


De nombreuses applications Web enregistrent les données dans des systèmes de gestion de bases de données relationnelles tels que MySQL, application Le serveur lit le données de celui-ci et les affiche dans le navigateur. Cependant, à mesure que la quantité de données augmente et que l'accès se concentre, il y aura des effets négatifs tels qu'une charge accrue sur la base de données, une détérioration de la réponse de la base de données et un retard dans l'affichage du site Web. La mise en cache distribuée est un moyen important d'optimiser les performances des sites Web. Un grand nombre de sites fournissent des services de mise en cache de données chaudes à grande échelle via des clusters de serveurs évolutifs. En mettant en cache les données la bibliothèque les requêtes les résultats et en réduisant le nombre d'accès à la base de données, la vitesse et l'évolutivité des applications Web dynamiques peuvent être considérablement améliorées. Ceux couramment utilisés dans l'industrie incluent redis, memcached, etc. Ce dont je veux parler aujourd'hui, c'est comment utiliser le service de cache memcached dans le projet python .
memcached est un objetsystème de mise en cache de mémoire distribuée open source et hautes performances qui peut être appliqué Divers scénarios nécessitent une mise en cache, dont l'objectif principal est d'accélérer les applications Web en réduisant l'accès à la base de données.
Memcached lui-même ne fournit pas réellement de solution distribuée. Côté serveur, l'environnement de cluster memcached est en fait l'accumulation de serveurs memcached, et la construction de l'environnement est relativement simple ; la distribution du cache est principalement implémentée sur le client , et est traitée via le du client. routage Atteindre l'objectif des solutions distribuées. Le principe du routage client est très simple. Chaque fois que le serveur d'applications accède à la valeur d'une certaine clé, il mappe la clé à un certain nœud de serveur memcached via l'algorithme de routage. sont effectués sur le nœud A. Continuez. Tant que le serveur met toujours les données en cache, un accès au cache est garanti. 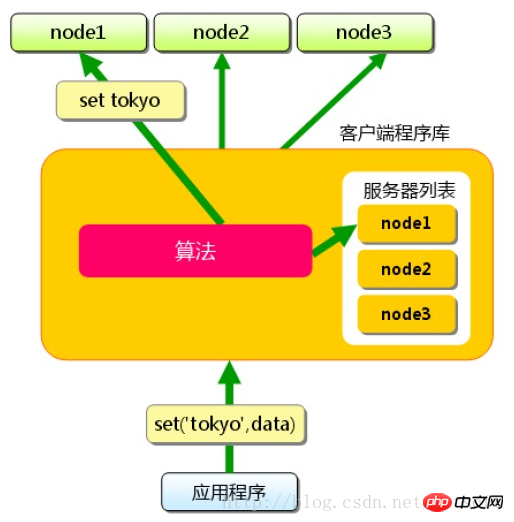
Algorithme de routage simple, utilisant le resteHash : Utiliser la valeur de hachage du clé de données mise en cache, divisée par le nombre de serveurs, le reste est le numéro de la liste des serveurs dans le tableau ci-dessous. Cet algorithme peut répartir uniformément les données du cache dans tout le cluster memcached et peut également répondre à la plupart des exigences de routage du cache.
Cependant, lorsque le cluster Memcached doit être étendu, des problèmes surviendront. Par exemple : le site Web doit étendre la capacité de 3 serveurs de cache à 4 serveurs de cache. Après avoir modifié la liste des serveurs, si vous utilisez toujours le hachage restant, il est facile de calculer que 75 % des requêtes n'atteindront pas le cache. À mesure que la taille du cluster de serveurs augmente, le taux d'échec augmente.
1%3 = 1 1%4 = 1 2%3 = 2 2%4 = 2 3%3 = 0 3%4 = 3 4%4 = 1 4%4 = 0 #以此类推
Une telle opération d'expansion est extrêmement risquée et peut exercer une pression instantanée importante sur la base de données et peut même provoquer un crash de la base de données. Il existe deux manières de résoudre ce problème : 1. Augmentez la capacité lorsque l'accès est faible et réchauffez les données après l'expansion. 2. Utilisez un meilleur algorithme de routage ; L’algorithme le plus couramment utilisé à l’heure actuelle est l’algorithme de hachage cohérent.
Le client memcached peut utiliser l'algorithme de hachage cohérent comme stratégie de routage, comme le montre la figure. Par rapport à l'algorithme de hachage général (tel que modulo simple), le hachage cohérent. algorithme sauf En plus de calculer la valeur de hachage de la clé, la valeur de hachage correspondant à chaque serveur est également calculée, puis ces valeurs de hachage sont mappées sur une plage de valeurs limitée (telle que 0~2^32). En trouvant le plus petit serveur avec une valeur de hachage supérieure à hash(key), il est utilisé comme serveur cible pour stocker les données clés. S'il est introuvable, le serveur avec la plus petite valeur de hachage est directement utilisé comme serveur cible. Dans le même temps, dans une certaine mesure, le problème d'expansion est résolu. L'ajout ou la suppression d'un seul nœud n'aura pas un grand impact sur l'ensemble du cluster. 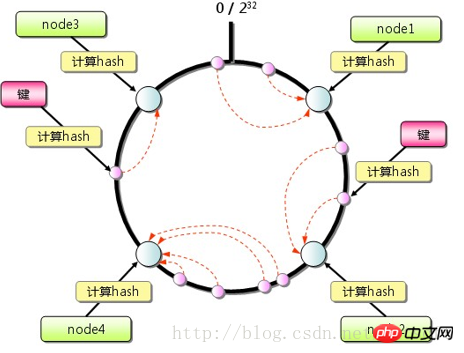 Couche virtuelle
Couche virtuelle
为了提高性能,memcached中保存的数据都存储在memcached内置的内存存储空间中。由于数据仅存在于内存中,因此重启memcached、重启操作系统会导致全部数据消失。另外,缓存的内容容量达到指定值之后,就基于LRU(Least Recently Used)算法自动删除不使用的缓存。memcached本身是为缓存而设计的服务,因此并没有过多考虑数据的永久性问题。
memcached仅支持基础的key-value键值对类型数据存储。在memcached内存结构中有两个非常重要的概念:slab和chunk。
slab是一个内存块,它是memcached一次申请内存的最小单位。在启动memcached的时候一般会使用参数-m指定其可用内存,但是并不是在启动的那一刻所有的内存就全部分配出去了,只有在需要的时候才会去申请,而且每次申请一定是一个slab。Slab的大小固定为1M(1048576 Byte),一个slab由若干个大小相等的chunk组成。每个chunk中都保存了一个item结构体、一对key和value。
虽然在同一个slab中chunk的大小相等的,但是在不同的slab中chunk的大小并不一定相等,在memcached中按照chunk的大小不同,可以把slab分为很多种类(class),默认情况下memcached把slab分为40类(class1~class40),在class 1中,chunk的大小为80字节,由于一个slab的大小是固定的1048576字节(1M),因此在class1中最多可以有13107个chunk(也就是这个slab能存最多13107个小于80字节的key-value数据)。 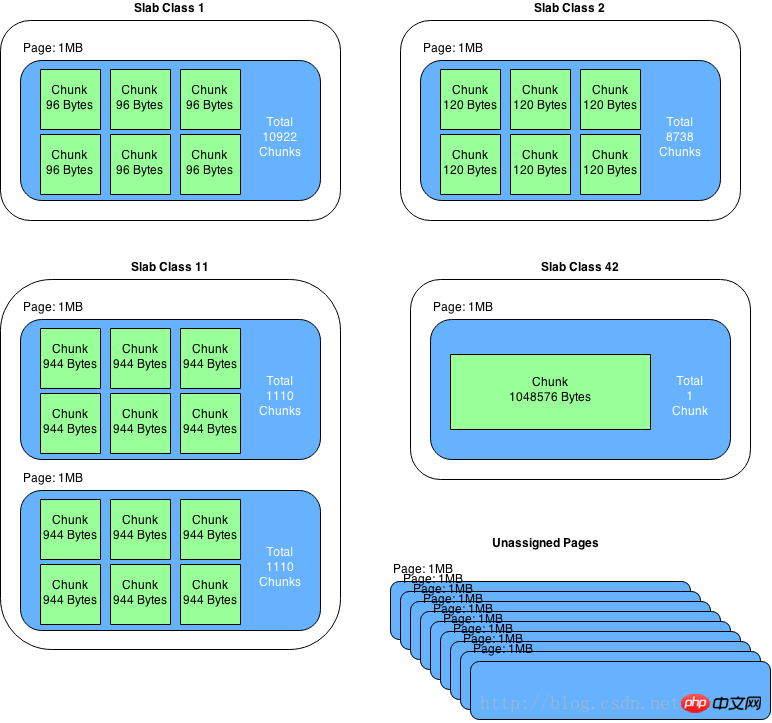
memcached内存管理采取预分配、分组管理的方式,分组管理就是我们上面提到的slab class,按照chunk的大小slab被分为很多种类。内存预分配过程是怎样的呢?向memcached添加一个item时候,memcached首先会根据item的大小,来选择最合适的slab class:例如item的大小为190字节,默认情况下class 4的chunk大小为160字节显然不合适,class 5的chunk大小为200字节,大于190字节,因此该item将放在class 5中(显然这里会有10字节的浪费是不可避免的),计算好所要放入的chunk之后,memcached会去检查该类大小的chunk还有没有空闲的,如果没有,将会申请1M(1个slab)的空间并划分为该种类chunk。例如我们第一次向memcached中放入一个190字节的item时,memcached会产生一个slab class 2(也叫一个page),并会用去一个chunk,剩余5241个chunk供下次有适合大小item时使用,当我们用完这所有的5242个chunk之后,下次再有一个在160~200字节之间的item添加进来时,memcached会再次产生一个class 5的slab(这样就存在了2个pages)。
chunk是在page里面划分的,而page固定为1m,所以chunk最大不能超过1m。
chunk实际占用内存要加48B,因为chunk数据结构本身需要占用48B。
如果用户数据大于1m,则memcached会将其切割,放到多个chunk内。
已分配出去的page不能回收。
-对于key-value信息,最好不要超过1m的大小;同时信息长度最好相对是比较均衡稳定的,这样能够保障最大限度的使用内存;同时,memcached采用的LRU清理策略,合理甚至过期时间,提高命中率。
key-value能满足需求的前提下,使用memcached分布式集群是较好的选择,搭建与操作使用都比较简单;分布式集群在单点故障时,只影响小部分数据异常,目前还可以通过Magent缓存代理模式,做单点备份,提升高可用;整个缓存都是基于内存的,因此响应时间是很快,不需要额外的序列化、反序列化的程序,但同时由于基于内存,数据没有持久化,集群故障重启数据无法恢复。高版本的memcached已经支持CAS模式的原子操作,可以低成本的解决并发控制问题。
$ sudo apt-get install memcached $ memcached -m 32 -p 11211 -d # memcached将会以守护程序的形式启动 memcached(-d),为其分配32M内存(-m 32),并指定监听 localhost的11211端口。
在python中可通过memcache库来操作memcached,这个库使用很简单,声明一个client就可以读写memcached缓存了。
#!/usr/bin/env pythonimport memcache
mc = memcache.Client(['127.0.0.1:12000'],debug=0)
mc.set("some_key", "Some value")
value = mc.get("some_key")
mc.set("another_key", 3)
mc.delete("another_key")
mc.set("key", "1") # note that the key used for incr/decr must be a string.
mc.incr("key")
mc.decr("key")然而,python-memcached默认的路由策略没有使用一致性哈希。
def _get_server(self, key):
if isinstance(key, tuple):
serverhash, key = key
else:
serverhash = serverHashFunction(key)
if not self.buckets:
return None, None
for i in range(Client._SERVER_RETRIES):
server = self.buckets[serverhash % len(self.buckets)]
if server.connect():
# print("(using server %s)" % server,)
return server, key
serverhash = serverHashFunction(str(serverhash) + str(i))
return None, None从源码中可以看到:server = self.buckets[serverhash % len(self.buckets)],只是根据key进行了简单的取模。我们可以通过重写_get_server方法,让python-memcached支持一致性哈希。
import memcacheimport typesfrom hash_ring import HashRingclass MemcacheRing(memcache.Client):
"""Extends python-memcache so it uses consistent hashing to
distribute the keys.
"""
def init(self, servers, *k, **kw):
self.hash_ring = HashRing(servers)
memcache.Client.init(self, servers, *k, **kw)
self.server_mapping = {}
for server_uri, server_obj in zip(servers, self.servers):
self.server_mapping[server_uri] = server_obj
def _get_server(self, key):
if type(key) == types.TupleType:
return memcache.Client._get_server(key)
for i in range(self._SERVER_RETRIES):
iterator = self.hash_ring.iterate_nodes(key)
for server_uri in iterator:
server_obj = self.server_mapping[server_uri]
if server_obj.connect():
return server_obj, key
return None, None这里采用的策略是:1. 应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。2. 应用程序从cache中取数据,取到后返回。缓存更新是一个很复杂的问题,一般是先把数据存到数据库中,成功后,再让缓存失效。后面会再写文单独讨论memcached缓存更新的问题。
# coding: utf-8import sysimport tornado.ioloopimport tornado.webimport loggingimport memcacheimport jsonimport urllib# 初始化memcache clientmc = memcache.Client(['127.0.0.1:11211'], debug=0)
mc_prefix = 'demo'class BaseHandler(tornado.web.RequestHandler):
""" 把缓存处理抽象到BaseHandler基类 """
USE_CACHE = False # 控制是否使用缓存
def format_args(self):
arg_list = []
for a in self.request.arguments:
for value in self.request.arguments[a]:
arg_list.append('%s=%s' % (a, urllib.quote(value.replace(' ', ''))))
# 根据请求的URL产生key
arg_list.sort()
key = '%s?%s' % (self.request.path, '&'.join(arg_list)) if arg_list else self.request.path
key = '%s_%s' % (mc_prefix, key)
# key太长,不进行缓存处理
if len(key) > 250:
logging.error('key out of length: %s', key)
return None
return key def get(self, *args, **kwargs):
if self.USE_CACHE:
try:
# 根据请求获取key
self.key = self.format_args()
if self.key:
data = mc.get(self.key)
# 若缓存命中,则直接返回数据
if data:
logging.info('get data from memecahce')
self.finish(data)
return
except Exception, e:
logging.exception(e)
# 若未命中缓存,调用do_get处理请求,获取数据
data = self.do_get()
data_str = json.dumps(data)
# 把成功获取到的数据,放入memcache缓存
if self.USE_CACHE and data and data.get('result', -1) == 0 and self.key:
try:
mc.set(self.key, data_str, 60)
except Exception, e:
logging.exception(e)
self.finish(data_str) def do_get(self):
return Noneclass DemoHandler(BaseHandler):
USE_CACHE = True
def do_get(self):
a = self.get_argument('a', 'test')
b = self.get_argument('b', 'test')
# 访问数据库获取数据,此处略去
data = {'result': 0, 'a': a, 'b': b} return datadef make_app():
return tornado.web.Application([
(r"/", DemoHandler),
])if name == "main":
logging.basicConfig(stream=sys.stdout, level=logging.INFO,
format='%(asctime)s %(levelno)s %(message)s',
)
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()在浏览器访问http://127.0.0.1:8888/?a=1&b=3,终端打印的log如下:
2017-02-21 22:45:05,987 20 304 GET /?a=1&b=2 (127.0.0.1) 3.11ms 2017-02-21 22:45:07,427 20 get data from memecahce 2017-02-21 22:45:07,427 20 304 GET /?a=1&b=2 (127.0.0.1) 0.71ms 2017-02-21 22:45:10,350 20 200 GET /?a=1&b=3 (127.0.0.1) 0.82ms 2017-02-21 22:45:13,586 20 get data from memecahce
从日志可以看到,缓存命中的情况。
本文介绍了memcached的路由算法、内存管理、使用场景等基本概念,然后举例说明了在python项目中如何使用memcached缓存。缓存更新的问题还需要进一步分析讨论。
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



