


Cet article vous apporte une brève introduction au prétraitement et aux cartes thermiques en python. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer. J'espère qu'il vous sera utile.
Il y a encore beaucoup de choses dans l'analyse des données. Je vais juste donner ici une introduction heuristique. Après avoir compris cet aspect, je pourrai trouver des solutions plus rapidement en l'utilisant, j'espère que cela sera utile à tout le monde.
Cette fois, nous utilisons toujours les données d'iris définies dans sklearn et les affichons via une carte thermique.
Prétraitement
sklearn.preprocessing est un module de prétraitement de la bibliothèque d'apprentissage automatique, qui permet de standardiser, régulariser, etc. les données et de les utiliser en fonction des besoins. Ici, sa méthode standardisée est utilisée pour organiser les données. D'autres méthodes peuvent être interrogées par vous-même.
Standardisation : Ajustez la distribution des données caractéristiques à une distribution normale standard, également appelée distribution gaussienne, ce qui signifie que la moyenne des données est de 0 et la variance est de 1.
La raison de la standardisation est que si la variance de certaines caractéristiques est trop grande, elle dominera la fonction objectif et empêchera l'estimateur de paramètres d'apprendre correctement d'autres caractéristiques.
Le processus de standardisation se déroule en deux étapes : décentralisation de la moyenne (la moyenne devient 0) ;
fournit une méthode d'échelle dans sklearn.preprocessing pour réaliser les fonctions ci-dessus.
Prenons un exemple :
from sklearn import preprocessing
import numpy as np
# 创建一组特征数据,每一行表示一个样本,每一列表示一个特征
xx = np.array([[1., -1., 2.],
[2., 0., 0.],
[0., 1., -1.]])
# 将每一列特征标准化为标准正太分布,注意,标准化是针对每一列而言的
xx_scale = preprocessing.scale(xx)
xx_scaleLe résultat après normalisation des données dans chaque colonne est :
array([[ 0. , -1.22474487, 1.33630621],
[ 1.22474487, 0. , -0.26726124],
[-1.22474487, 1.22474487, -1.06904497]])Comme vous pouvez le voir, à l'intérieur Les données ont changé , et la valeur est relativement petite. Peut-être que quelqu'un peut le voir d'un coup d'œil, mais peu importe s'il ne peut pas facilement calculer certaines de ses statistiques.
# 测试一下xx_scale每列的均值方差 print('均值:', xx_scale.mean(axis=0)) # axis=0指列,axis=1指行 print('方差:', xx_scale.std(axis=0))
Ce qui précède a présenté en quoi la standardisation doit être convertie. Les résultats sont en effet cohérents. Les résultats du calcul de la moyenne et de la variance par colonnes sont :
均值: [0. 0. 0.] 方差: [1. 1. 1.]
Bien sûr. pour la standardisation La variance et la moyenne ne doivent pas nécessairement être effectuées ensemble. Par exemple, parfois, si vous souhaitez simplement bénéficier de l'une des méthodes, il existe un moyen :
with_mean, with_std. paramètres, et les deux sont par défaut vrais, mais peuvent également être personnalisés sur faux, c'est-à-dire ne veulent pas dire centre ou ne mettent pas la variance à l'échelle 1.
Carte thermique<🎜. >
À propos de la carte thermique ici uniquement. Mentionnez-le simplement brièvement, car il existe déjà de nombreuses informations détaillées à ce sujet sur Internet. Dans une carte thermique, les données existent sous la forme d'une matrice, et la plage d'attributs est représentée par un dégradé de couleurs. Ici, pcolor est utilisé pour dessiner la carte thermique. Petite LiziPartez de la bibliothèque d'importation, puis chargez l'ensemble de données, traitez les données, puis dessinez l'image, faites quelques annotations et décorations sur l'image, etc. J'ai l'habitude de faire des commentaires dans le code. S'il y a quelque chose que vous ne comprenez pas, vous pouvez laisser un message et je vous répondrai à temps.# 导入后续所需要的库 from sklearn.datasets import load_iris from sklearn.preprocessing import scale import numpy as np import matplotlib.pyplot as plt # 加载数据集 data = load_iris() x = data['data'] y = data['target'] col_names = data['feature_names'] # 数据预处理 # 根据平均值对数据进行缩放 x = scale(x, with_std=False) x_ = x[1:26,] # 选取其中25组数据 y_labels = range(1, 26) # 绘制热图 plt.close('all') plt.figure(1) fig, ax = plt.subplots() ax.pcolor(x_, cmap=plt.cm.Greens, edgecolors='k') ax.set_xticks(np.arange(0, x_.shape[1])+0.5) # 设置横纵坐标 ax.set_yticks(np.arange(0, x_.shape[0])+0.5) ax.xaxis.tick_top() # x轴提示显示在图形上方 ax.yaxis.tick_left() # y轴提示显示在图形的左侧 ax.set_xticklabels(col_names, minor=False, fontsize=10) # 传递标签数据 ax.set_yticklabels(y_labels, minor=False, fontsize=10) plt.show()
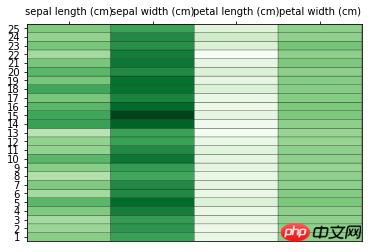
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



