


Le contenu principal de cet article est d'utiliser plusieurs processus PHP avec la collection ordonnée de redis pour réaliser la déduplication de fichiers volumineux. Les amis intéressés peuvent en apprendre davantage.
1. Pour un fichier volumineux, par exemple, mon fichier est
-rw-r--r-- 1 ubuntu ubuntu 9.1G 1 mars 17:53 2018-12 -awk -uniq.txt
2. Utilisez la commande split pour couper en 10 petits fichiers
split -b 1000m 2018-12-awk-uniq.txt -b Couper en fonction des octets, unité de support m et k
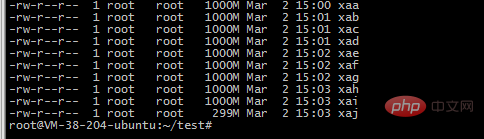
3. Utilisez 10 processus php pour lire le fichier et l'insérer dans la structure d'ensemble ordonnée de redis. être inséré. , afin qu'il puisse jouer le rôle de déduplication
<?php
$file=$argv[1];
//守护进程
umask(0); //把文件掩码清0
if (pcntl_fork() != 0){ //是父进程,父进程退出
exit();
}
posix_setsid();//设置新会话组长,脱离终端
if (pcntl_fork() != 0){ //是第一子进程,结束第一子进程
exit();
}
$start=memory_get_usage();
$redis=new Redis();
$redis->connect('127.0.0.1', 6379);
$handle = fopen("./{$file}", 'rb');
while (feof($handle)===false) {
$line=fgets($handle);
$email=str_replace("\n","",$line);
$redis->zAdd('emails', 1, $email);
}
4. Visualiser l'acquis. données dans Redis
e-mails zcard Obtenez le nombre d'éléments

Obtenez des éléments dans une certaine plage, par exemple à partir de 100 000 et se terminant à 100 100
zrange emails 100000 100100 WITHSCORES
Si vous souhaitez apprendre PHP plus efficacement, veuillez prêter attention au Tutoriel vidéo PHP sur le site Web PHP chinois.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Comment supprimer les premiers éléments d'un tableau en php
Comment supprimer les premiers éléments d'un tableau en php
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Logiciel de base de données couramment utilisé
Logiciel de base de données couramment utilisé
 Comment télécharger du HTML
Comment télécharger du HTML
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP










![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



