


Les mini-programmes WeChat ont été très populaires récemment. J'ai également téléchargé les outils de développement Web WeChat avec l'intention de les essayer. Les outils de développement sont relativement simples, ont relativement peu de fonctions et n'ont pas de paramètres personnalisés. Après avoir découvert les outils de développement, j'ai jeté un œil aux documents de développement officiels du mini-programme et j'ai à peu près compris le processus de développement du mini-programme et certaines API couramment utilisées.
Après avoir découvert les mini-programmes, j'ai eu envie de faire une petite démo. Même si je n'ai pas fait beaucoup de pratique avec les mini-programmes et que je me suis contenté de parcourir les exemples officiels, je veux quand même faire quelque chose. petites choses. Puisque je veux faire une démo, j'ai naturellement besoin de données, je les ai moi-même mais je ne veux pas construire un serveur par moi-même, j'ai donc recherché en ligne des API gratuites pouvant être utilisées pour fournir des données de test, et finalement j'ai choisi Douban. Livres. Douban Books fournit relativement peu de fonctions API et n'autorise pas les applications appkey, les données utilisateur ne peuvent donc pas être manipulées. Il ne peut effectuer que quelques requêtes simples sur le livre et afficher des informations détaillées sur le livre. Cette démo ne comporte que deux pages, ce qui est très simple.
Il n'y a que deux API Douban Books utilisées dans la démo, l'une pour la recherche de livres et l'autre pour obtenir les détails du livre.
| 参数 | 意义 | 备注 |
|---|---|---|
| q | 查询关键字 | q和tag必传其一 |
| tag | 查询的tag | q和tag必传其一 |
| start | 取结果的offset | 默认为0 |
| count | 取结果的条数 | 默认为20,最大为100 |
Statut de retour = 200
{
"start": 0,
"count": 10,
"total": 30,
"books" : [Book, ...]
}GET //m.sbmmt.com/:id
| 参数 | 意义 |
|---|---|
| :id | 图书id |
以下是具体图书的详情信息,部分demo中用不到的信息省略
{
"id":"1003078",
"title":"小王子",
"alt":"https:\/\/book.douban.com\/subject\/1003078\/",
"image":"https://img3.doubanio.com\/mpic\/s1001902.jpg",
"author":[
"(法)圣埃克苏佩里"
],
"publisher":"中国友谊出版公司",
"pubdate":"2000-9-1",
"rating":{"max":10,"numRaters":9438,"average":"9.1","min":0},
"author_intro":"圣埃克苏佩里(1900-1944)1900年,玛雅·戴斯特莱姆......",
"catalog":"序言:法兰西玫瑰\n小王子\n圣埃克苏佩里年表\n"
}项目取名为DouBanBookApp,项目的结构小程序默认的结构一样
DouBanBookApp pages index 首页 index.js index.wxml index.wxss detail 详情页 detail.js detail.wxml detail.wxss requests api.js API地址 request.js 网络请求 utils util.js 工具 app.js app.json app.wxss
应用的主调色参考了豆瓣app的色调,采用了偏绿色。
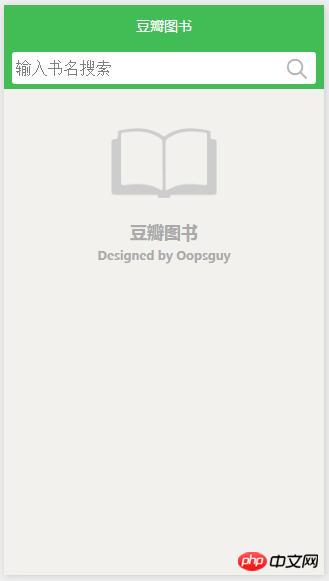
首页顶部展示搜索输入框,用户输入图书名称,点击搜索按钮,展示图书列表。图书可能会很多,不能一下子全部展示,需要用到分页,app上最常见的列表分页就是上拉加载模式,根据小程序提供的组件中,找到了一个比较符合场景的scroll-view组件,这个组件有一个上拉到底部自动触发的bindscrolltolower事件。
先制作出界面的静态效果,之后再整合API,由于本人对界面设计不敏感,所以随便弄了一个粗糙的布局,看得过去就行了,嘿嘿~~
index.wxml
<view class="search-container">
<input type="text" placeholder="输入书名搜索"></input><icon type="search" size="20"/></view><scroll-view scroll-y="true" style="width:100%;position:relative;top:40px;height:200px">
<view style="text-align:center;padding-top:50rpx;">
<icon type="cancel" color="red" size="40" />
<view><text>没有找到相关图书</text></view>
</view>
<view style="text-align:center;padding-top:50rpx;">
<icon type="search" size="60" />
<view><text>豆瓣图书</text></view>
</view>
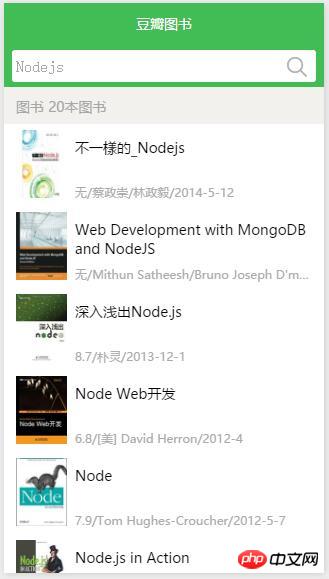
<view class="header">
<text>图书 10本图书</text>
</view>
<view class="common-list">
<view class="list-item">
<view class="index-list-item">
<view class="cover">
<image class="cover-img" src="images/demo.png"></image>
</view>
<view class="content">
<view class="title">图书标图</view>
<text class="desc">9.0/oopsguy/2016-07-08</text>
</view>
</view>
</view>
</view>
<view class="refresh-footer">
<icon type="waiting" size="30" color="reed" />
</view></scroll-view>index.wxss
page {
background: #F2F1EE;}/*seach*/.search-container {
position: fixed;
top: 0;
right: 0;
left: 0;
background-color: #42BD56;
color: #FFF;
height: 40px;
padding: 0 10rpx;
z-index: 100;}.search-container input {
background: #FFF;
color: #AAA;
margin-top: 5px;
padding: 5px 10rpx;
height: 20px;
border-radius: 8rpx;}.search-container icon {
position: absolute;
top: 10px;
right: 20rpx;}/*header*/.header {
padding: 20rpx 30rpx;}.header text {
color: #A6A6A6;}/*common list*/.list-item {
position: relative;
overflow: hidden}/*index list*/.index-list-item {
background: #FFF;
padding: 15rpx 30rpx;
overflow: hidden;}.index-list-item::active {
background: #EEE;}.index-list-item .cover {
float: left;
width: 120rpx;
height: 160rpx;
overflow: hidden}.index-list-item .cover image.cover-img {
width: 120rpx;
height: 160rpx;}.index-list-item .content {
margin-left: 140rpx;}.index-list-item .title {
display: inline-block;
height: 90rpx;
padding-top: 20rpx;
overflow: hidden;}.index-list-item .desc {
display: block;
font-size: 30rpx;
padding-top: 10rpx;
color: #AAA;
white-space:nowrap;
overflow: hidden;
text-overflow: ellipsis;}.refresh-footer {
text-align: center;
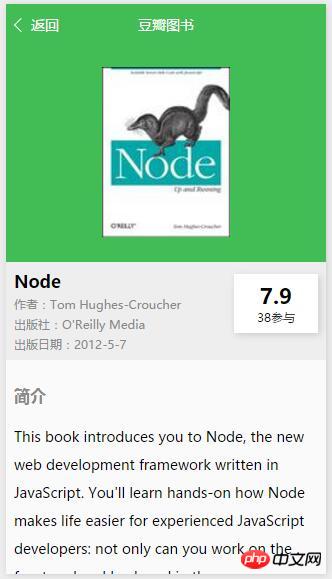
padding: 10rpx 0;}图书详细页面就是展示具体的图书信息,通用首页穿过了的图书id来获取图书信息之后在展示出来,获取的过程中可能有延迟,需要一个加载效果来过渡。
detail.wxml
<view>
<view class="cover-container">
<image src="images/demo.png"></image>
</view>
<view class="book-meta">
<view class="meta-info">
<text class="book-title">图书标题</text>
<text class="other-meta">作者:作者名称</text>
<text class="other-meta">出版社:xxx出版社</text>
<text class="other-meta">出版日期:2010-05-07</text>
</view>
<view class="range">
<text class="score">0</text>
<text class="viewers">0</text>
</view>
</view>
<view class="book-intro">
<view class="intro-header"><text>简介</text></view>
<text class="intro-content">
这是图书简介 </text>
</view>
<view class="book-intro">
<view class="intro-header"><text>作者</text></view>
<text class="intro-content">
这是作者简介 </text>
</view></view><loading>
加载中...</loading>detail.wxss
page {
background: #EEE;}.cover-container {
background: #42BD56;
text-align: center;
padding: 50rpx 0;}.cover-container image {
display: inline-block;
width: 300rpx;
height: 400rpx;}.book-meta {
position: relative;
padding: 20rpx;
overflow: hidden;}.book-meta .range {
position: absolute;
top: 30rpx;
right: 20rpx;
width: 180rpx;
background: #FFF;
padding: 20rpx 10rpx;
text-align: center;
box-shadow: 2px 2px 10px #CCC;}.book-meta .meta-info {
margin-right: 200rpx;}.meta-info text {
display: block}.book-title {
font-weight: bold;
font-size: 50rpx;}.other-meta {
padding-top: 10rpx;
color: #888;
font-size: 30rpx;}.range text {
display: block;}.range .score {
font-size: 50rpx;
font-weight: bold;}.range .starts {
font-size: 40rpx;}.range .viewers {
font-size: 30rpx;}.book-intro {
padding: 20rpx;
font-size: 40rpx;}.book-intro .intro-header {
color: #888}.book-intro .intro-content {
font-size: 35rpx;
line-height: 45rpx;}做好了首页和详细页的静态页面,接下来就是通过网络请求api来获取数据,并显示到页面上来。
为了更好的管理api,我把api专门放到了一个单独的api.js文件中
api.js
const API_BASE = "https://api.douban.com/v2/book";module.exports = {
API_BOOK_SEARCH: API_BASE + "/search",
API_BOOK_DETAIL: API_BASE + "/:id"}有些经常用到的工具函数放到了util.js中
util.js
function isFunction( obj ) {
return typeof obj === 'function';
}
module.exports = {
isFunction: isFunction
}微信小程序提供了一个用于网络请求的api:wx.request(OBJECT),具体的参数跟jquery的ajax方法差不多,为了方便调用,我把网络请求放到了request.js中
request.js
var api = require('./api.js');var utils = require('../utils/util.js');/** * 网路请求 */function request(url, data, successCb, errorCb, completeCb) {
wx.request({
url: url,
method: 'GET',
data: data,
success: function(res) {
utils.isFunction(successCb) && successCb(res.data);
},
error: function() {
utils.isFunction(errorCb) && errorCb();
},
complete: function() {
utils.isFunction(completeCb) && completeCb();
}
});}/** * 搜索图书 */function requestSearchBook(data, successCb, errorCb, completeCb) {
request(api.API_BOOK_SEARCH, data, successCb, errorCb, completeCb);}/** * 获取图书详细信息 */function requestBookDokDetail(id, data, successCb, errorCb, completeCb) {
request(api.API_BOOK_DETAIL.replace(':id', id), data, successCb, errorCb, completeCb);}module.exports = {
requestSearchBook: requestSearchBook,
requestBookDokDetail: requestBookDokDetail}首页有图书搜索和列表展示,上拉加载的效果。微信小程序中没有了DOM操作的概念,一切的界面元素的改变都要通过数据变化来改变,所以需要在js中的Page中的data中声明很多数据成员。
用户在输入数据时,输入框的input绑定了searchInputEvent事件,就回捕获到输入的数据,把输入的数据更新的data中的searchKey中。
searchInputEvent: function( e ) {
this.setData( { searchKey: e.detail.value });}当点击搜索按钮是,触发tap事件,其绑定了searchClickEvent
searchClickEvent: function( e ) {
if( !this.data.searchKey ) return;
this.setData( { pageIndex: 0, pageData: [] });
requestData.call( this );}requestData中封装了请求图书列表的方法
/** * 请求图书信息 */function requestData() {
var _this = this;
var q = this.data.searchKey;
var start = this.data.pageIndex;
this.setData( { loadingMore: true, isInit: false });
updateRefreshBall.call( this );
requests.requestSearchBook( { q: q, start: start }, ( data ) => {
if( data.total == 0 ) {
//没有记录
_this.setData( { totalRecord: 0 });
} else {
_this.setData( {
pageData: _this.data.pageData.concat( data.books ),
pageIndex: start + 1,
totalRecord: data.total
});
}
}, () => {
_this.setData( { totalRecord: 0 });
}, () => {
_this.setData( { loadingMore: false });
});}上拉加载的效果是一个小球不停的变换颜色,需要一个颜色列表
//刷新动态球颜色var iconColor = [ '#353535', '#888888'];
然后用一个定时器来动态改变小球图标的颜色
/** * 刷新上拉加载效果变色球 */function updateRefreshBall() {
var cIndex = 0;
var _this = this;
var timer = setInterval( function() {
if( !_this.data[ 'loadingMore' ] ) {
clearInterval( timer );
}
if( cIndex >= iconColor.length )
cIndex = 0;
_this.setData( { footerIconColor: iconColor[ cIndex++ ] });
}, 100 );}详细页面的显示需要到首页点击了具体图书的id,所以需要首页传值过来,这里用到了小程序土工的wx.navigateTo方法,给其指定的url参数后面带以查询字符串格式形式的参数,被跳转的页面就会在onLoad方法中得到值。
//跳转到详细页面toDetailPage: function( e ) {
var bid = e.currentTarget.dataset.bid; //图书id [data-bid]
wx.navigateTo( {
url: '../detail/detail?id=' + bid });}detail.js中接受参数
onLoad: function( option ) {
this.setData({
id: option.id
});}其实小程序的页面制作跟平时的html和css差不多,只是页面中不能用传统的html标签,而是改用了小程序提供的自定义标签,小程序对css的支持也有限制,注意哪些写法不兼容也差不多懂了。操作页面变化是通过数据变化来表现出来的,这点有点像react和vue。以上的demo用到的知识点并不多,主要是页面的数据绑定、事件绑定、模版知识和网络请求等相关api。仔细看看文档也差不多可以做出一个小例子。
qi
总体来说,Demo很简单,只有两个页面,界面也是丑丑的T_T,算是我入门小程序的第一课吧。
更多微信小程序可开发实例请关注php中文网!
 comment cacher l'adresse IP
comment cacher l'adresse IP
 La différence entre les fonctions fléchées et les fonctions ordinaires
La différence entre les fonctions fléchées et les fonctions ordinaires
 Comment activer la même fonction de ville sur Douyin
Comment activer la même fonction de ville sur Douyin
 Comment ouvrir l'autorisation de téléchargement de Douyin
Comment ouvrir l'autorisation de téléchargement de Douyin
 Comment supprimer des pages vierges dans Word
Comment supprimer des pages vierges dans Word
 Comment diffuser l'écran d'un téléphone mobile Huawei sur un téléviseur
Comment diffuser l'écran d'un téléphone mobile Huawei sur un téléviseur
 Comment résoudre le statut http 404
Comment résoudre le statut http 404
 Comment se connecter à la base de données en utilisant VB
Comment se connecter à la base de données en utilisant VB








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



