


La colonne

Le compteur de référence est le principal, le recyclage des sous-codes et l'effacement des marques sont supplémentaires
Dans le code source Python C, il existe une liste chaînée circulaire bidirectionnelle appelée refchain Cette liste chaînée est assez géniale car une fois qu'un objet est créé dans le programme Python, le l'objet sera ajouté à la liste chaînée refchain au milieu. En d’autres termes, il sauvegarde tous les objets.
age = 18number = age # 对象18的引用计数器 + 1del age # 对象18的引用计数器 - 1def run(arg): print(arg) run(number) # 刚开始执行函数时,对象18引用计数器 + 1,当函数执行完毕之后,对象18引用计数器 - 1 。num_list = [11,22,number] # 对象18的引用计数器 + 1复制代码
La collecte des déchets basée sur des compteurs de référence est très pratique et simple, mais elle présente toujours le problème des références circulaires, ce qui entraîne l'impossibilité de recycler certaines données normalement, par exemple :
v1 = [11,22,33] # refchain中创建一个列表对象,由于v1=对象,所以列表引对象用计数器为1.v2 = [44,55,66] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1.v1.append(v2) # 把v2追加到v1中,则v2对应的[44,55,66]对象的引用计数器加1,最终为2.v2.append(v1) # 把v1追加到v1中,则v1对应的[11,22,33]对象的引用计数器加1,最终为2.del v1 # 引用计数器-1del v2 # 引用计数器-1复制代码
Marquer comme clair : créez une liste chaînée spéciale spécifiquement pour enregistrer des listes, des tuples, des dictionnaires, des collections, des classes personnalisées et d'autres objets, puis vérifiez si les objets de cette liste chaînée are Il existe une référence circulaire Si elle existe, que les compteurs de référence des deux parties soient -1.
Recyclage générationnel : Optimisez la liste chaînée dans l'effacement des marques et divisez les objets pouvant avoir des références circulaires en 3 listes chaînées s'appellent : 0/1/2 trois générations. chaque génération peut stocker des objets et des seuils. Lorsque le seuil est atteint, chaque objet de la liste chaînée correspondante sera analysé, à l'exception des références circulaires, chacun sera décrémenté de 1 et les objets avec un compteur de référence de 0 seront détruits.
// 分代的C源码#define NUM_GENERATIONS 3struct gc_generation generations[NUM_GENERATIONS] = { /* PyGC_Head, threshold, count */
{{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代
{{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代
{{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代};复制代码Remarque spéciale : le seuil et le décompte de la génération 0 et des générations 1 et 2 ont des significations différentes.
Génération 0, le nombre représente le nombre d'objets dans la liste chaînée de génération 0, le seuil représente le seuil du nombre d'objets dans la liste chaînée de génération 0, s'il dépasse, une vérification par scan de génération 0 sera effectuée . Génération 1, le nombre représente le nombre d'analyses de liste chaînée de génération 0 et le seuil représente le seuil du nombre d'analyses de liste chaînée de génération 0. S'il dépasse le seuil, une vérification d'analyse de génération 1 sera effectuée. Génération 2, le nombre représente le nombre d'analyses de la liste chaînée de 1ère génération et le seuil représente le seuil du nombre d'analyses de la liste chaînée de 1ère génération. S'il dépasse le seuil, une vérification d'analyse de 2ème génération sera effectuée.
Le processus détaillé de gestion de la mémoire et de garbage collection sera expliqué sur la base de la couche inférieure du langage C et combiné avec des diagrammes.
Étape 1 : Lorsque l'objet age=19 est créé, l'objet sera ajouté à la liste refchain.
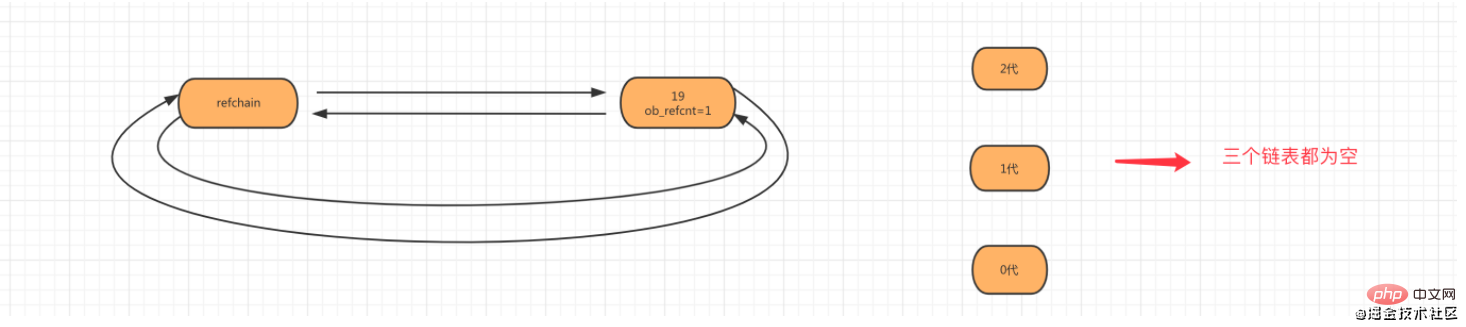
Étape 2 : Lorsque l'objet num_list = [11,22] est créé, l'objet liste sera ajouté à la refchain et aux générations 0.
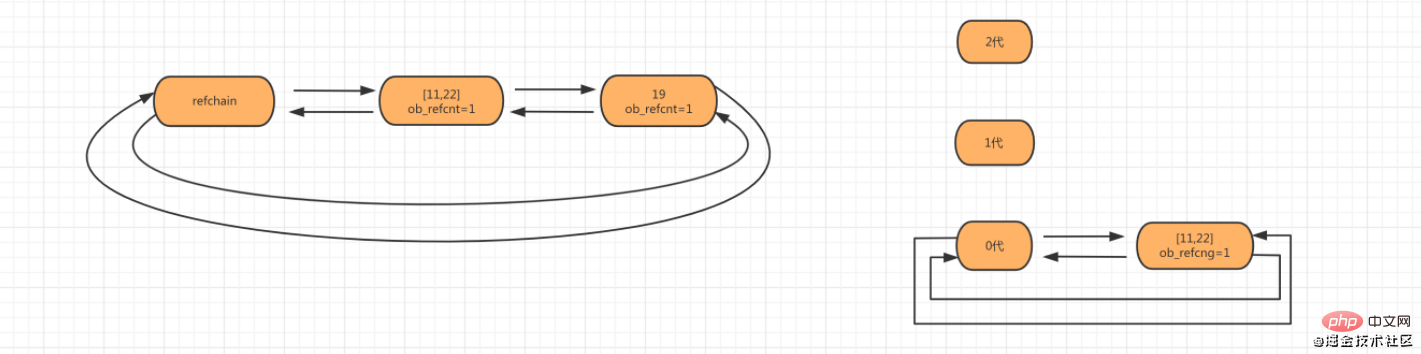
Étape 3 : Lorsque des objets nouvellement créés font que le nombre d'objets sur la liste chaînée des générations de génération 0 est supérieur au seuil de 700, scannez et vérifiez les objets sur la liste chaînée.
Lorsque la génération 0 est supérieure au seuil, la couche inférieure n'analyse pas directement la génération 0, mais détermine d'abord si 2 et 1 dépassent également le seuil.
Le La liste chaînée épissée est traitée Lors de la numérisation, la tâche principale est d'éliminer les références circulaires et de détruire les déchets. Le processus détaillé est le suivant :
.至此,垃圾回收的过程结束。
从上文大家可以了解到当对象的引用计数器为0时,就会被销毁并释放内存。而实际上他不是这么的简单粗暴,因为反复的创建和销毁会使程序的执行效率变低。Python中引入了“缓存机制”机制。
例如:引用计数器为0时,不会真正销毁对象,而是将他放到一个名为 free_list 的链表中,之后会再创建对象时不会在重新开辟内存,而是在free_list中将之前的对象来并重置内部的值来使用。
v1 = 3.14 # 开辟内存来存储float对象,并将对象添加到refchain链表。 print( id(v1) ) # 内存地址:4436033488 del v1 # 引用计数器-1,如果为0则在rechain链表中移除,不销毁对象,而是将对象添加到float的free_list. v2 = 9.999 # 优先去free_list中获取对象,并重置为9.999,如果free_list为空才重新开辟内存。 print( id(v2) ) # 内存地址:4436033488 # 注意:引用计数器为0时,会先判断free_list中缓存个数是否满了,未满则将对象缓存,已满则直接将对象销毁。复制代码
v1 = 38 # 去小数据池small_ints中获取38整数对象,将对象添加到refchain并让引用计数器+1。 print( id(v1)) #内存地址:4514343712 v2 = 38 # 去小数据池small_ints中获取38整数对象,将refchain中的对象的引用计数器+1。 print( id(v2) ) #内存地址:4514343712 # 注意:在解释器启动时候-5~256就已经被加入到small_ints链表中且引用计数器初始化为1, # 代码中使用的值时直接去small_ints中拿来用并将引用计数器+1即可。另外,small_ints中的数据引用计数器永远不会为0 # (初始化时就设置为1了),所以也不会被销毁。复制代码
v1 = "A" print( id(v1) ) # 输出:4517720496 del v1 v2 = "A" print( id(v1) ) # 输出:4517720496 # 除此之外,Python内部还对字符串做了驻留机制,针对只含有字母、数字、下划线的字符串(见源码Objects/codeobject.c),如果 # 内存中已存在则不会重新在创建而是使用原来的地址里(不会像free_list那样一直在内存存活,只有内存中有才能被重复利用)。 v1 = "asdfg" v2 = "asdfg" print(id(v1) == id(v2)) # 输出:True复制代码
list类型,维护的free_list数组最多可缓存80个list对象。
v1 = [11,22,33] print( id(v1) ) # 输出:4517628816del v1 v2 = ["你","好"] print( id(v2) ) # 输出:4517628816复制代码
v1 = (1,2)
print( id(v1) )del v1 # 因元组的数量为2,所以会把这个对象缓存到free_list[2]的链表中。v2 = ("哈哈哈","Alex") # 不会重新开辟内存,而是去free_list[2]对应的链表中拿到一个对象来使用。print( id(v2) )复制代码 v1 = {"k1":123}
print( id(v1) ) # 输出:4515998128
del v1
v2 = {"name":"哈哈哈","age":18,"gender":"男"}
print( id(v1) ) # 输出:4515998128复制代码C语言源码底层分析
相关免费学习推荐:python教程(视频)
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



