


Vous pouvez obtenir des numéros de téléchargement pour les packages (ou projets) PyPI à partir d'un ensemble de données Google BigQuery. Vous avez besoin d'un compte et d'informations d'identification Google, et Google vous offre 1 Tio de quota gratuit par mois.
Chaque mois, je dispose d'une automatisation pour récupérer les numéros de téléchargement des 8 000 packages les plus populaires au cours des 30 derniers jours et les rendre disponibles sous forme de fichiers JSON et CSV plus accessibles sur Top PyPI Packages. Ces données sont largement utilisées pour la recherche dans le monde universitaire et industriel.
Cependant, à mesure que de plus en plus de packages et de versions sont téléchargés sur PyPI et que de plus en plus de téléchargements sont enregistrés, la quantité de données facturées augmente également.
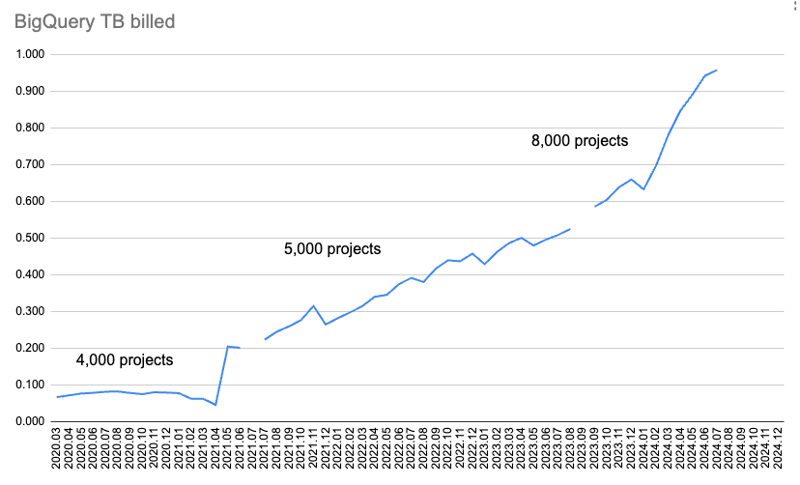
Ce graphique montre la quantité de données facturée par mois.
Au début, je collectais uniquement les données de téléchargement de 4 000 packages, et elles étaient récupérées pour deux requêtes : téléchargements sur 365 jours et sur 30 jours. Mais au fil du temps, le quota de téléchargement de données pendant 365 jours a commencé à être utilisé.
J'ai donc abandonné les données sur 365 jours et augmenté les données sur 30 jours de 4 000 à 5 000 colis. Plus tard, j'ai vérifié le quota utilisé et je suis passé de 5 000 colis à 8 000 colis.
Mais j'ai ensuite dépassé le quota mensuel BigQuery de 1 Tio de récupération de données pour juillet 2024.
Pour récupérer les données manquantes et enquêter sur ce qui se passe, j'ai commencé l'essai gratuit de 90 jours de Google Cloud, à 300 $ (277,46 €) ?
Voici ce que j'ai trouvé !
J'utilise le client pypinfo pour interroger BigQuery. Par défaut, il récupère uniquement les téléchargements pour pip.
Cette commande obtient les données de téléchargement d'une journée pour les 10 meilleurs packages, pour pip uniquement :
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
Résultats :
| project | download count |
|---|---|
| boto3 | 37,251,744 |
| aiobotocore | 16,252,824 |
| urllib3 | 16,243,278 |
| botocore | 15,687,125 |
| requests | 13,271,314 |
| s3fs | 12,865,055 |
| s3transfer | 12,014,278 |
| fsspec | 11,982,305 |
| charset-normalizer | 11,684,740 |
| certifi | 11,639,584 |
| Total | 158,892,247 |
L'ajout de l'indicateur --all permet d'obtenir des données de téléchargement d'une journée pour les 10 meilleurs packages, pour tous les installateurs :
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
| project | download count |
|---|---|
| boto3 | 39,495,624 |
| botocore | 17,281,187 |
| urllib3 | 17,225,121 |
| aiobotocore | 16,430,826 |
| requests | 14,287,965 |
| s3fs | 12,958,516 |
| charset-normalizer | 12,781,405 |
| certifi | 12,647,098 |
| setuptools | 12,608,120 |
| idna | 12,510,335 |
| Total | 168,226,197 |
Nous pouvons donc voir que le pip par défaut coûte uniquement 25 % de données supplémentaires traitées et facturées, et coûte 25 % de plus en dollars.
Sans surprise, le nombre réel de téléchargements est plus élevé pour tous les installateurs. Le classement a un peu changé, mais je pense que nous obtiendrons toujours plus ou moins les mêmes packages dans les milliers de premiers résultats.
Il envoie une requête comme celle-ci à BigQuery pour seulement pip :
SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 10
Et pour tous les installateurs :
$ pypinfo --all --limit 100 --days 1 "" installer Served from cache: False Data processed: 29.49 GiB Data billed: 29.49 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) GROUP BY project ORDER BY download_count DESC LIMIT 8000
Ces requêtes sont les mêmes, sauf que la condition par défaut a une condition supplémentaire AND details.installer.name = "pip". Il semble raisonnable que cela coûterait plus cher pour effectuer un travail de filtrage supplémentaire.
Regardons les installateurs :
| installer name | download count |
|---|---|
| pip | 1,121,198,711 |
| uv | 117,194,833 |
| requests | 29,828,272 |
| poetry | 23,009,454 |
| None | 8,916,745 |
| bandersnatch | 6,171,555 |
| setuptools | 1,362,797 |
| Bazel | 1,280,271 |
| Browser | 1,096,328 |
| Nexus | 593,230 |
| Homebrew | 510,247 |
| Artifactory | 69,063 |
| pdm | 62,904 |
| OS | 13,108 |
| devpi | 9,530 |
| conda | 2,272 |
| pex | 194 |
| Total | 1,311,319,514 |
pip reste de loin le plus populaire, et sans surprise, uv est également présent, avec environ 10 % des téléchargements de pip.
Les autres contiennent environ 25 % ou moins d'uv. Beaucoup d’entre eux reflètent des services que nous voulions exclure auparavant.
Je pense qu'étant donné l'importance de uv et mon attente qu'il continue à prendre une plus grande part du gâteau, plus particulièrement le coût supplémentaire du filtrage par pip uniquement, signifie que nous devrions passer à la récupération de données pour tous les téléchargeurs. De plus, les autres ne représentent pas une grande partie du gâteau.
C'était la plus grande surprise. Auparavant, j'avais augmenté ou diminué le nombre pour essayer de rester sous quota. Mais il s'avère que le nombre de paquets que vous interrogez ne fait aucune différence !
J'ai récupéré les données d'une seule journée et de tous les installateurs pour différentes limites de packages : 1 000, 2 000, 3 000, 4 000, 5 000, 6 000, 7 000, 8 000. Exemple de requête :
$ pypinfo --limit 10 --days 1 "" project Served from cache: False Data processed: 58.21 GiB Data billed: 58.21 GiB Estimated cost: <pre class="brush:php;toolbar:false">$ pypinfo --all --limit 10 --days 1 "" project Served from cache: False Data processed: 46.63 GiB Data billed: 46.63 GiB Estimated cost: <pre class="brush:php;toolbar:false">SELECT file.project as project, COUNT(*) as download_count, FROM `bigquery-public-data.pypi.file_downloads` WHERE timestamp BETWEEN TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -2 DAY) AND TIMESTAMP_ADD(CURRENT_TIMESTAMP(), INTERVAL -1 DAY) AND details.installer.name = "pip" GROUP BY project ORDER BY download_count DESC LIMIT 10
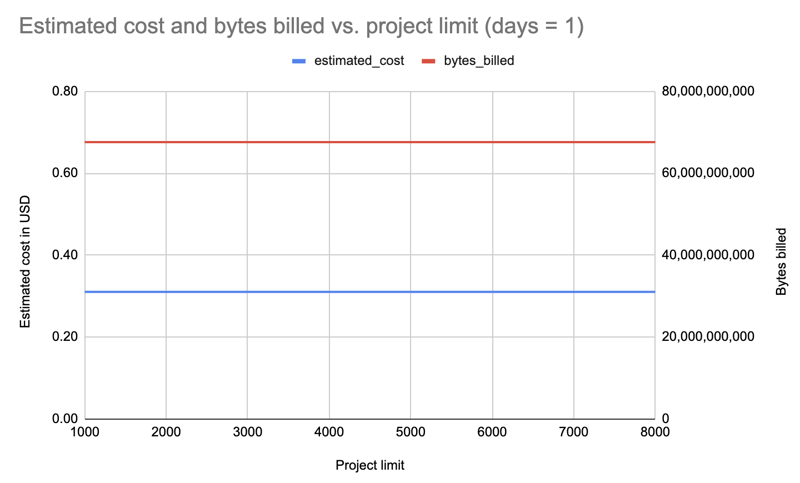
Résultat : Fait intéressant, le coût est le même pour toutes les limites (1 000-8 000) : 0,31 $.
Répéter avec un jour mais filtrer uniquement le pip :
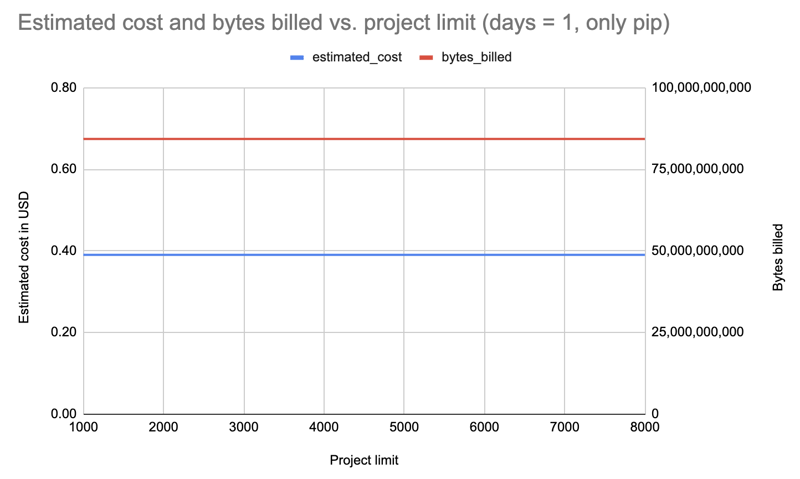
Résultat : Coût augmenté à 0,39 $ mais encore une fois identique pour toutes les limites.
Répétons avec tous les installateurs, mais pendant 30 jours, et cette fois-ci en interrogeant des limites décroissantes, au cas où nous ne payions que pour des modifications incrémentielles : 8000, 7000, 6000, 5000, 4000, 3000, 2000, 1000 :
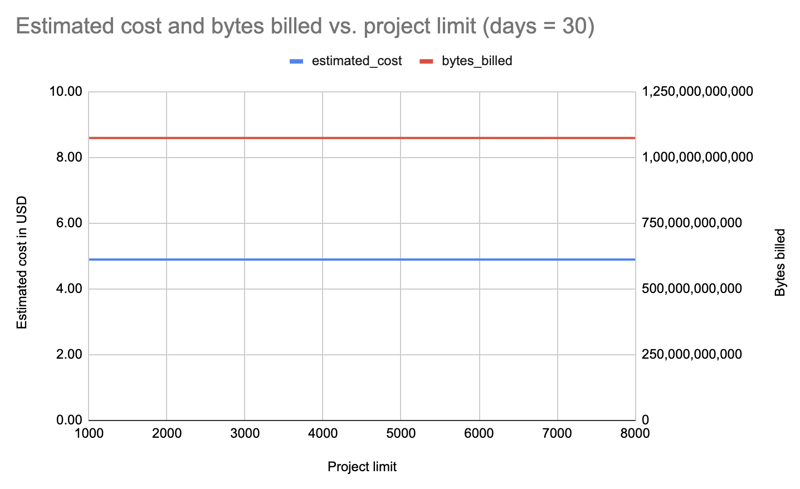
Résultat : Encore une fois, le coût est le même quelle que soit la limite du forfait : 4,89 $ par requête.
Eh bien, répétons avec la limite augmentant par puissances de dix, jusqu'à 1 000 000 ! Ce dernier récupère les données des 531 022 packages sur PyPI :
| limit | projects count | estimated cost | bytes billed | bytes processed |
|---|---|---|---|---|
| 1 | 1 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10 | 10 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100 | 100 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000 | 1,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 8000 | 8,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 10000 | 10,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 100000 | 100,000 | 0.20 | 43,447,746,560 | 43,447,720,943 |
| 1000000 | 531,022 | 0.20 | 43,447,746,560 | 43,447,720,943 |
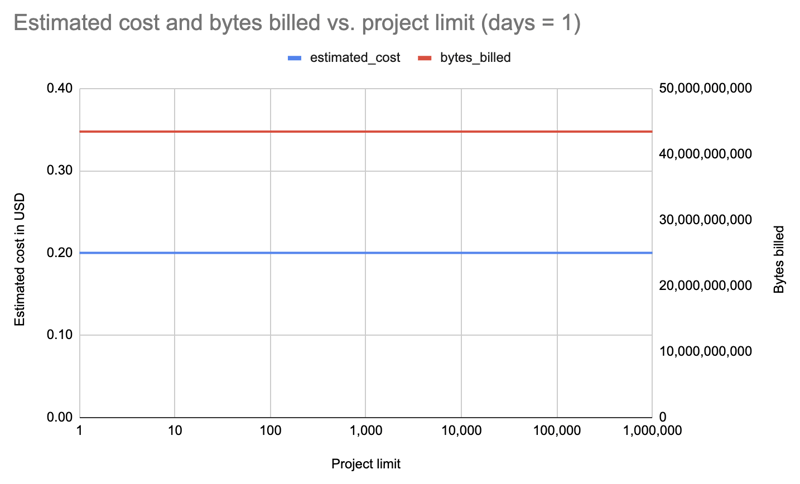
Résultat : Là encore, même coût, que ce soit pour 1 colis ou 531 022 colis !
Pas de surprise. J'avais déjà remarqué que 365 jours prenaient également beaucoup de quota, et je pouvais continuer avec 30 jours.
Voici le coût estimé et les octets facturés (pour un package, tous les installateurs) entre un et 30 jours (f"pypinfo --all --json --indent 0 --days {days} --limit 1'' project "), montrant une augmentation à peu près linéaire :
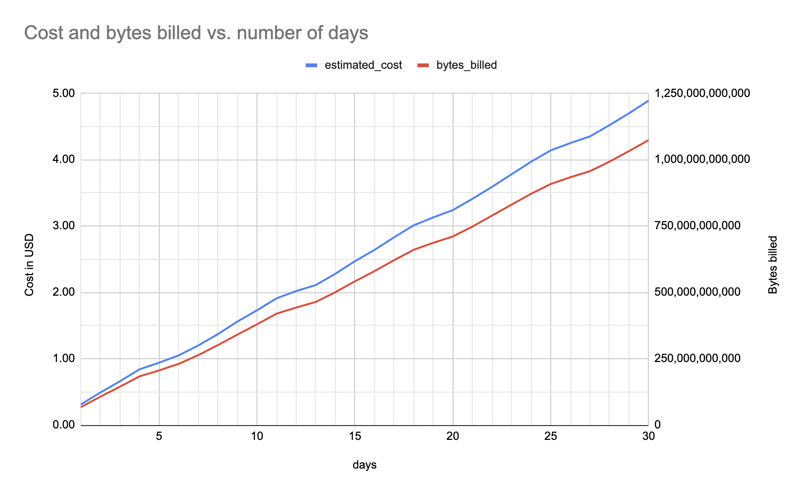
Peu importe le nombre de paquets pour lesquels je récupère les données, je pourrais aussi bien les récupérer tous et les rendre accessibles à tout le monde, en fonction de la taille du fichier de données. Il sera logique de toujours proposer un fichier plus petit avec environ 8 000 packages : souvent, vous avez juste besoin d'un nombre important mais gérable.
Il en coûte plus cher de filtrer uniquement les téléchargements à partir de pip, j'ai donc opté pour la récupération des données pour tous les installateurs.
Le nombre de jours affecte le coût, je devrai donc le diminuer à l'avenir pour rester dans les limites du quota. Par exemple, à un moment donné, je devrai peut-être passer de 30 à 25 jours, puis plus tard de 25 à 20 jours.
Plus de détails sur l'enquête, les scripts et les fichiers de données peuvent être trouvés sur
hugovk/top-pypi-packages#36.
Et faites-moi savoir si vous connaissez des astuces pour réduire les coûts !
Photo d'en-tête : "The Balancing Rock, Stonehenge, Near Glen Innes, NSW" par la Royal Australian Historical Society, sans restrictions de droits d'auteur connues.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



