



[Recommandations d'apprentissage associées : Tutoriel vidéo sur la production de sites Web]
Qu'est-ce qu'un robot ? Pour faire simple et unilatéralement, un robot est un outil qui permet à un ordinateur d'interagir automatiquement avec un serveur pour obtenir des données. La chose la plus fondamentale à propos d'un robot d'exploration est d'obtenir les données du code source d'une page Web. Si vous allez plus loin, vous aurez une interaction POST avec la page Web et obtiendrez les données renvoyées par le serveur après avoir reçu la requête POST. En un mot, le robot est utilisé pour obtenir automatiquement les données source. Quant au traitement supplémentaire des données, etc., il s'agit d'un travail de suivi. Cet article veut principalement parler de cette partie de l'obtention des données par le robot. Crawlers, veuillez faire attention au fichier Robot.txt du site Web. Ne laissez pas les robots enfreindre la loi ou causer des dommages au site Web.
Exemples inappropriés de concepts anti-crawling et anti-anti-crawling
Pour de nombreuses raisons (telles que les ressources du serveur, la protection des données, etc.), de nombreux sites Web limiter l'effet crawler.
Pensez-y, si un humain joue le rôle d'un robot, comment obtenons-nous le code source de la page Web ? Le plus couramment utilisé est bien sûr de cliquer avec le bouton droit sur le code source ?
Que dois-je faire si le clic droit est bloqué sur le site Web

Supprimez F12, l'outil le plus utile que nous utilisons en crawl (bienvenue sur discuter)
Appuyez sur F12 en même temps pour l'ouvrir (drôle)
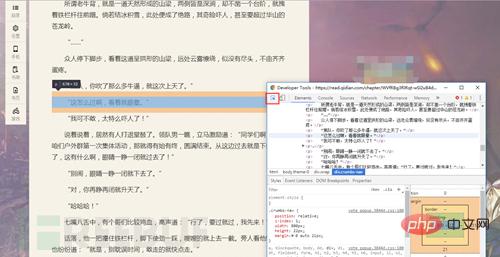
Le code source est sorti
Lors du traitement !! les gens en tant que robots d'exploration, bloquent le clic droit. C'est la stratégie anti-exploration, et F12 est la méthode anti-exploration.
Parlons de la stratégie anti-crawling formelle
En fait, il a dû y avoir des situations où aucune donnée n'a été renvoyée pendant le processus d'écriture d'un robot. Dans ce cas, il s'agit peut-être du serveur. Limiter l'en-tête UA (user-agent), c'est un anti-crawling très basique. Il suffit d'ajouter l'en-tête UA lors de l'envoi de la requête... N'est-ce pas très simple
En fait, ce n'est pas du tout nécessaire. Ajouter tous les en-têtes de requête requis est une méthode simple et grossière... Avez-vous trouvé que le code de vérification du site Web est également une stratégie anti-crawling ? pour garantir que les utilisateurs du site Web sont de vraies personnes, le code de vérification est vraiment fait. Une grande contribution. Parallèlement au code de vérification, la reconnaissance du code de vérification est apparue. En parlant de ça, je me demande quelle reconnaissance de code de vérification ou reconnaissance d'image est arrivée en premier. Il est très simple de reconnaître des codes de vérification simples maintenant. Il y a trop de tutoriels sur Internet, dont un. petits concepts avancés tels que le débruitage, le binaire, la segmentation et la réorganisation. Mais maintenant, la reconnaissance homme-machine des sites Web est devenue de plus en plus terrifiante, comme ceci :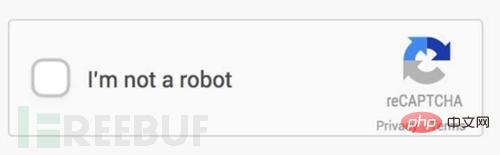

for x in range(0,image.size[0]): for y in range(0,image.size[1]): # print arr2[x][y] if arr[x][y].tolist()==底色: arr[x][y]=0 elif arr[x][y].tolist()[0] in range(200,256) and arr[x][y].tolist()[1] in range(200,256) and arr[x][y].tolist()[2] in range(200,256): arr[x][y]=0 elif arr[x][y].tolist()==[0,0,0]: arr[x][y]=0 else: arr[x][y]=255

Dans le développement du code de vérification, il existe des chiffres et des lettres relativement clairs, des additions, soustractions, multiplications et divisions simples. Il existe des roues sur Internet qui peuvent être utilisées pour certains nombres, lettres et caractères chinois difficiles. fabriquez également vos propres roues (comme celle ci-dessus), mais il y en a plus. Des choses suffisent pour écrire une intelligence artificielle... (Un type de travail consiste à reconnaître les codes de vérification...)
Ajoutez un peu astuce : certains sites internet ont des codes de vérification côté PC, mais pas côté téléphone portable...
Sujet suivant !
L'un des anti- Les stratégies d'exploration sont la stratégie de blocage IP. Généralement, trop de visites sur une courte période sont bloquées. C'est très simple de limiter la fréquence d'accès ou d'ajouter un pool de proxy IP. ..
Pool de proxy IP-> tournez à gauche vers Google et à droite vers baidu. Il existe de nombreux sites Web proxy, bien qu'ils soient gratuits. Pas beaucoup utilisés mais toujours ok.
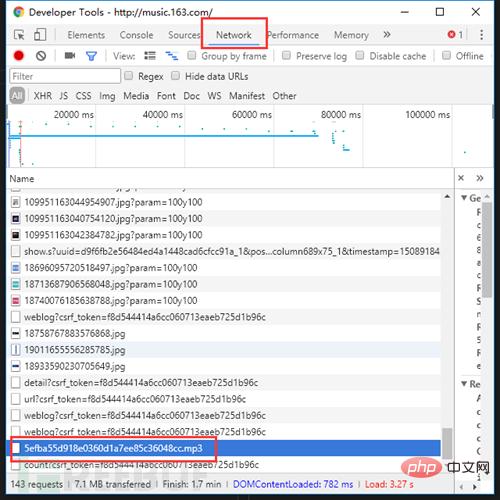
Un autre type de stratégie anti-crawler est celui des données asynchrones. Avec l'approfondissement progressif des robots (il s'agit évidemment d'une mise à jour du site !), le chargement asynchrone est un problème qui sera certainement rencontré, et la solution est. c'est toujours F12. Prenons l'exemple du site Web anonyme NetEase Cloud Music. Après avoir fait un clic droit pour ouvrir le code source, essayez de rechercher des commentaires

Où sont les données ?! après la montée en puissance des fonctionnalités JS et Ajax. Mais ouvrez F12, passez à l'onglet NetWork, actualisez la page et recherchez attentivement, il n'y a pas de secret.
Oh, au fait, si vous écoutez la chanson, vous pouvez la télécharger en cliquant sur...
Uniquement Pour vulgariser la structure du site Web, veuillez résister consciemment au piratage, protéger les droits d'auteur et protéger les intérêts du créateur original.
Et si ce site Web vous restreint ? Nous avons un dernier plan, une combinaison invincible : sélénium + PhantomJs
Cette combinaison est très puissante et peut parfaitement simuler le comportement du navigateur. Veuillez vous référer à Baidu pour plus de détails. Cette méthode n’est pas recommandée. Elle est très lourde et concerne uniquement la science populaire.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



