


HTTP a de nombreuses versions, et chaque version a également ses propres différences. Cet article est un aperçu et un résumé des principales fonctionnalités des différentes versions de HTTP.
La version 1.0 de la précédente HTTP est un protocole de couche application sans état et sans connexion.
HTTP1.0 stipule que le navigateur et le serveur maintiennent une connexion à court terme. Chaque requête du navigateur doit établir une connexion TCP avec le serveur, le serveur déconnecte immédiatement la connexion TCP après. complétant le traitement (pas de connexion), le serveur ne suit pas chaque client ni n'enregistre les demandes passées (sans état).
Cette apatridie peut être réalisée grâce au cookie/session mécanisme d'authentification de l'identité et d'enregistrement du statut. Les deux questions suivantes sont plus gênantes.
Tout d'abord, le plus gros défaut de performances causé par la fonctionnalité sans connexion est l'incapacité de réutiliser les connexions. Chaque fois qu'une demande est envoyée, une connexion TCP est requise et le processus de libération de la connexion TCP prend beaucoup de temps. Cette fonctionnalité sans connexion rend l’utilisation du réseau très faible.
Le second est le blocage en tête de ligne (head of line blocking). Puisque HTTP1.0 stipule que la prochaine demande doit être envoyée avant que la réponse à la demande précédente n'arrive. En supposant que la réponse à la requête précédente n’arrive jamais, la requête suivante ne sera pas envoyée et les mêmes requêtes ultérieures seront également bloquées.
Afin de résoudre ces problèmes, HTTP1.1 est apparu.
Pour HTTP1.1, il hérite non seulement des fonctionnalités simples de HTTP1.0, mais surmonte également de nombreux HTTP1.0 problèmes de performances.
Le premier est une connexion longue, HTTP1.1 ajoute un champ Connection, en définissant Keep-Alive vous pouvez empêcher la HTTP connexion d'être déconnectée, évitant ainsi d'avoir besoin du le client doit se connecter au serveur à chaque fois. Les requêtes doivent être établies, libérées et établies à plusieurs reprises TCP connexions, ce qui améliore l'utilisation du réseau. Si le client souhaite fermer la connexion HTTP, il peut porter Connection: false dans l'en-tête de la requête pour indiquer au serveur de fermer la requête.
Deuxièmement, il y a la HTTP1.1Demande d'assistancePipelined (pipelining). La longue connexion basée sur HTTP1.1 rend possible le pipeline de requêtes. Le pipeline permet de transmettre des requêtes en parallèle. Par exemple, si le corps principal de la réponse est une page html et que la page contient plusieurs img, alors keep-alive joue un rôle important et peut envoyer plusieurs requêtes en parallèle. (Le client établit une connexion au serveur en fonction du nom de domaine. Généralement, les navigateurs PC établiront des 6~8 connexions au serveur d'un seul nom de domaine en même temps. Les terminaux mobiles contrôlent généralement le numéro vers 4~6. Ceci c'est pourquoi de nombreux grands sites Web mettent en place des ressources statiques différentes. Nom de domaine CDN pour charger les ressources.)
Il est à noter que le serveur doit renvoyer les résultats correspondants dans l'ordre demandé par le client pour garantir que le client puisse distinguer le contenu de la réponse de chaque requête.
En d'autres termes, HTTPPipeline nous permet de migrer la file d'attente premier entré, premier sorti du client (file d'attente des demandes) vers le serveur (file d'attente des réponses).
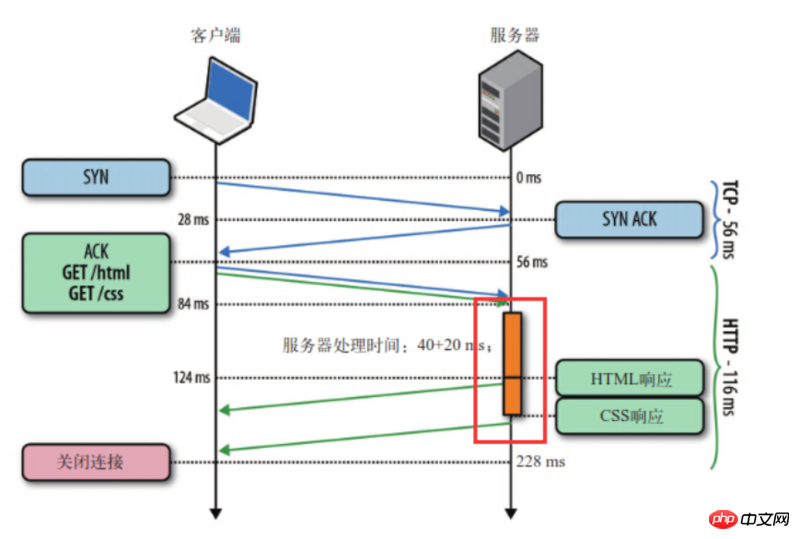
Comme le montre la figure, le client a envoyé deux requêtes en même temps pour obtenir respectivement html et css If du serveur. cssLa ressource est prête en premier, et le serveur enverra html d'abord puis css.
En même temps, la technologie des pipelines permet uniquement au client d'envoyer un ensemble de requêtes à un serveur en même temps. Si le client souhaite lancer un autre ensemble de requêtes vers le même serveur, il le fait. doit également attendre l'ensemble de demandes précédent. Toutes les réponses sont terminées.
On constate que HTTP1.1 la résolution du blocage de tête de ligne (head of line blocking) n'est pas encore terminée. Dans le même temps, il existe divers problèmes avec la technologie "pipeline", c'est pourquoi de nombreux navigateurs soit ne la supportent pas du tout, soit la désactivent simplement par défaut, et les conditions d'activation sont très strictes...
De plus, HTTP1.1 Le traitement du cache (cache fort et cache négocié [portail]) , la prise en charge de la transmission du point d'arrêt et l'ajout de Champ Hôte (permettant à un serveur de créer plusieurs sites Web). Les nouvelles fonctionnalités de
sont à peu près les suivantes : HTTP2.0
Binary Framing
Par Une couche de tramage binaire est ajoutée entre la couche d'application et la couche de transmission, ce qui dépasse les limitations de performances de HTTP2.0 et améliore les performances de transmission. HTTP1.1
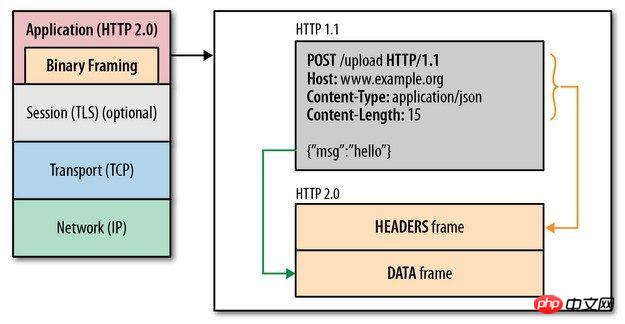
On peut voir que bien que les spécifications entre le protocole HTTP2.0 et le protocole HTTP1.x soient complètement différentes, HTTP2.0 ne change en réalité pas la sémantique de HTTP1.x.
Pour faire simple, HTTP2.0 ré-encapsule simplement les parties HTTP1.x et header de l'original body avec frame.
Multiplexage (partage de connexion)
Voici quelques concepts :
Stream (stream) : Octet bidirectionnel diffuser sur une connexion établie.
Message : Une série complète de trames de données correspondant au message logique.
Trame (frame) : HTTP2.0 La plus petite unité de communication. Chaque trame contient un en-tête de trame, qui identifie au moins le flux auquel appartient la trame actuelle (). stream id
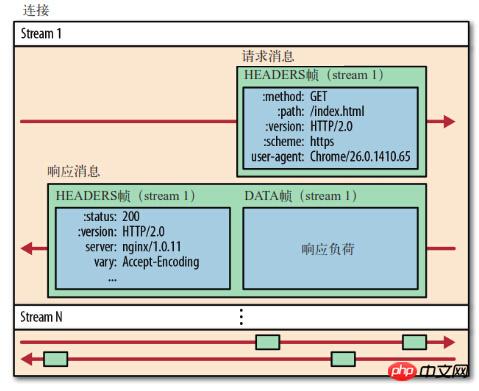
communications s'effectuent sur une connexion, qui peut transporter n'importe quel Quantité de flux de données bidirectionnel. HTTP2.0
) dans l'en-tête de chaque trame. stream id
pour identifier les données. flux auquel il appartient. Des images d’origines différentes peuvent être mélangées de manière aléatoire dans la connexion. Le récepteur peut réattribuer des trames à différentes requêtes en fonction de stream id. stream id
peut définir la priorité et les dépendances. Les flux de données avec une priorité élevée seront d'abord traités par le serveur et renvoyés au client. Les flux de données peuvent également dépendre d'autres sous-flux de données. HTTP2.0
Compression d'en-tête
Dans, les métadonnées d'en-tête sont envoyées en texte brut, ajoutant généralement 500 à 800 octets à chaque chargement de requête. HTTP1.x
, par défaut, le navigateur attachera cookie à cookie et l'enverra au serveur à chaque fois qu'il est demandé. (Étant donné que header est relativement volumineux et est envoyé à plusieurs reprises à chaque fois, les informations ne sont généralement pas stockées et ne sont utilisées que pour l'enregistrement du statut et l'authentification de l'identité) cookie
Utilisez HTTP2.0 pour réduire le nombre de encoder qui doivent être transmis. Taille, chaque partie communicante header dispose d'une cache table, ce qui non seulement évite les header fields transmissions répétées, mais réduit également la taille qui doit être transmise. Des algorithmes de compression efficaces peuvent compresser considérablement header, réduire le nombre de paquets envoyés et ainsi réduire la latence. header
Server Push
En plus de répondre à la requête initiale, le serveur peut envoyer des ressources supplémentaires au client sans demande explicite du client. RésuméHTTP1.0
HTTP1.1
, prendre en charge la transmission du point d'arrêt, etc.Host
HTTP2.0
À propos du Server Push HTTP/2
PHP implémente l'authentification HTTP
Exemple d'analyse de la façon dont PHP implémente les requêtes http simulées
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



