


La création du pool de threads a été analysée dans l'article précédent. Il est entendu que le pool de threads possède à la fois des modèles prédéfinis et une variété de paramètres pour prendre en charge une personnalisation flexible.
Cet article se concentrera sur le cycle de vie du pool de threads et analysera le processus d'exécution des tâches par le pool de threads.
Comprenez d'abord les deux paramètres dans le code du pool de threads :
runState : état d'exécution du pool de threads
WorkerCount : Le nombre de threads de travail
Le pool de threads utilise un entier de 32 bits pour enregistrer runState et WorkerCount en même temps, dont les 3 bits de poids fort sont runState et les 29 bits restants sont WorkerCount. RunStateOf et WorkerCountOf sont utilisés à plusieurs reprises dans le code pour obtenir runState et WorkerCount.
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3; private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// 线程池状态 private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS;
// ctl操作
private static int runStateOf(int c) { return c & ~CAPACITY; }
private static int workerCountOf(int c) { return c & CAPACITY; }
private static int ctlOf(int rs, int wc) { return rs | wc; }RUNNING : peut recevoir de nouvelles tâches, peut exécuter des tâches dans la file d'attente
SHUTDOWN : ne peut pas recevoir de nouvelles tâches, peut être exécuté En attente des tâches dans la file d'attente
STOP : les nouvelles tâches ne peuvent pas être reçues, les tâches dans la file d'attente ne peuvent pas être exécutées et des tentatives sont faites pour terminer toutes les tâches en cours
TIDYING : Toutes les tâches ont été terminé, exécutez terminated()
TERMINATED : l'exécution de terminated() est terminée
Le statut du pool de threads commence par RUNNING par défaut et se termine par le statut TERMINATED. chaque statut au milieu, mais le statut ne peut pas être annulé. Voici les chemins possibles et les conditions de changement pour les changements d'état : 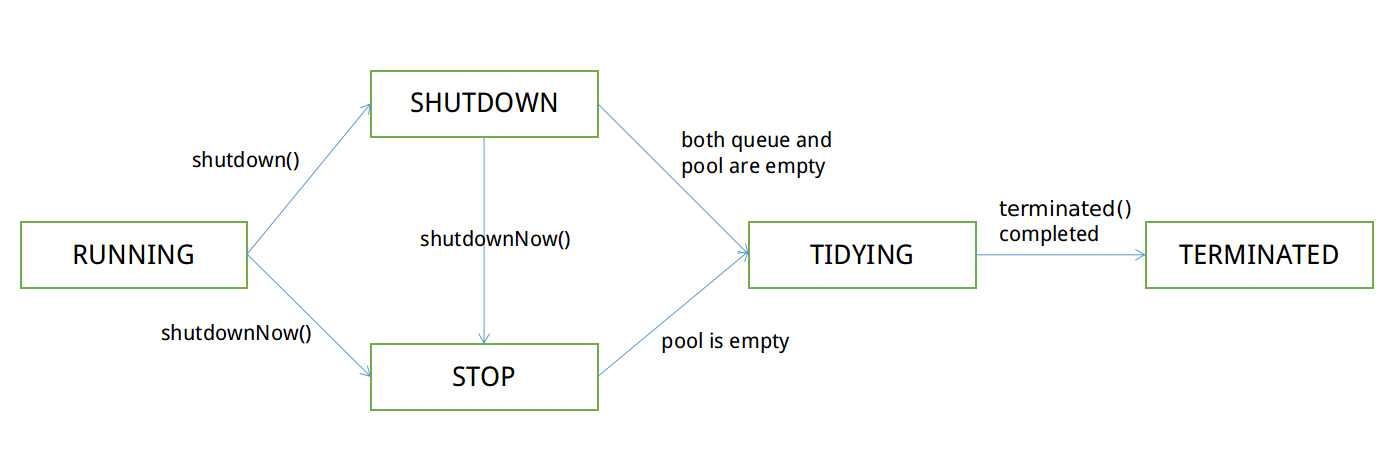
Figure 1 Chemin de changement d'état du pool de threads
Le pool de threads est responsable de l'exécution des tâches par la classe Worker hérite de AbstractQueuedSynchronizer, qui mène à AQS, le cœur du framework de concurrence Java.
AbstractQueuedSynchronizer,简称AQS,是Java并发包里一系列同步工具的基础实现,原理是根据状态位来控制线程的入队阻塞、出队唤醒来处理同步。
AQS n'en discutera pas ici. Vous devez seulement savoir que Worker encapsule Thread et lui permet d'effectuer des tâches.
L'appel d'execution créera un Worker en fonction de la situation du pool de threads. Les quatre situations suivantes peuvent être résumées : 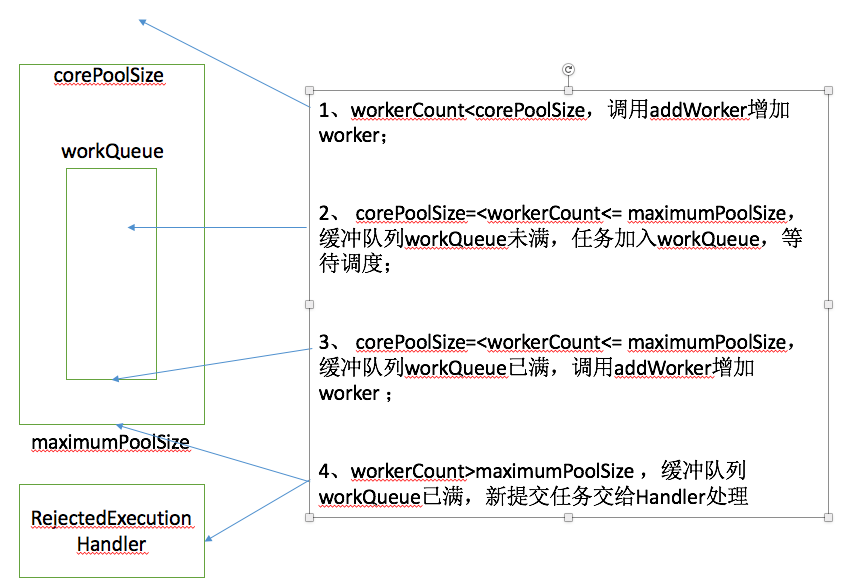
Figure 2 Worker dans le thread. pool Quatre possibilités
public void execute(Runnable command) {
if (command == null)
throw new NullPointerException();
int c = ctl.get();
//1
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
//2
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
//3
reject(command);
else if (workerCountOf(recheck) == 0)
//4
addWorker(null, false);
}
//5
else if (!addWorker(command, false))
//6
reject(command);
} la marque 1 correspond à la première situation. Veuillez noter que addWorker passe dans core, core=true est corePoolSize, core=false est maximumPoolSize, et vous devez vérifier si workerCount. est ajouté lors de l'ajout. Dépasse la valeur maximale autorisée.
Mark 2 correspond à la deuxième situation, vérifier si le pool de threads est en cours d'exécution et ajouter la tâche à la file d'attente. Mark 3 vérifie à nouveau l'état du pool de threads. Si le pool de threads est soudainement dans un état non en cours d'exécution, supprimez la tâche qui vient d'être ajoutée à la file d'attente et remettez-la au RejectedExecutionHandler pour traitement. Mark 4 constate qu'il n'y a pas de travailleur, il ajoute donc d'abord un travailleur avec une tâche vide.
La marque 5 correspond à la troisième situation. Aucune autre tâche ne peut être ajoutée à la file d'attente. Appelez addWorker pour en ajouter une pour le traitement.
Mark 6 correspond à la quatrième situation. Le noyau de addWorker est passé en false et l'appel de retour échoue, ce qui signifie que le workerCount a dépassé le maximumPoolSize, il est donc transmis à RejectedExecutionHandler pour traitement.
private boolean addWorker(Runnable firstTask, boolean core) {
//1
retry:
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
int wc = workerCountOf(c);
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
if (compareAndIncrementWorkerCount(c))
break retry;
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
//2
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);
final Thread t = w.thread;
if (t != null) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}Le premier morceau de code marqué 1 a un objectif simple, qui est d'en ajouter un à workerCount. Quant à la raison pour laquelle l'écriture du code a pris autant de temps, c'est parce que l'état du pool de threads change constamment et que la synchronisation des variables doit être assurée dans un environnement concurrent. La boucle externe détermine l'état du pool de threads, la tâche n'est pas vide et la file d'attente n'est pas vide. La boucle interne utilise le mécanisme CAS pour garantir que workerCount est incrémenté correctement. Si vous ne comprenez pas CAS, vous pouvez en apprendre davantage sur le mécanisme de synchronisation non bloquant que CAS sera utilisé pour les augmentations ou diminutions ultérieures de workerCount.
Le deuxième morceau de code marqué 2 est relativement simple. Créez un nouvel objet Worker et ajoutez le Worker aux Workers (collection Set). Après un ajout réussi, démarrez le thread dans le travailleur. Enfin, il est déterminé si le thread a démarré avec succès. S'il échoue, addWorkerFailed est appelé directement.
private void addWorkerFailed(Worker w) {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (w != null)
workers.remove(w);
decrementWorkerCount();
tryTerminate();
} finally {
mainLock.unlock();
}
}addWorkerFailed réduira le workerCount déjà incrémenté et appellera tryTerminate pour mettre fin au pool de threads.
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
public void run() {
runWorker(this);
}Worker utilise ThreadFactory pour créer Thread dans le constructeur et appelle runWorker dans la méthode run, qui semble être l'endroit où le la tâche est effectivement exécutée.
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//1
while (task != null || (task = getTask()) != null) {
w.lock();
//2
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//3
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
afterExecute(task, thrown);
}
} finally {
task = null;
//4
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false; //5
} finally {
//6
processWorkerExit(w, completedAbruptly);
}
} Mark 1 entre dans la boucle et obtient la tâche à exécuter à partir de getTask jusqu'à ce que null soit renvoyé. L'effet de réutilisation des threads est obtenu ici, permettant aux threads de gérer plusieurs tâches.
Mark 2 est un jugement relativement complexe, qui garantit que le pool de threads est interrompu dans l'état STOP et n'est pas interrompu dans l'état non-STOP. Si vous ne comprenez pas le mécanisme d'interruption de Java, lisez cet article pour savoir comment terminer correctement un thread Java.
Mark 3 appelle la méthode run et exécute réellement la tâche. Deux méthodes, beforeExecute et afterExecute, sont fournies avant et après l'exécution, qui sont implémentées par des sous-classes.
Les tâches terminées dans la marque 4 comptent le nombre de tâches que le travailleur a exécutées et sont finalement accumulées dans la variable complétéeTaskCount. Vous pouvez appeler la méthode correspondante pour renvoyer des informations statistiques.
La variablecompleteAbruptly marquée 5 indique si le travailleur s'est terminé anormalement. Ici, l'exécution signifie que les méthodes suivantes nécessitent cette variable.
Mark 6 appelle processWorkerExit pour terminer, qui sera analysé plus tard.
Ensuite, regardons la méthode getTask du travailleur récupérant la tâche de la file d'attente :
private Runnable getTask() {
boolean timedOut = false; // Did the last poll() time out?
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);
//1
// Check if queue empty only if necessary.
if (rs >= SHUTDOWN && (rs >= STOP || workQueue.isEmpty())) {
decrementWorkerCount();
return null;
}
int wc = workerCountOf(c);
//2
// Are workers subject to culling?
boolean timed = allowCoreThreadTimeOut || wc > corePoolSize;
if ((wc > maximumPoolSize || (timed && timedOut))
&& (wc > 1 || workQueue.isEmpty())) {
if (compareAndDecrementWorkerCount(c))
return null;
continue;
}
//3
try {
Runnable r = timed ?
workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS) :
workQueue.take();
if (r != null)
return r;
timedOut = true;
} catch (InterruptedException retry) {
timedOut = false;
}
}
}标记1检查线程池的状态,这里就体现出SHUTDOWN和STOP的区别。如果线程池是SHUTDOWN状态,还会先处理完等待队列的任务;如果是STOP状态,就不再处理等待队列里的任务了。
标记2先看allowCoreThreadTimeOut这个变量,false时worker空闲,也不会结束;true时,如果worker空闲超过keepAliveTime,就会结束。接着是一个很复杂的判断,好难转成文字描述,自己看吧。注意一下wc>maximumPoolSize,出现这种可能是在运行中调用setMaximumPoolSize,还有wc>1,在等待队列非空时,至少保留一个worker。
标记3是从等待队列取任务的逻辑,根据timed分为等待keepAliveTime或者阻塞直到有任务。
最后来看结束worker需要执行的操作:
private void processWorkerExit(Worker w, boolean completedAbruptly) {
//1
if (completedAbruptly) // If abrupt, then workerCount wasn't adjusted
decrementWorkerCount();
//2
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
completedTaskCount += w.completedTasks;
workers.remove(w);
} finally {
mainLock.unlock();
}
//3
tryTerminate();
int c = ctl.get();
//4
if (runStateLessThan(c, STOP)) {
if (!completedAbruptly) {
int min = allowCoreThreadTimeOut ? 0 : corePoolSize;
if (min == 0 && ! workQueue.isEmpty())
min = 1;
if (workerCountOf(c) >= min)
return; // replacement not needed
}
addWorker(null, false);
}
}正常情况下,在getTask里就会将workerCount减一。标记1处用变量completedAbruptly判断worker是否异常退出,如果是,需要补充对workerCount的减一。
标记2将worker处理任务的数量累加到总数,并且在集合workers中去除。
标记3尝试终止线程池,后续会研究。
标记4处理线程池还是RUNNING或SHUTDOWN状态时,如果worker是异常结束,那么会直接addWorker。如果allowCoreThreadTimeOut=true,并且等待队列有任务,至少保留一个worker;如果allowCoreThreadTimeOut=false,workerCount不少于corePoolSize。
总结一下worker:线程池启动后,worker在池内创建,包装了提交的Runnable任务并执行,执行完就等待下一个任务,不再需要时就结束。
线程池的关闭不是一关了事,worker在池里处于不同状态,必须安排好worker的”后事”,才能真正释放线程池。ThreadPoolExecutor提供两种方法关闭线程池:
shutdown:不能再提交任务,已经提交的任务可继续运行;
shutdownNow:不能再提交任务,已经提交但未执行的任务不能运行,在运行的任务可继续运行,但会被中断,返回已经提交但未执行的任务。
public void shutdown() {
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess(); //1 安全策略机制
advanceRunState(SHUTDOWN); //2
interruptIdleWorkers(); //3
onShutdown(); //4 空方法,子类实现
} finally {
mainLock.unlock();
}
tryTerminate(); //5
}shutdown将线程池切换到SHUTDOWN状态,并调用interruptIdleWorkers请求中断所有空闲的worker,最后调用tryTerminate尝试结束线程池。
public List<Runnable> shutdownNow() {
List<Runnable> tasks;
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
checkShutdownAccess();
advanceRunState(STOP);
interruptWorkers();
tasks = drainQueue(); //1
} finally {
mainLock.unlock();
}
tryTerminate();
return tasks;
}shutdownNow和shutdown类似,将线程池切换为STOP状态,中断目标是所有worker。drainQueue会将等待队列里未执行的任务返回。
interruptIdleWorkers和interruptWorkers实现原理都是遍历workers集合,中断条件符合的worker。
上面的代码多次出现调用tryTerminate,这是一个尝试将线程池切换到TERMINATED状态的方法。
final void tryTerminate() {
for (;;) {
int c = ctl.get();
//1
if (isRunning(c) ||
runStateAtLeast(c, TIDYING) ||
(runStateOf(c) == SHUTDOWN && ! workQueue.isEmpty()))
return;
//2
if (workerCountOf(c) != 0) { // Eligible to terminate
interruptIdleWorkers(ONLY_ONE);
return;
}
//3
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
if (ctl.compareAndSet(c, ctlOf(TIDYING, 0))) {
try {
terminated();
} finally {
ctl.set(ctlOf(TERMINATED, 0));
termination.signalAll();
}
return;
}
} finally {
mainLock.unlock();
}
// else retry on failed CAS
}
}标记1检查线程池状态,下面几种情况,后续操作都没有必要,直接return。
RUNNING(还在运行,不能停)
TIDYING或TERMINATED(已经没有在运行的worker)
SHUTDOWN并且等待队列非空(执行完才能停)
标记2在worker非空的情况下又调用了interruptIdleWorkers,你可能疑惑在shutdown时已经调用过了,为什么又调用,而且每次只中断一个空闲worker?你需要知道,shutdown时worker可能在执行中,执行完阻塞在队列的take,不知道要结束,所有要补充调用interruptIdleWorkers。每次只中断一个是因为processWorkerExit时,还会执行tryTerminate,自动中断下一个空闲的worker。
标记3是最终的状态切换。线程池会先进入TIDYING状态,再进入TERMINATED状态,中间提供了terminated这个空方法供子类实现。
调用关闭线程池方法后,需要等待线程池切换到TERMINATED状态。awaitTermination检查限定时间内线程池是否进入TERMINATED状态,代码如下:
public boolean awaitTermination(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
for (;;) {
if (runStateAtLeast(ctl.get(), TERMINATED))
return true;
if (nanos <= 0)
return false;
nanos = termination.awaitNanos(nanos);
}
} finally {
mainLock.unlock();
}
} 以上就是Java 线程池执行原理分析 的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



