


Cet article présente principalement l'implémentation de l'encodage/décodage Huffman en PHP. Il a une certaine valeur de référence. Maintenant, je le partage avec vous. Les amis dans le besoin peuvent s'y référer
L'encodage Huffman est un algorithme de compression de données. . Le cœur de notre compression zip couramment utilisée est le codage Huffman, et dans HTTP/2, le codage Huffman est utilisé pour compresser les en-têtes HTTP.
Cet article utilisera PHP pour pratiquer l'encodage et le décodage Huffman.
La première étape de l'encodage Huffman consiste à compter le nombre d'occurrences de chaque caractère dans la fonction intégrée de PHP peut le faire Faire : count_chars()
$input = file_get_contents('input.txt');$stat = count_chars($input, 1);
$huffmanTree = [];foreach ($stat as $char => $count) { $huffmanTree[] = [ 'k' => chr($char), 'v' => $count, 'left' => null, 'right' => null,
];
}// 构造树的层级关系,思想见wiki:https://zh.wikipedia.org/wiki/%E9%9C%8D%E5%A4%AB%E6%9B%BC%E7%BC%96%E7%A0%81$size = count($huffmanTree);for ($i = 0; $i !== $size - 1; $i++) {
uasort($huffmanTree, function ($a, $b) {
if ($a['v'] === $b['v']) { return 0;
} return $a['v'] < $b['v'] ? -1 : 1;
}); $a = array_shift($huffmanTree); $b = array_shift($huffmanTree); $huffmanTree[] = [ 'v' => $a['v'] + $b['v'], 'left' => $b, 'right' => $a,
];
}$root = current($huffmanTree); pointera vers le nœud racine de l'arbre de Huffman $root
function buildDict($elem, $code = '', &$dict) {
if (isset($elem['k'])) { $dict[$elem['k']] = $code;
} else {
buildDict($elem['left'], $code.'0', $dict);
buildDict($elem['right'], $code.'1', $dict);
}
}$dict = [];
buildDict($root, '', $dict); fournie par PHP peut écrire 8 bits (un octet) ou un multiple entier de 8 bits à la fois. Cependant, dans le codage Huffman, un caractère peut être représenté par seulement 1 bit, et PHP ne prend pas en charge l'opération d'écriture d'un seul bit dans le fichier. Par conséquent, nous devons épisser l’encodage nous-mêmes et écrire le fichier uniquement après l’obtention de 8 bits. fwrite()
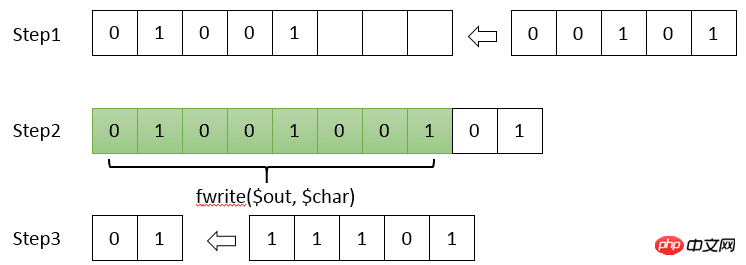
$dictString = serialize($dict);// 写入字典和编码各自占用的字节数$header = pack('VV', strlen($dictString), strlen($input));
fwrite($outFile, $header);// 写入字典本身fwrite($outFile, $dictString);// 写入编码的内容$buffer = '';$i = 0;while (isset($input[$i])) { $buffer .= $dict[$input[$i]]; while (isset($buffer[7])) { $char = bindec(substr($buffer, 0, 8));
fwrite($outFile, chr($char)); $buffer = substr($buffer, 8);
} $i++;
}// 末尾的内容如果没有凑齐 8-bit,需要自行补齐if (!empty($buffer)) { $char = bindec(str_pad($buffer, 8, '0'));
fwrite($outFile, chr($char));
}
fclose($outFile);<?php$content = file_get_contents('a.out');// 读出字典长度和编码内容长度$header = unpack('VdictLen/VcontentLen', $content);$dict = unserialize(substr($content, 8, $header['dictLen']));$dict = array_flip($dict);$bin = substr($content, 8 + $header['dictLen']);$output = '';$key = '';$decodedLen = 0;$i = 0;while (isset($bin[$i]) && $decodedLen !== $header['contentLen']) { $bits = decbin(ord($bin[$i])); $bits = str_pad($bits, 8, '0', STR_PAD_LEFT); for ($j = 0; $j !== 8; $j++) { // 每拼接上 1-bit,就去与字典比对是否能解码出字符
$key .= $bits[$j]; if (isset($dict[$key])) { $output .= $dict[$key]; $key = ''; $decodedLen++; if ($decodedLen === $header['contentLen']) { break;
}
}
} $i++;
}echo $output;Avant l'encodage. : 418 504 octets après encodage : 280 127 octetséconomisez 33 % d'espace Si le texte original a beaucoup de contenu répété, l'espace économisé par l'encodage Huffman peut atteindre plus de 50. %.En plus du contenu texte, nous essayons d'encoder selon Huffman un fichier binaire, tel que le programme d'installation f.lux. Les résultats des tests sont les suivants :
Avant. encodage : 770 384 octetsAprès encodage : 773 076 octetsAprès l'encodage, cela prend plus de place. D'une part, c'est parce qu'on ne fait pas de traitement supplémentaire lors du stockage du. dictionnaire, qui prend beaucoup de place. En revanche, dans les fichiers binaires, la probabilité d'apparition de chaque caractère est relativement égale et les avantages du codage de Huffman ne peuvent pas être utilisés. Recommandations associées :
Utiliser PHP pour implémenter une liste à chaînage unique
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment ouvrir le fichier php
Comment ouvrir le fichier php
 Comment supprimer les premiers éléments d'un tableau en php
Comment supprimer les premiers éléments d'un tableau en php
 Que faire si la désérialisation php échoue
Que faire si la désérialisation php échoue
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Comment télécharger du HTML
Comment télécharger du HTML
 Comment résoudre les caractères tronqués en PHP
Comment résoudre les caractères tronqués en PHP
 Comment ouvrir des fichiers php sur un téléphone mobile
Comment ouvrir des fichiers php sur un téléphone mobile








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



