



[Recommandations d'apprentissage associées : Tutoriel Python]
Dans le processus d'analyse des données lui-même, nous analysons et utilisons Python pour traiter les données (données massives ), nous convertissons ces données en objets Python, comme le dictionnaire le plus courant.
Par exemple, il existe désormais des centaines de milliers de données (bien sûr, des données aussi volumineuses utiliseront généralement le concept de base de données et ne seront pas exécutées dans la mémoire CPU. Il nous est impossible d'utiliser des fonctions pour). en calculer dans Excel ça vaut le coup, c'est irréaliste.
Excel ne convient qu'au traitement de quantités relativement petites de données et présente l'avantage de la commodité et de la rapidité
Supposons donc qu'il y ait autant de données. Maintenant, je veux analyser, convertir et enfin analyser et traiter les données. , puis écrivez les données dans le fichier CSV, cela répond aux exigences, voyons donc comment écrire le dictionnaire de données dans le fichier CSV.
Associez ce projet à un système de calcul de score que nous avons écrit auparavant. N'oubliez pas que nous l'avons écrit sous forme de fichier txt, qui a été présenté sous la forme d'un dictionnaire, améliorons-le maintenant, juste pour présenter ces données analysées. pour d’autres, par exemple, nous devons désormais archiver et stocker ces données.
Tout d'abord, nous avons créé une fonction qui écrit spécifiquement dans des fichiers CSV
def csv_writer():
Ici, nous retirons d'abord la clé (en-tête) de nos données. Ici, nous utilisons Lorsqu'il s'agit d'une traversée. , certains amis ont demandé, pourquoi ne pas l'ajouter et l'écrire manuellement ? Je peux simplement copier quelques lignes. Mais réfléchissons-y s'il y a des dizaines de clés, comment pouvons-nous les copier directement ? un peu non automatisé, Python peut résoudre les problèmes de bureau. Ne prenez pas une heure, vous n'avez besoin que d'une minute.
a=[]
dict=student_infos[0]
for headers in sorted(dict.keys()):#把字典的键取出来
a.append(headers)
header=a#把列名给提取出来,用列表形式呈现L'en-tête ici est une liste
Ici, j'ai ouvert ce fichier et je me suis préparé à écrire, je vais expliquer les paramètres à l'intérieur un par un.
** a signifie écrire sous la forme "ajouter". S'il s'agit de "w", cela signifie que les données du fichier d'origine seront effacées avant l'écriture
une nouvelle ligne signifie qu'aucune ligne vide n'est ajoutée. entre les données.
encoding='utf-8' signifie que le format d'encodage est utf-8. Si vous ne souhaitez pas que des caractères chinois tronqués apparaissent lors de l'ouverture du fichier csv dans Excel, vous pouvez le supprimer sans l'écrire. .
Afin d'éviter que le fichier CSV dans pycharm ne soit tronqué, le codage des paramètres que nous utilisons ici est utf-8
et le format de codage du fichier Excel est gbk. Il est recommandé d'ajouter le codage. = paramètre 'utf-8'.
Si vous ne souhaitez pas que le fichier csv dans Excel soit tronqué, il est recommandé d'ouvrir le fichier csv dans le Bloc-notes et de l'enregistrer au format ANSI. **
with open('成绩更新.csv', 'a', newline='', encoding='utf-8') as f:
writer = csv.DictWriter(f, fieldnames=header) # 提前预览列名,当下面代码写入数据时,会将其一一对应。
writer.writeheader() # 写入列名
writer.writerows(student_infos) # 写入数据
print("数据已经写入成功!!!")Les données du dictionnaire ici sont les données que nous avons déjà analysées et traitées dans l'espace mémoire auparavant. J'écris ici la dernière ligne directement en utilisant .writerows (dictionnaire). avec writeheader() D'accord
En fait, écrire est si simple, et cela résout tous nos problèmes !
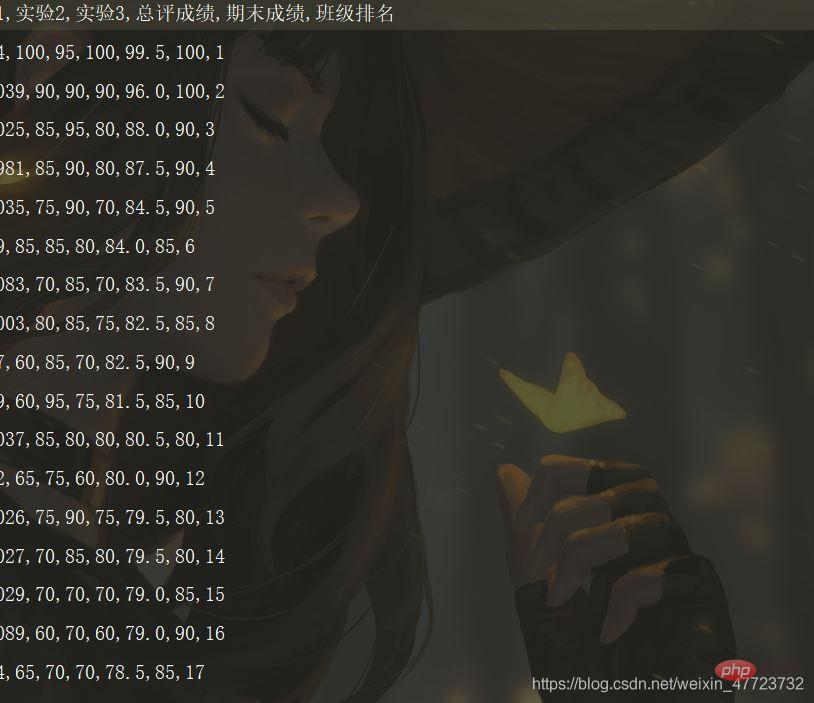

Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!


















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



