


Cet article présente principalement en détail comment utiliser l'artefact de collection PHP cURL. La fonction file_get_contents présente plus d'avantages pour obtenir des données à partir de liens distants. Les amis intéressés peuvent se référer au
manuel recommandé : manuel d'auto-apprentissage complet en phpPour ceux qui ont collecté des données, cURL sera certainement familier. Bien qu'il existe une fonction file_get_contents en PHP qui peut obtenir des données de liaison distante, sa contrôlabilité est trop faible pour divers scénarios de collecte complexes, file_get_contents semble un peu impuissante. Par conséquent, cet article vous présentera l’utilisation de l’artefact de collection cURL. Tout d'abord, permettez-moi d'ajouter comment la fonction file_get_contents peut obtenir des données de liaison distante.
<?php $url = "http://git.oschina.net/yunluo/API/raw/master/notice.txt"; $ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10); $notice = curl_exec($ch); echo $notice; ?>
<?php
if (function_exists('curl_init')) {
$url = "http://git.oschina.net/yunluo/API/raw/master/notice.txt";
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 10);
$dxycontent = curl_exec($ch);
echo $dxycontent;
} else {
echo '汗!貌似您的服务器尚未开启curl扩展,无法收到来自云落的通知,请联系您的主机商开启,本地调试请无视';
}
?><?php echo file_get_contents( "http://git.oschina.net/yunluo/API/raw/master/notice.txt" ); ?>
FireFox + Firebug
Utilisez F12 pour ouvrir Firebug, nous pouvons obtenir l'interface comme indiqué dans la figure (1) :
1 L'icône en forme de flèche est l'outil de « sélection d'élément ». mettez l'icône en surbrillance, et en même temps, déplacer la souris dans la page sélectionnera en même temps le contenu correspondant dans le menu HTML. Cliquer sur le contenu à ce moment signifie que l'élément est sélectionné et la mise en surbrillance de l'icône est annulée. Comme le montre la figure (2) :
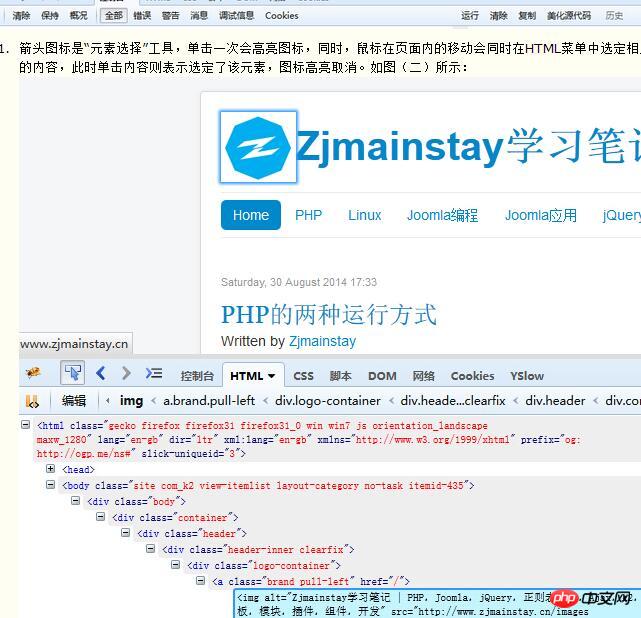 2 Console
2 Console
3. HTML
Contenu HTML. Notez que ce que vous voyez ici n'est pas nécessairement le contenu à analyser lors de la collecte. L'analyse du contenu lors de la collecte est toujours basée sur la visualisation du code source (Ctrl+U). C'est juste pour un positionnement rapide de la structure de l'élément, puis sélectionnez une référence plus spéciale pour localiser la position correspondante dans le code source.
Par exemple, vous voyez une balise en HTML qui est
Demo
, mais lorsque vous affichez le code source, le contenu que vous voyez peut être < ;p class ="demo" id="demo">Demo, si vous effectuez une correspondance régulière sur le contenu collecté selon la première, vous n'obtiendrez pas le résultat.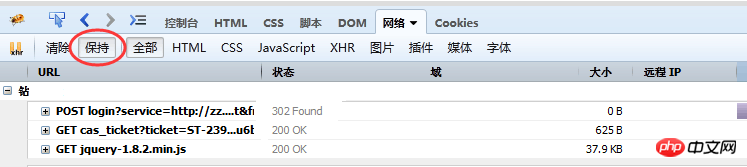 De plus, Firefox dispose également d'une extension de données Tamper qui peut également obtenir des données de requête, qui peuvent être installées et utilisées si nécessaire.
De plus, Firefox dispose également d'une extension de données Tamper qui peut également obtenir des données de requête, qui peuvent être installées et utilisées si nécessaire.
8. Cookies
Dans la figure (1), vous pouvez également voir qu'il existe de nombreux petits éléments de menu facultatifs ci-dessous, parmi lesquels la conservation est ce à quoi nous devons prêter attention lors de la sélection. même si la soumission du formulaire actualise la page, mais les données de la zone de contenu ci-dessous seront toujours conservées. Ceci est particulièrement critique pour l'analyse des données soumises.
Résumé
Lorsque nous analysons la demande de collecte, nous nous soucions principalement des données de la demande dans le menu "Réseau". Si nécessaire, utilisez "Conserver" pour afficher les données de la demande. Actualiser la page Demande Vous pouvez d'abord utiliser « Effacer » pour effacer le contenu suivant.
1 Collection simple
La collection simple mentionnée ici fait référence à une seule page GET La collection. des requêtes est si simple que vous pouvez facilement obtenir les résultats de retour de page même via la fonction file_get_contents.
Extrait de code file_get_contents
Extrait de code cURL
<?php $url = 'http://demo.zjmainstay.cn/php/curl/simple.html'; $content = file_get_contents($url); echo $content;
<?php $url = 'http://demo.zjmainstay.cn/php/curl/simple.html'; $ch = curl_init($url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 $content = curl_exec($ch); //执行并存储结果 curl_close($ch); echo $content;
相关文章推荐:
1.PHP的curl函数的详细介绍(总结)
2.PHP中使用CURL之php curl详细解析和常见大坑
相关视频推荐:
1.独孤九贱(4)_PHP视频教程
二、需要参数的采集
这种情况,页面请求需要传入一些参数,可以是GET请求,也可以是POST请求。这种情况的采集,使用file_get_contents外带一些参数还是可以实现的,但是这里我们将不再展示。
代码片段之cURL GET
这种请求,我们可以选择搜索引擎作为演示,比如我百度搜索一个词语“PHP cURL”,在输入回车后,我们会得到一个类似http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=&tn=baidu&bar=&wd=PHP%20cURL的链接,注意这里的链接可能不同浏览器、不同入口方式访问得到不一样结果,因此不必介意链接是否一样。通过输入多个关键词并观察链接,我们可以确定 wd 参数就是我们要传入的动态参数,而其他参数则可以不变,因此得到我们下面的采集代码。
<?php $keyword = 'PHP cURL'; $url = 'http://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&ch=&tn=baidu&bar=&wd=' . urlencode($keyword); $ch = curl_init($url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 $content = curl_exec($ch); //执行并存储结果 curl_close($ch); echo $content;
有些时候,一些参数并不是必须的,这时候我们可以删掉它,比如上面的链接可以只保留http://www.baidu.com/s?ie=utf-8&wd=PHP%20cURL,ie=utf-8 这个参数可能影响结果的编码,所以暂且留着它。就这样简单的代码,我们就可以采集到百度搜索的结果了。
代码片段之cURL POST
对于POST类型的请求,我们平时并不少见,比如有些搜索就是使用POST方式提交,这时候我们就需要使用POST类型来提交参数了。这个在PHP cURL里面有相应的参数:CURLOPT_POST 和 CURLOPT_POSTFIELDS , CURLOPT_POST 的设置可以指定当前提交是否为POST方式,CURLOPT_POSTFIELDS则用于设定提交的参数,可以是参数串,也可以是参数数组,比如:
curl_setopt($ch, CURLOPT_POSTFIELDS, 'ie=utf-8&wd=PHP%20cURL'); 或 curl_setopt($ch, CURLOPT_POSTFIELDS, array( 'ie' => 'utf-8', 'wd' => 'PHP%20cURL', ));
下面是我做的一个POST模拟搜索PHP POST 搜索,后端是使用了前面的百度关键词搜索,基本原理就是,客户端提交一个关键词到我服务器,我服务器使用该关键词请求百度的搜索,然后得到结果,返回到客户端。
如图(四)是利用Firebug对请求数据的分析,得到我们需要提交的请求链接和请求参数:
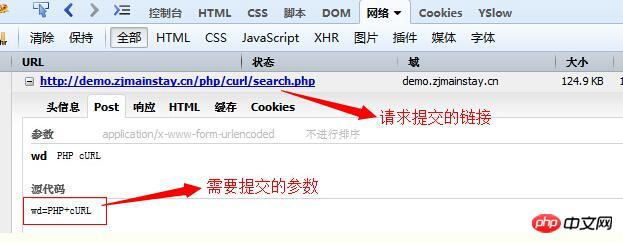
然后下面是我们的代码:
<?php
$keyword = 'PHP cURL';
//参数方法一
// $post = 'wd=' . urlencode($keyword);
//参数方法二
$post = array(
'wd' => urlencode($keyword),
);
$url = 'http://demo.zjmainstay.cn/php/curl/search.php';
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
var_dump($content);三、需要Referer的采集
对于一些程序,它可能判断来源网址,如果发现referer不是自己的网站,则拒绝访问,这时候,我们就需要添加CURLOPT_REFERER参数,模拟来路,使得程序能够正常采集。
<?php
$keyword = 'PHP cURL';
//参数方法一
// $post = 'wd=' . urlencode($keyword);
//参数方法二
$post = array(
'wd' => urlencode($keyword),
);
$url = 'http://demo.zjmainstay.cn/php/curl/search_refer.php';
$refer = 'http://demo.zjmainstay.cn/'; //来路地址
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
curl_setopt($ch, CURLOPT_REFERER, $refer); //来路模拟
curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据
curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
var_dump($content);search_refer.php的源码如下,做了简单的Referer判断拦截:
<?php
if(empty($_POST['wd'])) {
exit('Deny empty params.');
}
//Referer判断
if(stripos($_SERVER['HTTP_REFERER'], $_SERVER['HTTP_HOST']) === false) {
exit('Deny');
}
$keyword = addslashes(trim(strip_tags($_POST['wd'])));
$url = 'http://www.baidu.com/s?ie=utf-8&wd=' . urlencode($keyword);
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;四、需要cookie支持的采集
对于模拟登录的应用,单单提交参数和模拟来路并不能解决问题,这时候我们就需要保存或者提交相应的Cookie参数,这个在PHP cURL里面也提供了相应的参数:
CURLOPT_COOKIE: 直接使用字符串方式提交cookie参数
CURLOPT_COOKIEFILE: 使用文件方式提交cookie参数
CURLOPT_COOKIEJAR: 保存提交后反馈的cookie数据
下面是PHP100的模拟登录示例:
<?php
header("content-Type: text/html; charset=UTF-8");
$cookie_file = tempnam('./temp', 'cookie');
$login_url="http://bbs.php100.com/login.php";
$post_fields="cktime=36000&step=2&pwuser=username&pwpwd=password";
//提交登录表单请求
$ch=curl_init($login_url);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_POST,1);
curl_setopt($ch,CURLOPT_POSTFIELDS,$post_fields);
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file); //存储提交后得到的cookie数据
curl_exec($ch);
curl_close($ch);
//登录成功后,获取bbs首页数据
$url="http://bbs.php100.com/index.php";
$ch=curl_init($url);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_COOKIEFILE,$cookie_file); //使用提交后得到的cookie数据做参数
$contents=curl_exec($ch);
curl_close($ch);
//转码显示
echo iconv('gbk', 'UTF-8', $contents);五、压缩网页采集(gzip)
有些没有接触过压缩页面的朋友估计会在这里被坑死,因为他们会发现采集回来的内容是乱码,并且无论使用iconv还是强大的mb_convert_encoding都无法还原数据,然后又没有概念,各种抓狂却找不到方法,哈哈,我曾经也是这样~
如图(五)是乱码表现形式:
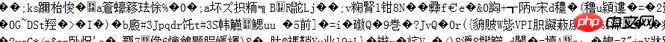
还好最后功夫不负有心人,还是找到了,它就是CURLOPT_ENCODING参数。
比如,采集搜狐的新闻时候就遇到gzip压缩问题,下面是示例:
<?php $url = 'http://news.sohu.com/'; $ch = curl_init($url); curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 curl_setopt($ch, CURLOPT_ENCODING, "gzip"); //指定gzip压缩 $content = curl_exec($ch); //执行并存储结果 curl_close($ch); echo $content;
手册说明:支持的编码有"identity","deflate"和"gzip"。如果为空字符串"",请求头会发送所有支持的编码类型。
后面一句表明,使用curl_setopt($ch, CURLOPT_ENCODING, "");也是可以的,但是不能不加这个参数。
六、SSL链接的采集
有些请求链接是https类型的,这时候使用cURL采集可能会失败,这时候,我们可以使用 var_dump(curl_error($ch));的方法打印错误提示,然后根据错误提示查找相应的解决方案。比如SSL错误常见提示:SSL certificate problem: unable to get local issuer certificate,这时候,我们就需要利用参数:CURLOPT_SSL_VERIFYPEER 和 CURLOPT_SSL_VERIFYHOST 来禁用SSL证书的验证,我尝试过只使用CURLOPT_SSL_VERIFYPEER参数禁用失败,所以大家最好同时使用两个参数。
下面是代码示例:
<?php $searchStr = 'RC376981638HK'; $post = 'accion=LocalizaUno&numero='.$searchStr.'&ecorreo=&numeros='; $url = 'https://aplicacionesweb.correos.es/localizadorenvios/track.asp'; $ch = curl_init($url); //初始化curl curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); //返回数据不直接输出 curl_setopt($ch, CURLOPT_POST, 1); //发送POST类型数据 curl_setopt($ch, CURLOPT_POSTFIELDS, $post); //POST数据,$post可以是数组,也可以是拼接参数串 curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); //SSL 报错时使用 curl_setopt($ch, CURLOPT_SSL_VERIFYHOST, false); //SSL 报错时使用 $contents = curl_exec($ch); //执行并存储结果 // var_dump(curl_error($ch)); //获取失败是使用(采集错误提示) curl_close($ch); echo $contents;
七、代理采集
大家都知道,国内存在万恶的墙,所以,假如我们需要获取某些被墙数据时,就需要用到国外代理服务器;又或者我们需要采集大量数据时,需要不断切换IP,也会用到代理。
使用代理在PHP cURL里面有几个相对应的参数:CURLOPT_PROXY、CURLOPT_PROXYPORT 和 CURLOPT_PROXYUSERPWD,还有另外几个,这里不列举。
CURLOPT_PROXY 指定代理IP参数
CURLOPT_PROXYPORT 指定代理端口参数
CURLOPT_PROXYUSERPWD 指定需要验证的代理的账号密码,"[username]:[password]"格式的字符串
关于代理账号获取,大家自己发挥,我这里提供网上搜索到的一个列表:cURL 高匿代理
下面是代理采集示例:
<?php
$url = 'http://demo.zjmainstay.cn/php/curl/dump_ip.php?t=' . time();
echo "本地IP:" . file_get_contents($url) . "\n伪造IP:";
$ip = '183.224.1.116';
$port = '80';
//伪造请求头参数,如果是高匿代理这里不需要提供
$header = array(
'X-FORWARDED-FOR: ' . $ip,
'CLIENT-IP: ' . $ip,
);
$ch = curl_init($url); //初始化curl
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_HTTPHEADER, $header);
curl_setopt($ch, CURLOPT_PROXY, $ip);
curl_setopt($ch, CURLOPT_PROXYPORT, $port);
$content = curl_exec($ch); //执行并存储结果
curl_close($ch);
echo $content;八、 多线程采集
对于大量采集工作,为了提高采集效率,使用PHP cURL提供的多线程采集是必不可少的。手册上提供的多线程采集例子好像都不太好用,我刚开始也从里面测试了几个例子,但是发现都是执行卡死,根本无法执行完成,前几天突然又测试了一下,然后发现curl_multi_info_read函数下面的Example #1是可以执行的,它的内容在$res上,但是没有打印出来,而且雅虎的请求比较慢,会卡住,前面两个链接都能正常返回。
不过,还好当时的例子不好用,然后我经过搜索找到了一个很厉害的项目,CurlMulti ,它对PHP cURL Multi 进行了一个良性扩展的封装,能够很好地提供采集支持。
关于CurlMulti的使用我就不多介绍,官网上面提供了demo,使用过程有技术难题可以直接加入Q群讨论,作者@Ares 和其他的采集大牛都会提供技术解答帮助。
下面是PHP cURL Multi的一个简单示例:
<?php
$urls = array(
"http://demo.zjmainstay.cn/php/curl/curl_multi_1.php",
"http://demo.zjmainstay.cn/php/curl/curl_multi_2.php",
);
$mh = curl_multi_init();
foreach ($urls as $i => $url) {
$conn[$i] = curl_init($url);
curl_setopt($conn[$i], CURLOPT_RETURNTRANSFER, 1); //不直接输出结果
curl_multi_add_handle($mh, $conn[$i]);
}
$active = null;
$res = array();
do {
$status = curl_multi_exec($mh, $active);
$info = curl_multi_info_read($mh);
if (false !== $info) {
//采集信息处理
$res[] = array(
'content' => curl_multi_getcontent($info['handle']),
'info' => $info,
);
curl_close($info['handle']);
}
} while ($status === CURLM_CALL_MULTI_PERFORM || $active);
curl_multi_close($mh);
var_dump($res);九、302跳转(301跳转)
对于一些应用,比如模拟登录,如果遇上302跳转,会导致cookie丢失而使得模拟登录失败,请求现象如图(六)所示:
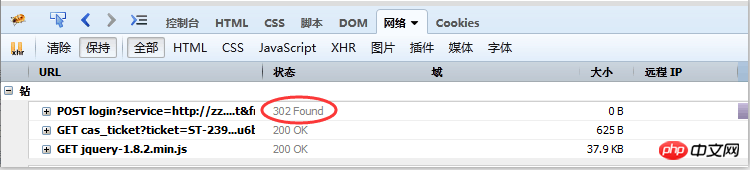
这个时候,可以使用:
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
关于CURLOPT_FOLLOWLOCATION,手册说明是:
启用时会将服务器服务器返回的"Location: "放在header中递归的返回给服务器,使用CURLOPT_MAXREDIRS可以限定递归返回的数量。
我个人理解,通俗点讲就是后面的跳转会继续跟踪访问,而且cookie在header里面被保留了下来。
十、模拟上传文件
在PHP手册的curl_setopt函数中,关于CURLOPT_POSTFIELDS有如下描述:
全部数据使用HTTP协议中的"POST"操作来发送。要发送文件,在文件名前面加上@前缀并使用完整路径。这个参数可以通过urlencoded后的字符串类似'para1=val1¶2=val2&...'或使用一个以字段名为键值,字段数据为值的数组。如果value是一个数组,Content-Type头将会被设置成multipart/form-data。
对于上传文件,这句话包含两个信息:
1. 要上传文件,post的数据参数必须使用数组,使得Content-Type头将会被设置成multipart/form-data。
2. 要上传文件,在文件名前面加上@前缀并使用完整路径。
因此,模拟文件上传可以按照如下实现:
//上传D盘下的test.jpg文件,文件必须存在,否则curl处理失败且没有任何提示 $data = array('name' => 'Foo', 'file' => '@d:/test.jpg'); $ch = curl_init('http://localhost/upload.php'); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS, $data); curl_exec($ch);
本地测试的时候,在upload.php文件中打印出\\(_POST和\$_FILES即可验证是否上传成功,如下: " print_r($_FILES);
输出结果类似:
Array ( [name] => Foo ) Array ( [file] => Array ( [name] => test.jpg [type] => application/octet-stream [tmp_name] => D:\xampp\tmp\php2EA0.tmp [error] => 0 [size] => 139999 ) )
关于CURLOPT_POSTFIELDS的赋值,另外补充一句描述:
传递一个数组到CURLOPT_POSTFIELDS,cURL会把数据编码成 multipart/form-data,而然传递一个URL-encoded字符串时,数据会被编码成 application/x-www-form-urlencoded。
即:
curl_setopt(\(ch, CURLOPT_POSTFIELDS, 'param1=val1¶m2=val2&...'); 和 curl_setopt(\)ch, CURLOPT_POSTFIELDS, array('param1' => 'val1', 'param2' => 'val2', ...));
这样一个功能强大的采集神器cURL的使用方法为大家介绍到这,希望对大家的学习有所帮助。
以上就是本文的全部内容,希望对大家的学习有所帮助,更多相关内容请关注PHP中文网!
相关推荐:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 curl_exec
curl_exec
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Comment supprimer les premiers éléments d'un tableau en php
Comment supprimer les premiers éléments d'un tableau en php
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Outils de téléchargement et d'installation Linux courants
Outils de téléchargement et d'installation Linux courants
 Comment télécharger du HTML
Comment télécharger du HTML








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



