


La colonne

Lorsque l'échelle commerciale atteint une certaine échelle, le volume de commandes quotidien de Taobao est supérieur à 50 millions de commandes, et le volume de commandes quotidien de Meituan est plus de 30 millions de commandes. Lorsque la base de données est confrontée à une pression massive sur les données, des sous-opérations de sous-base de données et de table sont nécessaires. Une fois la base de données divisée en tables, certaines requêtes régulières peuvent poser des problèmes. Les plus courantes sont les requêtes de pagination. Généralement, nous appelons les champs des tables de partitionnement comme shardingkey. Par exemple, la table de commande utilise l'ID utilisateur comme shardingkey. Alors, comment effectuer la pagination si la condition de requête n'inclut pas l'ID utilisateur ? Par exemple, comment interroger davantage de requêtes multidimensionnelles s’il n’y a pas de clé de partitionnement ?
Généralement, les clés primaires de notre base de données sont auto-incrémentées, donc le problème du conflit de clé primaire après la division de la table est un problème inévitable. une entreprise unique Le champ sert de seule clé primaire. Par exemple, le numéro de commande de la table de commande doit être globalement unique.
Il existe de nombreuses méthodes distribuées courantes pour générer des identifiants uniques, les plus courantes étant Snowflake, Didi Tinyid et Meituan Leaf. En prenant l'algorithme du flocon de neige comme exemple, une milliseconde peut générer 4194304 plusieurs identifiants.
Le premier bit n'est pas utilisé et est par défaut à 0. L'horodatage à 41 chiffres est précis à la milliseconde près et peut accueillir 69 ans Le travail à 10 chiffres. Les 5 chiffres supérieurs de l'ID de la machine sont l'ID du centre de données, les 5 chiffres inférieurs sont l'ID du nœud et le numéro de série à 12 chiffres est accumulé chaque milliseconde pour chaque nœud, et le total peut atteindre 2 ^ 12 4096 ID.

La première étape consiste à s'assurer que le numéro de commande est unique une fois la table divisée. . Considérez d’abord la taille du sous-tableau en fonction de son propre volume d’activité et de son incrément.
Par exemple, notre volume de commandes quotidien est désormais de 100 000 commandes, et on estime qu'il atteindra 1 million de commandes par jour dans un an. Selon les attributs commerciaux, nous prenons généralement en charge l'interrogation des commandes d'ici six mois. , et les commandes qui dépassent six mois sont nécessaires.
Ainsi, sur la base de l'ordre de 1 million de commandes par jour pendant six mois, sans tables séparées, notre volume de commandes atteindra 1 million, même si vous pouvez gérer le temps de RT, vous ne pouvez tout simplement pas l'accepter. D'après l'expérience, il n'y a aucune pression sur la base de données si le nombre d'une seule table se compte en millions, il suffit donc de la diviser en 256 tables, 180 millions/256 ≈ 700 000. Si vous êtes prudent, vous. peut également le diviser en 512 tableaux. Alors réfléchissez-y, si le volume d'affaires augmente encore 10 fois pour atteindre 10 millions de commandes par jour, le sous-tableau 1024 est un choix plus approprié.
Après avoir divisé les tables et archivé les données pendant plus de six mois, 700 000 données dans une seule table suffisent pour faire face à la plupart des scénarios. Ensuite, hachez le numéro de commande, puis prenez le modulo de 256 pour déterminer à quelle table il correspond.
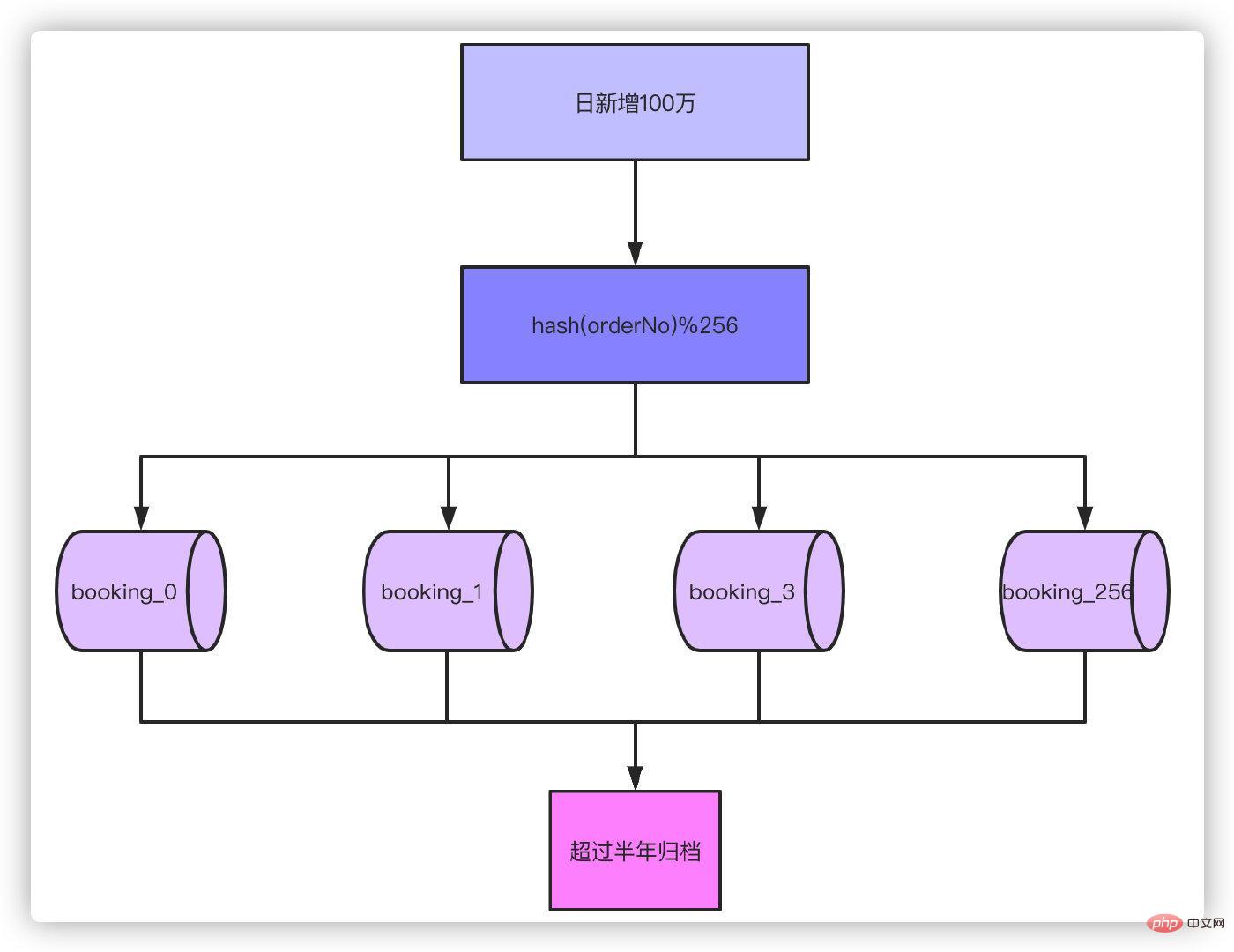
Eh bien, comme la seule clé primaire est basée sur le numéro de commande, les requêtes que vous avez écrites sur la base de l'ID de clé primaire dans le passé ne peuvent pas être utilisées. Cela implique un certain historique. . Modifications de la fonctionnalité de requête. Mais ce n'est pas un problème, n'est-ce pas ? Il suffit de le changer pour vérifier par le numéro de commande. Rien de tout cela n’est un problème, le problème vient de ce que dit notre titre.
Après avoir longuement discuté, nous sommes enfin arrivés au point. Alors, comment résoudre les problèmes de requête et de requête de pagination après le partitionnement de table ?
Tout d'abord, parlons de la requête avec la clé de partitionnement. Par exemple, la requête par numéro de commande, quelle que soit la pagination ou la manière dont, vous pouvez localiser directement la table spécifique à requête. avec la requête.
S'il ne s'agit pas de la clé de partitionnement, si le numéro de commande est utilisé comme clé de partitionnement dans l'exemple ci-dessus, les applications et les petits programmes sont généralement interrogés via l'ID utilisateur. Alors, que devons-nous faire avec le partitionnement effectué. via le numéro de commande ? Les tables de commande de nombreuses entreprises utilisent directement l'ID utilisateur comme clé de partitionnement, ce qui est très simple et peut être vérifié directement. Alors que faire du numéro de commande ? Un moyen très simple consiste à ajouter l’attribut ID utilisateur au numéro de commande. Pour donner un exemple très simple, vous pensez que vous ne pouvez pas utiliser l'horodatage d'origine à 41 chiffres. L'ID utilisateur est composé de 10 chiffres. La règle de génération du numéro de commande contient l'ID utilisateur. Lors de la saisie du tableau spécifique, le hachage de l'ID utilisateur est. sur la base des 10 chiffres du numéro de commande, prenez le module afin que l'effet de la requête soit le même quel que soit le numéro de commande ou l'ID utilisateur.
Bien sûr, cette méthode n'est qu'un exemple. Les règles spécifiques de génération du numéro de commande, le nombre de chiffres et les facteurs inclus sont déterminés en fonction de votre propre activité et du mécanisme de mise en œuvre.

D'accord, que vous utilisiez le numéro de commande ou l'ID utilisateur comme clé de partitionnement, vous pouvez résoudre le problème en suivant les deux méthodes ci-dessus. Ensuite, il y a une autre question : que se passe-t-il s’il ne s’agit ni d’un numéro de commande ni d’une requête d’ID utilisateur ? L'exemple le plus intuitif est la requête du côté marchand ou du backend. Le côté marchand utilise l'ID du commerçant ou du vendeur comme condition de requête. Les conditions de requête dans le backend peuvent être plus compliquées, comme certaines conditions de requête backend que j'ai rencontrées. Il pourrait y en avoir des dizaines. ? ? Ne vous inquiétez pas, parlons séparément des requêtes complexes côté B et backend.
En réalité, la majeure partie du trafic réel provient du côté C du côté utilisateur, cela résout donc essentiellement le problème du côté utilisateur. Ce problème est en grande partie résolu, et le reste vient du commerçant. Côté vendeur, côté B et activité de support backend, le trafic de requêtes n'est pas très important, ce problème est donc facile à résoudre.
Il existe deux façons de résoudre la requête sans clé de partitionnement du côté B.
Double écriture. La double écriture signifie que les données de commande sont stockées en deux copies. La face C et la face B enregistrent chacune une copie. utilisez le numéro de commande et l’ID utilisateur comme clé de partitionnement. OK, le côté B peut simplement utiliser l’ID du vendeur du commerçant comme clé de partitionnement. Certains camarades de classe diront : cela n'affectera-t-il pas les performances si vous écrivez en double ? Un léger retard étant acceptable pour le côté B, une méthode asynchrone peut être utilisée pour passer la commande du côté B. Pensez-y, si vous allez sur Taobao pour acheter quelque chose et passer une commande, est-il important si le vendeur tarde à recevoir le message de commande pendant une seconde ou deux ? Cela a-t-il un impact important sur le commerçant de plats à emporter que vous avez commandé si il reçoit la commande avec une seconde ou deux de retard ?
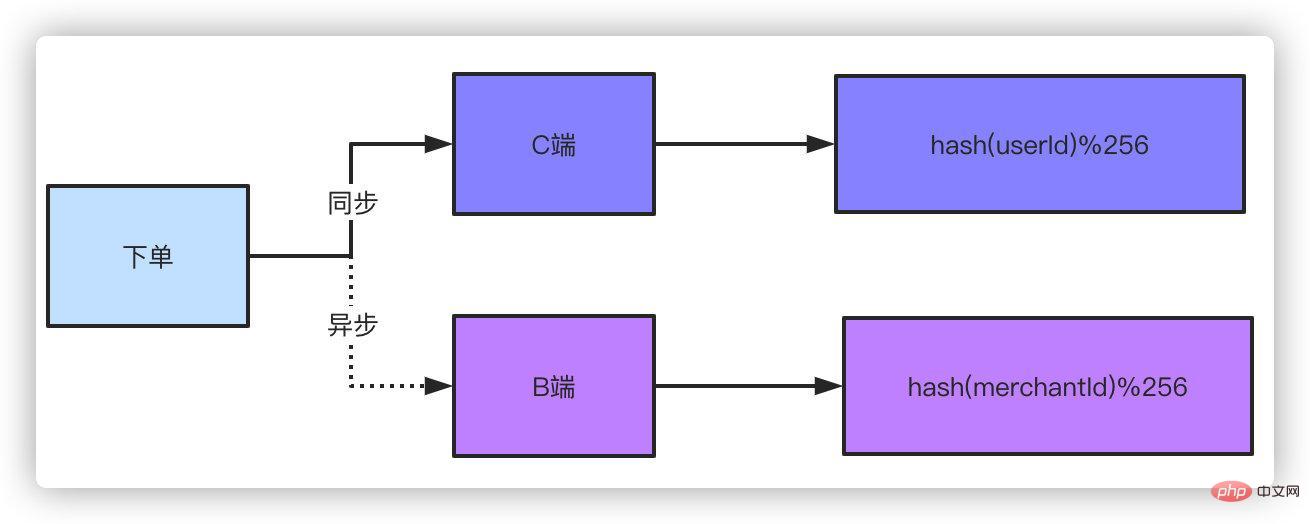
Il s'agit d'une solution. Une autre solution consiste à utiliser l'entrepôt de données hors ligne ou la requête ES une fois les données de commande déposées dans la base de données. vous utilisez binlog ou les messages MQ se présentent tous sous la forme de synchronisation de données avec un entrepôt de données ou ES. L'ordre de grandeur qu'ils prennent en charge est très simple pour ce type de conditions de requête. Il y a certes un léger retard dans cette méthode, mais ce délai contrôlable est acceptable.
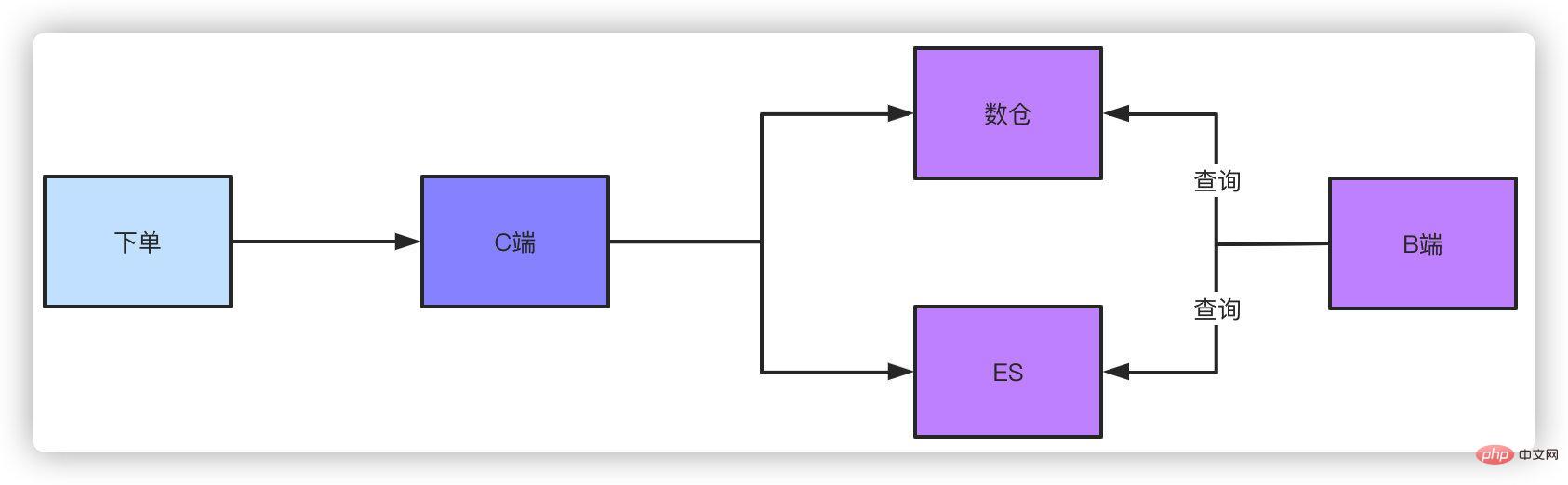
Quant aux requêtes sur le backend de gestion, telles que les opérations, les activités et les produits qui ont besoin de voir des données, elles nécessitent naturellement des conditions de requête complexes, qui peuvent également être effectuées via ES ou entrepôt de données. Si vous n'utilisez pas cette solution et effectuez une requête de pagination sans clé de partage, frère, vous pouvez uniquement analyser la table entière pour interroger les données agrégées, puis effectuer la pagination manuellement, mais les résultats obtenus de cette manière sont limités.
Par exemple, si vous avez 256 fragments, lors de l'interrogation, vous analysez tous les fragments de manière cyclique, récupérez 20 éléments de données de chaque fragment, et enfin agrégez les données et les pagez manuellement, il sera certainement impossible de les trouver. la totalité des données.
Problèmes de requête après le partitionnement de bases de données et de tables. Pour les étudiants expérimentés, ce problème est en fait connu, mais je pense que la plupart des étudiants n'ont peut-être pas fait l'affaire à cet ordre de grandeur, les sous-bases de données et les tableaux sont peut-être encore au stade conceptuel. Après avoir été interrogé à ce sujet lors de l'entretien, je me sens perdu car je ne sais pas quoi faire car je n'ai aucune expérience.
Le partitionnement des sous-bases de données et des tables est d'abord effectué en fonction du volume d'affaires existant et de l'augmentation future. Par exemple, si Pinduoduo a un volume de commandes quotidien de 50 millions, ses données semestrielles atteindront des dizaines de milliards. le score est de 4096 tables, n'est-ce pas ? Mais le fonctionnement réel est le même. Pour votre entreprise, il n'est pas nécessaire d'obtenir un score de 4096. Faites un choix raisonnable en fonction de l'entreprise.
Nous pouvons facilement résoudre les requêtes basées sur shardingkey. Les requêtes sur non-shardingkey peuvent être résolues en supprimant les doubles données, l'entrepôt de données et la solution ES. Bien sûr, si la quantité de données après le fractionnement est très faible, , ce n'est pas un problème de créer l'index et d'analyser la table entière à interroger.
Recommandations d'apprentissage gratuites associées : Tutoriel vidéo MySQL
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 utilisation des instructions mul
utilisation des instructions mul
 Fichier au format DAT
Fichier au format DAT
 Comment régler la luminosité de l'écran d'un ordinateur
Comment régler la luminosité de l'écran d'un ordinateur
 Comment augmenter le nombre de fans de Douyin rapidement et efficacement
Comment augmenter le nombre de fans de Douyin rapidement et efficacement
 Comment fermer la bibliothèque de ressources d'application
Comment fermer la bibliothèque de ressources d'application
 présentation de l'interface Lightning
présentation de l'interface Lightning
 vue fait référence aux fichiers js
vue fait référence aux fichiers js
 Formules de permutation et de combinaison couramment utilisées
Formules de permutation et de combinaison couramment utilisées









![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



