


Buffer est en fait un objet conteneur, qui contient des données à écrire ou simplement à lire. L'ajout de l'objet Buffer à NIO reflète une différence importante entre la nouvelle bibliothèque et les E/S d'origine. Dans les E/S orientées flux, vous écrivez ou lisez des données directement dans un objet Stream.
Dans la bibliothèque NIO, toutes les données sont gérées à l'aide de tampons. Lors de la lecture des données, elles sont lues directement dans le tampon. Lorsque les données sont écrites, elles sont écrites dans un tampon. Chaque fois que vous accédez à des données dans NIO, vous les placez dans un tampon.
Un tampon est essentiellement un tableau. Il s'agit généralement d'un tableau d'octets, mais d'autres types de tableaux peuvent être utilisés. Mais un tampon est bien plus qu’un simple tableau. Les tampons fournissent un accès structuré aux données et peuvent également suivre les processus de lecture/écriture du système.
Le type de tampon le plus couramment utilisé est ByteBuffer. Un ByteBuffer peut effectuer des opérations get/set (c'est-à-dire l'acquisition et le réglage d'octets) sur son tableau d'octets sous-jacent.
ByteBuffer n'est pas le seul type de tampon dans NIO. En fait, il existe un type de tampon pour chaque type Java de base (seul le type booléen n'a pas de classe tampon correspondante) :
ByteBuffer
CharBuffer
ShortBuffer
IntBuffer
LongBuffer
FloatBuffer
DoubleBuffer
Chaque classe Buffer est une instance de l'interface Buffer. À l'exception de ByteBuffer, chaque classe Buffer a exactement les mêmes opérations, mais les types de données qu'elles gèrent sont différents. Étant donné que la plupart des opérations d'E/S standard utilisent ByteBuffer, il contient toutes les opérations de tampon partagé ainsi que certaines opérations uniques. Jetons un coup d'œil au diagramme hiérarchique des classes de Buffer : 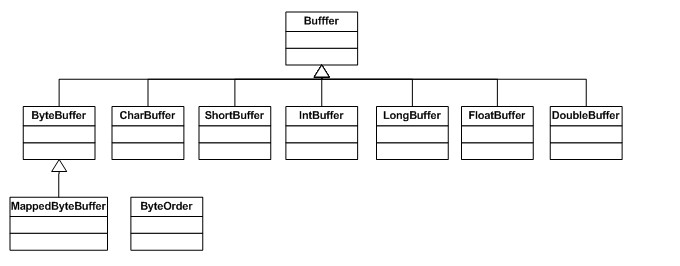
Chaque Buffer a les attributs suivants :
capacité
La quantité maximale de données que ce tampon peut contenir. La capacité est généralement spécifiée lors de la création du tampon.
limite
Les opérations de lecture et d'écriture effectuées sur le Buffer ne peuvent pas dépasser cet indice. Lors de l'écriture de données dans le tampon, la limite est généralement égale à la capacité. Lors de la lecture de données, la limite représente la longueur des données valides dans le tampon.
position
La variable de position suit la quantité de données écrites ou lues dans le tampon.
Plus précisément, lorsque vous lisez les données du canal dans le tampon, cela indique dans quel élément du tableau les données suivantes seront placées. Par exemple, si vous lisez trois octets du canal dans un tampon, la position du tampon sera définie sur 3, pointant vers le 4ème élément du tableau. À l’inverse, lorsque vous obtenez des données d’un tampon pour un canal d’écriture, cela indique de quel élément du tableau proviennent les données suivantes. Par exemple, lorsque vous écrivez 5 octets du tampon vers le canal, la position du tampon sera définie sur 5, pointant vers le sixième élément du tableau.
marque
Un index d'emplacement de stockage temporaire. L'appel de mark() définira mark sur la valeur de la position actuelle, et l'appel de reset() ultérieurement définira la propriété position sur la valeur de mark. La valeur de la marque est toujours inférieure ou égale à la valeur de la position. Si la valeur de la position est inférieure à la valeur de la marque, la valeur actuelle de la marque sera ignorée.
Ces propriétés satisfont toujours aux conditions suivantes :
0 <= mark <= position <= limit <= capacity
Le mécanisme interne de mise en œuvre du buffer :
Ci-dessous nous prendrons l'exemple de copie de données d'un canal d'entrée vers un canal de sortie pour analyser chaque variable en détail, et Expliquez comment ils fonctionnent ensemble :
Variables initiales :
Nous observons d'abord un tampon nouvellement créé, en prenant ByteBuffer comme exemple, en supposant que la taille du tampon est de 8 octets, ByteBuffer L'état initial est la suivante : 
Rappelons que la limite ne peut jamais être supérieure à la capacité, et les deux valeurs sont fixées à 8 dans cet exemple. Nous illustrons cela en les pointant après la fin du tableau (emplacement 8). 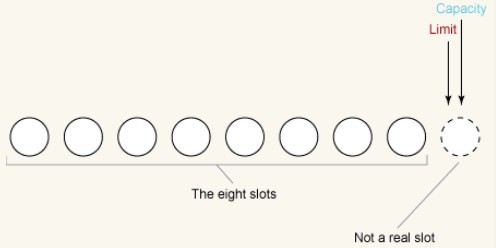
Nous remettons la position à 0. Indique que si nous lisons des données dans le tampon, les prochaines données lues entreront dans l'emplacement 0. Si nous écrivons des données à partir du tampon, le prochain octet lu dans le tampon proviendra de l'emplacement 0. Le paramètre de position est le suivant : 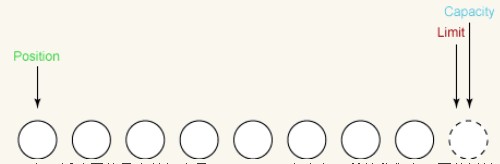
Étant donné que la capacité maximale de données du tampon ne changera pas, nous pouvons l'ignorer dans la discussion suivante.
Première lecture :
Nous pouvons maintenant commencer les opérations de lecture/écriture sur le tampon nouvellement créé. Lisez d’abord quelques données du canal d’entrée dans le tampon. La première lecture obtient trois octets. Ils sont placés dans le tableau en commençant à la position, qui est définie sur 0. Après lecture, la position est passée à 3, comme indiqué ci-dessous, et la limite n'a pas changé. 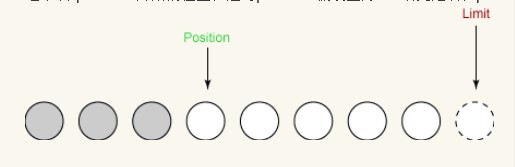
Deuxième lecture :
Lors de la deuxième lecture, nous lisons deux autres octets du canal d'entrée dans le tampon . Ces deux octets sont stockés à l'emplacement spécifié par position, la position est ainsi augmentée de 2 et la limite reste inchangée. 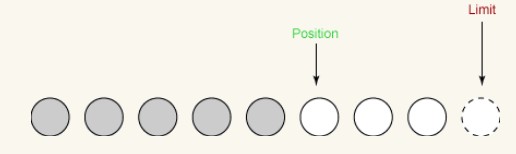
flip :
Maintenant, nous voulons écrire les données sur le canal de sortie. Avant cela, nous devons appeler la méthode flip(). Le code source est le suivant :
public final Buffer flip()
{
limit = position;
position = 0;
mark = -1;
return this;
}
这个方法做两件非常重要的事:
i 它将limit设置为当前position。
ii 它将position设置为0。L'image précédente montre le tampon avant le retournement. Voici le tampon après le flip : 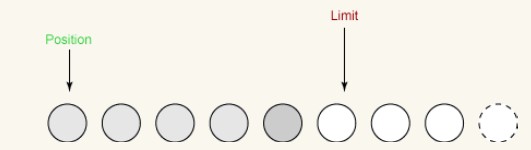
Nous pouvons maintenant écrire les données du tampon vers le canal. position est définie sur 0, ce qui signifie que le prochain octet que nous obtenons est le premier octet. limit a été défini sur la position d'origine, ce qui signifie qu'il inclut tous les octets précédemment lus et pas un seul octet de plus.
Première écriture :
Lors de la première écriture, nous prenons quatre octets du tampon et les écrivons sur le canal de sortie. Cela augmente la position à 4, tout en laissant la limite inchangée, comme suit : 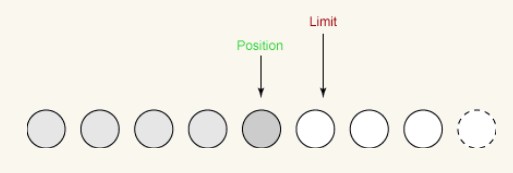
Deuxième écriture :
Il nous reste un seul octet pouvant être écrit. la limite est définie sur 5 lorsque nous appelons flip() et la position ne peut pas dépasser la limite. Ainsi, la dernière opération d'écriture prend un octet du tampon et l'écrit sur le canal de sortie. Cela augmente la position à 5 et laisse la limite inchangée, comme suit : 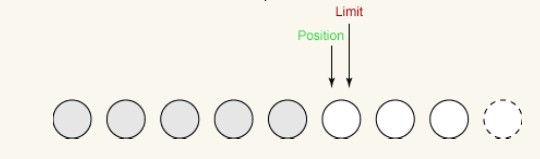
clear :
La dernière étape consiste à appeler la méthode clear() du tampon. Cette méthode réinitialise le tampon pour recevoir plus d'octets. Le code source est le suivant :
public final Buffer clear()
{
osition = 0;
limit = capacity;
mark = -1;
return this;
}clear fait deux choses très importantes :
i Il fixe la même limite que la capacité.
ii Il définit la position à 0.
La figure suivante montre l'état du tampon après l'appel de clear(). Le tampon est maintenant prêt à recevoir de nouvelles données. 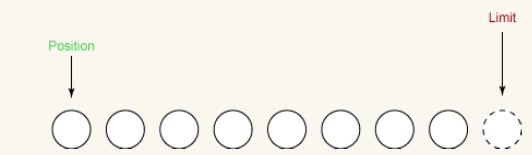
Jusqu'à présent, nous n'avons utilisé que des tampons pour transférer des données d'un canal à un autre. Cependant, les programmes doivent souvent traiter les données directement. Par exemple, vous devrez peut-être enregistrer les données utilisateur sur le disque. Dans ce cas, vous devez mettre ces données directement dans un tampon puis utiliser un canal pour écrire le tampon sur le disque. Vous pouvez également souhaiter lire les données utilisateur à partir du disque. Dans ce cas, vous lisez les données du canal dans un tampon, puis vérifiez les données dans le tampon. En fait, chaque type de base de tampon nous fournit une méthode pour accéder directement aux données dans le tampon. Prenons ByteBuffer comme exemple pour analyser comment utiliser les méthodes get() et put() qu'il fournit pour accéder directement aux données qu'il contient. les données du tampon.
a) get()
Il existe quatre méthodes get() dans la classe ByteBuffer :
byte get(); ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length ); byte get( int index );
第一个方法获取单个字节。第二和第三个方法将一组字节读到一个数组中。第四个方法从缓冲区中的特定位置获取字节。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 此外,我们认为前三个get()方法是相对的,而最后一个方法是绝对的。“相对”意味着get()操作服从limit和position值,更明确地说, 字节是从当前position读取的,而position在get之后会增加。另一方面,一个“绝对”方法会忽略limit和position值,也不会 影响它们。事实上,它完全绕过了缓冲区的统计方法。 上面列出的方法对应于ByteBuffer类。其他类有等价的get()方法,这些方法除了不是处理字节外,其它方面是是完全一样的,它们处理的是与该缓冲区类相适应的类型。
注:这里我们着重看一下第二和第三这两个方法
ByteBuffer get( byte dst[] ); ByteBuffer get( byte dst[], int offset, int length );
这两个get()主要用来进行批量的移动数据,可供从缓冲区到数组进行的数据复制使用。第一种形式只将一个数组 作为参数,将一个缓冲区释放到给定的数组。第二种形式使用 offset 和 length 参数来指 定目标数组的子区间。这些批量移动的合成效果与前文所讨论的循环是相同的,但是这些方法 可能高效得多,因为这种缓冲区实现能够利用本地代码或其他的优化来移动数据。
buffer.get(myArray)
等价于:
buffer.get(myArray,0,myArray.length);
注:如果您所要求的数量的数据不能被传送,那么不会有数据被传递,缓冲区的状态保持不 变,同时抛出 BufferUnderflowException 异常。因此当您传入一个数组并且没有指定长度,您就相当于要求整个数组被填充。如果缓冲区中的数据不够完全填满数组,您会得到一个 异常。这意味着如果您想将一个小型缓冲区传入一个大数组,您需要明确地指定缓冲区中剩 余的数据长度。上面的第一个例子不会如您第一眼所推出的结论那样,将缓冲区内剩余的数据 元素复制到数组的底部。例如下面的代码:
String str = "com.xiaoluo.nio.MultipartTransfer";
ByteBuffer buffer = ByteBuffer.allocate(50);
for(int i = 0; i < str.length(); i++)
{
buffer.put(str.getBytes()[i]);
}
buffer.flip();byte[] buffer2 = new byte[100];
buffer.get(buffer2);
buffer.get(buffer2, 0, length);
System.out.println(new String(buffer2));这里就会抛出java.nio.BufferUnderflowException异常,因为数组希望缓存区的数据能将其填满,如果填不满,就会抛出异常,所以代码应该改成下面这样:
//得到缓冲区未读数据的长度
int length = buffer.remaining();
byte[] buffer2 = new byte[100];
buffer.get(buffer2, 0, length);
b) put()ByteBuffer类中有五个put()方法:
ByteBuffer put( byte b );
ByteBuffer put( byte src[] );
ByteBuffer put( byte src[], int offset, int length );
ByteBuffer put( ByteBuffer src );
ByteBuffer put( int index, byte b );第一个方法 写入(put)单个字节。第二和第三个方法写入来自一个数组的一组字节。第四个方法将数据从一个给定的源ByteBuffer写入这个 ByteBuffer。第五个方法将字节写入缓冲区中特定的 位置 。那些返回ByteBuffer的方法只是返回调用它们的缓冲区的this值。 与get()方法一样,我们将把put()方法划分为“相对”或者“绝对”的。前四个方法是相对的,而第五个方法是绝对的。上面显示的方法对应于ByteBuffer类。其他类有等价的put()方法,这些方法除了不是处理字节之外,其它方面是完全一样的。它们处理的是与该缓冲区类相适应的类型。
c) 类型化的 get() 和 put() 方法
除了前些小节中描述的get()和put()方法, ByteBuffer还有用于读写不同类型的值的其他方法,如下所示:
getByte()
getChar()
getShort()
getInt()
getLong()
getFloat()
getDouble()
putByte()
putChar()
putShort()
putInt()
putLong()
putFloat()
putDouble()
事实上,这其中的每个方法都有两种类型:一种是相对的,另一种是绝对的。它们对于读取格式化的二进制数据(如图像文件的头部)很有用。
下面的内部循环概括了使用缓冲区将数据从输入通道拷贝到输出通道的过程。
while(true)
{
//clear方法重设缓冲区,可以读新内容到buffer里
buffer.clear();
int val = inChannel.read(buffer);
if(val == -1)
{
break;
}
//flip方法让缓冲区的数据输出到新的通道里面
buffer.flip();
outChannel.write(buffer);
}read()和write()调用得到了极大的简化,因为许多工作细节都由缓冲区完成了。clear()和flip()方法用于让缓冲区在读和写之间切换。
好了,缓冲区的内容就暂且写到这里,下一篇我们将继续NIO的学习–通道(Channel).
以上就是Java NIO 缓冲区学习笔记 的内容,更多相关内容请关注PHP中文网(m.sbmmt.com)!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



