La deuxième partie est là ! Apprenons quelques connaissances de base aujourd’hui. Une base solide est la seule façon d’apprendre en profondeur ! ! !
Apprentissage des connaissances de base
1. Modèle OSI
Le modèle OSI divise le travail de communication réseau en 7 couches, de bas en haut ce sont couche physique, couche liaison de données, couche réseau, couche de transport, couche de session, couche de présentation et couche d'application . OSI n'est qu'un modèle qui existe en concept et en théorie. Son inconvénient est qu'il comporte trop de couches, ce qui augmente la complexité du travail en réseau, il n'a donc pas été appliqué à grande échelle. Plus tard, les gens ont simplifié OSI et fusionné certaines couches. Au final, seules 4 couches ont été conservées, de bas en haut, ce sont la couche d'interface, la couche réseau, la couche transport et la couche application . 🎜>Modèle TCP/IP.
À quoi sert exactement ce modèle de réseau ? En bref, c'est l'encapsulation des données.
Principe d'encapsulation des données : Les programmes (logiciels) que nous utilisons habituellement accèdent généralement au réseau via la couche application, et les programmes génèrent le les données seront transmises couche par couche jusqu'à ce que la couche d'interface réseau finale soit envoyée à Internet via le câble réseau. Chaque fois que les données descendent d'une couche, elles seront empaquetées par le protocole de cette couche. Au moment où elles sont envoyées sur Internet, elles comportent quatre couches d'empaquetage de plus que les données d'origine. L’ensemble du processus d’encapsulation des données ressemble à une poupée matriochka russe. Lorsqu'un autre ordinateur reçoit le paquet de données, il sera transmis couche par couche depuis la couche d'interface réseau. Chaque couche de transmission sera décompressée, jusqu'à la couche d'application finale, les données les plus originales seront obtenues. utilisera. Le processus de conditionnement des données consiste en fait à ajouter un indicateur (un bloc de données) en tête des données, indiquant que les données ont traversé cette couche et que je les ai traitées. Le processus de décompression des données est exactement le contraire, qui consiste à supprimer la marque dans l'en-tête des données et à leur laisser progressivement révéler leur forme originale. (Comparaison entre le modèle de réseau à sept couches OSI et le modèle de réseau à quatre couches TCP/IP)
Lorsque deux ordinateurs communiquent , doit respecter les principes suivants : (1) La communication doit être au même niveau Par exemple, la couche application de l'ordinateur A et la couche transport de l'ordinateur B. ne peuvent pas communiquer car ils ne sont pas au même niveau, le déballage des données rencontrera des problèmes. (2) La fonction de chaque couche doit être la même, c'est-à-dire qu'elle doit avoir le exactement le même modèle de réseau. Si les modèles de réseaux sont tous différents, ce sera le chaos et personne ne connaîtra personne. Les données ne peuvent être transmises que couche par couche et ne peuvent pas passer d'une couche à l'autre. (3) Chaque couche peut utiliser les services fournis par la couche inférieure et fournir des services à la couche supérieure.
2. TCP, famille de protocoles IP :
La programmation de socket couramment utilisée est Basé sur les protocoles TCP et UDP, leur relation hiérarchique est illustrée dans la figure ci-dessous :
3. Méthode d'encodage de chaîne en python
Convertissez l'encodage de chaîne en utf-8 en python !
Pour un même numéro, vous pouvez choisir différentes manières de le représenter. Quelle que soit la solution que vous choisissez, c'est une méthode d'encodage pour Unicode (utf-8 est une méthode d'encodage spécifique pour Unicode) .
Python utilise en interne Unicode pour représenter les chaînes, donc si vous souhaitez imprimer des caractères chinois (l'encodage Unicode et utf-8 des lettres et chiffres anglais sont les mêmes), vous doit Il est garanti qu'il s'agit de la méthode de codage Unicode. S'il s'agit de la méthode de codage "utf-8" (la sortie est un tas de codes binaires, le codage UTF-8 d'un caractère chinois est de trois octets, c'est-à-dire trois octets. -représentation binaire de segment, comme indiqué ci-dessous), vous pouvez utiliser .decode("utf-8") pour décoder. Lors de l'enregistrement sur le disque dur ou de l'envoi sur Internet (à l'aide de sockets et d'autres éléments liés à la communication), il doit être converti en UTF-8. (Résultat de sortie de l'encodage utf-8 en python)
Pourquoi ne pas continuer à utiliser UTF-8 en interne, sinon ce n'est pas nécessaire Converti? Cela implique un défaut de l'UTF-8 : calculer la longueur d'une chaîne et trouver des sous-chaînes est très inefficace. Lorsque vous utilisez UCS2, si vous voulez connaître la longueur d'une chaîne, regardez simplement combien d'octets elle occupe, puis divisez-la par 2. Pour UTF-8, vous devez la compter caractère par caractère. Lors d'une recherche de sous-chaîne, parce que nous ne savons pas combien d'octets occupe le caractère suivant, ces algorithmes de recherche efficaces ne fonctionneront pas.
Conclusion
Je proposerai quelques exemples simples la prochaine fois , pour aider chacun à le comprendre et à le mettre en pratique. Enfin, j'espère que tout le monde lui donnera un petit coup de pouce après l'avoir lu et lui donnera quelques encouragements. Cela fait plus de deux heures que j'ai écrit cet article. Ce n'est pas un acte de profit, c'est juste pour le partage de connaissances, l'apprentissage. ensemble et grandir ensemble ! ! ! (En secret, je n'aime pas les articles des autres après les avoir lus. Ce n'est pas une bonne habitude. Je vais la changer tout de suite. Woohoo)
Le contenu de cet article est volontairement contribué par les internautes et les droits d'auteur appartiennent à l'auteur original. Ce site n'assume aucune responsabilité légale correspondante. Si vous trouvez un contenu suspecté de plagiat ou de contrefaçon, veuillez contacter admin@php.cn




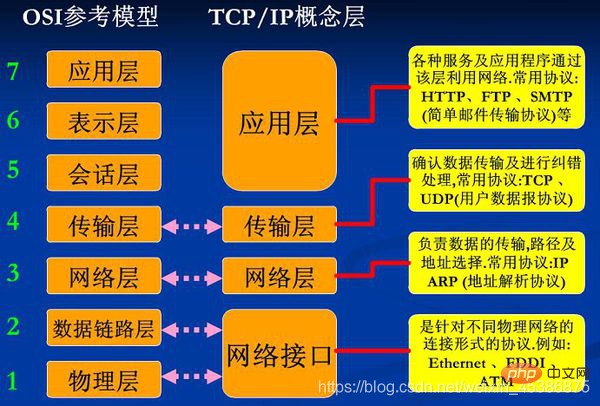 (Comparaison entre le modèle de réseau à sept couches OSI et le modèle de réseau à quatre couches TCP/IP)
(Comparaison entre le modèle de réseau à sept couches OSI et le modèle de réseau à quatre couches TCP/IP) 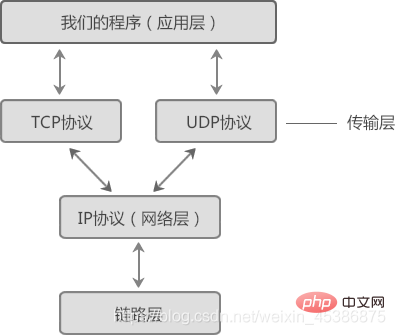
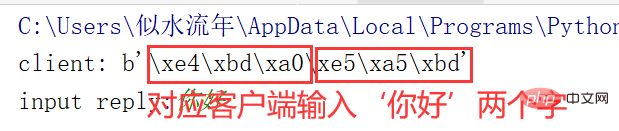


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



