


Un processus est l'instance de démarrage d'une application. Ressources de fichiers indépendantes, ressources de données et espace mémoire.
Les threads appartiennent aux processus et sont les exécuteurs des programmes. Un processus contient au moins un thread principal et peut également avoir plusieurs threads enfants. Les threads ont deux stratégies de planification, l’une est la planification en temps partagé et l’autre est la planification préemptive.
Mon groupe Penguin officiel
Les coroutines sont des threads légers, les coroutines appartiennent également aux threads et les coroutines sont exécutées dans les threads. La planification des coroutines est modifiée manuellement par l'utilisateur, elle est donc également appelée thread de l'espace utilisateur. La création, la commutation, la suspension et la destruction de coroutines sont toutes des opérations mémoire et la consommation est très faible. La stratégie de planification des coroutines est la suivante : planification collaborative.
Puisque Swoole4 est monothread et multi-processus, il n'y aura qu'une seule coroutine exécutée dans le même processus en même temps.
Le serveur Swoole reçoit des données et déclenche le rappel onReceive dans le processus de travail pour générer un Ctrip. Swoole crée un Ctrip correspondant pour chaque requête. Des sous-coroutines peuvent également être créées dans des coroutines.
L'implémentation sous-jacente de la coroutine est monothread, il n'y a donc qu'une seule coroutine travaillant en même temps, et l'exécution de la coroutine est en série.
Par conséquent, lorsque le multitâche et le multi-coroutine sont exécutés, lorsqu'une coroutine est en cours d'exécution, les autres coroutines cesseront de fonctionner. La coroutine actuelle se bloquera lors de l'exécution d'opérations d'E/S bloquantes et le planificateur sous-jacent entrera dans la boucle d'événements. Lorsqu'il y a un événement de fin d'E/S, le planificateur sous-jacent reprend l'exécution de la coroutine correspondant à l'événement. . Par conséquent, les coroutines n'ont pas de consommation de temps d'E/S et sont très adaptées aux scénarios d'E/S à haute concurrence. (Comme le montre l'image ci-dessous)
La coroutine n'a pas d'E/S et attend une exécution normale, le code PHP ne provoquera pas de changement de flux d'exécution
Lorsque la coroutine rencontre une IO, elle changera immédiatement de contrôle. Une fois l'IO terminée, le flux d'exécution sera commuté. revenez à la coroutine d'origine. Cliquez sur
coroutine et coroutine parallèle pour exécuter en séquence, la même logique que le processus d'exécution imbriqué de coroutine
précédent. est entré couche par couche de l'extérieur vers l'intérieur jusqu'à ce que l'IO se produise, puis passe à la coroutine externe. La coroutine parent n'attendra pas la fin de la coroutine enfant
Jetons d'abord un coup d'œil aux bases Exemple :
go(function () {
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";});go() est l'abréviation de Co::create(), utilisée pour créer une coroutine qui accepte le rappel comme paramètre Le code dans. le rappel sera exécuté dans cette coroutine nouvellement créée.
Remarques : SwooleCoroutine peut être abrégé en Co
Le résultat de l'exécution du code ci-dessus :
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello go1 hello main hello go2
Le résultat de l'exécution ne semble pas différent de l'ordre dans lequel nous écrivons habituellement le code. Le processus d'exécution réel :
Exécutez ce code, le système démarre un nouveau processus
, et une coroutine est générée dans le processus en cours. Le processus génère go(), la coroutine quitte heelo go1
hello main
dans la coroutine, quittez la coroutine heelo go2
// co.php<?phpsleep (100);
pour afficher les processus dans le système :ps aux
root@b98940b00a9b /v/w/c/p/swoole# php co.php &⏎ root@b98940b00a9b /v/w/c/p/swoole# ps auxPID USER TIME COMMAND 1 root 0:00 php -a 10 root 0:00 sh 19 root 0:01 fish 749 root 0:00 php co.php 760 root 0:00 ps aux ⏎
use Co;go(function () {
Co::sleep(1); // 只新增了一行代码
echo "hello go1 \n";});echo "hello main \n";go(function () {
echo "hello go2 \n";}); Fonctions de fonction et Co::sleep() Presque, mais cela simule l'attente d'IO (IO sera discuté en détail plus tard). Les résultats de l'exécution sont les suivants : sleep()
root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go2 hello go1
go()
Co::sleep()
hello mainhello go2
hello go1go(function () {
Co::sleep(1);
echo "hello go1 \n";});echo "hello main \n";go(function () {
Co::sleep(1);
echo "hello go2 \n";});root@b98940b00a9b /v/w/c/p/swoole# php co.phphello main hello go1 hello go2 ⏎
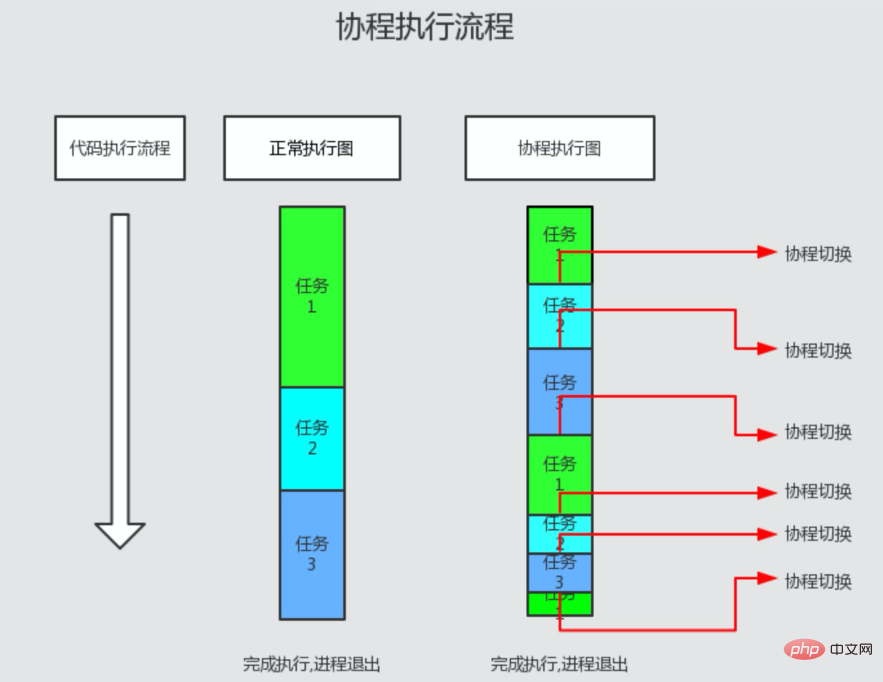
大家可能听到使用协程的最多的理由, 可能就是 协程快. 那看起来和平时写得差不多的代码, 为什么就要快一些呢? 一个常见的理由是, 可以创建很多个协程来执行任务, 所以快. 这种说法是对的, 不过还停留在表面.
首先, 一般的计算机任务分为 2 种:
其次, 高性能相关的 2 个概念:
了解了这些, 我们再来看协程, 协程适合的是 IO 密集型 应用, 因为协程在 IO阻塞 时会自动调度, 减少IO阻塞导致的时间损失.
我们可以对比下面三段代码:
$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965075.4608: hello 01528965076.461: hello 11528965077.4613: hello 21528965078.4616: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ⏎
$n = 4;go(function () use ($n) {
for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965150.4834: hello 01528965151.4846: hello 11528965152.4859: hello 21528965153.4872: hello 3real 0m 4.03s
user 0m 0.00s
sys 0m 0.02s
⏎$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.phphello main1528965245.5491: hello 01528965245.5498: hello 31528965245.5502: hello 21528965245.5506: hello 1real 0m 1.02s user 0m 0.01s sys 0m 0.00s ⏎
为什么时间有这么大的差异呢:
普通写法, 会遇到 IO阻塞 导致的性能损失
单协程: 尽管 IO阻塞 引发了协程调度, 但当前只有一个协程, 调度之后还是执行当前协程
多协程: 真正发挥出了协程的优势, 遇到 IO阻塞 时发生调度, IO就绪时恢复运行
我们将多协程版稍微修改一下:
$n = 4;for ($i = 0; $i <pre class="brush:php;toolbar:false">root@b98940b00a9b /v/w/c/p/swoole# time php co.php1528965743.4327: hello 01528965744.4331: hello 11528965745.4337: hello 21528965746.4342: hello 3hello main real 0m 4.02s user 0m 0.01s sys 0m 0.00s ⏎
只是将 Co::sleep() 改成了 sleep(), 时间又和普通版差不多了. 因为:
sleep() 可以看做是 CPU密集型任务, 不会引起协程的调度
Co::sleep() 模拟的是 IO密集型任务, 会引发协程的调度
这也是为什么, 协程适合 IO密集型 的应用.
再来一组对比的例子: 使用 redis
// 同步版, redis使用时会有 IO 阻塞$cnt = 2000;for ($i = 0; $i connect('redis');
$redis->auth('123');
$key = $redis->get('key');}// 单协程版: 只有一个协程, 并没有使用到协程调度减少 IO 阻塞go(function () use ($cnt) {
for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
}});// 多协程版, 真正使用到协程调度带来的 IO 阻塞时的调度for ($i = 0; $i connect('redis', 6379);
$redis->auth('123');
$redis->get('key');
});}性能对比:
# 多协程版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 0.54s user 0m 0.04s sys 0m 0.23s ⏎# 同步版root@0124f915c976 /v/w/c/p/swoole# time php co.phpreal 0m 1.48s user 0m 0.17s sys 0m 0.57s ⏎
接触过 go 协程的 coder, 初始接触 swoole 的协程会有点 懵, 比如对比下面的代码:
package main
import (
"fmt"
"time")func main() {
go func() {
fmt.Println("hello go")
}()
fmt.Println("hello main")
time.Sleep(time.Second)}> 14:11 src $ go run test.go hello main hello go
刚写 go 协程的 coder, 在写这个代码的时候会被告知不要忘了 time.Sleep(time.Second), 否则看不到输出 hello go, 其次, hello go与 hello main 的顺序也和 swoole 中的协程不一样.
原因就在于 swoole 和 go 中, 实现协程调度的模型不同.
上面 go 代码的执行过程:
package main, 然后执行其中的 func mian()
hello main
time.Sleep(time.Second), main 函数执行完, 程序结束, 进程退出, 导致调度中的协程也终止go 中的协程, 使用的 MPG 模型:
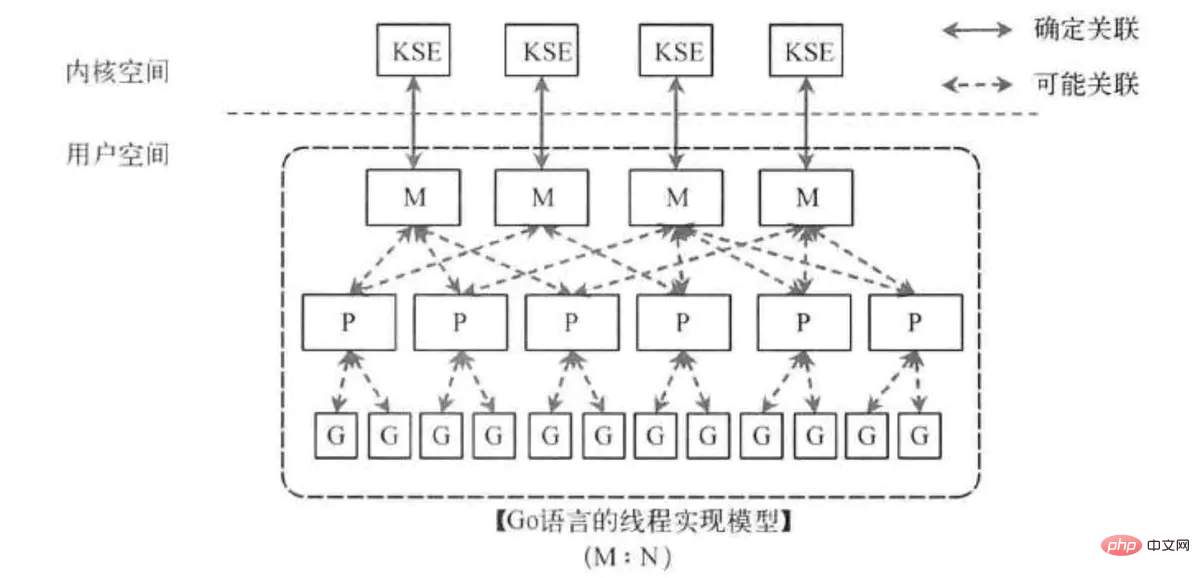
而 swoole 中的协程调度使用 单进程模型, 所有协程都是在当前进程中进行调度, 单进程的好处也很明显 – 简单 / 不用加锁 / 性能也高.
无论是 go 的 MPG模型, 还是 swoole 的 单进程模型, 都是对 CSP理论 的实现.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



