


Tutoriel MySQL Pourquoi l'index introduit dans la colonne utilise-t-il B+Tree

Avant-propos
Le titre de cet article est un réel problème que j'ai rencontré lors du processus d'entretien. Une société de financement participatif sur Internet a été la première à tester les connaissances liées à MySQL de l'intervieweur. Question, j'étais assez confus à l'époque. Je ne m'attendais pas à ce que ce jeune homme ne pratique pas les arts martiaux et ne joue pas ses cartes selon des routines. Lorsqu'il lui posait des questions sur ses connaissances liées à MySQL, il ne le faisait pas toujours. poser des questions sur l'optimisation de l'index, l'échec de l'index et d'autres problèmes connexes ? Pourquoi est-il sorti ? Les fichiers de stockage sont différents ? Même l'examen d'un mécanisme MVCC fera l'affaire. Cette fois, je vais donc résumer cette partie des points de connaissance.
Pourquoi avez-vous besoin de créer un index
Tout d'abord, nous savons tous que le but de la création d'un index est d'augmenter la vitesse des requêtes, alors pourquoi un index peut-il augmenter la vitesse des requêtes ?
Jetons un coup d’œil à un diagramme schématique d’un index. 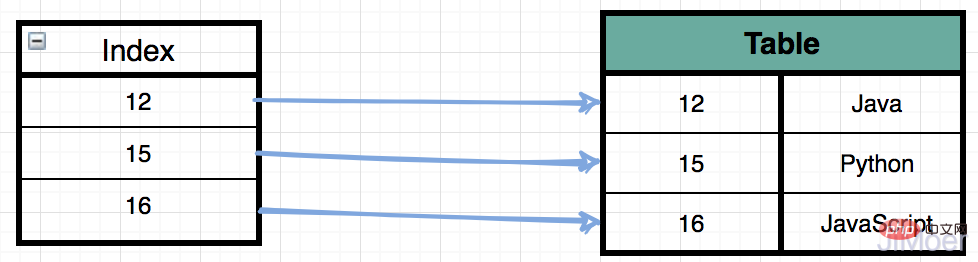
Si j'ai une instruction SQL : select * from Table where id = 15 Puis en l'absence d'index, un parcours complet de la table sera effectué je rechercherai un par un jusqu'à trouver l'enregistrement avec l'id=15. . , la complexité temporelle est O(n);
Et si la requête est effectuée avec un index ? Tout d'abord, une recherche binaire sera effectuée dans la valeur d'index basée sur id=15. L'efficacité de la recherche binaire est très élevée et sa complexité temporelle est O(logn) ; efficacité, mais la quantité de données d'index est également relativement importante, elles ne sont donc généralement pas stockées en mémoire, mais sont stockées directement sur le disque. Par conséquent, les E/S du disque sont inévitables lors de la lecture du contenu du fichier sur le disque.
Pourquoi MySQL utilise-t-il B+Tree pour l'indexation ? Si le fichier d'index est très volumineux, il ne peut pas être chargé dans la mémoire en même temps, donc lorsque vous utilisez l'index pour rechercher des données, plusieurs E/S sur disque sont nécessaires. sera effectué pour charger les données d'index dans la mémoire par lots, <p> Par conséquent, une bonne structure de données indexées doit avoir le moins de fois d'E/S disque dans le but d'obtenir des résultats corrects. <strong></strong></p>Type de hachage<strong>因此一个好的索引的数据结构,在得到正确的结果前提下,一定是磁盘IO次数最少的。</strong>
Actuellement, MySQL propose en fait deux types de données d'index, l'un est BTree (en fait B+Tree ), un hachage. Mais pourquoi la plupart des gens choisissent BTree dans l'utilisation réelle ?
Parce que si vous utilisez un index de type Hash, MySQL effectuera une opération de hachage sur les données de l'index lors de la création de l'index, afin que le pointeur du disque puisse être rapidement localisé en fonction de la valeur de hachage, même si la quantité de les données sont volumineuses. Les données peuvent également être localisées rapidement et avec précision.
Mais pour les requêtes par plage comme, les index de type Hash ne peuvent pas gérer les requêtes par plage, la table entière sera analysée directement. De plus, les index de type Hash ne peuvent pas gérer le tri.
select * from Table where id > 15Alors pourquoi MySQL n'a-t-il pas d'arbre binaire comme structure de données d'index ? Nous savons tous que les arbres binaires localisent les données via la recherche binaire, donc l'effet est toujours bon et la complexité temporelle est O(logn);
Mais il y a un problème avec les arbres binaires, c'est-à-dire dans des cas particuliers, elle dégénérera en un bâton, c'est-à-dire une liste chaînée à sens unique. À ce stade, sa complexité temporelle dégénérera en O(n);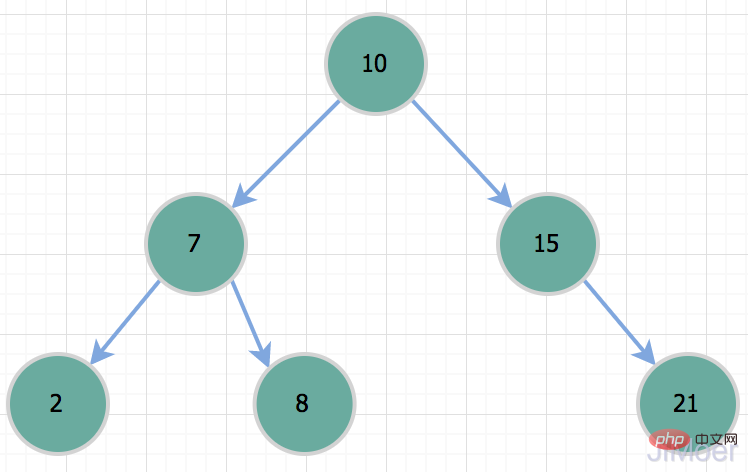 Ainsi, lorsque nous voulons interroger l'enregistrement avec id=50, c'est en fait la même chose qu'une analyse de table complète. Ainsi, à cause de cette situation, l’arbre binaire ne convient pas comme structure de données d’index.
Ainsi, lorsque nous voulons interroger l'enregistrement avec id=50, c'est en fait la même chose qu'une analyse de table complète. Ainsi, à cause de cette situation, l’arbre binaire ne convient pas comme structure de données d’index. 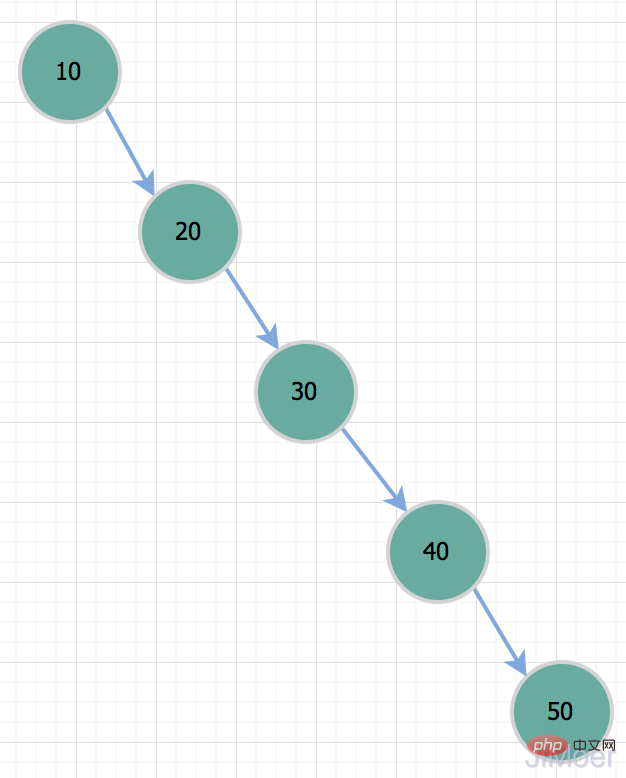 Arbre binaire équilibré
Arbre binaire équilibré
Donc, puisqu'un arbre binaire dégénérera en une liste chaînée dans des circonstances particulières, pourquoi pas un arbre binaire équilibré ?
La différence de hauteur entre les nœuds enfants d'un arbre binaire équilibré ne peut pas dépasser 1Comme l'arbre binaire de la figure ci-dessous, le nœud avec la clé 15 a une hauteur de 0 sur son. le nœud enfant gauche et une hauteur de 0 sur son nœud enfant droit est 1, et la différence de hauteur ne dépasse pas 1, donc l'arbre ci-dessous est un arbre binaire équilibré.
Parce qu'il peut maintenir l'équilibre, sa complexité temporelle de requête est O(logN). Quant à la façon de maintenir l'équilibre, cela implique principalement d'effectuer une rotation à gauche, une rotation à droite, etc. Les détails spécifiques sur le maintien de l'équilibre ne figurent pas dans cet article. Si vous souhaitez connaître le contenu principal, vous pouvez le rechercher vous-même. 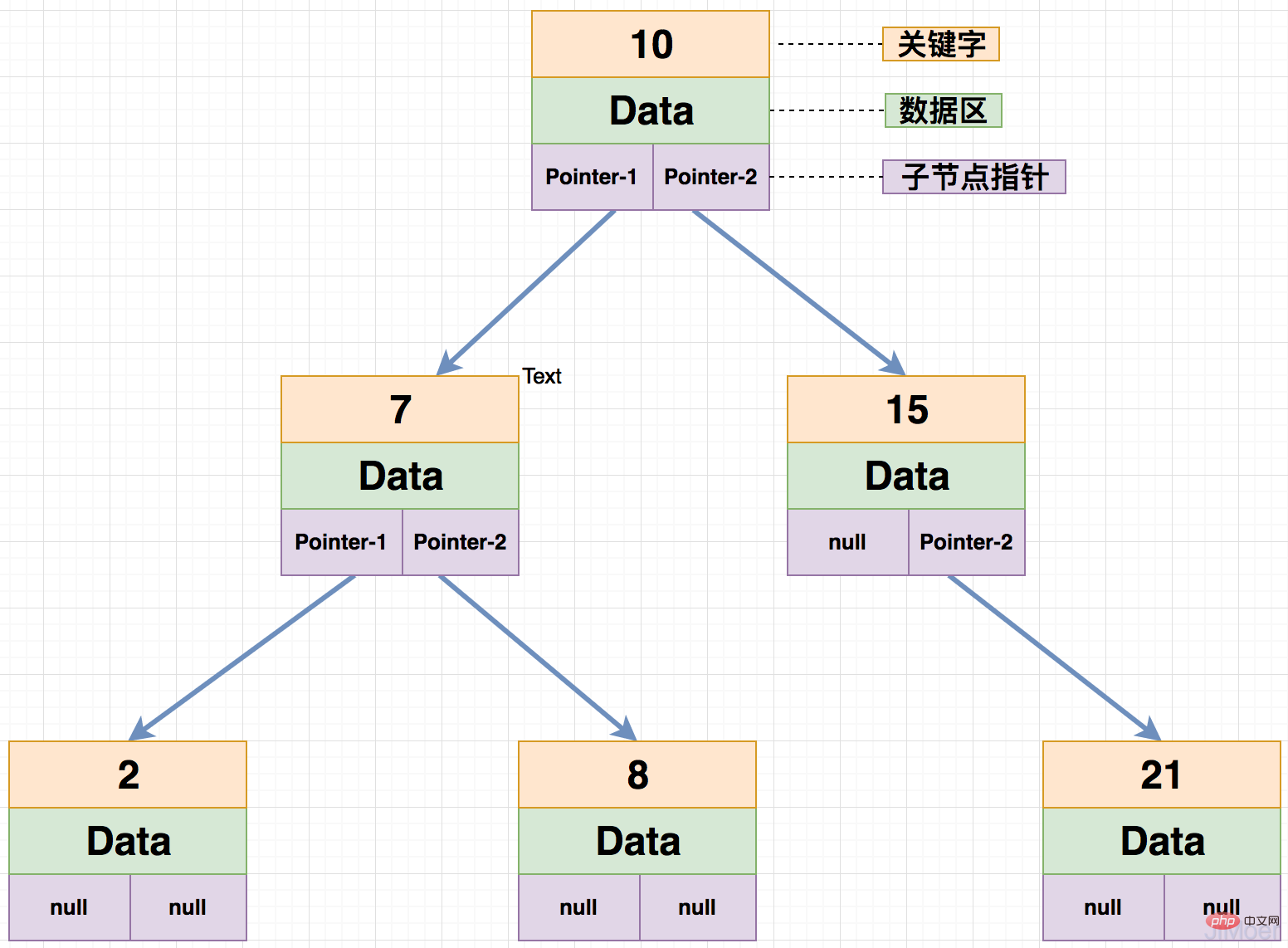 Quels sont les problèmes liés à l'utilisation de cette structure de données pour indexer MySQL ?
Quels sont les problèmes liés à l'utilisation de cette structure de données pour indexer MySQL ?
Bien que l'arbre binaire résolve le problème de l'équilibre, il apporte également de nouveaux problèmes, c'est-à-dire qu'en raison de la profondeur de son propre arbre, il provoquera une série de problèmes d'efficacité.
Ainsi, afin de résoudre le problème de l'équilibrage des arbres binaires, le multi-arbre équilibré (Balance Tree) est devenu un meilleur choix.
Balance Tree – B-Tree
B-Tree signifie multi-arbre équilibré. Généralement, un nœud dans B-Tree a le nombre de nœuds enfants que nous avons. appelez un B-Tree de cet ordre. Habituellement, m est utilisé pour représenter l'ordre. Lorsque m vaut 2, il s'agit d'un arbre binaire équilibré.
Chaque nœud d'un B-Tree peut avoir au plus m-1 mots-clés, et au moins Math.ceil(m/2)-1 mots-clés doivent être stockés. Tous les nœuds feuilles sont au même niveau. L'image ci-dessous est un B-Tree du 4ème ordre. 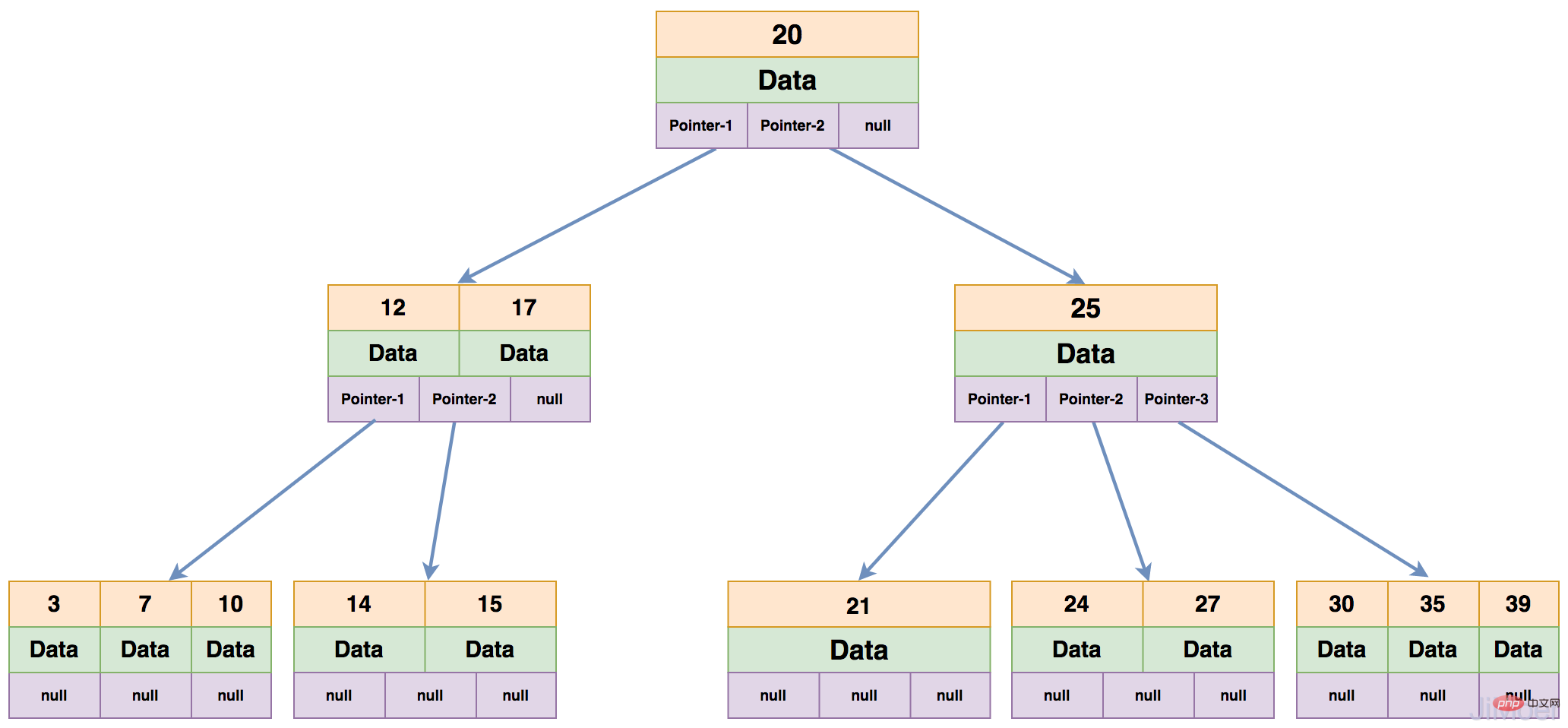
Ensuite, regardons comment B-Tree recherche les données :
De cette façon, l'ensemble de l'opération effectue en fait 3 opérations d'E/S, mais en fait, le B-Tree général a de nombreuses branches (généralement supérieures à 100) dans chaque couche.
Afin de mieux utiliser la capacité IO du disque, MySQL définit la taille de la page d'opération à 16 Ko, c'est-à-dire que la taille de chaque nœud est de 16 Ko. Si les mots-clés de chaque nœud sont de type int, alors ils font 4 octets. Si la taille de la zone de données est de 8 octets et que le pointeur de nœud occupe 4 octets supplémentaires, alors chaque nœud du B-Tree est le nombre de mots-clés. peut être enregistré est : (16*1000) / (4+8+4)=1000, chaque nœud peut stocker jusqu'à 1000 mots-clés et chaque nœud peut avoir jusqu'à 1001 nœuds de branche.
De cette façon, lors de l'interrogation des données d'index, une opération d'E/S sur disque peut lire 1 000 mots-clés dans la mémoire pour le calcul. Une opération d'E/S sur disque de B-Tree équilibre les données binaires sur N opérations d'E/S sur disque. effectué.
要注意的是 : B-Tree effectuera une série d'opérations afin d'assurer l'équilibre des données. Ce processus de maintien de l'équilibre prend du temps, alors quand. lors de la création de l'index, choisissez les champs appropriés et ne créez pas trop d'index. Si vous créez trop d'index, le processus de mise à jour de l'index prendra plus de temps lors de la mise à jour des données.
De plus, Ne choisissez pas des valeurs de champ à faible discrimination comme index, comme les champs de genre, qui n'ont que deux valeurs au total, ce qui peut entraîner la profondeur du B -L'arbre est trop grand et l'indice d'efficacité est réduit.
B+Tree
B-Tree a très bien résolu le problème des arbres binaires équilibrés et peut également garantir l'efficacité des requêtes, alors pourquoi y a-t-il quoi à propos de B+Tree ?
Regardons d’abord à quoi ressemble B+Tree.
B+Tree est une variante de B-Tree. La relation de formule entre chaque mot-clé de nœud et l'ordre m de B+Tree est différente de celle de B-Tree.
Tout d'abord, le nombre de nœuds enfants de chaque nœud et le ratio de mots-clés pouvant être stockés dans chaque nœud sont 1:1. Deuxièmement, lors de l'interrogation de données, l'intervalle fermé de gauche est utilisé pour l'interrogation, et il y a des nœuds de branche Lorsqu'il n'y a pas de données, seuls les mots-clés et les points de nœuds enfants sont enregistrés et les données sont stockées dans les nœuds feuilles. 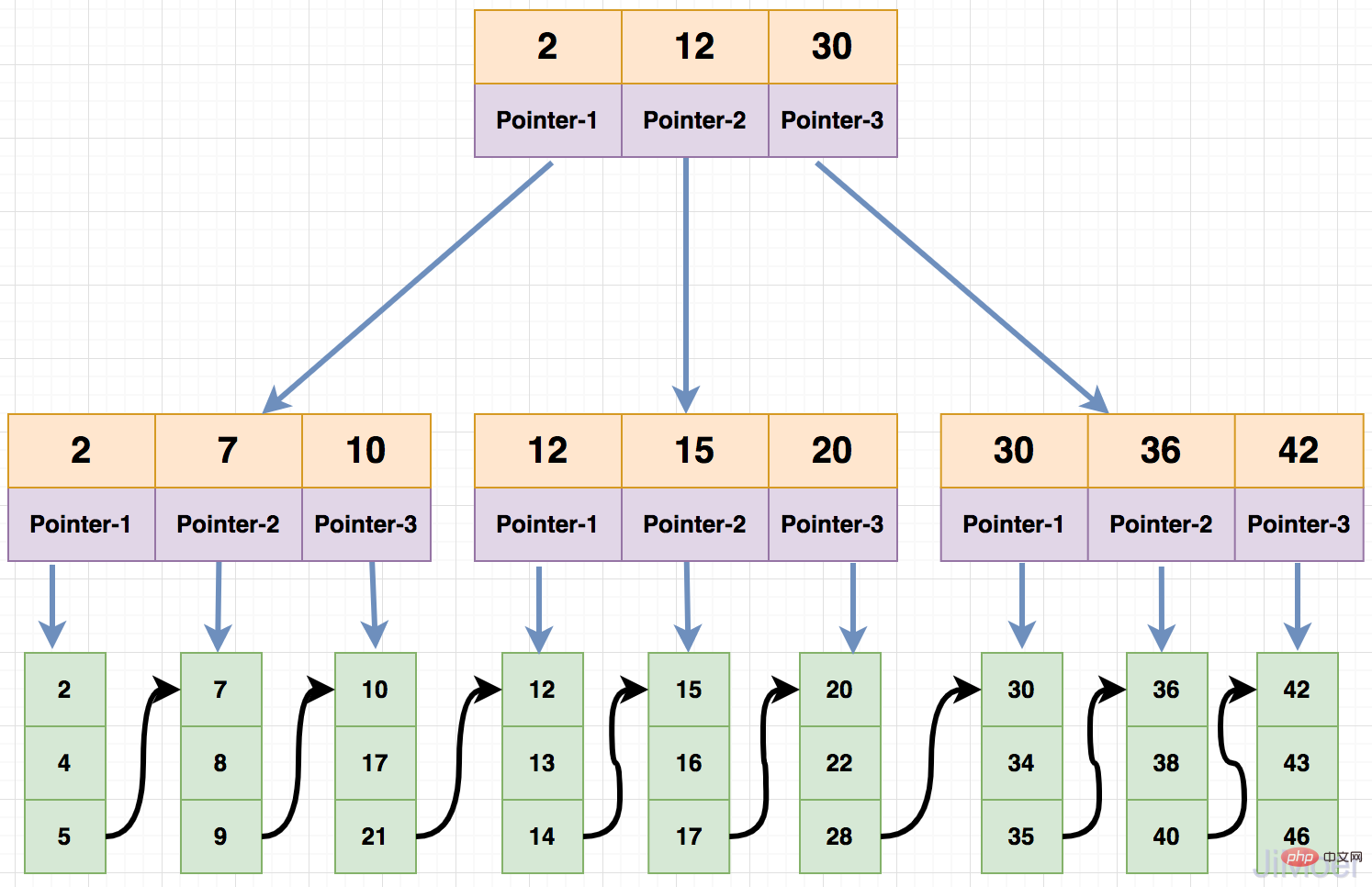
Voyons ensuite comment effectuer une requête de données dans B+Tree.
Par exemple :
id=2 existe dans le nœud racine car les données sont stockées dans le. intervalle fermé à gauche, les id sont tous sur le premier nœud enfant du nœud racine
id=2
Regardons maintenant la différence entre B-Tree et B+Tree
Tout d'abord, par rapport à l'arbre binaire équilibré, B+Tree a une profondeur inférieure, plus de nœuds enregistrent des mots-clés, moins de temps d'E/S disque et une meilleure efficacité de calcul des requêtes.
B+Tree a des capacités d'analyse globale plus puissantes. Si vous souhaitez analyser globalement la table de données en fonction des données d'index, B-Tree analysera l'intégralité de l'arborescence. , puis parcourez couche par couche. Quant à B+Tree, il vous suffit de parcourir les nœuds feuilles, car il existe une relation de référence séquentielle entre les nœuds feuilles.
B+Tree a des capacités de lecture et d'écriture d'E/S disque plus fortes, car seuls les mots-clés sont enregistrés sur chaque nœud de branche de B+Tree, de sorte qu'à chaque fois que le disque Lorsque IO lit et écrit, une page de 16 Ko de données peut stocker plus de mots-clés, et chaque nœud peut stocker plus de mots-clés que B-Tree. De cette façon, B+Tree charge beaucoup plus de données dans une seule E/S disque que B-Tree.
La structure de données B+Tree a une capacité de tri naturelle, qui est plus forte que les autres structures de données et le tri est effectué via des nœuds de branche si vous en avez besoin. chargez les nœuds de branche en mémoire pour le tri, plus de données peuvent être chargées en même temps.
L'effet de requête de B+Tree est plus stable, car toutes les requêtes doivent analyser les nœuds feuilles avant de renvoyer les données. L'effet est seulement stable mais pas nécessairement optimal. Si les données du nœud racine de B-Tree sont directement interrogées, B-Tree peut renvoyer directement les données avec une seule E/S disque, mais l'effet est optimal.
Quelles sont les différences entre les fichiers de stockage de données d'InnDB et ceux de MyISAM ?
Ce qui précède résume la structure des données de l'index MySQL. Cette fois, nous pouvons parler de la deuxième question, car ce problème a en fait une certaine relation avec l'index MySQL. Jetons un coup d'œil. Trouvez d'abord le répertoire dans lequel le serveur MySQL stocke les données :
Connectez-vous à MySQL et ouvrez l'interface de ligne de commande MySQL : entrez
et vous verrez le répertoire dans lequel les données sont stockées. show variables like '%datadir%'; Le répertoire dans lequel MySQL stocke les données sur mon serveur est :
/var/lib/mysql/
. study_test Entrez ensuite dans le répertoire
/var/lib/mysql/study_test
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt
student_innodb:
CREATE TABLE `student_innodb` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='innodb引擎表';
student_myisam:
CREATE TABLE `student_myisam` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `name` varchar(50) COLLATE utf8mb4_bin DEFAULT NULL, `age` int(11) DEFAULT NULL, `address` varchar(100) COLLATE utf8mb4_bin DEFAULT NULL, PRIMARY KEY (`id`), KEY `idx_name` (`name`) USING BTREE COMMENT 'name索引') ENGINE=MyISAM DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_bin COMMENT='myISAM引擎类型表';
Prendre un regardez : /var/lib/mysql/study_test
-rw-r----- 1 mysql mysql 60 1月 31 10:28 db.opt-rw-r----- 1 mysql mysql 8650 1月 31 10:41 student_innodb.frm-rw-r----- 1 mysql mysql 114688 1月 31 10:41 student_innodb.ibd-rw-r----- 1 mysql mysql 8650 1月 31 10:58 student_myisam.frm-rw-r----- 1 mysql mysql 0 1月 31 10:58 student_myisam.MYD-rw-r----- 1 mysql mysql 1024 1月 31 10:58 student_myisam.MYI
Moteur de stockage de données MyISAM, index et structure de stockage de données
Lorsque le moteur de stockage MyISAM stocke l'index, les données sont stocké séparément, et le B+Tree indexé pointe finalement vers l'adresse physique où les données existent, et non vers les données spécifiques. Recherchez ensuite les données spécifiques dans le fichier de données (*.MYD) en fonction de l'adresse physique.
Comme le montre la figure ci-dessous : 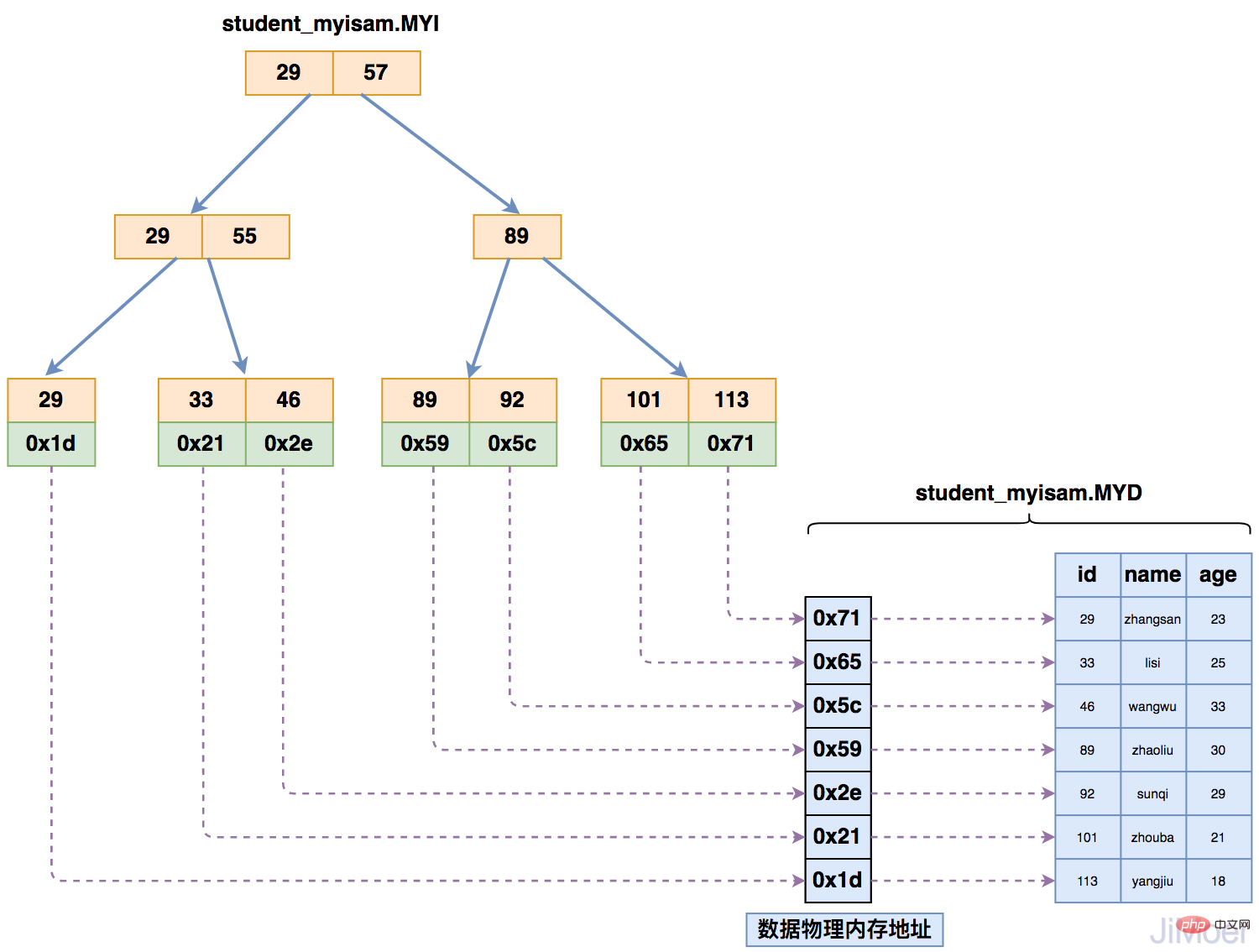
Ensuite, lorsqu'il y a plusieurs index, plusieurs index pointent vers la même adresse physique.
Comme le montre la figure ci-dessous : 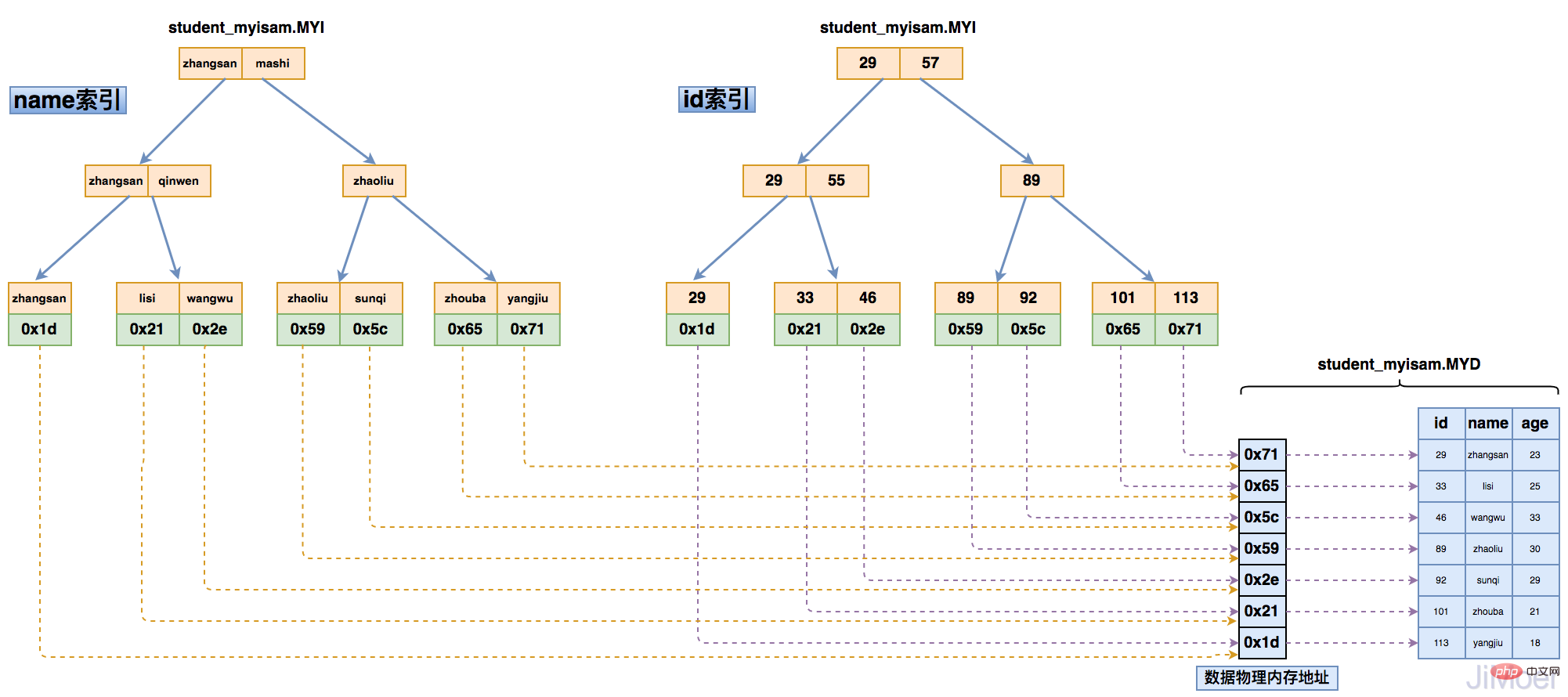
Grâce à cette structure, nous pouvons voir que les index du moteur de stockage MyISAM sont tous au même niveau, et l'index de clé primaire et celui de clé non primaire les structures et les méthodes de requête sont exactement les mêmes.
Moteur de stockage de données InnoDB, index et structure de stockage de données
Tout d'abord, les index InnoDB sont divisés en index clusterisés et les index non clusterisés stockent des mots clés. enregistrez les données, les mots-clés sont enregistrés sur chaque nœud de branche de B+Tree et les données sont enregistrées sur les nœuds feuilles.
"Clustering" signifie que les lignes de données sont stockées étroitement ensemble une par une dans un certain ordre. Une table ne peut avoir qu'un seul index clusterisé, car il n'y a qu'une seule façon de stocker des données dans une table. Généralement, la clé primaire est utilisée comme index clusterisé. S'il n'y a pas de clé primaire, InnoDB générera une colonne cachée comme primaire. clé par défaut.
Comme le montre la figure ci-dessous : 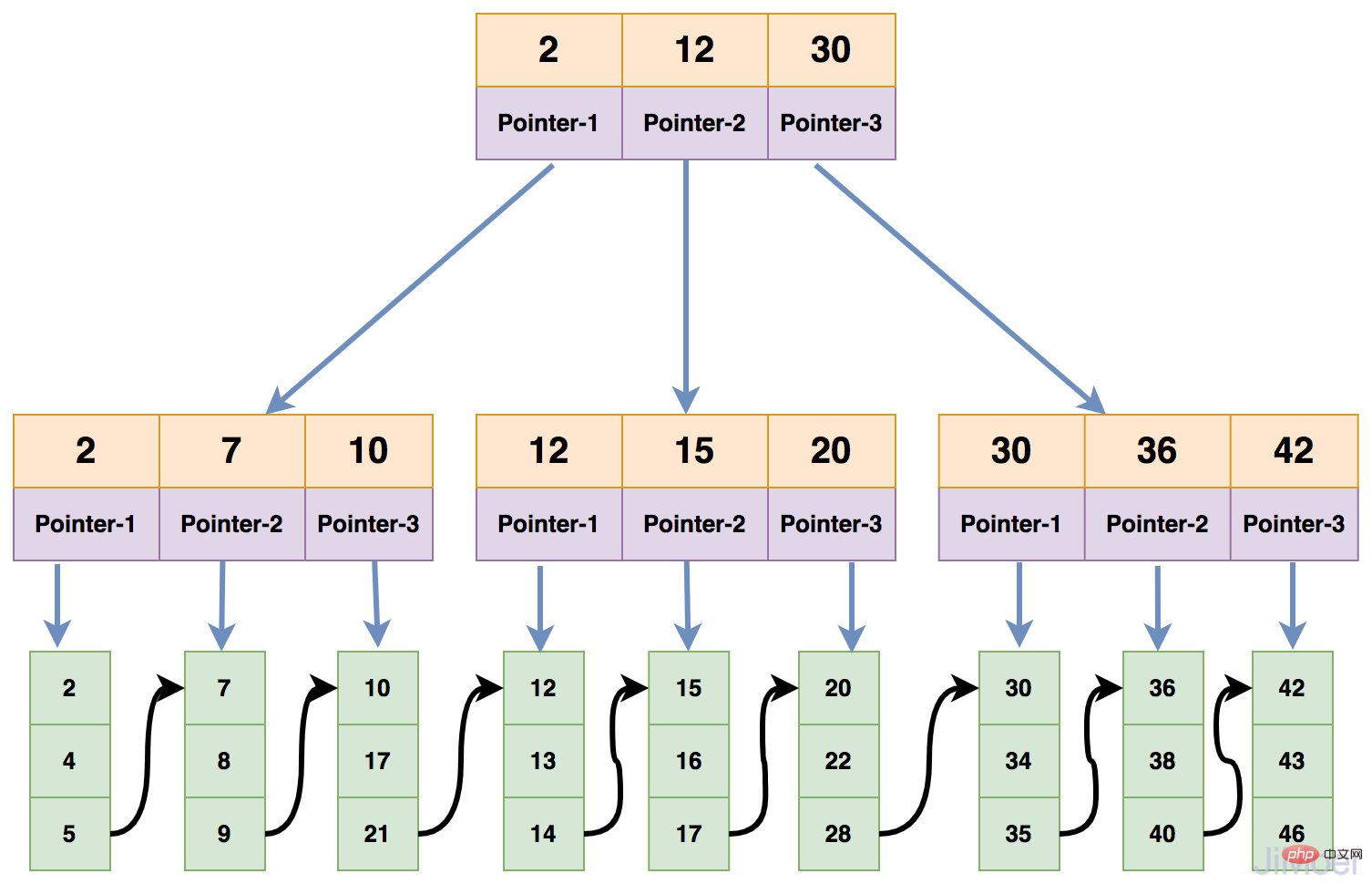
Index non clusterisé, également appelé index secondaire, bien qu'il enregistre également des mots-clés sur chaque nœud de branche de B+Tree, mais les feuilles Les nœuds ne sont pas des données enregistrées, mais des valeurs de clé primaire enregistrées. L'interrogation de données via l'index secondaire interrogera d'abord la clé primaire correspondant aux données, puis interrogera la ligne de données spécifique en fonction de la clé primaire.
Comme le montre la figure ci-dessous : 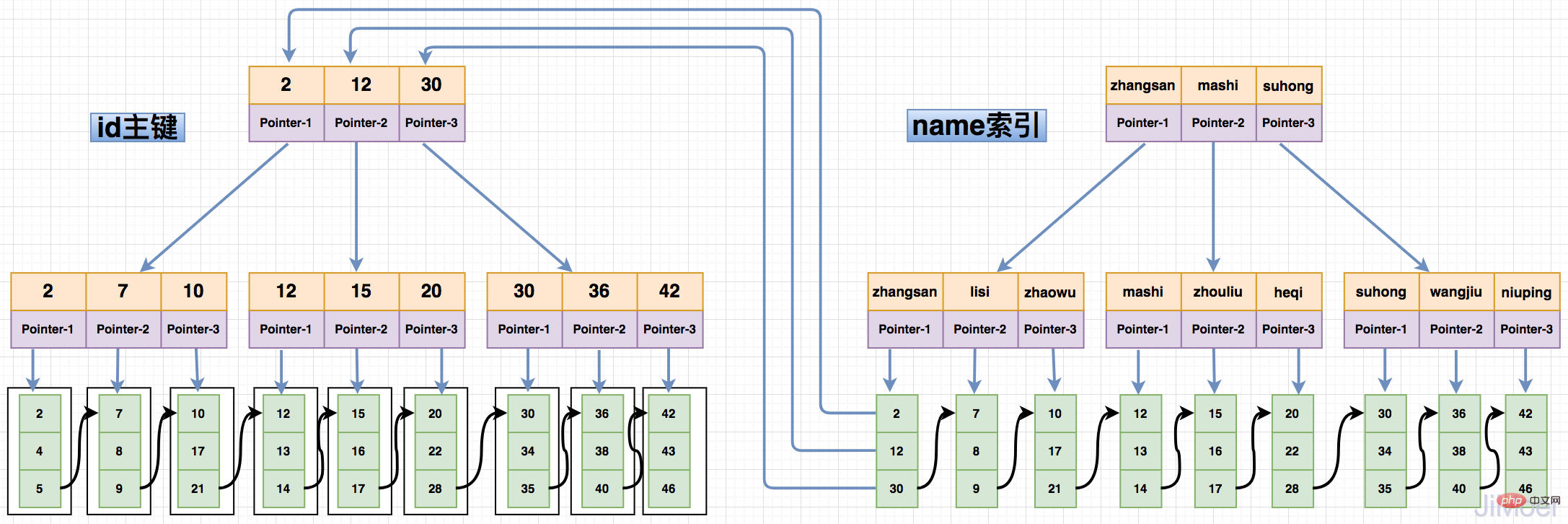
En raison de la structure de conception de l'index non clusterisé, l'index non clusterisé doit effectuer deux récupérations d'index lors de l'interrogation de cette conception. L'avantage est qu'une fois la migration des données effectuée, seul l'index de clé primaire doit être mis à jour et l'index non clusterisé n'a pas besoin d'être déplacé. Cela évite également d'avoir à stocker des adresses physiques comme l'index MyISAM, qui doit être déplacé. maintenu pendant la migration des données. Tous les problèmes d'indexation.
Résumé
Cette fois, j'ai clairement résumé la structure des données de l'index MySQL et la structure de stockage des fichiers plus tard, dans le processus de travail lui-même, lors de la conception de l'index. peut penser de manière plus globale. En comprenant la structure des données de l'index, vous pouvez également déterminer, lorsque vous écrivez réellement du SQL, quelles situations sont indexées et lesquelles ne le sont pas.
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



