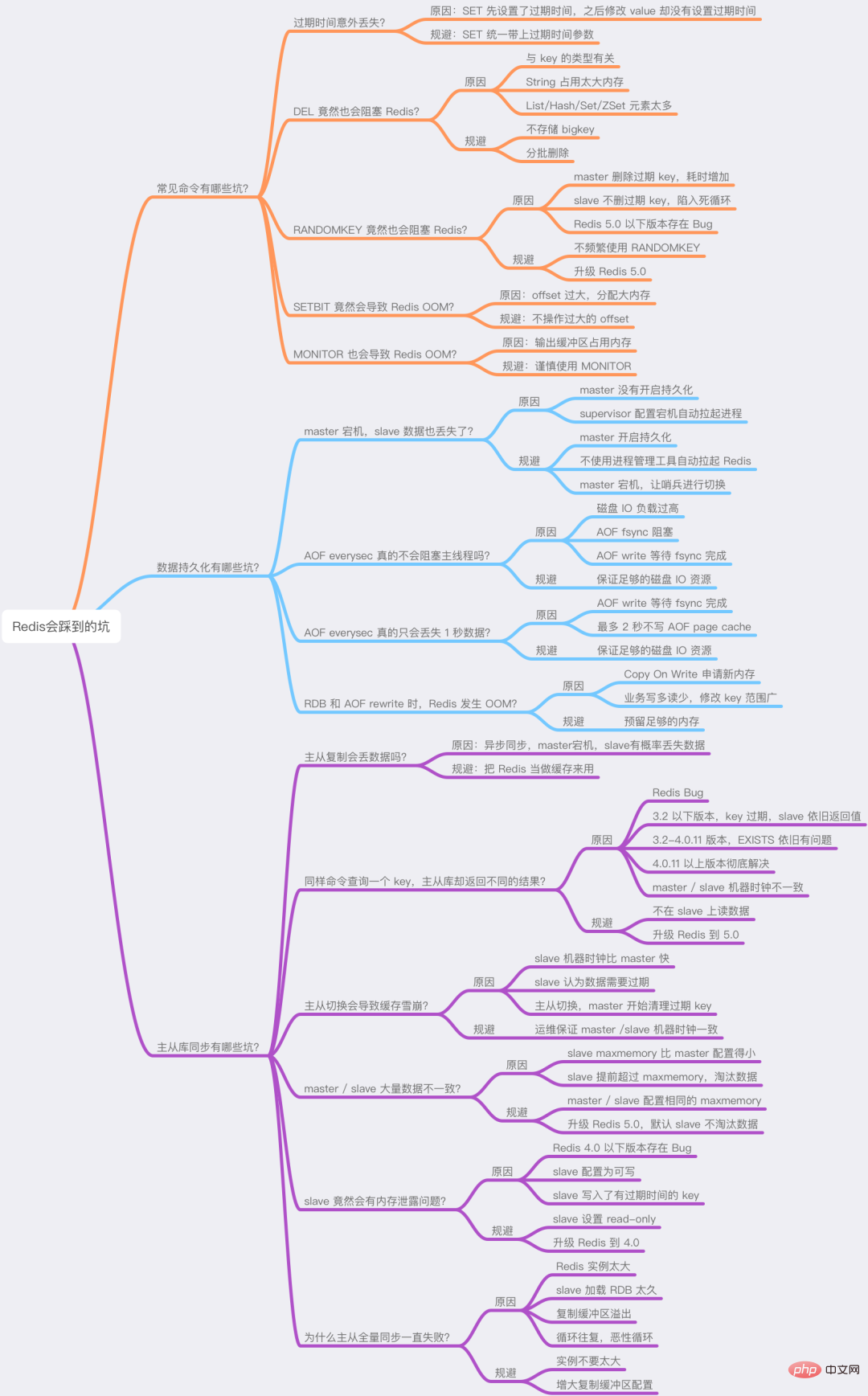
J'ai divisé ces questions en trois parties :
Quels sont les pièges des commandes courantes ?
Quels sont les pièges de la persistance des données ?
Quels sont les pièges de la synchronisation de bases de données maître-esclave ?
Les causes de ces problèmes sont susceptibles de « subvertir » votre compréhension. Si vous êtes prêt, alors suivez mes idées et commencez !
Cet article contient de nombreuses informations utiles, j'espère que vous pourrez le lire patiemment.
Tout d'abord, examinons quelques commandes courantes qui peuvent rencontrer des résultats « inattendus » lors de l'utilisation de Redis.
1) Date d'expiration perdue accidentellement ?
Lorsque vous utilisez Redis, vous devez souvent utiliser la commande SET, c'est très simple.
SET En plus de définir la valeur-clé, vous pouvez également définir le délai d'expiration de la clé, comme suit :
127.0.0.1:6379> SET testkey val1 EX 60 OK 127.0.0.1:6379> TTL testkey (integer) 59
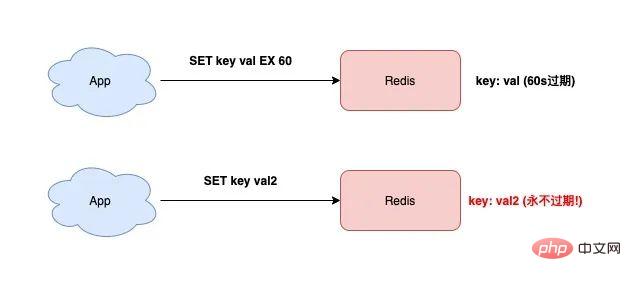
À ce moment, si vous souhaitez modifier la valeur de la clé, mais simplement Si vous utilisez la commande SET sans ajouter le paramètre "expiration time", le délai d'expiration de cette clé sera "effacé".
127.0.0.1:6379> SET testkey val2 OK 127.0.0.1:6379> TTL testkey // key永远不过期了! (integer) -1
L'avez-vous vu ? la clé de test n'expirera jamais !
Si vous venez de commencer à utiliser Redis, je pense que vous avez dû marcher sur cet écueil.
La raison de ce problème est : Si le délai d'expiration n'est pas défini dans la commande SET, Redis "effacera" automatiquement le délai d'expiration de la clé.
Si vous constatez que la mémoire de Redis continue de croître et que de nombreuses clés avaient initialement un délai d'expiration défini, mais que vous constatez plus tard que le délai d'expiration a été perdu, c'est probablement pour cette raison.
À ce moment-là, il y aura un grand nombre de clés non expirées dans votre Redis, consommant trop de ressources mémoire.
Ainsi, lorsque vous utilisez la commande SET, si vous définissez le délai d'expiration au début, puis lorsque vous modifiez la clé plus tard, vous devez également ajouter le paramètre de délai d'expiration pour éviter le problème de perte du délai d'expiration. .
2) DEL peut aussi bloquer Redis ?
Pour supprimer une clé, vous utiliserez certainement la commande DEL. Je me demande si vous n'avez pas pensé à sa complexité temporelle ?
O(1) ? Pas nécessairement.
Si vous lisez attentivement la documentation officielle de Redis, vous trouverez : Le temps nécessaire pour supprimer une clé est lié au type de clé.
La documentation officielle de Redis décrit la commande DEL comme suit :
la clé est de type String et la complexité temporelle DEL est O(1)
la clé est de type List/Hash/Set/ZSet, la complexité temporelle DEL est O(M), M est le nombre d'éléments
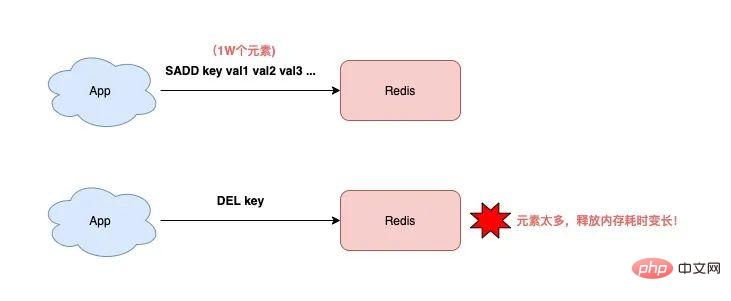
Dans en d’autres termes, si vous souhaitez supprimer une clé de type non String, plus la clé contient d’éléments, plus l’exécution de DEL sera longue !
Pourquoi ça ?
La raison est que lors de la suppression de ce type de clé, Redis doit libérer la mémoire de chaque élément tour à tour. Plus il y a d'éléments, plus ce processus prendra du temps.
Et une opération aussi longue bloquera inévitablement toute l'instance Redis et affectera les performances de Redis.
Ainsi, lorsque vous supprimez des clés de type List/Hash/Set/ZSet, vous devez prêter une attention particulière. Vous ne pouvez pas exécuter DEL sans cervelle, vous devez utiliser ce qui suit. méthode Supprimer :
Interroger le nombre d'éléments : Exécuter la commande LLEN/HLEN/SCARD/ZCARD
Juger le nombre d'éléments : Si le nombre d'éléments est petit, vous pouvez exécuter directement la suppression DEL, sinon supprimer par lots
Suppression par lots : exécuter LRANGE/HSCAN/SSCAN/ZSCAN + LPOP/RPOP/HDEL/SREM/ Suppression de ZREM
Après avoir compris l'impact de DEL sur les données de type List/Hash/Set/ZSet, analysons-le à nouveau. La suppression d'une clé de type String provoquera-t-elle ce problème ?
Hein ? N'ai-je pas mentionné plus tôt que le document officiel de Redis décrit que la complexité temporelle de la suppression d'une clé de type String est O(1) ? Cela ne bloquera pas Redis, n'est-ce pas ?
En fait, ce n’est pas forcément le cas !
Pensez-y, et si cette clé prenait beaucoup de mémoire ?
Par exemple, si cette clé stocke 500 Mo de données (évidemment, c'est une grosse clé), alors lors de l'exécution de DEL, cela prendra encore plus de temps !
En effet, il faut du temps à Redis pour libérer une mémoire aussi volumineuse au système d'exploitation, l'opération prendra donc plus de temps.
Donc, pour le type String, il vaut mieux ne pas stocker de données trop volumineuses, sinon il y aura des problèmes de performances lors de leur suppression.
À ce stade, vous pensez peut-être : Redis 4.0 n'a-t-il pas introduit le mécanisme sans paresseux ? Si ce mécanisme est activé, l'opération de libération de mémoire sera exécutée dans le thread d'arrière-plan. Cela ne bloquera-t-il pas le thread principal ?
C'est une très bonne question.
Est-ce vraiment le cas ?
Ici, je vais d'abord vous dire la conclusion : Même si le lazy-free est activé dans Redis, lors de la suppression d'une bigkey de type String, elle est toujours traitée dans le thread principal au lieu d'être exécutée dans un fil de fond. Il y a donc toujours un risque de bloquer Redis !
Pourquoi ça ?
Voici un indice. Les étudiants intéressés peuvent d’abord rechercher des informations connexes sans paresseux pour trouver la réponse. :)
3) RANDOMKEY peut aussi bloquer Redis ?En fait, il existe de nombreux points de connaissances sur le paresseux. Pour des raisons d'espace, je prévois d'écrire un article spécial plus tard pour continuer à y prêter attention. 🎜>
Si vous souhaitez afficher aléatoirement une clé dans Redis, vous utilisez généralement la commande RANDOMKEY.
Cette commande extraira "de manière aléatoire" une clé de Redis.
Comme c'est aléatoire, la vitesse d'exécution doit être très rapide, non ?
Ce n’est pas le cas.
Pour expliquer clairement ce problème, nous devons le combiner avec la stratégie d'expiration de Redis.
Si vous savez quelque chose sur la stratégie d'expiration de Redis, sachez que Redis nettoie les clés expirées en utilisant une combinaison de nettoyage programmé + de nettoyage paresseux.
Une fois que RANDOMKEY a extrait une clé au hasard, il vérifiera d'abord si la clé a expiré.
Si la clé a expiré, Redis la supprimera. Ce processus est un
nettoyage paresseux. Mais le nettoyage n'est pas encore terminé. Redis doit encore trouver une clé "non expirée" et la renvoyer au client.
À ce stade, Redis continuera à retirer une clé au hasard, puis à déterminer si elle a expiré, jusqu'à ce qu'une clé non expirée soit trouvée et renvoyée au client.
L'ensemble du processus est comme ceci :
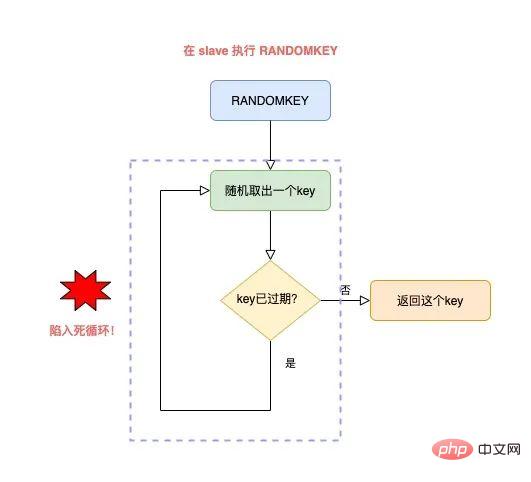
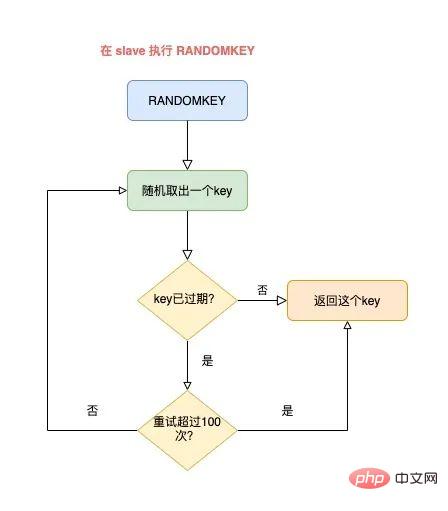
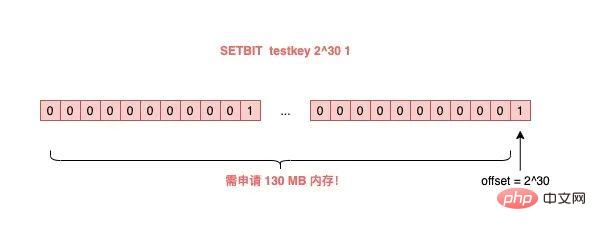
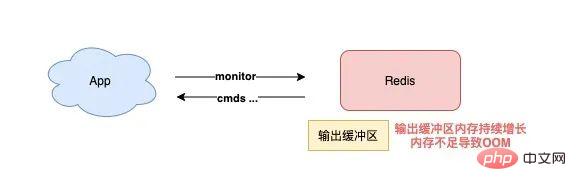
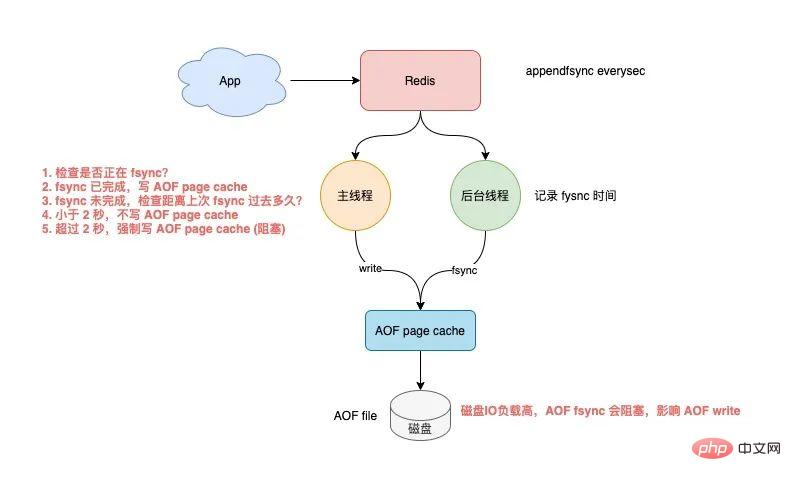
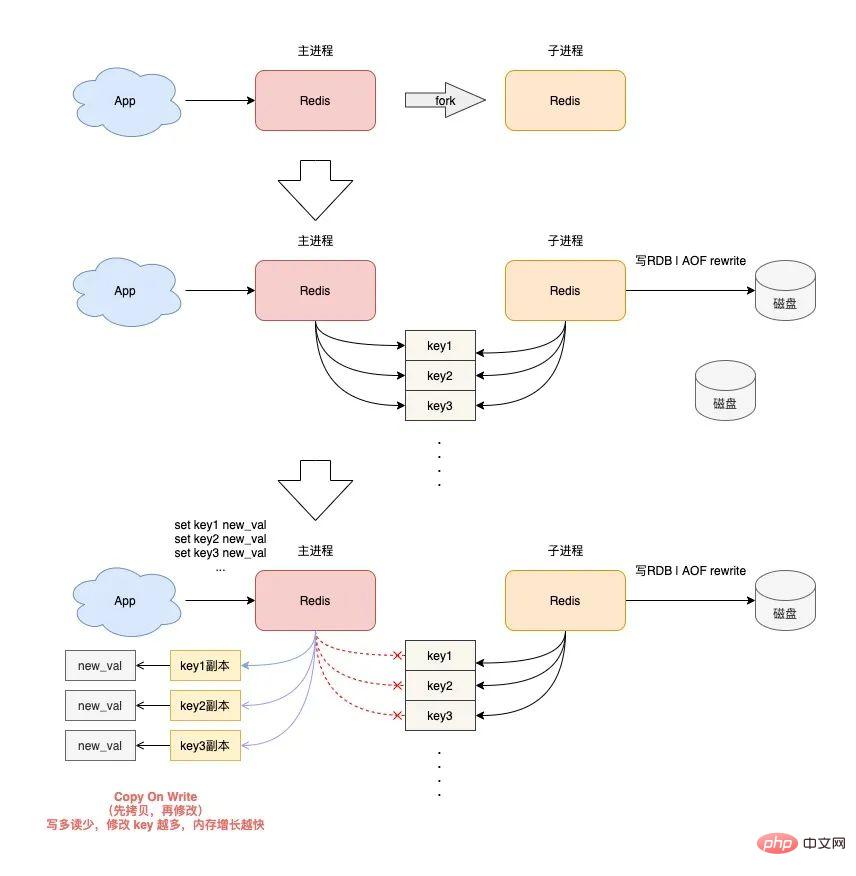
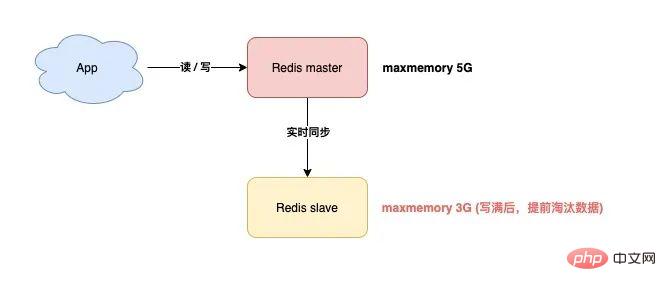
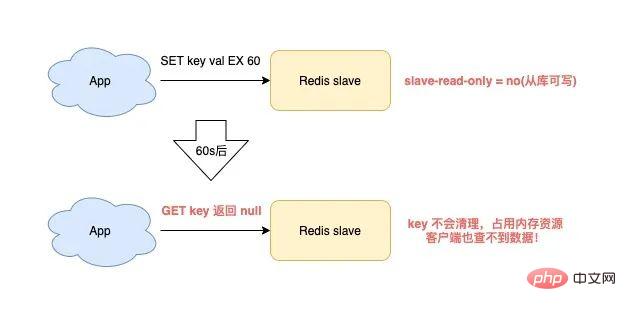
导致的结果就是,RANDOMKEY 执行耗时变长,影响 Redis 性能。 以上流程,其实是在 master 上执行的。 如果在 slave 上执行 RANDOMEKY,那么问题会更严重! 为什么? 主要原因就在于,slave 自己是不会清理过期 key。 那 slave 什么时候删除过期 key 呢? 其实,当一个 key 要过期时,master 会先清理删除它,之后 master 向 slave 发送一个 DEL 命令,告知 slave 也删除这个 key,以此达到主从库的数据一致性。 还是同样的场景:Redis 中存在大量已过期,但还未被清理的 key,那在 slave 上执行 RANDOMKEY 时,就会发生以下问题: slave 随机取出一个 key,判断是否已过期 key 已过期,但 slave 不会删除它,而是继续随机寻找不过期的 key 由于大量 key 都已过期,那 slave 就会寻找不到符合条件的 key,此时就会陷入「死循环」! 也就是说,在 slave 上执行 RANDOMKEY,有可能会造成整个 Redis 实例卡死! 是不是没想到?在 slave 上随机拿一个 key,竟然有可能造成这么严重的后果? 这其实是 Redis 的一个 Bug,这个 Bug 一直持续到 5.0 才被修复。 修复的解决方案是,在 slave 上执行 RANDOMKEY 时,会先判断整个实例所有 key 是否都设置了过期时间,如果是,为了避免长时间找不到符合条件的 key,slave 最多只会在哈希表中寻找 100 次,无论是否能找到,都会退出循环。 这个方案就是增加上了一个最大重试次数,这样一来,就避免了陷入死循环。 虽然这个方案可以避免了 slave 陷入死循环、卡死整个实例的问题,但是,在 master 上执行这个命令时,依旧有概率导致耗时变长。 所以,你在使用 RANDOMKEY 时,如果发现 Redis 发生了「抖动」,很有可能是因为这个原因导致的! 4) O(1) 复杂度的 SETBIT,竟然会导致 Redis OOM? 在使用 Redis 的 String 类型时,除了直接写入一个字符串之外,还可以把它当做 bitmap 来用。 具体来讲就是,我们可以把一个 String 类型的 key,拆分成一个个 bit 来操作,就像下面这样: 其中,操作的每一个 bit 位叫做 offset。 但是,这里有一个坑,你需要注意起来。 如果这个 key 不存在,或者 key 的内存使用很小,此时你要操作的 offset 非常大,那么 Redis 就需要分配「更大的内存空间」,这个操作耗时就会变长,影响性能。 所以,当你在使用 SETBIT 时,也一定要注意 offset 的大小,操作过大的 offset 也会引发 Redis 卡顿。 这种类型的 key,也是典型的 bigkey,除了分配内存影响性能之外,在删除它时,耗时同样也会变长。 5) 执行 MONITOR 也会导致 Redis OOM? 这个坑你肯定听说过很多次了。 当你在执行 MONITOR 命令时,Redis 会把每一条命令写到客户端的「输出缓冲区」中,然后客户端从这个缓冲区读取服务端返回的结果。 但是,如果你的 Redis QPS 很高,这将会导致这个输出缓冲区内存持续增长,占用 Redis 大量的内存资源,如果恰好你的机器的内存资源不足,那 Redis 实例就会面临被 OOM 的风险。 Vous devez donc utiliser MONITOR avec prudence, surtout lorsque le QPS est élevé. Les scénarios problématiques ci-dessus se produisent tous lorsque nous utilisons des commandes courantes, et ils sont susceptibles d'être déclenchés "involontairement". Jetons un coup d'œil aux pièges de la « persistance des données » de Redis ? La persistance des données Redis est divisée en deux méthodes : RDB et AOF. Parmi eux, RDB est un instantané de données, et AOF enregistrera chaque commande d'écriture dans un fichier journal. Les problèmes de persistance des données sont principalement concentrés dans ces deux blocs. 1) Le maître est en panne et les données de l'esclave sont également perdues ? Si votre Redis est déployé dans le mode suivant, une perte de données se produira : instance de déploiement maître-esclave + sentinelle le maître n'active pas la fonction de persistance des données Le processus Redis est géré par le superviseur et est configuré comme "temps d'arrêt du processus, redémarrage automatique" Si le maître est en panne à ce moment-là, cela provoquera les problèmes suivants : Le maître est en panne et la sentinelle n'a pas initié le changement à ce moment-là, le processus maître est immédiatement automatiquement extrait par le superviseur Mais le maître n'active aucune persistance des données, et c'est une instance "vide" après le démarrage A ce moment, l'esclave est afin d'être cohérent avec le maître, il "effacera" automatiquement toutes les données de l'instance, et l'esclave deviendra également une instance "vide" L'avez-vous vu ? Dans ce scénario, toutes les données maître/esclave sont perdues. À ce moment-là, lorsque l'application métier accède à Redis et constate qu'il n'y a aucune donnée dans le cache, elle enverra toutes les requêtes à la base de données principale, ce qui déclenchera en outre une « avalanche de cache » et aura. un grand impact sur l'entreprise. Vous devez donc éviter que cette situation ne se produise. Mon conseil est le suivant : Les instances Redis sont automatiquement extraites sans utiliser d'outils de gestion de processus Une fois le maître tombé en panne, laissez la sentinelle lancer le changement et promouvoir l'esclave au rang de maître Une fois le changement terminé, redémarrez le maître et laissez-le dégénérer into slave Vous devez éviter ce problème lors de la configuration de la persistance des données. 2) AOF Everysec ne bloque-t-il vraiment pas le thread principal ? Lorsque Redis active AOF, vous devez configurer la stratégie de vidage AOF. Basé sur l'équilibre entre performances et sécurité des données, vous adopterez certainement la solution appendfsync Everysec. Le mode de fonctionnement de cette solution est que le thread d'arrière-plan de Redis vide les données du cache de la page AOF sur le disque (fsync) toutes les 1 seconde. L'avantage de cette solution est que l'opération fastidieuse de brossage de disque AOF est exécutée dans le thread d'arrière-plan, évitant ainsi l'impact sur le thread principal. Mais cela n’affecte-t-il vraiment pas le fil principal ? La réponse est non. En fait, il existe un tel scénario : Lorsque le thread d'arrière-plan Redis effectue un vidage du cache de page AOF (fysnc), si la charge d'E/S du disque est trop élevée à ce moment-là, l'appel à fsync sera bloqué. À l'heure actuelle, le thread principal reçoit toujours des demandes d'écriture, donc le thread principal à ce moment déterminera d'abord si le dernier thread d'arrière-plan a réussi à vider le disque. Comment juger ? Une fois le flash du disque réussi, le fil d'arrière-plan enregistrera la durée du flash. Le fil principal utilisera ce temps pour déterminer combien de temps s'est écoulé depuis le dernier pinceau. L'ensemble du processus est comme ceci : Avant d'écrire le cache de la page AOF (appel système d'écriture), le thread principal vérifie d'abord si la fsync en arrière-plan est terminée ? fsync est terminé, le thread principal écrit directement dans le cache de la page AOF fsync n'est pas terminé, puis vérifiez combien de temps s'est écoulé depuis le dernier fsync ? Si c'est dans les 2 secondes du dernier succès fysnc, le thread principal reviendra directement sans écrire dans le cache de la page AOF Si c'est dans les 2 secondes. Si fysnc réussit pendant plus de 2 secondes, le thread principal forcera l'écriture du cache de la page AOF (appel système d'écriture) En raison de la charge élevée d'E/S du disque, à ce moment-là temps, le thread d'arrière-plan fynsc bloquera, le thread principal bloquera également et attendra lors de l'écriture du cache de la page AOF (fonctionner de la même manière fd, fsync et write s'exclut mutuellement, une partie doit attendre que l'autre réussisse avant de pouvoir continuer l'exécution , sinon il bloquera et attendra) Grâce à l'analyse, nous pouvons constater que même si la stratégie de vidage AOF que vous configurez est appendfsync toutes les secondes, il existe toujours le risque de bloquer le thread principal. En fait, le point clé de ce problème est que la charge d'E/S du disque est trop élevée, provoquant le blocage de fynsc, ce qui à son tour provoque le blocage du thread principal lors de l'écriture dans le cache de la page AOF. Vous devez donc vous assurer que le disque dispose de suffisamment de ressources IO pour éviter ce problème. 3) AOF chaque seconde ne perd vraiment qu'1 seconde de données ? Continuez à analyser les questions ci-dessus. Comme mentionné ci-dessus, nous devons ici nous concentrer sur l'étape 4 ci-dessus. C'est-à-dire : lorsque le thread principal écrit le cache de la page AOF, il déterminera d'abord l'heure à laquelle la dernière fsync a réussi. Si c'est dans les 2 secondes suivant le dernier succès fysnc, le thread principal reviendra directement. et n'écrivez plus le cache des pages AOF. Cela signifie que lorsque le thread d'arrière-plan exécute fsync pour vider le disque, le thread principal attendra jusqu'à 2 secondes et n'écrira pas dans le cache de la page AOF. Si Redis plante à ce moment-là, alors 2 secondes de données seront perdues dans le fichier AOF, pas 1 seconde ! Poursuivons notre analyse. Pourquoi le thread principal Redis attend-il 2 secondes sans écrire dans le cache de la page AOF ? En fait, lorsque Redis AOF est configuré en appendfsync toutes les secondes, normalement, le thread d'arrière-plan exécute fsync flush toutes les 1 seconde si les ressources disque sont suffisantes, il ne sera pas bloqué. En d'autres termes, le thread principal Redis n'a pas réellement besoin de se soucier de savoir si le thread d'arrière-plan se vide correctement, tant qu'il écrit le cache de la page AOF sans réfléchir. Cependant, l'auteur de Redis a considéré que si les ressources d'E/S du disque sont relativement limitées à ce moment-là, le thread d'arrière-plan fsync peut être bloqué. Ainsi, avant que l'auteur Redis n'écrive le cache de la page AOF dans le thread principal, il vérifie d'abord le temps écoulé depuis la dernière fsync réussie. S'il est supérieur à 1 seconde et échoue, le thread principal le saura. moment où fsync peut être bloqué. Ainsi, le thread principal attendra 2 secondes sans écrire le cache de la page AOF. Le but est de : Réduire le risque de blocage du thread principal (si vous le souhaitez). écrivez le cache de la page AOF sans réfléchir), le thread principal se bloquera immédiatement) Si fsync bloque, le thread principal laissera 1 seconde au thread d'arrière-plan pour attendre que fsync réussisse Mais le prix est que si un temps d'arrêt survient à ce moment-là, AOF perdra 2 secondes de données au lieu d'1 seconde. Cette solution devrait être un compromis supplémentaire entre performances et sécurité des données par l'auteur Redis. Quoi qu'il en soit, tout ce que vous devez savoir ici, c'est que même si AOF est configuré pour vider les disques toutes les secondes, lorsque la situation extrême ci-dessus se produit, les données perdues par AOF sont en réalité de 2 secondes. 4) Le MOO se produit dans Redis lors de la réécriture de RDB et AOF ? Enfin, examinons les problèmes qui surviennent lorsque Redis effectue des instantanés RDB et une réécriture AOF. Lorsque Redis effectue un instantané RDB et une réécriture AOF, il crée un processus enfant pour conserver les données de l'instance sur le disque. La création d'un processus enfant appellera la fonction fork du système d'exploitation. Une fois l'exécution du fork terminée, le processus parent et le processus enfant partageront les mêmes données de mémoire en même temps. Mais le processus principal à ce stade peut toujours recevoir des demandes d'écriture, et les demandes d'écriture entrantes utiliseront Copy On Write pour exploiter les données de la mémoire. En d'autres termes, une fois que le processus principal a des données qui doivent être modifiées, Redis ne modifiera pas directement les données dans la mémoire existante, mais copiera d'abord les données de la mémoire, puis modifiera les données dedans. la nouvelle mémoire, c'est ce qu'on appelle "copie sur écriture". La copie sur écriture peut également être comprise comme signifiant que celui qui a besoin d'écrire le copiera d'abord puis le modifiera. Vous auriez dû découvrir que si le processus parent veut modifier une clé, il doit copier les données de la mémoire d'origine dans la nouvelle mémoire. Ce processus implique l'application d'une "nouvelle mémoire". Si les caractéristiques de votre entreprise sont "plus d'écriture et moins de lecture" et que l'OPS est très élevé, alors beaucoup de travail de copie de mémoire sera généré lors de la réécriture RDB et AOF. Quel est le problème avec ça ? Comme il existe de nombreuses demandes d'écriture, le processus parent Redis demandera beaucoup de mémoire. Pendant cette période, plus la portée de la modification de clé est large, plus de nouvelles applications mémoire sont nécessaires. Si votre machine ne dispose pas de ressources mémoire suffisantes, cela exposera Redis à un risque de MOO ! 这就是你会从 DBA 同学那里听到的,要给 Redis 机器预留内存的原因。 其目的就是避免在 RDB 和 AOF rewrite 期间,防止 Redis OOM。 以上这些,就是「数据持久化」会遇到的坑,你踩到过几个? 下面我们再来看「主从复制」会存在哪些问题。 Redis 为了保证高可用,提供了主从复制的方式,这样就可以保证 Redis 有多个「副本」,当主库宕机后,我们依旧有从库可以使用。 在主从同步期间,依旧存在很多坑,我们依次来看。 1) 主从复制会丢数据吗? 首先,你需要知道,Redis 的主从复制是采用「异步」的方式进行的。 这就意味着,如果 master 突然宕机,可能存在有部分数据还未同步到 slave 的情况发生。 这会导致什么问题呢? 如果你把 Redis 当做纯缓存来使用,那对业务来说没有什么影响。 master 未同步到 slave 的数据,业务应用可以从后端数据库中重新查询到。 但是,对于把 Redis 当做数据库,或是当做分布式锁来使用的业务,有可能因为异步复制的问题,导致数据丢失 / 锁丢失。 关于 Redis 分布式锁可靠性的更多细节,这里先不展开,后面会单独写一篇文章详细剖析这个知识点。这里你只需要先知道,Redis 主从复制是有概率发生数据丢失的。 2) 同样命令查询一个 key,主从库却返回不同的结果? 不知道你是否思考过这样一个问题:如果一个 key 已过期,但这个 key 还未被 master 清理,此时在 slave 上查询这个 key,会返回什么结果呢? slave 正常返回 key 的值 slave 返回 NULL 你认为是哪一种?可以思考一下。 答案是:不一定。 嗯?为什么会不一定? 这个问题非常有意思,请跟紧我的思路,我会带你一步步分析其中的原因。 其实,返回什么结果,这要取决于以下 3 个因素: Redis 的版本 具体执行的命令 机器时钟 先来看 Redis 版本。 如果你使用的是 Redis 3.2 以下版本,只要这个 key 还未被 master 清理,那么,在 slave 上查询这个 key,它会永远返回 value 给你。 也就是说,即使这个 key 已过期,在 slave 上依旧可以查询到这个 key。 但如果此时在 master 上查询这个 key,发现已经过期,就会把它清理掉,然后返回 NULL。 发现了吗?在 master 和 slave 上查询同一个 key,结果竟然不一样? 其实,slave 应该要与 master 保持一致,key 已过期,就应该给客户端返回 NULL,而不是还正常返回 key 的值。 为什么会发生这种情况? 其实这是 Redis 的一个 Bug:3.2 以下版本的 Redis,在 slave 上查询一个 key 时,并不会判断这个 key 是否已过期,而是直接无脑返回给客户端结果。 这个 Bug 在 3.2 版本进行了修复,但是,它修复得「不够彻底」。 什么叫修复得「不够彻底」? 这就要结合前面提到的,第 2 个影响因素「具体执行的命令」来解释了。 Redis 3.2 虽然修复了这个 Bug,但却遗漏了一个命令:EXISTS。 也就是说,一个 key 已过期,在 slave 直接查询它的数据,例如执行 GET/LRANGE/HGETALL/SMEMBERS/ZRANGE 这类命令时,slave 会返回 NULL。 但如果执行的是 EXISTS,slave 依旧会返回:key 还存在。 原因在于,EXISTS 与查询数据的命令,使用的不是同一个方法。 Redis 作者只在查询数据时增加了过期时间的校验,但 EXISTS 命令依旧没有这么做。 直到 Redis 4.0.11 这个版本,Redis 才真正把这个遗漏的 Bug 完全修复。 如果你使用的是这个之上的版本,那在 slave 上执行数据查询或 EXISTS,对于已过期的 key,就都会返回「不存在」了。 这里我们先小结一下,slave 查询过期 key,经历了 3 个阶段: 3.2 以下版本,key 过期未被清理,无论哪个命令,查询 slave,均正常返回 value 3.2 - 4.0.11 版本,查询数据返回 NULL,但 EXISTS 依旧返回 true 4.0.11 以上版本,所有命令均已修复,过期 key 在 slave 上查询,均返回「不存在」 这里要特别鸣谢《Redis开发与运维》的作者,付磊。 这个问题我是在他的文章中看到的,感觉非常有趣,原来 Redis 之前还存在这样的 Bug 。随后我又查阅了相关源码,并对逻辑进行了梳理,在这里才写成文章分享给大家。 虽然已在微信中亲自答谢,但在这里再次表达对他的谢意~ 最后,我们来看影响查询结果的第 3 个因素:「机器时钟」。 假设我们已规避了上面提到的版本 Bug,例如,我们使用 Redis 5.0 版本,在 slave 查询一个 key,还会和 master 结果不同吗? 答案是,还是有可能会的。 这就与 master / slave 的机器时钟有关了。 无论是 master 还是 slave,在判断一个 key 是否过期时,都是基于「本机时钟」来判断的。 如果 slave 的机器时钟比 master 走得「快」,那就会导致,即使这个 key 还未过期,但以 slave 上视角来看,这个 key 其实已经过期了,那客户端在 slave 上查询时,就会返回 NULL。 是不是很有意思?一个小小的过期 key,竟然藏匿这么多猫腻。 如果你也遇到了类似的情况,就可以通过上述步骤进行排查,确认是否踩到了这个坑。 3) 主从切换会导致缓存雪崩? 这个问题是上一个问题的延伸。 我们假设,slave 的机器时钟比 master 走得「快」,而且是「快很多」。 此时,从 slave 角度来看,Redis 中的数据存在「大量过期」。 如果此时操作「主从切换」,把 slave 提升为新的 master。 它成为 master 后,就会开始大量清理过期 key,此时就会导致以下结果: master 大量清理过期 key,主线程发生阻塞,无法及时处理客户端请求 Redis 中数据大量过期,引发缓存雪崩 你看,当 master / slave 机器时钟严重不一致时,对业务的影响非常大! 所以,如果你是 DBA 运维,一定要保证主从库的机器时钟一致性,避免发生这些问题。 4) master / slave 大量数据不一致? 还有一种场景,会导致 master / slave 的数据存在大量不一致。 这就涉及到 Redis 的 maxmemory 配置了。 Redis 的 maxmemory 可以控制整个实例的内存使用上限,超过这个上限,并且配置了淘汰策略,那么实例就开始淘汰数据。 但这里有个问题:假设 master / slave 配置的 maxmemory 不一样,那此时就会发生数据不一致。 例如,master 配置的 maxmemory 为 5G,而 slave 的 maxmemory 为 3G,当 Redis 中的数据超过 3G 时,slave 就会「提前」开始淘汰数据,此时主从库数据发生不一致。 De plus, bien que les paramètres de mémoire maximale du maître/esclave soient les mêmes, si vous souhaitez ajuster leur limite supérieure, vous devez également y prêter une attention particulière, sinon l'esclave entraînera également l'élimination des données : Augmenter la mémoire maximale Lors du réglage de l'esclave, ajustez d'abord l'esclave, puis ajustez le maître Lors du réglage de la mémoire maximale, réglez d'abord le maître, puis ajustez l'esclave De cette façon, cela évite le problème de l'esclave dépassant la mémoire maximale à l'avance. En fait, vous pouvez y réfléchir, quelle est la clé de ces problèmes ? La raison fondamentale est qu'après que l'esclave dépasse la mémoire maximale, les données seront éliminées "d'elles-mêmes" . Si l'esclave n'est pas autorisé à éliminer les données par lui-même, ces problèmes peuvent-ils être évités ? C'est vrai. En réponse à ce problème, les responsables de Redis auraient également dû recevoir des commentaires de nombreux utilisateurs. Dans la version Redis 5.0, le responsable a finalement complètement résolu ce problème ! Redis 5.0 ajoute un élément de configuration : plica-ignore-maxmemory, la valeur par défaut est oui. Ce paramètre indique que même si la mémoire esclave dépasse maxmemory, il n'éliminera pas les données tout seul ! De cette façon, l'esclave sera toujours à égalité avec le maître, et ne copiera fidèlement que les données envoyées par le maître, et ne se lancera pas dans des "petits trucs" tout seul. À ce stade, les données maître/esclave peuvent être garanties d'être totalement cohérentes ! Si vous utilisez la version 5.0, vous n'avez pas à vous soucier de ce problème. 5) L'esclave a effectivement un problème de fuite mémoire ? Oui, vous avez bien lu. Comment est-ce arrivé ? Examinons-le en détail. Lorsque vous utilisez Redis, la fuite de mémoire esclave sera déclenchée si les scénarios suivants sont rencontrés : Redis utilise des versions inférieures à 4.0 L'élément de configuration de l'esclave est en lecture seule = non (inscriptible depuis la bibliothèque) La clé avec le délai d'expiration est écrite sur l'esclave A ce moment, l'esclave aura une fuite de mémoire : La clé de l'esclave ne sera pas automatiquement effacée même si elle expire. Si vous ne la supprimez pas activement, ces clés resteront dans la mémoire de l'esclave et consommeront la mémoire de l'esclave. Le plus gênant est que vous utilisez des commandes pour interroger ces clés, mais vous ne trouvez toujours aucun résultat ! Il s'agit d'un problème de "fuite de mémoire" esclave. Il s'agit en fait d'un bug dans Redis. Ce problème n'a été corrigé que dans Redis 4.0. La solution est, sur un esclave inscriptible, lors de l'écriture de clés avec délai d'expiration, l'esclave "enregistrera" ces clés. Ensuite l'esclave scannera ces clés régulièrement et les nettoiera si le délai d'expiration est atteint. Si votre entreprise a besoin de stocker temporairement des données sur l'esclave et que ces clés ont des délais d'expiration définis, vous devez alors prêter attention à ce problème. Vous devez confirmer votre version Redis. S'il s'agit d'une version inférieure à 4.0, veillez à éviter cet écueil. En fait, la meilleure solution est de formuler une spécification d'utilisation Redis. L'esclave doit être forcé à être en lecture seule et aucune écriture n'est autorisée. Cela peut non seulement garantir la cohérence des données du maître/esclave, mais évitez également le problème de fuite de mémoire esclave. 6) Pourquoi la synchronisation complète maître-esclave continue-t-elle d'échouer ? Lors d'une synchronisation complète maître-esclave, vous pouvez rencontrer le problème d'échec de synchronisation. Le scénario spécifique est le suivant : L'esclave initie une demande de synchronisation complète au maître, et le maître génère un RDB et l'envoie à l'esclave, l'esclave charge le RDB. Les données RDB étant trop volumineuses, le temps de chargement de l'esclave deviendra également très long. À ce stade, vous constaterez que l'esclave n'a pas terminé le chargement du RDB, mais que la connexion entre le maître et l'esclave a été déconnectée et que la synchronisation des données a échoué. Après cela, vous constaterez que l'esclave lance à nouveau une synchronisation complète, et que le maître génère RDB et l'envoie à l'esclave. De même, lorsque l'esclave charge le RDB, la synchronisation maître/esclave échoue à nouveau, et ainsi de suite. Que se passe-t-il ? En fait, c'est le problème de la « tempête de réplication » de Redis. Qu'est-ce qu'une tempête de copies ? Exactement comme ce qui vient d'être décrit : La synchronisation complète maître-esclave a échoué, la synchronisation a été redémarrée, puis la synchronisation a échoué à nouveau. Cela va et vient, un cercle vicieux, et continue de gaspiller les ressources de la machine. Pourquoi cela pose-t-il ce problème ? Si votre Redis présente les caractéristiques suivantes, ce problème peut survenir : Les données d'instance du maître sont trop volumineuses et l'esclave met trop de temps à charger le RDB. La configuration du tampon de réplication (esclave client-output-buffer-limit) est trop petite Le maître a un grand nombre de demandes d'écriture Lorsque le maître et l'esclave synchronisent complètement les données, la demande d'écriture reçue par le maître sera d'abord écrite dans le « tampon de copie » maître-esclave. de ce tampon est déterminé par la configuration. Lorsque l'esclave charge le RDB trop lentement, l'esclave ne pourra pas lire les données dans le "tampon de réplication" à temps, ce qui entraînera un "débordement" du tampon de réplication. Afin d'éviter une croissance continue de la mémoire, le maître déconnectera "de force" l'esclave à ce moment-là, et la synchronisation complète échouera. Après cela, l'esclave qui n'a pas réussi à se synchroniser va "ré" lancer une synchronisation complète, puis tomber dans le problème décrit ci-dessus, et se répétera dans un cercle vicieux. C'est ce qu'on appelle la "tempête de réplication". Comment résoudre ce problème ? Je vous donne les suggestions suivantes : Ne rendez pas l'instance Redis trop grande et évitez les RDB trop volumineux Configurez le tampon de copie pour être aussi grand que possible Certains, laisser suffisamment de temps à l'esclave pour charger le RDB et réduire la probabilité d'échec de synchronisation complète Si vous avez également marché sur ce piège, vous pouvez le résoudre grâce à cette solution. D'accord, pour résumer, dans cet article nous parlons principalement de Redis en "utilisation des commandes", "persistance des données" et "synchronisation maître-esclave" Il y a trois pièges possibles. Et si ? Cela a-t-il bouleversé votre compréhension ? La quantité d'informations contenues dans cet article est assez importante. Si votre réflexion est un peu « brouillonne » maintenant, ne vous inquiétez pas, je vous ai également préparé une carte mentale pour faciliter votre meilleure compréhension et votre mémoire. . J'espère que vous pourrez éviter ces pièges à l'avance lors de l'utilisation de Redis afin que Redis puisse fournir de meilleurs services. Enfin, j'aimerais vous parler de mon expérience et de mes réflexions sur le fait de tomber dans les pièges au cours du processus de développement. En fait, lorsque vous entrez en contact avec un nouveau domaine, vous passerez par plusieurs étapes : méconnaissance, familiarité, marcher sur des pièges, absorber l'expérience et devenir plus à l'aise. Alors, à ce stade de marcher sur des pièges, comment éviter de marcher sur des pièges ? Ou comment résoudre efficacement les problèmes après être tombé dans un piège ? Ici, j'ai résumé 4 aspects, qui devraient vous aider : 1) Lire plus de documents officiels + commentaires sur les fichiers de configuration Assurez-vous de lisez plus de documentation officielle et de commentaires sur les fichiers de configuration. En fait, un excellent logiciel vous rappellera de nombreux risques possibles dans les documents et les commentaires. Si vous les lisez attentivement, vous pouvez éviter à l'avance de nombreux problèmes fondamentaux. 2) Ne pas lâcher les détails et réfléchir davantage au pourquoi ? Restez toujours curieux. Lorsque vous rencontrez des problèmes, maîtrisez la capacité de décoller les cocons et de localiser progressivement les problèmes, et maintenez toujours la mentalité d'explorer l'essence des problèmes dans les choses. 3) Osez poser des questions, le code source ne mentira pas Si vous pensez qu'un problème est étrange, il peut s'agir d'un bug, osez poser des questions. Trouver la vérité sur le problème grâce au code source est mieux que de lire une centaine d'articles plagiés les uns des autres sur Internet (les copier encore et encore est très probablement faux). 4) Il n'y a pas de logiciel parfait, un excellent logiciel est itéré étape par étape Tout excellent logiciel est itéré étape par étape. Au cours du processus d'itération, il est normal que des bugs existent et nous devons les examiner avec la bonne mentalité. Ces expériences et idées sont applicables à n’importe quel domaine d’études et j’espère qu’elles vous seront utiles. Pour plus de connaissances liées à la programmation, veuillez visiter : Enseignement de la programmation ! ! Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!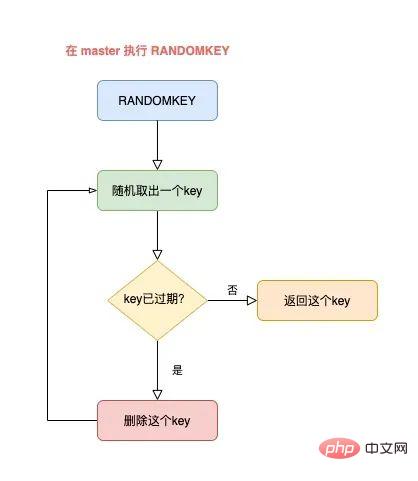
127.0.0.1:6379> SETBIT testkey 10 1
(integer) 1
127.0.0.1:6379> GETBIT testkey 10
(integer) 1
Copier après la connexion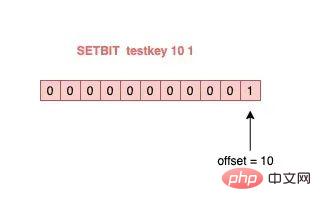
Quels sont les pièges de la persistance des données ?
主从复制有哪些坑?
// Redis 2.8 版本 在 slave 上执行
127.0.0.1:6479> TTL testkey
(integer) -2 // 已过期
127.0.0.1:6479> GET testkey
"testval" // 还能查询到!
Copier après la connexion// Redis 2.8 版本 在 master 上执行
127.0.0.1:6379> TTL testkey
(integer) -2
127.0.0.1:6379> GET testkey
(nil)
Copier après la connexion// Redis 3.2 版本 在 slave 上执行
127.0.0.1:6479> GET testkey
(nil) // key 已逻辑过期
127.0.0.1:6479> EXISTS testkey
(integer) 1 // 还存在!
Copier après la connexion
Résumé
Post-scriptum
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Que sont les bases de données en mémoire ?
Que sont les bases de données en mémoire ?
 Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
Lequel a une vitesse de lecture plus rapide, mongodb ou redis ?
 Comment utiliser Redis comme serveur de cache
Comment utiliser Redis comme serveur de cache
 Comment Redis résout la cohérence des données
Comment Redis résout la cohérence des données
 Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
Comment MySQL et Redis assurent-ils la cohérence des doubles écritures ?
 Quelles données le cache Redis stocke-t-il généralement ?
Quelles données le cache Redis stocke-t-il généralement ?
 Quels sont les 8 types de données de Redis
Quels sont les 8 types de données de Redis










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



