


Lorsque j'analysais un projet récemment, j'ai vu un fichier de données avec le suffixe ".sqlite". Comme je n'étais pas entré en contact avec lui auparavant, je réfléchissais à la façon d'utiliser python pour l'ouvrir. et effectuer l'analyse et le traitement des données, j'ai donc fait une petite recherche.
SQLite est une base de données relationnelle très populaire qui est utilisée par un grand nombre d'applications car elle est très légère.
Comme les fichiers csv, SQLite peut stocker des données dans un seul fichier de données pour un partage facile avec d'autres personnes. De nombreux langages de programmation prennent en charge le traitement des données SQLite, et le langage python ne fait pas exception.
sqlite3 est une bibliothèque standard de python qui peut être utilisée pour traiter les bases de données SQLite.
Pour les instructions SQL de la base de données, cet article utilisera les instructions SQL les plus basiques, ce qui ne devrait pas affecter la lecture. Si vous souhaitez en savoir plus, vous pouvez vous référer au site suivant :
Ensuite, nous appliquerons le module salite3 pour créer des fichiers de données SQLite et effectuer des opérations de lecture et d'écriture de données. Les principales étapes sont les suivantes :
Établir une connexion avec la base de données et créer un fichier de base de données (fichier .sqlite)
Créer un curseur
Créer une table de données (table)
Insérer des données dans la table de données
Requête data
Le code de démonstration est le suivant :
import sqlite3with sqlite3.connect('test_database.sqlite') as con:
c = con.cursor()
c.execute('''CREATE TABLE test_table
(date text, city text, value real)''')for table in c.execute("SELECT name FROM sqlite_master WHERE type='table'"):
print("Table", table[0])
c.execute('''INSERT INTO test_table VALUES
('2017-6-25', 'bj', 100)''')
c.execute('''INSERT INTO test_table VALUES
('2017-6-25', 'pydataroad', 150)''')
c.execute("SELECT * FROM test_table")
print(c.fetchall())Table test_table
[('2017-6-25', 'bj', 100.0), ('2017-6-25', 'pydataroad', 150.0)]Concernant l'aperçu visuel des données dans la base de données SQLite, il existe de nombreux outils qui peuvent être implémenté. J'utilise SQLite Studio ici. C'est un outil gratuit qui ne nécessite pas d'installation. Vous pouvez l'utiliser après l'avoir téléchargé. Les étudiants intéressés peuvent se référer au lien ci-dessous.
https://sqlitestudio.pl/index.rvt?act=download
L'effet de l'aperçu des données est le suivant :

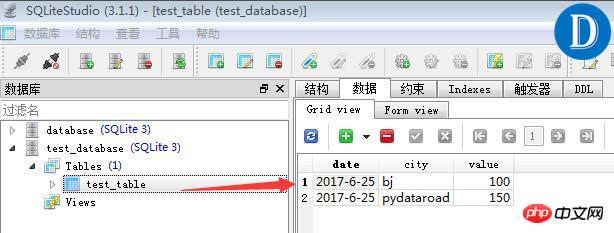
Comme le montrent les résultats d'exécution du code ci-dessus, le résultat de la requête de données est une liste composée de tuples. Les données de liste de Python peuvent être peu pratiques pour un traitement et une analyse ultérieurs des données. Vous pouvez imaginer que s'il y a 1 million de lignes de données ou plus dans la table de base de données, l'efficacité du parcours de la liste pour obtenir les données sera relativement faible.
À l'heure actuelle, nous pouvons envisager d'utiliser les fonctions fournies par pandas pour lire les informations de données pertinentes du fichier de base de données SQLite et les enregistrer dans un DataFrame pour faciliter le traitement ultérieur.
Pandas fournit deux fonctions, qui peuvent toutes deux lire des informations à partir de fichiers de données portant le suffixe ".sqlite".
read_sql()
read_sql_query()
import pandas as pdwith sqlite3.connect('test_database.sqlite') as con:# read_sql_query和read_sql都能通过SQL语句从数据库文件中获取数据信息df = pd.read_sql_query("SELECT * FROM test_table", con=con)# df = pd.read_sql("SELECT * FROM test_table", con=con)print(df.shape)
print(df.dtypes)
print(df.head())<code style="font-size: 14px; font-family: Roboto, 'Courier New', Consolas, Inconsolata, Courier, monospace; margin: auto 5px; white-space: pre; border-radius: 3px; display: block !important; overflow: auto; padding: 1px;">(2, 3) date object city object value float64 dtype: object date city value 0 2017-6-25 bj 100.0 1 2017-6-25 pydataroad 150.0<br></code>
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Caractères tronqués commençant par ^quxjg$c
Caractères tronqués commençant par ^quxjg$c
 outils de développement Python
outils de développement Python
 Comment ouvrir le fichier img
Comment ouvrir le fichier img
 python emballé dans un fichier exécutable
python emballé dans un fichier exécutable
 ce que python peut faire
ce que python peut faire
 Vous avez besoin de l'autorisation de l'administrateur pour apporter des modifications à ce fichier
Vous avez besoin de l'autorisation de l'administrateur pour apporter des modifications à ce fichier
 Comment utiliser le format en python
Comment utiliser le format en python
 tutoriel python
tutoriel python








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



