


Cet article vous apporte une introduction détaillée au bytecode JVM en Java. Il a une certaine valeur de référence. Les amis dans le besoin peuvent s'y référer.
Il s'agit d'un article sur les bases de Java (JVM). Au départ, je voulais d'abord parler du mécanisme de chargement des classes Java, mais j'y ai ensuite réfléchi. Le rôle de la JVM est de charger le bytecode compilé par le compilateur. et l'interpréter dans un code machine, vous devez d'abord comprendre le bytecode, puis parler du mécanisme de chargement de classe pour charger le bytecode. Cela semble mieux, donc cet article est remplacé par une explication détaillée du bytecode.
En raison de la nature purement orientée objet de Java, tant que le bytecode peut représenter les informations d'une classe, il peut représenter l'intégralité du programme Java. Tant que la JVM peut charger les informations d'une classe. , il peut charger l'intégralité du programme. Par conséquent, qu'il s'agisse du bytecode ou du mécanisme de chargement JVM, l'accent est mis sur les classes. Mes principales préoccupations sont :
1. Puisque le bytecode n'est pas chargé en mémoire d'un seul coup, comment la JVM sait-elle où se trouvent les informations de classe qu'elle souhaite charger dans le fichier .class ?
2. Comment le bytecode représente-t-il les informations de classe ?
3. Le bytecode optimisera-t-il le programme ?
La première question est très simple, car même si un fichier source possède plusieurs classes (une seule classe publique), le compilateur générera un fichier .class pour chaque classe, et la JVM le chargera selon les besoins. charge le nom de la classe chargée.
Pour résoudre le problème suivant, regardons d'abord la composition du bytecode (ouvert avec Hex Fiend sur Mac).
Pour un morceau de code comme celui-ci :
package com.test.main1;
public class ByteCodeTest {
int num1 = 1;
int num2 = 2;
public int getAdd() {
return num1 + num2;
}
}
class Extend extends ByteCodeTest {
public int getSubstract() {
return num1 - num2;
}
}Analysons la classe Extend qu'il contient.
Ouvrez le fichier .class compilé avec Hex Fiend comme ceci (code hexadécimal) :
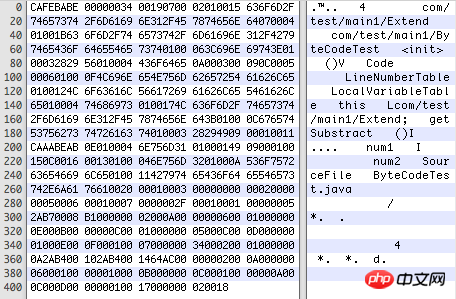
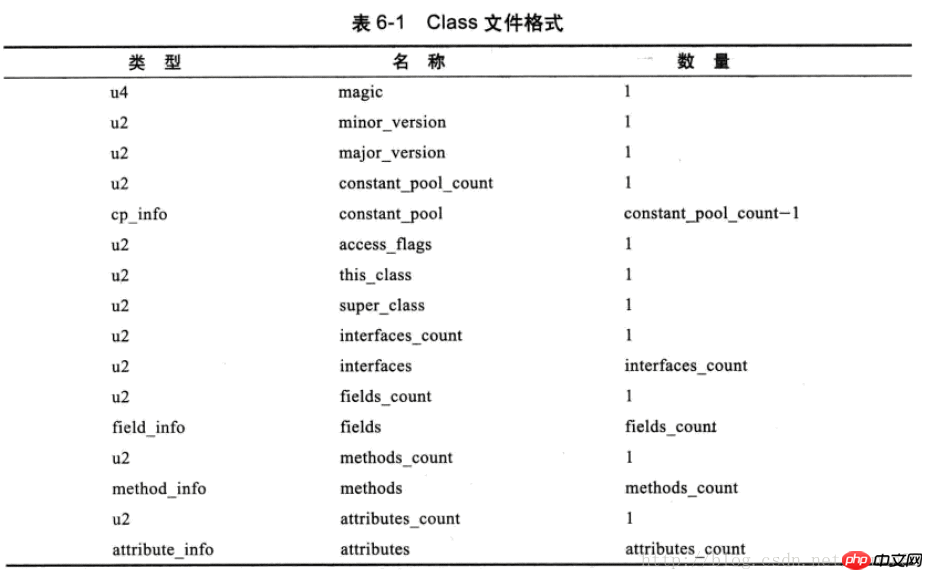
Puisque le fichier de classe n'a pas de délimiteur, chaque Ce que représente chaque position , la longueur de chaque partie et les autres formats sont strictement réglementés, voir le tableau ci-dessous :
où u1, u2, u4, u8 Un numéro non signé représentant plusieurs octets Dans le fichier hexadécimal décompilé, deux nombres représentent un octet, qui est u1.
Regardez-le un par un du début à la fin :
(1) magie : u4, le nombre magique, signifie que ce fichier est un fichier .class. .jpg, etc. auront également ce nombre magique. En raison du nombre magique, même si *.jpg est remplacé par *.123, il peut toujours être ouvert comme d'habitude.
(2) Version mineure, version majeure : chaque u2, numéro de version, rétrocompatible, c'est-à-dire que la version supérieure du JDK peut utiliser les fichiers .class de version inférieure, mais pas l'inverse.
(3) constant_pool_count : u2, le nombre de constantes dans le pool de constantes, 0019 représente 24.
(4) Viennent ensuite les constantes spécifiques, un total de constant_pool_count-1.
Le pool de constantes stocke généralement deux types de données :
Les littéraux : tels que les chaînes, les constantes finales modifiées, etc. ;
Les références de symboles : telles que le nom complet d'un classe/interface Noms qualifiés, noms et descriptions de méthodes, noms et descriptions de champs, etc.
Sur la base des nombres décompilés, recherchez d'abord le tableau ci-dessous pour obtenir le type et la longueur de la constante. Le nombre suivant égal à la longueur que vous avez recherchée représente la valeur spécifique de la constante.
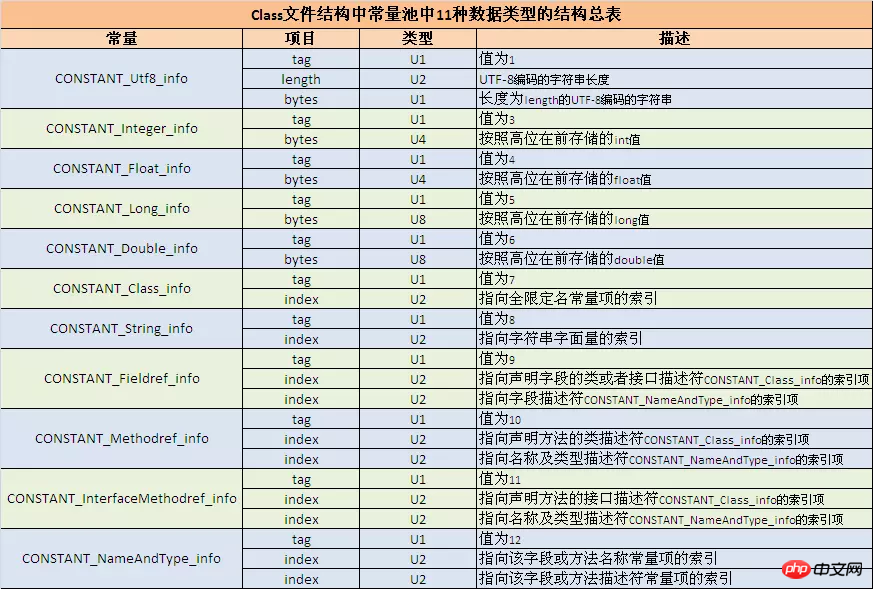
Par exemple, 070002, cela signifie que le type est CONSTANT_Class_info, sa balise est u1 et la longueur de u2 est l'index pointant vers l'élément constant de nom complet. Cet index doit également être consulté en conjonction avec le fichier de classe ouvert par javap -verbose. Le contenu et l'ordre dans le pool de constantes sont clairement répertoriés ici :
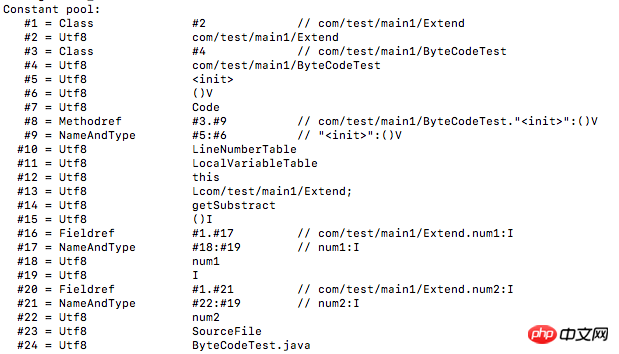
Vous pouvez voir 0002. ici La constante de l'élément d'index est : com/test/main1/Extend, qui est le nom complet de la classe. Si la valeur est une chaîne, vous devez convertir la valeur en décimal et vérifier la table de codes ASCII pour obtenir les caractères spécifiques. Les constantes suivantes sont analysées comme suit :
01001563 6F6D2F74 6573742F 6D61696E 312F4578 74656E64 : com/test/main1/Extend
070004 : com/test/main1/ByteCodeTest
01001B63
01000328 2956 : ()V01000443 6F6465 : Code0A000300 09 : com/test/main1/ByteCodeTest, "01000C67 65745375 62737472 616374: getSubstract
01000328 2949: () i
09000100 11: com / test / main1 / exc, num 1: i
🎜>
0C001200 13 : num1, I0100046E 756D31 : num101000149 : I09000100 15 : com/test/main1/Extend, num2:I 0C001600 13 : num2, I0100046E 756D32 : num201000A53 6F757263 6546696C 65 : SourceFile01001142 79746543 6F646554 6573742E 6A617661 : ByteCodeTest.java
À ce stade, toutes les constantes du pool de constantes ont été analysées.
(5) Vient ensuite le access_flags de u2 : le but principal du drapeau d'accès access_flags est de marquer si la classe est une classe ou une interface. S'il s'agit d'une classe, si l'autorisation d'accès est publique, s'il est abstrait, et s'il est marqué comme final, etc., voir le tableau ci-dessous :
| Flag_name | Value | Interpretation |
| ACC_PUBLIC | 0x0001 | 表示访问权限为public,可以从本包外访问 |
| ACC_FINAL | 0x0010 | 表示由final修饰,不允许有子类 |
| ACC_SUPER | 0x0020 | 较为特殊,表示动态绑定直接父类,见下面的解释 |
| ACC_INTERFACE | 0x0200 | 表示接口,非类 |
| ACC_ABSTRACT | 0x0400 | 表示抽象类,不能实例化 |
| ACC_SYNTHETIC | 0x1000 | 表示由synthetic修饰,不在源代码中出现,见附录[2] |
| ACC_ANNOTATION | 0x2000 | 表示是annotation类型 |
| ACC_ENUM | 0x4000 | 表示是枚举类型 |
所以,本类中的access_flags是0020,表示这个Extend类调用父类的方法时,并非是编译时绑定,而是在运行时搜索类层次,找到最近的父类进行调用。这样可以保证调用的结果是一定是调用最近的父类,而不是编译时绑定的父类,保证结果的正确性。
(6)this_class:u2的类索引,用于确定类的全限定名。本类的this_class是0001,表示在常量池中#1索引,是com/test/main1/Extend
(7)super_class:u2的父类索引,用于确定直接父类的全限定名。本类是0003,#3是com/test/main1/ByteCodeTest
(8)interfaces_count:u2,表示当前类实现的接口数量,注意是直接实现的接口数量。本类中是0000,表示没有实现接口。
(9)Interfaces:表示接口的全限定名索引。每个接口u2,共interfaces_count个。本类为空。
(10)fields_count:u2,表示类变量和实例变量总的个数。本类中是0000,无。
(11)fields:fileds的长度为filed_info,filed_info是一个复合结构,组成如下:
filed_info: {
u2 access_flags;
u2 name_index;
u2 descriptor_index;
u2 attributes_count;
attribute_info attributes[attributes_count];
}由于本类无类变量和实例变量,故本字段为空。
(12)methods_count:u2,表示方法个数。本类中是0002,表示有2个。
(13)methods:methods的长度为一个method_info结构:
method_info {
u2 access_flags; 0000 ?
u2 name_index; 0005 <init>
u2 descriptor_index; 0006 ()V
u2 attributes_count; 0001 1个
attribute_info attributes[attributes_count]; 0007 Code
}其中attribute_info结构如下:
attribute_info {
u2 attribute_name_index; 0007 Code
u1 attribute_length;
u1 info[attribute_length];
}上面是通用的attribute_info的定义,另外,JVM里预定义了几种attribute,Code即是其中一种(注意,如果使用的是JVM预定义的attribute,则attribute_info的结构就按照预定义的来),其结构如下:
Code_attribute { //Code_attribute包含某个方法、实例初始化方法、类或接口初始化方法的Java虚拟机指令及相关辅助信息
u2 attribute_name_index; 0007 Code
u4 attribute_length; 0000002F 47
u2 max_stack; 0001 1 //用来给出当前方法的操作数栈在方法执行的任何时间点的最大深度
u2 max_locals; 0001 1 //用来给出分配在当前方法引用的局部变量表中的局部变量个数
u4 code_length; 00000005 5 //给出当前方法code[]数组的字节数
u1 code[code_length]; 2AB70008 B1 42、183、0、8、177
//给出了实现当前方法的Java虚拟机代码的实际字节内容 (这些数字代码实际对应一些Java虚拟机的指令)
u2 exception_table_lentgh; 0000 0 //异常的信息
{
u2 start_pc; //这两项的值表明了异常处理器在code[]中的有效范围,即异常处理器x应满足:start_pc≤x≤end_pc
u2 end_pc; //start_pc必须在code[]中取值,end_pc要么在code[]中取值,要么等于code_length的值
u2 handler_pc; //表示一个异常处理器的起点
u2 catch_type; //表示当前异常处理器需要捕捉的异常类型。为0,则都调用该异常处理器,可用来实现finally。
} exception_table[exception_table_lentgh]; 在本类中大括号里的结构为空
u2 attribute_count; 0002 2 表示该方法的其它附加属性,本类有1个
attribute_info attributes[attributes_count]; 000A、000B LineNumberTable、LocalVariableTable
}LineNumberTable和LocalVariableTable又是两个预定义的attribute,其结构如下:
LineNumberTable_attribute { //被调试器用来确定源文件中由给定的行号所表示的内容,对应于Java虚拟机code[]数组的哪部分
u2 attribute_name_index; 000A
u4 attribute_length; 00000006
u2 line_number_table_length; 0001
{ u2 start_pc; 0000
u2 line_number; 000E //该值必须与源文件中对应的行号相匹配
} line_number_table[line_number_table_length];
}以及:
LocalVariableTable_attribute {
u2 attribute_name_index; 000B
u4 attribute_length; 0000000C
u2 local_variable_table_length; 0001
{ u2 start_pc; 0000
u2 length; 0005
u2 name_index; 000C
u2 descriptor_index; 000D //用来表示源程序中局部变量类型的字段描述符
u2 index; 0000
} local_variable_table[local_variable_table_length];然后就是第二个方法,具体略过。
(14)attributes_count:u2,这里的attribute表示整个class文件的附加属性,和前面方法的attribute结构相同。本类中为0001。
(15)attributes:class文件附加属性,本类中为0017,指向常量池#17,为SourceFile,SourceFile的结构如下:
SourceFile_attribute {
u2 attribute_name_index; 0017 SourceFile
u4 attribute_length; 00000002 2
u2 sourcefile_index; 0018 ByteCodeTest.java //表示本class文件是由ByteCodeTest.java编译来的
}嗯,字节码的内容大概就写这么多。可以看到通篇文章基本都是在分析字节码文件的16进制代码,所以可以这么说,字节码的核心在于其16进制代码,利用规范中的规则去解析这些代码,可以得出关于这个类的全部信息,包括:
1. 这个类的版本号;
2. 这个类的常量池大小,以及常量池中的常量;
3. 这个类的访问权限;
4. 这个类的全限定名、直接父类全限定名、类的直接实现的接口信息;
5. 这个类的类变量和实例变量的信息;
6. 这个类的方法信息;
7. 其它的这个类的附加信息,如来自哪个源文件等。
解析完字节码,回头再来看开始提出的问题,也就迎刃而解了。由于字节码文件格式严格按照规定,可以用来表示类的全部信息;字节码只是用来表示类信息的,不会进行程序的优化。
那么在编译期间,编译器会对程序进行优化吗?运行期间JVM会吗?什么时候进行的,按照什么原则呢?这个留作以后再表。
最后,值得注意的是,字节码不仅是平台无关的(任何平台生成的字节码都可以在任何的JRE环境运行),还是语言无关的,不仅Java可以生成字节码,其它语言如Groovy、Jython、Scala等也能生成字节码,运行在JRE环境中。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 tutoriel d'installation de pycharm
tutoriel d'installation de pycharm
 Comment vérifier l'état du port avec netstat
Comment vérifier l'état du port avec netstat
 Comment vérifier l'utilisation du processeur sous Linux
Comment vérifier l'utilisation du processeur sous Linux
 Comment lire des fichiers texte en HTML
Comment lire des fichiers texte en HTML
 évaluation python
évaluation python
 Récupérer les données du disque dur mobile
Récupérer les données du disque dur mobile
 Formule de la loi de conservation de l'énergie mécanique
Formule de la loi de conservation de l'énergie mécanique
 Comment définir la police en CSS
Comment définir la police en CSS












![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



