

Répertoire de cet article :
9.1 Description simple du processus
9.11 La différence entre processus et programme
9.12 Multitâches et tranches de temps CPU
9.13 Processus parent-enfant et comment créer des processus
9.14 État du processus
9.15 Exemple d'analyse de processus de transition de l'état du processus
9.16 Structure et sous-couches du processus
9.2 Tâche de travail
9.3 La relation entre le terminal et le processus
9.4 Signaux
9.41 Signaux à connaître
9.42 SIGHUP
9.43 Processus zombies et SIGCHLD
9.44 Envoyer manuellement un signal (commande kill)
9.45 pkill et killall
9.5 fuser et lsof
Le processus est un concept très complexe et implique beaucoup de contenu. Le contenu répertorié dans cette section a été extrêmement simplifié par moi. Vous devez le comprendre autant que possible. Je pense que ces théories sont plus importantes que la façon d'utiliser les commandes pour vérifier l'état. Si vous ne comprenez pas ces théories, vous pouvez. vérifiez les informations d'état plus tard, en gros, je ne sais pas ce que signifie le statut correspondant.
Mais pour les non-programmeurs, il n'est pas nécessaire d'approfondir les détails du processus. Bien sûr, plus on est de fous.
Un programme est un fichier binaire qui est stocké statiquement sur le disque et n'occupe pas les ressources d'exécution du système (processeur/mémoire).
Un processus est le résultat de l'exécution d'un programme par un utilisateur ou du déclenchement d'un programme. On peut considérer qu'un processus est une instance en cours d'exécution du programme. Le processus est dynamique, demandant et utilisant des ressources système et interagissant avec le noyau du système d'exploitation. Dans l'article suivant, les résultats de nombreux outils de statistiques d'état montrent l'état de la classe système. En fait, le synonyme d'état du système est l'état du noyau.
Désormais, tous les systèmes d'exploitation peuvent exécuter plusieurs processus "simultanément", c'est-à-dire multitâches ou On dit être exécutés en parallèle. Mais en fait, c'est une illusion humaine. Un processeur physique ne peut exécuter qu'un seul processus en même temps. Seuls plusieurs processeurs physiques peuvent réellement réaliser plusieurs tâches.
Les humains auront l'illusion que le système d'exploitation peut faire plusieurs choses en parallèle. Ceci est réalisé en basculant entre les processus dans un temps très court. Parce que le temps est très court, le processus A est exécuté au premier instant. , et le processus A est exécuté au moment suivant. Passez au processus B en même temps et basculez constamment entre plusieurs processus, faisant croire aux humains qu'ils traitent plusieurs choses en même temps.
Cependant, la manière dont le processeur choisit le prochain processus à exécuter est une question très compliquée. Sous Linux, la détermination du prochain processus à exécuter se fait via la "classe de planification" (scheduler) . Le moment où un programme s'exécute est déterminé par la priorité du processus, mais sachez que plus la valeur de priorité est faible, plus la priorité est élevée et plus tôt elle sera sélectionnée par la classe de planification. Sous Linux, modifier la valeur agréable d'un processus peut affecter la valeur de priorité d'un certain type de processus.
Certains processus sont plus importants et doivent être terminés le plus tôt possible, tandis que certains processus sont moins importants et les terminer plus tôt ou plus tard n'aura pas beaucoup d'impact. Par conséquent, le système d'exploitation doit être capable de savoir quels processus sont les plus importants. et quels processus sont moins importants. Pour les processus plus importants, plus de temps d'exécution CPU doit leur être alloué afin qu'ils puissent être terminés dans les plus brefs délais. La figure ci-dessous représente le concept de tranche de temps CPU.

De là, nous pouvons savoir que tous les processus ont la possibilité de s'exécuter, mais que les processus importants obtiendront toujours plus de temps CPU. Cette méthode est un traitement de tâches "multi-processus préemptif". " : Le noyau peut forcer la reprise des droits d'utilisation du CPU lorsque la tranche de temps est épuisée, et remettre le CPU au processus sélectionné par la classe de planification. De plus, dans certains cas, il peut également préempter directement le processus en cours d'exécution. Au fil du temps, le temps alloué au processus sera progressivement consommé. Lorsque le temps alloué est consommé, le noyau reprend le contrôle du processus et laisse le processus suivant s'exécuter. Mais comme le processus précédent n'est pas terminé, la classe de planification le sélectionnera toujours à un moment donné dans le futur, de sorte que le noyau doit sauvegarder l'environnement d'exécution (contenu des registres et des tables de pages) lorsque chaque processus est temporairement arrêté (l'emplacement de sauvegarde est la mémoire occupée par le noyau), c'est ce qu'on appelle le site de protection. La prochaine fois que le processus reprend son exécution, l'environnement d'exécution d'origine est chargé sur le CPU. C'est ce qu'on appelle le site de récupération, afin que le CPU puisse continuer à s'exécuter. l'environnement d'exécution d'origine.
Reading a déclaré que le planificateur Linux ne sélectionne pas le prochain processus à exécuter en fonction de l'écoulement de la tranche de temps CPU, mais considère le temps d'attente du processus, c'est-à-dire combien de temps il a attendu avant d'être prêt. file d'attente, et ceux qui sont intéressés par le temps, les processus ayant les exigences les plus strictes doivent être programmés pour être exécutés le plus tôt possible. De plus, les processus importants alloueront naturellement plus de temps d’exécution du processeur.
Une fois que la classe de planification a sélectionné le prochain processus à exécuter, elle doit effectuer un changement de tâche sous-jacente, c'est-à-dire un changement de contexte. Ce processus nécessite une interaction étroite avec le processus CPU. Les changements de processus ne doivent pas être trop fréquents ni trop lents. Une commutation trop fréquente entraînera une inactivité trop longue du processeur dans la scène de protection et de récupération, ce qui n'est pas productif pour les humains ou les processus (car il n'exécute pas de programmes). Une commutation trop lente entraînera une commutation lente de la planification du processus Il est très probable que le processus suivant devra attendre longtemps avant que ce soit son tour de s'exécuter. Pour parler franchement, si vous émettez une commande ls, vous devrez peut-être attendre une demi-journée, ce qui n'est évidemment pas autorisé.
À ce stade, vous savez également que l'unité de mesure du processeur est le temps , tout comme l'unité de mesure de la mémoire est la taille de l'espace. Le long temps CPU occupé par un processus signifie que le CPU passe beaucoup de temps à s'exécuter dessus. Notez que la valeur en pourcentage d'un processeur n'est pas son intensité ou sa fréquence de travail, mais "temps CPU occupé par le processus/temps CPU total". Ce concept de mesure ne doit pas être confondu.
Chaque processus se verra attribuer un identifiant unique basé sur l'UID de l'utilisateur qui exécute le programme et d’autres critères PID.
Le concept de processus parent-enfant. En termes simples, lorsqu'un programme est exécuté ou appelé dans le contexte d'un certain processus (processus parent), le processus déclenché par ce programme est le processus enfant, et le PPID. du processus représente le parent du processus. Le PID du processus. De là, nous savons également que les processus enfants sont toujours créés par les processus parents .
Sous Linux, les processus parent-enfant existent dans une structure arborescente, et plusieurs processus enfants créés par un processus parent sont appelés processus frères. Sur CentOS 6, le processus init est le processus parent de tous les processus, et sur CentOS 7, il s'agit de systemd.
Il existe trois façons de créer des processus enfants sous Linux (un concept extrêmement important) : l'une est un processus créé par fork, l'autre est un processus créé par exec et l'autre est un processus créé par clone. .
(1).fork est un processus de copie, qui copie une copie du processus actuel (quel que soit le mode de copie sur écriture) et remet ces ressources au processus enfant dans d'une manière appropriée. Par conséquent, les ressources contrôlées par le processus enfant sont les mêmes que celles du processus parent, y compris le contenu de la mémoire, il inclut donc également les variables d'environnement et les variables . Mais les processus parent et enfant sont complètement indépendants. Ce sont deux instances du même programme.
(2).exec consiste à charger une autre application pour remplacer le processus en cours d'exécution, ce qui signifie charger un nouveau programme sans créer de nouveau processus. exec a également une autre action. Une fois le processus exécuté, quittez le shell où se trouve exec. Par conséquent, afin de garantir la sécurité du processus, si vous souhaitez former un nouveau sous-processus indépendant, vous devez d'abord créer une copie du processus actuel, puis appeler exec sur le sous-processus créé pour charger un nouveau programme à remplacer. le sous-processus. Par exemple, lors de l'exécution de la commande cp sous bash, un bash sera d'abord dupliqué, puis exec chargera le programme cp pour écraser le processus sous-bash et devenir le processus cp.
(3).clone est utilisé pour implémenter les threads. Clone fonctionne de la même manière que fork, mais le nouveau processus cloné n'est pas indépendant du processus parent. Il ne partagera que certaines ressources avec le processus parent. Lors du clonage du processus, vous pouvez spécifier les ressources à partager.
Généralement, les processus frères et sœurs sont indépendants et invisibles les uns aux autres, mais parfois grâce à des moyens spéciaux, ils peuvent parvenir à une communication inter-processus. Par exemple, un canal coordonne les processus des deux côtés. Les processus des deux côtés appartiennent au même groupe de processus et leurs PPID sont les mêmes. Le canal leur permet de transférer des données de manière « pipeline ».
Un processus a un propriétaire, c'est-à-dire son initiateur. Si un utilisateur n'est pas l'initiateur du processus, l'initiateur du processus parent ou l'utilisateur root, il ne peut pas tuer le processus. Et tuer le processus parent (processus non terminal) fera du processus enfant un processus orphelin. Le processus parent du processus orphelin est toujours init/systemd.
Un processus n'est pas toujours en cours d'exécution, du moins il ne s'exécute pas lorsque le CPU ne fonctionne pas dessus. Un processus a plusieurs états, et une commutation d’état peut être réalisée entre différents états. L'image ci-dessous est un diagramme de description de l'état du processus très classique. Personnellement, je pense que l'image de droite est plus facile à comprendre.
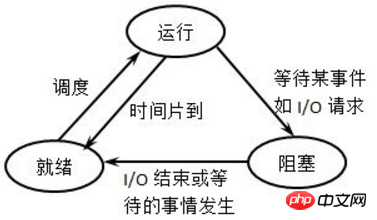
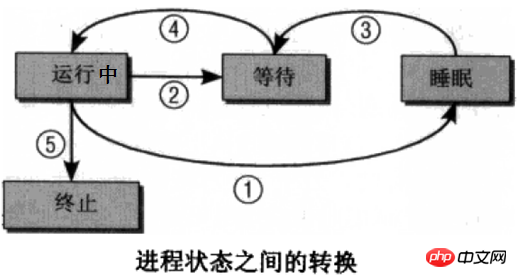
État d'exécution : le processus est en cours d'exécution, c'est-à-dire que le processeur est dessus.
État prêt (en attente) : le processus peut s'exécuter et est déjà dans la file d'attente, ce qui signifie que la classe de planification pourra le sélectionner la prochaine fois.
État veille (bloqué) : le processus est dormir et ne peut pas être utilisé pour courir.
La méthode de transition entre chaque état est : (Ce n'est peut-être pas facile à comprendre, vous pourrez la combiner avec l'exemple plus tard)
(1) Nouvel état -> État prêt : lorsque le la file d'attente est autorisée Lorsqu'un nouveau processus est admis, le noyau déplace le nouveau processus dans la file d'attente.
(2) État prêt -> État d'exécution : la classe de planification sélectionne un processus dans la file d'attente et le processus entre dans l'état d'exécution.
(3) État d'exécution -> État de veille : le processus en cours ne peut pas s'exécuter car il doit attendre l'apparition d'un certain événement (tel qu'une attente d'E/S, une attente de signal, etc.) et entre en état de veille .
(4) État de veille -> État prêt : lorsque l'événement que le processus attend se produit, le processus est mis en file d'attente de l'état de veille dans la file d'attente, en attendant d'être sélectionné pour l'exécution la prochaine fois.
(5) État d'exécution -> État prêt : le processus en cours d'exécution est suspendu en raison de l'expiration de la tranche de temps ou, en mode de planification préemptive, le processus à priorité élevée préempte de force le niveau de processus en cours d'exécution à faible priorité ; processus.
(6) État d'exécution -> État de fin : lorsqu'un processus est terminé ou qu'un événement spécial se produit, le processus passe à l'état terminé. Pour les commandes, les codes d’état de sortie sont généralement renvoyés.
Notez que dans l'image ci-dessus, il n'y a pas de changement d'état entre "Prêt-->Veille" et "Veille-->Exécuter". C'est facile à comprendre. Pour "Prêt-->Veille", le processus d'attente est déjà entré dans la file d'attente, indiquant qu'il peut être exécuté, et entrer dans l'état de veille signifie qu'il est temporairement inexécutable, ce qui est un conflit en soi pour "Veille-- ; >Exécuter" Cela ne fonctionne pas non plus car la classe de planification choisira simplement le prochain processus à exécuter dans la file d'attente.
Parlons de l'état de fonctionnement -> état de veille. De l'état de fonctionnement à l'état de veille, il s'agit généralement d'attendre l'apparition d'un événement, comme l'attente d'une notification de signal ou l'attente de la fin des IO. La notification du signal est facile à comprendre, mais pour l'attente des E/S, pour que le programme s'exécute, le CPU doit exécuter les instructions du programme, et en même temps des données doivent être saisies, qui peuvent être des données variables, des données saisies au clavier ou des données. dans les fichiers disque, ces deux derniers types de données sont extrêmement lents par rapport au processeur. Mais quoi qu'il en soit, si le processeur ne peut pas obtenir les données au moment où il en a besoin, il ne peut que rester inactif. Ce n'est certainement pas le cas, car le processeur est une ressource extrêmement précieuse, le noyau doit donc le laisser. le processeur fonctionne et a besoin de données. Le processus se met temporairement en veille et attend que ses données soient prêtes avant de retourner dans la file d'attente et d'attendre d'être sélectionné par la classe de planification. C'est IO en attente.
En fait, il manque dans l'image ci-dessus un état spécial de l'état processus-zombie. Le processus à l'état zombie signifie que le processus a été transféré à l'état terminé. Il a terminé sa mission et a disparu, mais le noyau n'a pas eu le temps de supprimer son entrée dans la liste des processus , ce qui signifie que le processus est à l'état zombie. Le noyau n'a pas à s'occuper de ses conséquences, cela crée l'illusion qu'un processus est à la fois mort et vivant. On le dit mort car il ne consomme plus de ressources, et il est impossible pour la classe d'ordonnancement de le sélectionner et de le laisser. run. On dit qu'il est vivant car il existe également une entrée correspondante dans la liste des processus, qui peut être capturée. Le processus zombie n'occupe pas beaucoup de ressources. Il n'occupe qu'un peu de mémoire dans la liste des processus. La plupart des processus zombies apparaissent parce que le processus se termine normalement (y compris kill -9), mais le processus parent ne confirme pas que le processus est terminé, il n'est donc pas notifié au noyau et le noyau ne sait pas que le processus est terminé. Pour une description plus détaillée du processus zombie, voir et versions ultérieures .
De plus, l'état de sommeil est un concept très large, divisé en sommeil interrompu et sommeil ininterrompu. Le sommeil interruption est un sommeil qui peut être réveillé en recevant des signaux externes et des signaux du noyau. La grande majorité du sommeil est un sommeil interruption. Le sommeil qui peut être capturé par ps ou top est presque toujours un sommeil ininterrompu qui ne peut être contrôlé. par le noyau. Initier un signal pour se réveiller. Le monde extérieur ne peut pas se réveiller via des signaux, principalement lors de l'interaction avec le matériel. Par exemple, lors du chargement d'un fichier, le chargement des données du disque dur dans la mémoire doit être ininterrompu pendant la courte période d'interaction avec le matériel, sinon il sera soudainement réveillé manuellement par un signal envoyé par les humains lors du chargement des données. , et lorsqu'il est réveillé, il ne sera pas interrompu. Le processus d'interaction matérielle n'est pas encore terminé, donc même s'il se réveille, il ne peut pas faire fonctionner le CPU, il est donc impossible d'afficher seulement une partie du contenu lorsqu'il est réveillé. chater un fichier. De plus, si un sommeil ininterrompu peut être réveillé artificiellement, la conséquence la plus grave sera un crash matériel. On peut voir que le sommeil ininterrompu vise à protéger certains processus importants et à éviter le gaspillage du processeur. En général, le sommeil ininterrompu est extrêmement de courte durée et extrêmement difficile à capturer sans programmation.
En fait, tant que le processus existe, n'est pas un processus zombie et n'occupe pas de ressources CPU, alors il est en veille. Y compris l’état de pause et l’état de suivi qui apparaissent plus loin dans l’article, ce sont également des états de veille.
La situation de transition d'état entre les processus peut être compliquée Voici un exemple pour la décrire. de manière aussi détaillée que possible.
Prenons l'exemple de l'exécution de la commande cp sous bash. Dans l'environnement bash actuel, lorsqu'il est dans un état exécutable (c'est-à-dire prêt), lorsque la commande cp est exécutée, un sous-processus bash est d'abord forké, puis le programme cp est chargé par exec sur le sous-processus bash. bash. Le sous-processus cp entre dans la file d'attente. La commande est tapée sur la ligne de commande, elle a donc une priorité plus élevée et la classe de planification la sélectionne rapidement. Pendant l'exécution du processus enfant cp, le processus parent bash entrera en état de veille (non seulement parce qu'un seul processus peut être exécuté à la fois lorsqu'il n'y a qu'un seul processeur, mais aussi parce que le processus est en attente) et attend d'être exécuté. réveillé. À ce moment, bash ne peut pas interagir avec les humains. Lorsque la commande cp est exécutée, elle informera le processus parent de son code d'état de sortie si la copie a réussi ou échoué. Ensuite, le processus cp disparaît de lui-même, et le processus parent bash est réveillé et entre à nouveau dans la file d'attente, et à. cette fois, bash a obtenu le code d'état de sortie. Selon le "signal" du code d'état, le processus parent bash sait que le processus enfant est terminé, il en informe donc le noyau. Après avoir reçu la notification, le noyau supprime l'entrée du processus cp dans la liste des processus. À ce stade, l’ensemble du processus cp se termine normalement.
Si le sous-processus cp copie un fichier volumineux et ne peut pas terminer la copie en une seule tranche de temps CPU, il entrera dans la file d'attente lorsqu'une tranche de temps CPU est épuisée.
Si le sous-processus cp copie un fichier et qu'il existe déjà un fichier du même nom à l'emplacement cible, il demandera par défaut s'il doit l'écraser. Lorsqu'il le demande, il attend un oui ou un non. signal, il entre donc dans un état de veille (interruptible) Sleep), lorsque vous tapez oui ou non un signal à cp sur le clavier, cp reçoit le signal et passe de l'état de veille à l'état prêt, en attendant que la classe de planification le sélectionne pour terminer le processus cp.
Lorsque cp copie, il doit interagir avec le disque Pendant le court processus d'interaction avec le matériel, cp sera en veille ininterrompue.
Si le processus cp se termine, mais que quelque chose d'inattendu se produit pendant le processus de fin, de sorte que le processus parent de bash ne sait pas qu'il est terminé (c'est impossible dans cet exemple), alors bash le fera. ne sera pas invité à recycler l'entrée cp dans la liste des processus, et cp deviendra un processus zombie à ce moment-là.
Processus de premier plan : les commandes générales (telles que la commande cp) bifurqueront le processus enfant pour l'exécution pendant l'exécution du processus enfant. , le processus parent Le processus se mettra en veille, ce qui est un processus de premier plan. Lorsque le processus de premier plan est exécuté, son processus parent se met en veille Comme il n'y a qu'un seul CPU, même s'il y a plusieurs CPU, un seul processus peut être exécuté en raison du flux d'exécution (processus en attente). true Pour le multitâche, le multithreading en cours doit être utilisé pour implémenter plusieurs flux d'exécution.
Processus en arrière-plan : Si vous ajoutez le symbole "&" à la fin de la commande lors de l'exécution de la commande, elle entrera en arrière-plan. Mettre la commande en arrière-plan reviendra immédiatement au processus parent et renverra l'ID de travail et le pid du processus d'arrière-plan, de sorte que le processus parent du processus d'arrière-plan ne se mettra pas en veille. Lorsqu'une erreur se produit dans le processus en arrière-plan, ou lorsque l'exécution est terminée et que le processus en arrière-plan se termine, le processus parent recevra le signal. Par conséquent, en ajoutant "&" après la commande, puis en donnant une autre commande à exécuter après le "&", peut obtenir une exécution "pseudo-parallèle" , telle que "cp /etc/fstab /tmp & cat /etc/fstab".
Commandes intégrées bash : les commandes intégrées bash sont très spéciales. Le processus parent ne créera pas de processus enfants pour exécuter ces commandes, mais sera exécuté directement dans le processus bash actuel. . Mais si vous placez la commande intégrée après le canal, la commande intégrée appartiendra au même groupe de processus que le processus sur le côté gauche du canal, donc le processus enfant sera toujours créé.
Cela dit, nous devrions expliquer le sous-shell, ce sous-processus spécial.
Généralement, le contenu d'un processus enfant forké est le même que celui du processus parent, y compris les variables. Par exemple, les variables du processus parent peuvent également être obtenues lors de l'exécution de la commande cp. Mais où la commande cp est-elle exécutée ? dans un sous-shell. Après avoir exécuté la commande cp et appuyé sur Entrée, le processus bash actuel génère un sous-bash, puis le sous-bash charge le programme cp via exec pour remplacer le sous-bash. S'il vous plaît, ne vous mêlez pas du sous-bash et du sous-shell ici. Si vous ne parvenez pas à comprendre leur relation, traitez-les simplement comme la même chose.
Peut-on comprendre que l'environnement d'exécution de toutes les commandes se trouve dans un sous-shell ? Évidemment, les commandes intégrées bash mentionnées ci-dessus ne sont pas exécutées dans un sous-shell. Toutes les autres méthodes sont effectuées dans des sous-shell, mais les méthodes sont différentes. Pour le sous-shell complet, voir man bash, où les sous-shell sont mentionnés à de nombreux endroits. Voici quelques méthodes courantes.
(1). Exécutez directement la commande bash. Il s’agit d’une commande très fortuite. La commande bash elle-même est une commande bash intégrée. L'exécution de la commande intégrée dans l'environnement shell actuel ne créera pas de sous-shell, ce qui signifie qu'aucun processus bash indépendant n'apparaîtra et le résultat réel est que le nouveau bash est un. processus enfant. L'une des raisons est que l'exécution de la commande bash chargera divers éléments de configuration de l'environnement. Afin de protéger l'environnement bash parent contre l'écrasement, il doit exister en tant que sous-shell. Bien que le contenu du processus enfant bash du fork hérite complètement du shell parent, en raison du rechargement des éléments de configuration de l'environnement, le shell enfant n'hérite pas des variables ordinaires. Pour être plus précis, il écrase les variables héritées de. le shell parent . Vous pourriez aussi bien essayer de définir une variable dans le fichier /etc/bashrc, puis exporter une variable d'environnement avec le même nom mais une valeur différente dans le shell parent, puis accéder au sous-shell pour voir quelle est la valeur de la variable ?
(2) Exécutez le script shell. Parce que la première ligne du script est toujours "#!/bin/bash" ou directement "bash xyz.sh", c'est en fait la même chose que l'exécution ci-dessus de bash pour entrer dans le sous-shell. Ils utilisent tous les deux la commande bash pour. entrez le sous-shell. C'est juste que le script d'exécution a une action supplémentaire : quitter automatiquement le sous-shell après l'exécution de la commande. Par conséquent, lorsque le script est exécuté, les variables d'environnement du shell parent ne seront pas héritées dans le script.
(3). Substitution de commandes pour les commandes non intégrées. Lorsque la commande contient une partie de substitution de commande, cette partie sera exécutée en premier. Si cette partie n'est pas une commande intégrée, elle sera complétée dans un sous-shell, puis le résultat de l'exécution sera renvoyé à la commande en cours. Étant donné que ce sous-shell n'est pas un sous-shell entré via la commande bash, il héritera de tout le contenu variable du shell parent. Cela explique également que le résultat de "$$" dans "$(echo $$)" est le numéro pid du bash actuel, et non le numéro pid du sous-shell, car il ne s'agit pas d'un sous-shell saisi à l'aide de la commande bash.
Il existe également deux méthodes spéciales d'appel de script : exec et source.
exec : exec est un chargeur qui remplace le processus actuel, il n'ouvre donc pas de sous-shell, mais exécute directement la commande ou le script dans le shell actuel. Après avoir exécuté exec, quittez directement. où se trouve exec. Cela explique pourquoi lors de l'exécution de la commande cp sous bash, le sous-shell où se trouve cp se fermera automatiquement après l'exécution de cp.
source : source est généralement utilisée pour charger des scripts de configuration d'environnement et ne peut pas charger directement des commandes. Il n'ouvre pas non plus de sous-shell, exécute directement le script appelant dans le shell actuel et ne quitte pas le shell actuel après l'exécution du script, de sorte que le script héritera des variables existantes actuelles et que les variables d'environnement chargées après l'exécution du script le feront. être collant au shell actuel, prend effet dans le shell actuel.
La plupart des processus peuvent la mettre en arrière-plan À l'heure actuelle, il s'agit d'une tâche en arrière-plan, donc c'est souvent le cas. appelé job, chaque shell ouvert maintiendra une table de tâches, et chaque tâche en arrière-plan correspond à un élément Job dans la table des tâches.
Pour exécuter manuellement une commande ou un script en arrière-plan, ajoutez le symbole "&" après la ligne de commande. Par exemple :
[root@server2 ~]# cp /etc/fstab /tmp/ &[1] 8701
Après avoir mis le processus en arrière-plan, il reviendra immédiatement à son processus parent. Généralement, les processus qui sont placés manuellement dans le processus parent. l'arrière-plan est exécuté sous bash, alors revenez immédiatement à l'environnement bash. Lors du renvoi du processus parent, son jobid et son pid seront également renvoyés au processus parent. Si vous souhaitez citer l'ID de travail à l'avenir, vous devez ajouter un signe de pourcentage "%" avant l'ID de travail, où "%%" représente le travail en cours. Par exemple, "kill -9 %1" signifie tuer le processus en arrière-plan avec l'ID de travail 1. . Si vous n'ajoutez pas une centaine de points-virgules, c'est fini, tuez le processus Init.
Vous pouvez afficher les informations sur les tâches en arrière-plan via la commande jobs.
jobs [--l:jobs默认不会列出后台工作的PID,加上---s:显示后台工作处于stopped状态的jobs
Les tâches placées en arrière-plan via "&" seront toujours exécutées en arrière-plan. Bien sûr, pour les commandes interactives telles que vim, elles entreront dans un état d'exécution en pause.
[root@server2 ~]# sleep 10 &[1] 8710[root@server2 ~]# jobs [1]+ Running sleep 10 &
Assurez-vous de noter que ce que vous voyez ici est le statut R affiché par running et ps ou top, ils sont non Cela signifie toujours exécuter, et les processus dans la file d'attente appartiennent également à l'exécution. Ils appartiennent tous à l’identifiant task_running.
Une autre façon de rejoindre manuellement l'arrière-plan consiste à appuyer sur les touches CTRL+Z. Cela peut ajouter le processus en cours à l'arrière-plan, mais le processus ajouté à l'arrière-plan sera suspendu en arrière-plan.
[root@server2 ~]# sleep 10^Z [1]+ Stopped sleep 10[root@server2 ~]# jobs [1]+ Stopped sleep 10
D'après les informations sur les emplois, nous pouvons également voir qu'il y a un signe "+" après chaque jobid, et il y a aussi un "-" , ou aucun signe.
[root@server2 ~]# sleep 30&vim /etc/my.cnf&sleep 50&[1] 8915[2] 8916[3] 8917
[root@server2 ~]# jobs [1] Running sleep 30 &[2]+ Stopped vim /etc/my.cnf [3]- Running sleep 50 &
On constate que le processus vim est suivi d'un signe plus, et "+" indique le tâche en cours d'exécution, c'est-à-dire qu'on dit que le CPU est dessus, "-" signifie la prochaine tâche à exécuter sélectionnée par la classe de planification, et elle ne sera pas marquée à partir de la troisième tâche. Il peut être analysé à partir de l'état des tâches. L'exécution sans "+" dans le tableau des tâches en arrière-plan signifie qu'elle est dans la file d'attente, l'exécution avec "+" signifie qu'elle est en cours d'exécution et l'état arrêté signifie qu'elle est dans la file d'attente. état de sommeil . Cependant, nous ne pouvons pas penser que les tâches de la liste de tâches seront toujours dans cet état, car la tranche de temps attribuée à chaque tâche est en réalité très courte. Après avoir exécuté la tâche de cette longueur de tranche de temps dans un laps de temps très court, elle le sera immédiatement. passer à la tâche suivante et exécuter. Cependant, dans le processus réel, étant donné que la vitesse de commutation et la tranche de temps de chaque tâche sont extrêmement courtes, lorsque la liste des tâches est petite, l'ordre affiché peut ne pas changer beaucoup.
En ce qui concerne l'exemple ci-dessus, la prochaine tâche à exécuter est vim, mais elle est arrêtée. Est-ce parce que le premier processus est arrêté que les autres processus ne seront pas exécutés ? Ce n'est évidemment pas le cas. En fait, d'ici peu, vous constaterez que les deux autres tâches de veille sont terminées, mais vim est toujours à l'état d'arrêt.
[root@server2 ~]# jobs [1] Done sleep 30[2]+ Stopped vim /etc/my.cnf [3]- Done sleep 50
Grâce à cet exemple de travail, avez-vous une compréhension plus approfondie de la manière dont les planifications du noyau sont traitées ?
Retour au sujet. Puisque vous pouvez mettre manuellement le processus en arrière-plan, vous pouvez certainement le ramener au premier plan. Si vous passez au premier plan pour vérifier la progression de l'exécution et que vous souhaitez le mettre en arrière-plan, il doit y avoir un moyen. Je n'utilise pas CTRL+Z pour l'ajouter en mode pause.
Les commandes fg et bg sont respectivement les abréviations de premier plan et d'arrière-plan, c'est-à-dire qu'elles sont placées au premier plan et à l'arrière-plan. À strictement parler, elles sont mises au premier plan et à l'arrière-plan dans un état d'exécution. , même si la tâche d'origine est dans un état arrêté.
La méthode d'opération est également très simple. Ajoutez simplement jobid directement après la commande (c'est-à-dire [fg|bg] [%jobid]). avec les éléments de tâche " +".
[root@server2 ~]# sleep 20^Z # 按下CTRL+Z进入暂停并放入后台 [3]+ Stopped sleep 20
[root@server2 ~]# jobs [2]- Stopped vim /etc/my.cnf [3]+ Stopped sleep 20 # 此时为stopped状态
[root@server2 ~]# bg %3 # 使用bg或fg可以让暂停状态的进程变会运行态 [3]+ sleep 20 &
[root@server2 ~]# jobs [2]+ Stopped vim /etc/my.cnf [3]- Running sleep 20 & # 已经变成运行态
Utilisez la commande disown pour supprimer directement une tâche de la table des tâches. Il s'agit simplement de supprimer la table des tâches, sans mettre fin à la tâche. Et après avoir supprimé la table des tâches, la tâche sera suspendue dans le processus init/systemd, la rendant indépendante du terminal .
disown [-ar] [-h] [%jobid ...] 选项说明:-h:给定该选项,将不从job table中移除job,而是将其设置为不接受shell发送的sighup信号。具体说明见"信号"小节。-a:如果没有给定jobid,该选项表示针对Job table中的所有job进行操作。-r:如果没有给定jobid,该选项严格限定为只对running状态的job进行操作
如果不给定任何选项,该shell中所有的job都会被移除,移除是disown的默认操作,如果也没给定jobid,而且也没给定-a或-r,则表示只针对当前任务即带有"+"号的任务项。
使用pstree命令查看下当前的进程,不难发现在某个终端执行的进程其父进程或上几个级别的父进程总是会是终端的连接程序。
例如下面筛选出了两个终端下的父子进程关系,第一个行是tty终端(即直接在虚拟机中)中执行的进程情况,第二行和第三行是ssh连接到Linux上执行的进程。
[root@server2 ~]# pstree -c | grep bash|-login---bash---bash---vim|-sshd-+-sshd---bash| `-sshd---bash-+-grep
正常情况下杀死父进程会导致子进程变为孤儿进程,即其PPID改变,但是杀掉终端这种特殊的进程,会导致该终端上的所有进程都被杀掉。这在很多执行长时间任务的时候是很不方便的。比如要下班了,但是你连接的终端上还在执行数据库备份脚本,这可能会花掉很长时间,如果直接退出终端,备份就终止了。所以应该保证一种安全的退出方法。
一般的方法也是最简单的方法是使用nohup命令带上要执行的命令或脚本放入后台,这样任务就脱离了终端的关联。当终端退出时,该任务将自动挂到init(或systemd)进程下执行。如:
shell> nohup tar rf a.tar.gz /tmp/*.txt
另一种方法是使用screen这个工具,该工具可以模拟多个物理终端,虽然模拟后screen进程仍然挂在其所在的终端上的,但同nohup一样,当其所在终端退出后将自动挂到init/systemd进程下继续存在,只要screen进程仍存在,其所模拟的物理终端就会一直存在,这样就保证了模拟终端中的进程继续执行。它的实现方式其实和nohup差不多,只不过它花样更多,管理方式也更多。一般对于简单的后台持续运行进程,使用nohup足以。
另外,可能你已经发现了,很多进程是和终端无关的,也就是不依赖于终端,这类进程一般是内核类进程/线程以及daemon类进程,若它们也依赖于终端,则终端一被终止,这类进程也立即被终止,这是绝对不允许的。
信号在操作系统中控制着进程的绝大多数动作,信号可以让进程知道某个事件发生了,也指示着进程下一步要做出什么动作。信号的来源可以是硬件信号(如按下键盘或其他硬件故障),也可以是软件信号(如kill信号,还有内核发送的信号)。不过,很多可以感受到的信号都是从进程所在的控制终端发送出去的。
Linux中支持非常多种信号,它们都以SIG字符串开头,SIG字符串后的才是真正的信号名称,信号还有对应的数值,其实数值才是操作系统真正认识的信号。但由于不少信号在不同架构的计算机上数值不同(例如CTRL+Z发送的SIGSTP信号就有三种值18,20,24),所以在不确定信号数值是否唯一的时候,最好指定其字符名称。
以下是需要了解的信号。
中断进程,可被捕捉和忽略,几乎等同于sigterm,所以也会尽可能的释放执行clean-up,释放资源,保存状态等(CTRL+ 强制杀死进程,该信号不可被捕捉和忽略,进程收到该信号后不会执行任何clean- 杀死(终止)进程,可被捕捉和忽略,几乎等同于sigint信号,会尽可能的释放执行clean-- 该信号是可被忽略的进程停止信号(CTRL+ 发送此信号使得stopped进程进入running,该信号主要用于jobs,例如bg & 用户自定义信号2
只有SIGKILL和SIGSTOP这两个信号是不可被捕捉且不可被忽略的信号,其他所有信号都可以通过trap或其他编程手段捕捉到或忽略掉。
更多更详细的信号理解或说明,可以参考wiki的两篇文章:
jobs控制机制:(Unix)
信号说明:
(1).当控制终端退出时,会向该终端中的进程发送sighup信号,因此该终端上行的shell进程、其他普通进程以及任务都会收到sighup而导致进程终止。
两种方式可以改变因终端中断发送sighup而导致子进程也被结束的行为:一是使用nohup命令启动进程,它会忽略所有的sighup信号,使得该进程不会随着终端退出而结束;二是使用disown,将任务列表中的任务移除出job table或者直接使用disown -h的功能设置其不接收终端发送的sighup信号。但不管是何种实现方式,终端退出后未被终止的进程将只能挂靠在init/systemd下。
(2).对于daemon类的程序(即服务性进程),这类程序不依赖于终端(它们的父进程都是Init或systemd),它们收到sighup信号时会重读配置文件并重新打开日志文件,使得服务程序可以不用重启就可以加载配置文件。
一个编程完善的程序,在子进程终止、退出的时候,会发送SIGCHLD信号给父进程,父进程收到信号就会通知内核清理该子进程相关信息。
在子进程死亡的那一刹那,子进程的状态就是僵尸进程,但因为发出了SIGCHLD信号给父进程,父进程只要收到该信号,子进程就会被清理也就不再是僵尸进程。所以正常情况下,所有终止的进程都会有一小段时间处于僵尸态(发送SIGCHLD信号到父进程收到该信号之间),只不过这种僵尸进程存在时间极短(倒霉的僵尸),几乎是不可被ps或top这类的程序捕捉到的。
如果在特殊情况下,子进程终止了,但父进程没收到SIGCHLD信号,没收到这信号的原因可能是多种的,不管如何,此时子进程已经成了永存的僵尸,能轻易的被ps或top捕捉到。僵尸不倒霉,人类就要倒霉,但是僵尸爸爸并不知道它儿子已经变成了僵尸,因为有僵尸爸爸的掩护,僵尸道长即内核见不到小僵尸,所以也没法收尸。悲催的是,人类能力不足,直接发送信号(如kill)给僵尸进程是无效的,因为僵尸进程本就是终结了的进程,不占用任何运行资源,也收不到信号,只有内核从进程列表中将僵尸进程表项移除才能收尸。
要解决掉永存的僵尸有几种方法:
(1).杀死僵尸进程的父进程。没有了僵尸爸爸的掩护,小僵尸就暴露给了僵尸道长的直系弟子init/systemd,init/systemd会定期清理它下面的各种僵尸进程。所以这种方法有点不讲道理,僵尸爸爸是正常的啊,不过如果僵尸爸爸下面有很多僵尸儿子,这僵尸爸爸肯定是有问题的,比如编程不完善,杀掉是应该的。
(2).手动发送SIGCHLD信号给僵尸进程的父进程。僵尸道长找不到僵尸,但被僵尸祸害的人类能发现僵尸,所以人类主动通知僵尸爸爸,让僵尸爸爸知道自己的儿子死而不僵,然后通知内核来收尸。
当然,第二种手动发送SIGCHLD信号的方法要求父进程能收到信号,而SIGCHLD信号默认是被忽略的,所以应该显式地在程序中加上获取信号的代码。也就是人类主动通知僵尸爸爸的时候,默认僵尸爸爸是不搭理人类的,所以要强制让僵尸爸爸收到通知。不过一般daemon类的程序在编程上都是很完善的,发送SIGCHLD总是会收到,不用担心。
使用kill命令可以手动发送信号给指定的进程。
kill [-s signal] pid...kill [-signal] pid...kill -l
使用kill -l可以列出Linux中支持的信号,有64种之多,但绝大多数非编程人员都用不上。
使用-s或-signal都可以发送信号,不给定发送的信号时,默认为TREM信号,即kill -15。
shell> kill -9 pid1 pid2... shell> kill -TREM pid1 pid2... shell> kill -s TREM pid1 pid2...
这两个命令都可以直接指定进程名来发送信号,不指定信号时,默认信号都是TERM。
(1).pkill
pkill和pgrep命令是同族命令,都是先通过给定的匹配模式搜索到指定的进程,然后发送信号(pkill)或列出匹配的进程(pgrep),pgrep就不介绍了。
pkill能够指定模式匹配,所以可以使用进程名来删除,想要删除指定pid的进程,反而还要使用"-s"选项来指定。默认发送的信号是SIGTERM即数值为15的信号。
pkill [-signal] [-v] [-P ppid,...] [-s pid,...][-U uid,...] [-t term,...] [pattern] 选项说明:-P ppid,... :匹配PPID为指定值的进程-s pid,... :匹配PID为指定值的进程-U uid,... :匹配UID为指定值的进程,可以使用数值UID,也可以使用用户名称-t term,... :匹配给定终端,终端名称不能带上"/dev/"前缀,其实"w"命令获得终端名就满足此处条件了,所以pkill可以直接杀掉整个终端-v :反向匹配-signal :指定发送的信号,可以是数值也可以是字符代表的信号
在CentOS 7上,还有两个好用的新功能选项。
-F, --pidfile file:匹配进程时,读取进程的pid文件从中获取进程的pid值。这样就不用去写获取进程pid命令的匹配模式-L, --logpidfile :如果"-F"选项读取的pid文件未加锁,则pkill或pgrep将匹配失败。
例如踢出终端:
shell> pkill -t pts/0
(2).killall
killall主要用于杀死一批进程,例如杀死整个进程组。其强大之处还体现在可以通过指定文件来搜索哪个进程打开了该文件,然后对该进程发送信号,在这一点上,fuser和lsof命令也一样能实现。
killall [-r,--regexp] [-s,--signal signal] [-u,--user user] [-v,--verbose] [-w,--wait] [-I,--ignore-case] [--] name ... 选项说明:-I :匹配时不区分大小写-r :使用扩展正则表达式进行模式匹配-s, --signal :发送信号的方式可以是-HUP或-SIGHUP,或数值的"-1",或使用"-s"选项指定信号-u, --user :匹配该用户的进程-v, :给出详细信息-w, --wait :等待直到该杀的进程完全死透了才返回。默认killall每秒检查一次该杀的进程是否还存在,只有不存在了才会给出退出状态码。 如果一个进程忽略了发送的信号、信号未产生效果、或者是僵尸进程将永久等待下去
fuser可以查看文件或目录所属进程的pid,即由此知道该文件或目录被哪个进程使用。例如,umount的时候提示the device busy可以判断出来哪个进程在使用。而lsof则反过来,它是通过进程来查看进程打开了哪些文件,但要注意的是,一切皆文件,包括普通文件、目录、链接文件、块设备、字符设备、套接字文件、管道文件,所以lsof出来的结果可能会非常多。
fuser [-ki] [-signal] file/dir-k:找出文件或目录的pid,并试图kill掉该pid。发送的信号是SIGKILL-i:一般和-k一起使用,指的是在kill掉pid之前询问。-signal:发送信号,如-1 -15,如果不写,默认-9,即kill -9不加选项:直接显示出文件或目录的pid
在不加选项时,显示结果中文件或目录的pid后会带上一个修饰符:
c:在当前目录下
e:可被执行的
f:是一个被开启的文件或目录
F:被打开且正在写入的文件或目录
r:代表root directory
例如:
[root@xuexi ~]# fuser /usr/sbin/crond/usr/sbin/crond: 1425e
表示/usr/sbin/crond被1425这个进程打开了,后面的修饰符e表示该文件是一个可执行文件。
[root@xuexi ~]# ps aux | grep 142[5] root 1425 0.0 0.1 117332 1276 ? Ss Jun10 0:00 crond
例如:
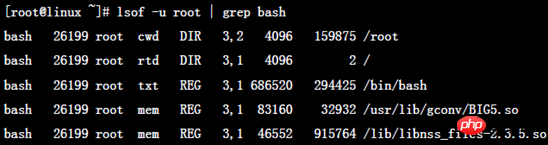
输出信息中各列意义:
COMMAND:进程的名称
PID:进程标识符
USER:进程所有者
FD:文件描述符,应用程序通过文件描述符识别该文件。如cwd、txt等
TYPE:文件类型,如DIR、REG等
DEVICE:指定磁盘的名称
SIZE/OFF:文件的大小或文件的偏移量(单位kb)(size and offset)
NODE:索引节点(文件在磁盘上的标识)
NAME:打开文件的确切名称
lsof的各种用法:
lsof /path/to/somefile:显示打开指定文件的所有进程之列表;建议配合grep使用 lsof -c string:显示其COMMAND列中包含指定字符(string)的进程所有打开的文件;可多次使用该选项lsof -p PID:查看该进程打开了哪些文件lsof -U:列出套接字类型的文件。一般和其他条件一起使用。如lsof -u root -a -Ulsof -u uid/name:显示指定用户的进程打开的文件;可使用脱字符"^"取反,如"lsof -u ^root"将显示非root用户打开的所有文件lsof +d /DIR/:显示指定目录下被进程打开的文件 lsof +D /DIR/:基本功能同上,但lsof会对指定目录进行递归查找,注意这个参数要比grep版本慢 lsof -a:按"与"组合多个条件,如lsof -a -c apache -u apache lsof -N:列出所有NFS(网络文件系统)文件 lsof -n:不反解IP至HOSTNAME lsof -i:用以显示符合条件的进程情况lsof -i[46] [protocol][@host][:service|port]46:IPv4或IPv6 protocol:TCP or UDP host:host name或ip地址,表示搜索哪台主机上的进程信息 service:服务名称(可以不只一个) port:端口号 (可以不只一个)
大概"-i"是使用最多的了,而"-i"中使用最多的又是服务名或端口了。
[root@www ~]# lsof -i :22COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME sshd 1390 root 3u IPv4 13050 0t0 TCP *:ssh (LISTEN) sshd 1390 root 4u IPv6 13056 0t0 TCP *:ssh (LISTEN) sshd 36454 root 3r IPv4 94352 0t0 TCP xuexi:ssh->172.16.0.1:50018 (ESTABLISHED)
回到系列文章大纲:
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 La différence entre les threads et les processus
La différence entre les threads et les processus
 Comment afficher les processus sous Linux
Comment afficher les processus sous Linux
 processus d'affichage Linux
processus d'affichage Linux
 navigateur.useragent
navigateur.useragent
 Utilisation de la commande source sous Linux
Utilisation de la commande source sous Linux
 Téléchargement du logiciel de trading Yiou
Téléchargement du logiciel de trading Yiou
 balises communes pour les dedecms
balises communes pour les dedecms
 jquery implémente la méthode de pagination
jquery implémente la méthode de pagination








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



