


GraphQL est un langage de requête permettant d'obtenir des données structurées profondément imbriquées à partir du backend d'un site Web, similaire aux requêtes MongoDB.
La requête est généralement un POST vers un point de terminaison général /graphql avec un corps comme celui-ci :

Cependant, avec de grandes structures de données, cela devient inefficace : vous envoyez une requête volumineuse dans un corps de requête POST, qui est (presque toujours) le même et ne change que lors des mises à jour du site Web ; Les requêtes POST ne peuvent pas être mises en cache, etc. Par conséquent, une extension appelée « requêtes persistantes » a été développée. Ce n’est pas un secret anti-grattage ; vous pouvez lire la documentation publique à ce sujet ici.
TLDR : le client calcule le hachage sha256 du texte de la requête et envoie uniquement ce hachage. De plus, vous pouvez éventuellement intégrer tout cela dans la chaîne de requête d'une requête GET, la rendant ainsi facilement mise en cache. Vous trouverez ci-dessous un exemple de demande de Zillow

Comme vous pouvez le voir, il ne s'agit que de quelques métadonnées sur l'extension persistedQuery, le hachage de la requête et les variables à intégrer dans la requête.
Voici une autre demande d'expedia.com, envoyée sous forme de POST, mais avec la même extension :

Cela optimise principalement les performances du site Web, mais cela crée plusieurs défis pour le web scraping :
Par conséquent, pour différentes raisons, vous pourriez vous retrouver dans la nécessité d'extraire l'intégralité du texte de la requête. Vous pouvez parcourir le JavaScript du site Web et, si vous avez de la chance, vous y trouverez peut-être le texte de la requête dans son intégralité, mais souvent, il est construit de manière dynamique à partir de plusieurs fragments, etc.
Par conséquent, nous avons trouvé une meilleure solution : nous ne toucherons pas du tout au JavaScript côté client. Au lieu de cela, nous allons essayer de simuler la situation dans laquelle le client tente d'utiliser un hachage que le serveur ne connaît pas. Par conséquent, nous devons intercepter la requête (valide) envoyée par le navigateur en cours et modifier le hachage en un faux avant de le transmettre au serveur.
Pour exactement ce cas d'utilisation, il existe un outil parfait : mitmproxy, une bibliothèque Python open source qui intercepte les requêtes effectuées par vos propres appareils, sites Web ou applications et vous permet de les modifier avec de simples scripts Python.
Téléchargez mitmproxy et préparez un script Python comme celui-ci :
import json
def request(flow):
try:
dat = json.loads(flow.request.text)
dat[0]["extensions"]["persistedQuery"]["sha256Hash"] = "0d9e" # any bogus hex string here
flow.request.text = json.dumps(dat)
except:
pass
Ceci définit un hook que mitmproxy exécutera à chaque requête : il essaie de charger le corps JSON de la requête, modifie le hachage en une valeur arbitraire et écrit le JSON mis à jour en tant que nouveau corps de la requête.
Nous devons également nous assurer de rediriger les requêtes de notre navigateur vers mitmproxy. Pour cela, nous allons utiliser une extension de navigateur appelée FoxyProxy. Il est disponible dans Firefox et Chrome.
Ajoutez simplement un itinéraire avec ces paramètres :

Nous pouvons maintenant exécuter mitmproxy avec ce script : mitmweb -s script.py
Cela ouvrira un onglet de navigateur où vous pourrez regarder toutes les requêtes interceptées en temps réel.

Si vous accédez au chemin particulier et voyez la requête dans la section requête, vous verrez qu'une valeur inutile a remplacé le hachage.
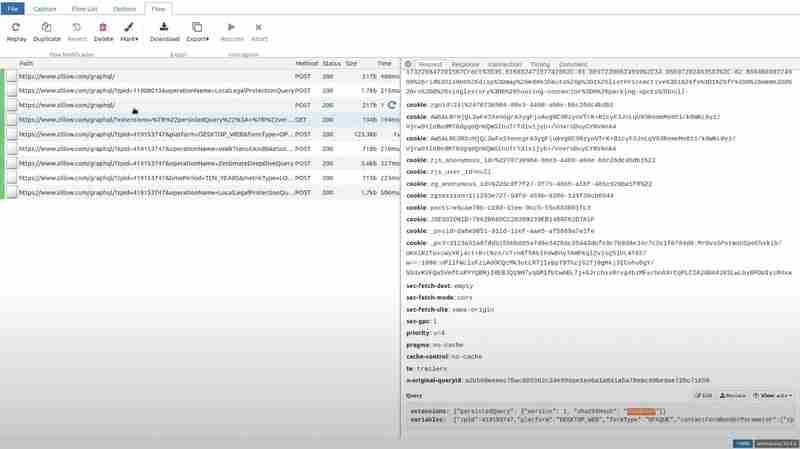
Maintenant, si vous visitez Zillow et ouvrez le chemin particulier que nous avons essayé pour l'extension, et accédez à la section de réponse, le côté client reçoit l'erreur PersistedQueryNotFound.

Le front-end de Zillow réagit en envoyant l'intégralité de la requête sous forme de requête POST.

Nous extrayons la requête et le hachage directement de cette requête POST. Pour garantir que le serveur Zillow n'oublie pas ce hachage, nous exécutons périodiquement cette requête POST avec exactement la même requête et le même hachage. Cela garantira que le scraper continue de fonctionner même lorsque le cache du serveur est nettoyé ou réinitialisé ou que le site Web change.
Conclusion
Les requêtes persistantes sont un puissant outil d'optimisation pour les API GraphQL, améliorant les performances du site Web en minimisant la taille des charges utiles et en activant la mise en cache des requêtes GET. Cependant, ils posent également des défis importants pour le web scraping, principalement en raison de la dépendance aux hachages stockés sur le serveur et du risque que ces hachages deviennent invalides.
L'utilisation de mitmproxy pour intercepter et manipuler les requêtes GraphQL offre une approche efficace pour révéler le texte complet de la requête sans se plonger dans du JavaScript complexe côté client. En forçant le serveur à répondre avec une erreur PersistedQueryNotFound, nous pouvons capturer la charge utile complète de la requête et l'utiliser à des fins de scraping. L'exécution périodique de la requête extraite garantit que le scraper reste fonctionnel, même lorsque des réinitialisations du cache côté serveur se produisent ou que le site Web évolue.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Une liste complète des touches de raccourci d'idées
Une liste complète des touches de raccourci d'idées
 Comment créer un index dans Word
Comment créer un index dans Word
 ps supprimer la zone sélectionnée
ps supprimer la zone sélectionnée
 Quel est le format du papier A5
Quel est le format du papier A5
 Solution au problème xlive.dll manquant
Solution au problème xlive.dll manquant
 Méthode d'ouverture de l'autorisation de portée
Méthode d'ouverture de l'autorisation de portée
 Solution à l'erreur de socket 10054
Solution à l'erreur de socket 10054
 Utilisation de la fonction printf en langage C
Utilisation de la fonction printf en langage C








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



