


En 2009, le projet Node.js est né, et tous les modules sont au format CommonJS.
Aujourd'hui, l'entrepôt de modules Node.js npmjs.com a stocké 150 000 modules, dont la plupart sont au format CommonJS.
Le cœur de ce format est l'instruction require, à travers laquelle les modules sont chargés. Lors de l'apprentissage de Node.js, vous devez apprendre à utiliser l'instruction require. Grâce à l'analyse du code source, cet article présente en détail le mécanisme de fonctionnement interne de l'instruction require pour vous aider à comprendre le mécanisme du module de Node.js.
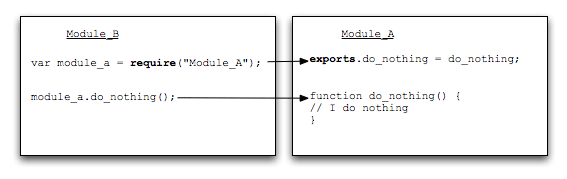
1. Utilisation de base de require()
Avant d'analyser le code source, introduisons d'abord la logique interne de l'instruction require. Si vous voulez simplement savoir comment utiliser require, lisez simplement ce paragraphe.
Le contenu suivant est traduit du "Manuel d'utilisation du nœud" .
Veuillez voir un exemple.
Le fichier de script actuel /home/ry/projects/foo.js exécute require('bar') , qui appartient à la troisième situation ci-dessus. Le processus de fonctionnement interne de Node est le suivant.
Tout d'abord, déterminez que le chemin absolu de x peut être les emplacements suivants et recherchez chaque répertoire tour à tour.
Lors de la recherche, Node traite d'abord bar comme nom de fichier, essaie de charger les fichiers suivants dans l'ordre et renvoie tant que l'on réussit.
bar bar.js bar.json bar.node
Si aucun des deux ne réussit, cela signifie que bar peut être un nom de répertoire, alors essayez de charger les fichiers suivants dans l'ordre.
Si le fichier ou le répertoire correspondant à bar ne peut être trouvé dans aucun répertoire, une erreur sera générée.
2. Constructeur de modules
Après avoir compris la logique interne, regardons le code source.
require se trouve dans le fichier lib/module.js de Node. Pour faciliter la compréhension, le code source cité dans cet article a été simplifié et les commentaires de l'auteur original ont été supprimés.
function Module(id, parent) {
this.id = id;
this.exports = {};
this.parent = parent;
this.filename = null;
this.loaded = false;
this.children = [];
}
module.exports = Module;
var module = new Module(filename, parent);
Dans le code ci-dessus, Node définit un constructeur Module, et tous les modules sont des instances de Module. Comme vous pouvez le voir, le module actuel (module.js) est également une instance de Module.
Chaque instance a ses propres propriétés. Prenons un exemple pour voir quelles sont les valeurs de ces attributs. Créez un nouveau fichier de script a.js.
// a.js
console.log('module.id: ', module.id);
console.log('module.exports: ', module.exports);
console.log('module.parent: ', module.parent);
console.log('module.filename: ', module.filename);
console.log('module.loaded: ', module.loaded);
console.log('module.children: ', module.children);
console.log('module.paths: ', module.paths);Exécutez ce script.
$ node a.js
module.id: .
module.exports: {}
module.parent: null
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
可以看到,如果没有父模块,直接调用当前模块,parent 属性就是 null,id 属性就是一个点。filename 属性是模块的绝对路径,path 属性是一个数组,包含了模块可能的位置。另外,输出这些内容时,模块还没有全部加载,所以 loaded 属性为 false 。
新建另一个脚本文件 b.js,让其调用 a.js 。
// b.js
var a = require('./a.js');运行 b.js 。
$ node b.js
module.id: /home/ruanyf/tmp/a.js
module.exports: {}
module.parent: { object }
module.filename: /home/ruanyf/tmp/a.js
module.loaded: false
module.children: []
module.paths: [ '/home/ruanyf/tmp/node_modules',
'/home/ruanyf/node_modules',
'/home/node_modules',
'/node_modules' ]
上面代码中,由于 a.js 被 b.js 调用,所以 parent 属性指向 b.js 模块,id 属性和 filename 属性一致,都是模块的绝对路径。
三、模块实例的 require 方法
每个模块实例都有一个 require 方法。
Module.prototype.require = function(path) {
return Module._load(path, this);
};由此可知,require 并不是全局性命令,而是每个模块提供的一个内部方法,也就是说,只有在模块内部才能使用 require 命令(唯一的例外是 REPL 环境)。另外,require 其实内部调用 Module._load 方法。
下面来看 Module._load 的源码。
Module._load = function(request, parent, isMain) {
// 计算绝对路径
var filename = Module._resolveFilename(request, parent);
// 第一步:如果有缓存,取出缓存
var cachedModule = Module._cache[filename];
if (cachedModule) {
return cachedModule.exports;
// 第二步:是否为内置模块
if (NativeModule.exists(filename)) {
return NativeModule.require(filename);
}
// 第三步:生成模块实例,存入缓存
var module = new Module(filename, parent);
Module._cache[filename] = module;
// 第四步:加载模块
try {
module.load(filename);
hadException = false;
} finally {
if (hadException) {
delete Module._cache[filename];
}
}
// 第五步:输出模块的exports属性
return module.exports;
};
上面代码中,首先解析出模块的绝对路径(filename),以它作为模块的识别符。然后,如果模块已经在缓存中,就从缓存取出;如果不在缓存中,就加载模块。
因此,Module._load 的关键步骤是两个。
四、模块的绝对路径
下面是 Module._resolveFilename 方法的源码。
Module._resolveFilename = function(request, parent) {
// 第一步:如果是内置模块,不含路径返回
if (NativeModule.exists(request)) {
return request;
}
// 第二步:确定所有可能的路径
var resolvedModule = Module._resolveLookupPaths(request, parent);
var id = resolvedModule[0];
var paths = resolvedModule[1];
// 第三步:确定哪一个路径为真
var filename = Module._findPath(request, paths);
if (!filename) {
var err = new Error("Cannot find module '" + request + "'");
err.code = 'MODULE_NOT_FOUND';
throw err;
}
return filename;
};
上面代码中,在 Module.resolveFilename 方法内部,又调用了两个方法 Module.resolveLookupPaths() 和 Module._findPath() ,前者用来列出可能的路径,后者用来确认哪一个路径为真。
为了简洁起见,这里只给出 Module._resolveLookupPaths() 的运行结果。
上面的数组,就是模块所有可能的路径。基本上是,从当前路径开始一级级向上寻找 node_modules 子目录。最后那三个路径,主要是为了历史原因保持兼容,实际上已经很少用了。
有了可能的路径以后,下面就是 Module._findPath() 的源码,用来确定到底哪一个是正确路径。
Module._findPath = function(request, paths) {
// 列出所有可能的后缀名:.js,.json, .node
var exts = Object.keys(Module._extensions);
// 如果是绝对路径,就不再搜索
if (request.charAt(0) === '/') {
paths = [''];
}
// 是否有后缀的目录斜杠
var trailingSlash = (request.slice(-1) === '/');
// 第一步:如果当前路径已在缓存中,就直接返回缓存
var cacheKey = JSON.stringify({request: request, paths: paths});
if (Module._pathCache[cacheKey]) {
return Module._pathCache[cacheKey];
}
// 第二步:依次遍历所有路径
for (var i = 0, PL = paths.length; i < PL; i++) {
var basePath = path.resolve(paths[i], request);
var filename;
if (!trailingSlash) {
// 第三步:是否存在该模块文件
filename = tryFile(basePath);
if (!filename && !trailingSlash) {
// 第四步:该模块文件加上后缀名,是否存在
filename = tryExtensions(basePath, exts);
}
}
// 第五步:目录中是否存在 package.json
if (!filename) {
filename = tryPackage(basePath, exts);
}
if (!filename) {
// 第六步:是否存在目录名 + index + 后缀名
filename = tryExtensions(path.resolve(basePath, 'index'), exts);
}
// 第七步:将找到的文件路径存入返回缓存,然后返回
if (filename) {
Module._pathCache[cacheKey] = filename;
return filename;
}
}
// 第八步:没有找到文件,返回false
return false;
};
经过上面代码,就可以找到模块的绝对路径了。
有时在项目代码中,需要调用模块的绝对路径,那么除了 module.filename ,Node 还提供一个 require.resolve 方法,供外部调用,用于从模块名取到绝对路径。
require.resolve = function(request) {
return Module._resolveFilename(request, self);
};
// 用法
require.resolve('a.js')
// 返回 /home/ruanyf/tmp/a.js
五、加载模块
有了模块的绝对路径,就可以加载该模块了。下面是 module.load 方法的源码。
Module.prototype.load = function(filename) {
var extension = path.extname(filename) || '.js';
if (!Module._extensions[extension]) extension = '.js';
Module._extensions[extension](this, filename);
this.loaded = true;
};上面代码中,首先确定模块的后缀名,不同的后缀名对应不同的加载方法。下面是 .js 和 .json 后缀名对应的处理方法。
Module._extensions['.js'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
module._compile(stripBOM(content), filename);
};
Module._extensions['.json'] = function(module, filename) {
var content = fs.readFileSync(filename, 'utf8');
try {
module.exports = JSON.parse(stripBOM(content));
} catch (err) {
err.message = filename + ': ' + err.message;
throw err;
}
};
这里只讨论 js 文件的加载。首先,将模块文件读取成字符串,然后剥离 utf8 编码特有的BOM文件头,最后编译该模块。
module._compile 方法用于模块的编译。
Module.prototype._compile = function(content, filename) {
var self = this;
var args = [self.exports, require, self, filename, dirname];
return compiledWrapper.apply(self.exports, args);
};
上面的代码基本等同于下面的形式。
(function (exports, require, module, __filename, __dirname) {
// 模块源码
});也就是说,模块的加载实质上就是,注入exports、require、module三个全局变量,然后执行模块的源码,然后将模块的 exports 变量的值输出。
(完)
 Comment utiliser exiger
Comment utiliser exiger
 Comment lire des fichiers et les convertir en chaînes en Java
Comment lire des fichiers et les convertir en chaînes en Java
 Pourquoi n'y a-t-il pas de son dans les réunions Tencent ?
Pourquoi n'y a-t-il pas de son dans les réunions Tencent ?
 Quels types de sélecteurs CSS existe-t-il ?
Quels types de sélecteurs CSS existe-t-il ?
 Que signifie la passerelle Edge Computing ?
Que signifie la passerelle Edge Computing ?
 Comment vérifier les ports sous Linux
Comment vérifier les ports sous Linux
 La différence entre un routeur et un chat
La différence entre un routeur et un chat
 La différence entre la carte MS et la carte SD
La différence entre la carte MS et la carte SD








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



