


Avant chaque version de fonctionnalité, j'effectue des Tests d'acceptation utilisateur (« UAT ») pour détecter les bogues et m'assurer que la logique métier est correctement traduite en code.
Je n'autorise la publication d'une fonctionnalité qu'une fois l'UAT réussie à 100 %.
Mon raisonnement est simple : vous n'avez qu'une seule chance de faire une bonne première impression à votre utilisateur final, et une mauvaise version rend cette tâche doublement difficile.

Bien qu'il s'agisse d'une fonctionnalité MVP qui n'est pas destinée à la production, j'ai pensé que ce serait bien de faire un peu d'UAT pour garder mes compétences à jour.
Parmi les 19 scénarios UAT que j'ai proposés, un a échoué en raison d'un changement dans le modèle PDF de la Déclaration du dépositaire.
J'avais anticipé ce risque lors de Discovery, mais à vrai dire, je ne m'attendais pas à ce que le problème surgisse si tôt.
J'entrerai dans les détails de la correction des bugs plus loin dans l'article.
Mon processus UAT implique d'utiliser la logique métier ou les exigences des fonctionnalités comme référence pour créer des scénarios de test et les résultats attendus.
Les scénarios de test n'ont pas besoin d'être compliqués. Ils peuvent être aussi simples que : "La fonctionnalité génère un fichier CSV en 30 secondes".
Pour l'UAT, j'ai traité 71 pages de documents provenant de 10 PDF de déclaration de garde. Il devrait s'agir d'un ensemble d'échantillons suffisamment grand.
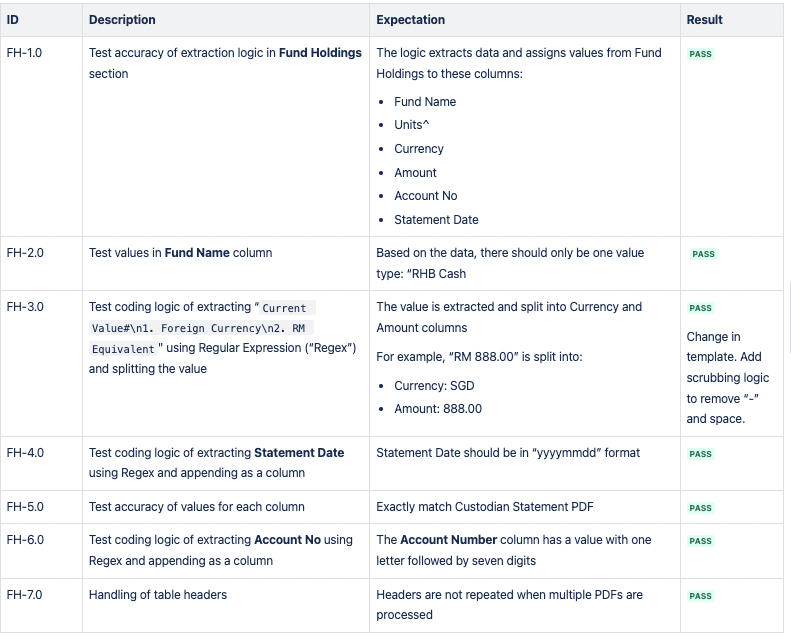
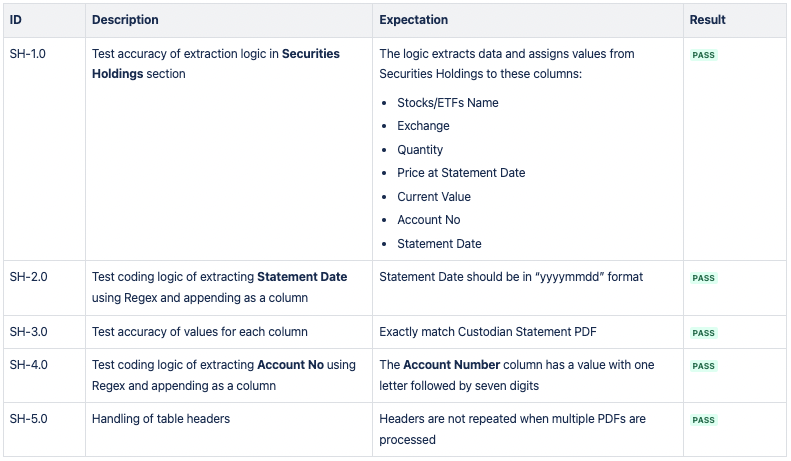
Le résultat attendu est trois fichiers CSV contenant des points de données spécifiques des sections Fund Holdings, Securities Holdings et Cash Holdings du PDF de la déclaration du dépositaire.
J'ai proposé les cas de test suivants :
CSV 1 : avoirs du fonds
CSV 2 : Titres détenus
CSV 3 : avoirs en espèces

Le seul test qui a échoué est dû au fait que le modèle PDF de la déclaration du dépositaire a légèrement changé en novembre. Plus précisément, les valeurs de la colonne « Valeur actuelle n° 1. Devise étrangère 2. Équivalent en RM » d'un tableau des avoirs du fonds comportent désormais un préfixe « -n » supplémentaire.
Par exemple, au lieu de lire « 10 000 USD » dans les PDF précédents, la valeur indique désormais « - 10 000 USD ».
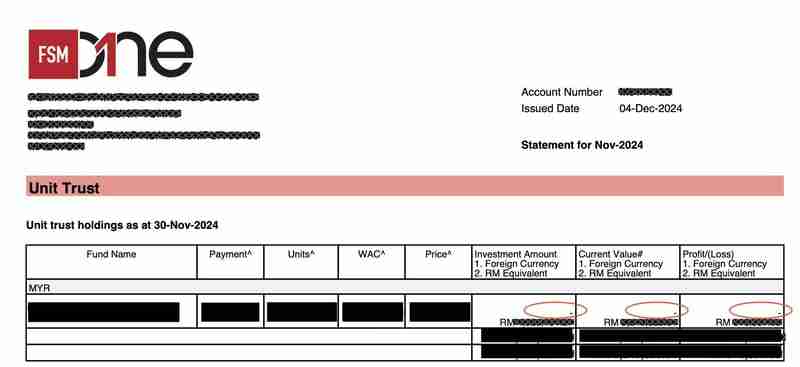
Ce petit changement a entraîné le problème suivant :

J'ai consulté ChatGPT sur un correctif, et il a recommandé que la logique de nettoyage suivante soit ajoutée pour supprimer le préfixe "-/n" incorrect.
# Scrub error prefix
df['Currency'] = df['Currency'].str.replace('[-\n]', '', regex=True)
Le nettoyage a fait l'affaire et la sortie CSV de Fund Holdings s'affiche désormais comme prévu.
Je suis maintenant convaincu que le code pour extraire les données PDF est fonctionnel. Cela dit, je ne pense pas qu'un fichier CSV soit le meilleur endroit pour stocker toutes ces données.
Bien que CSV soit convivial (pour moi), le stockage des données dans une base de données facilite grandement la récupération et la manipulation des données selon les exigences de l'utilisateur final.
J'ai une expérience très limitée dans les bases de données. Ce que je vais donc faire ensuite, c'est Discovery sur une application de base de données que je peux intégrer rapidement.
--Fin
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Que fait Python ?
Que fait Python ?
 Quelle est l'inscription dans la blockchain ?
Quelle est l'inscription dans la blockchain ?
 Représentation binaire des nombres négatifs
Représentation binaire des nombres négatifs
 Comment vérifier la mémoire
Comment vérifier la mémoire
 Le navigateur Edge ne peut pas rechercher
Le navigateur Edge ne peut pas rechercher
 Téléchargement d'E-O Exchange
Téléchargement d'E-O Exchange
 Comment résoudre le problème selon lequel le partage réseau d'ordinateurs portables n'a pas d'autorisations ?
Comment résoudre le problème selon lequel le partage réseau d'ordinateurs portables n'a pas d'autorisations ?
 format flac
format flac








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



