



Recommandé (gratuit) : Tutoriel d'introduction à Redis
1. De grandes opportunités dans le contexte de l'époque, pourquoi utiliser NoSQL
1.1 Le bon vieux temps du MySQL autonome
Dans les années 1990, le nombre de les visites sur un site Web n'étaient généralement pas importantes. Cela peut être facilement géré avec une seule base de données.
À cette époque, la plupart d'entre eux étaient des pages Web statiques et il n'y avait pas beaucoup de sites Web interactifs dynamiques. 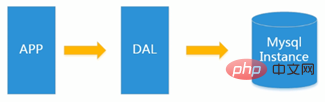
DAL dal est l'abréviation anglaise de data access layer, qui est la couche d'accès aux données (Data Access Layer)
Sous l'architecture ci-dessus, regardons quels sont les des goulots d'étranglement de stockage de données ?
1. Lorsque la quantité totale de données ne peut pas tenir dans une machine
2. Lorsque l'index de données (B+ Tree) ne peut pas tenir dans la mémoire d'une machine
3. La quantité de l'accès (lecture et écriture mixtes) ne peut pas être toléré par une seule instance
Si 1 ou 3 des conditions ci-dessus sont remplies, évoluez...
1.2.Memcached (cache) + MySQL + division verticale
Plus tard, à mesure que le nombre de visites augmente, presque la plupart des sites Web utilisant l'architecture MySQL ont commencé à avoir des problèmes de performances sur la base de données. Les programmes Web ne se concentrent plus uniquement sur les fonctions, mais recherchent également les performances. Les programmeurs ont commencé à utiliser largement la technologie de mise en cache pour soulager la pression sur la base de données et optimiser la structure et l'index de la base de données. Au début, il était plus courant d'utiliser la mise en cache de fichiers pour soulager la pression sur la base de données. Cependant, lorsque le nombre de visites continue d'augmenter, plusieurs machines Web ne peuvent pas être partagées via la mise en cache de fichiers. Un grand nombre de petites mises en cache entraînent également une pression d'E/S relativement élevée. . . A cette époque, Memcached est naturellement devenu un produit technologique très à la mode. 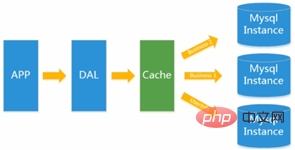 C'est l'équivalent de la couche dao précédente accédant directement à la base de données, et maintenant une couche de cache est insérée au milieu. L'accès fréquent à la base de données entraîne une dégradation des performances. Nous mettons une partie du contenu dans le cache pour réduire la pression.
C'est l'équivalent de la couche dao précédente accédant directement à la base de données, et maintenant une couche de cache est insérée au milieu. L'accès fréquent à la base de données entraîne une dégradation des performances. Nous mettons une partie du contenu dans le cache pour réduire la pression.
1.3. Séparation de lecture et d'écriture maître-esclave Mysql
En raison de la pression d'écriture accrue sur la base de données,Memcached ne peut que soulager la pression de lecture sur le base de données. La concentration de la lecture et de l'écriture sur une seule base de données rend la base de données submergée La plupart des sites Web ont commencé à utiliser la technologie de réplication maître-esclave pour réaliser la séparation de la lecture et de l'écriture afin d'améliorer les performances de lecture et d'écriture et l'évolutivité des bases de données de lecture . Le mode maître-esclave de MySQL est devenu actuellement la norme pour les sites Web. 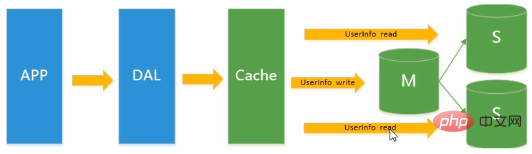 Explication : Il y a une mise à jour d'enregistrement dans la base de données maître Afin de garantir l'intégrité des données, elles doivent être copiées dans la base de données esclave. Séparation de lecture et d'écriture : maître/esclave. Nous pouvons placer les opérations d'écriture dans la bibliothèque maître et les opérations de lecture dans la bibliothèque esclave.
Explication : Il y a une mise à jour d'enregistrement dans la base de données maître Afin de garantir l'intégrité des données, elles doivent être copiées dans la base de données esclave. Séparation de lecture et d'écriture : maître/esclave. Nous pouvons placer les opérations d'écriture dans la bibliothèque maître et les opérations de lecture dans la bibliothèque esclave.
1.4. Fractionnement des tables et des bases de données + fractionnement horizontal + cluster mysql
Basé sur le cache de Memcached, la réplication maître-esclave de MySQL et la séparation lecture-écriture, À ce moment-là, la pression d'écriture de la base de données principale MySQL a commencé à apparaître comme un goulot d'étranglement et la quantité de données a continué d'augmenter Étant donné que MyISAM utilise des verrous de table, de graves problèmes de verrouillage se produiront en cas de concurrence élevée , Un grand nombre d'applications MySQL à haute concurrence ont commencé à utiliser le moteur InnoDB au lieu de MyISAM. Dans le même temps,
il est devenu populaire d'utiliser des sous-tables et des sous-bases de données pour atténuer la pression d'écriture et les problèmes d'expansion liés à la croissance des données. À cette époque, les sous-tableaux et les sous-bases de données sont devenus une technologie populaire, une question d'entrevue populaire et un problème technique brûlant discuté dans l'industrie. A cette époque, MySQL lançait des partitions de tables qui n'étaient pas encore stables, ce qui apportait également de l'espoir aux entreprises ayant une force technique moyenne. Bien que MySQL ait lancé le cluster MySQL Cluster, ses performances ne peuvent pas très bien répondre aux exigences d'Internet, mais elles n'offrent qu'une très grande garantie en termes de haute fiabilité. 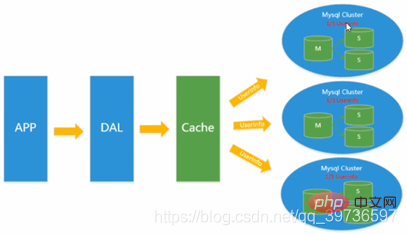 Verrouillage de table et verrouillage de rangée ?
Verrouillage de table et verrouillage de rangée ?
La sous-bibliothèque et la sous-table 1-3000 entrent dans la bibliothèque n°1. 3001-6000 allez à l’entrepôt 2. Attendez
1.5. Goulot d'étranglement lors de l'évolutivité de MySQL
La base de données MySQL stocke également souvent des champs de texte volumineux, ce qui entraîne des tables de base de données très volumineuses. très lent et difficile de restaurer la base de données rapidement. Par exemple, 10 millions de texte de 4 Ko correspondent à une taille proche de 40 Go. Si ces données peuvent être omises de MySQL, MySQL deviendra très petit. Les bases de données relationnelles sont puissantes, mais elles ne peuvent pas gérer tous les scénarios d'application. MySQL a une faible évolutivité (nécessite une technologie complexe à mettre en œuvre), une pression d'E/S élevée dans le cadre du Big Data et des difficultés à modifier la structure des tables. Ce sont les problèmes rencontrés par les développeurs qui utilisent actuellement MySOL.1.6. A quoi ça ressemble aujourd'hui ?
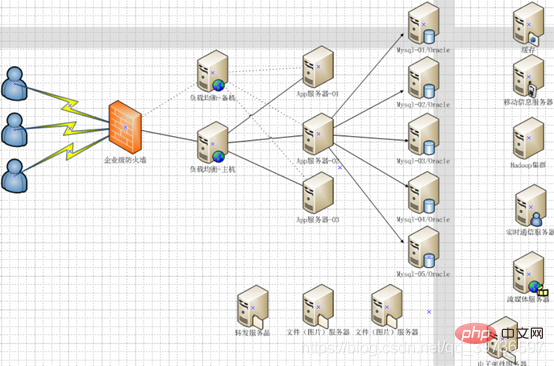 Cluster Firewall-nginx-Tomcat
Cluster Firewall-nginx-Tomcat
1.7 . Pourquoi utiliser NoSQL
Aujourd'hui, nous pouvons facilement accéder et capturer des données via des plateformes tierces (telles que Google, Facebook, etc.). Les informations personnelles des utilisateurs, les réseaux sociaux, les emplacements géographiques, les données générées par les utilisateurs et les journaux d'opérations des utilisateurs ont augmenté de façon exponentielle. Si nous voulons exploiter ces données utilisateur, alors les bases de données SQL ne sont plus adaptées à ces applications. Cependant, le développement de bases de données NoSQL peut très bien gérer ces données volumineuses. 
2. Qu'est-ce que
NoSQL (NoSQL = Not Only SQL), signifiant « pas seulement SQL », fait généralement référence à base de données non relationnelle . Avec l'essor des sites Web Internet Web2.0, les bases de données relationnelles traditionnelles sont devenues incapables de gérer les sites Web Web2.0, en particulier les sites Web purement dynamiques Web2.0 de type SNS à très grande échelle et hautement concurrents, exposant de nombreux problèmes non relationnels. les bases de données se sont développées très rapidement en raison de leurs caractéristiques propres. Les bases de données NoSQL ont été créées pour résoudre les défis posés par la collecte de données à grande échelle et par plusieurs types de données, en particulier les problèmes d'application du Big Data, y compris le stockage de données à très grande échelle .
(par exemple, Google ou Facebook collectent chaque jour des milliards de données sur leurs utilisateurs). Ces types de magasins de données ne nécessitent pas de schéma fixe et peuvent évoluer sans opérations redondantes.
3. Que peut-on faire
Facile à étendre
Il existe de nombreux types de bases de données NoSQL, mais une commune La fonctionnalité consiste à supprimer les caractéristiques relationnelles des bases de données relationnelles. Il n’y a aucune relation entre les données, il est donc très facile de les développer. Il apporte également de manière invisible des capacités d’évolutivité au niveau architectural.
Hautes performances pour les gros volumes de données
Les bases de données NoSQL ont des performances de lecture et d'écriture très élevées, en particulier sous de gros volumes de données, elles fonctionnent également bien.
Cela est dû à sa non-relation et à sa structure de base de données simple.
Généralement, MySQL utilise le cache de requêtes. Le cache devient invalide à chaque fois que la table est mise à jour. Dans les applications avec des interactions fréquentes dans web2.0, les performances du cache ne sont pas élevées.
Le cache de NoSQL est un cache de niveau enregistrement et à granularité fine, donc NoSQL a des performances beaucoup plus élevées à ce niveau.
Modèles de données diversifiés et flexibles
NoSQL n'a pas besoin de créer des champs pour que les données soient stockées à l'avance et peut stocker des formats de données personnalisés à tout moment temps.
Dans une base de données relationnelle, l'ajout et la suppression de champs sont une chose très gênante. S’il s’agit d’une table contenant une très grande quantité de données, ajouter des champs est tout simplement un cauchemar.
SGBDR traditionnel VS NOSQL
SGBDR
Données structurées hautement organisées
Langage de requête structuré (SQL)
Les données et les relations sont stockées séparément tables
Langage de manipulation de données, langage de définition de données
Cohérence stricte
Transactions de base
NoSQL
signifie plus que simplement SQL
Pas de requêtes déclaratives Langage
Pas de schéma prédéfini
Magasins de valeurs-clés, magasins de colonnes, magasins de documents, bases de données graphiques
Cohérence éventuelle, pas de propriétés ACID
Données non structurées et imprévisibles :
Théorème CAP
Hautes performances, haute disponibilité et évolutivité
4. Que sont les NoSQL
Redis (types de données et cache, excellents à tous égards)
Memcached (cache)
MongDB (le plus similaire à une base de données relationnelle)
5. Comment jouer à
KV
Cache
Persistance
Parlez de votre compréhension de Redis, dites simplement KV-CACHE-PERSISITENCE
3V + 3 high
Big Les 3V de l'ère des données :
Volume massif
Variété
Réel -time Velocity
Description de quelques problèmes sur le système, données massives Taobao Double Eleven. Un Weibo, un champ de texte, un champ vidéo, un champ d'arrière-plan, etc. diversification. 12306 a des exigences élevées en temps réel. Le temps réel absolu ne peut pas être atteint
Les trois exigences Internet les plus élevées sont :
Haute concurrence
Haute accessibilité
Hautes performances
Le système doit prendre en charge une haute concurrence, telle que 12306. Quatre façons d'obtenir du fil.
Évolutivité, horizontalement et verticalement. Horizontalement, si une machine ne suffit pas, ajoutez-en d’autres.
Exigences de haute performance
Pour plus d'apprentissage connexe, veuillez visiter la colonne redis. .
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 pagination mysql
pagination mysql
 Quelle est la touche de raccourci pour changer d'utilisateur ?
Quelle est la touche de raccourci pour changer d'utilisateur ?
 Comment résoudre le problème selon lequel le dossier Win10 ne peut pas être supprimé
Comment résoudre le problème selon lequel le dossier Win10 ne peut pas être supprimé
 Comment ouvrir le disque virtuel
Comment ouvrir le disque virtuel
 Que faire si votre adresse IP est attaquée
Que faire si votre adresse IP est attaquée
 Comment couper de longues photos sur les téléphones mobiles Huawei
Comment couper de longues photos sur les téléphones mobiles Huawei
 Cache mybatis de premier niveau et cache de deuxième niveau
Cache mybatis de premier niveau et cache de deuxième niveau
 Utilisation de la fonction get en langage C
Utilisation de la fonction get en langage C










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



