


Dans les articles précédents nous avons découvert DOM et CSSOM, si vous avez encore des doutes sur ces deux mots je vous recommande de lire les deux articles ci-dessous :
Pour récapituler, le DOM est une structure que le navigateur utilise pour restituer notre page. Cependant, les données Internet ne sont pas transmises sous la forme d'un DOM, il doit donc y avoir un processus avant que le DOM soit prêt à être consommé par le navigateur.
À ce stade, vous vous demandez peut-être comment les données circulent sur Internet ?
Chaque fois que nous accédons à un site Web, un échange a lieu selon un modèle que nous appelons client x serveur.
Dans cet échange, le client (votre navigateur) demande au serveur d'accéder au site www.cristiano.dev, qui répond avec tout le contenu du site demandé, mais ce contenu se présente sous forme d'octets et en quelque sorte c'est éloigné du html/css/js que nous connaissons.
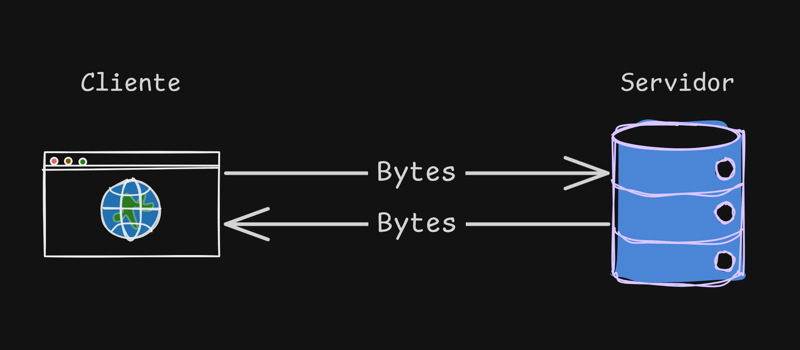
Ce que le navigateur recevra du serveur est une séquence d'octets.
Pour ce petit extrait de html fourni par le serveur :
<!doctype html>
<html>
<head>
<title>Um título</title>
</head>
<body>
<a href="#">Um link</a>
<h1>Um cabeçalho</h1>
</body>
</html>
Le navigateur recevrait en octets quelque chose comme ceci :
3C21646F63747970652068746D6C3E0A3C68746D6C3E0A20203C686561643E0A202020203C7469746C653E556D2074C3AD74756C6F3C2F7469746C653E0A20203C2F686561643E0A20203C626F64793E0A202020203C6120687265663D2223223E556D206C696E6B3C2F613E0A202020203C68313E556D2063616265C3A7616C686F3C2F68313E0A20203C2F626F64793E0A3C2F68746D6C3E
Cependant, le navigateur ne peut pas afficher une page avec uniquement ces informations. Pour que notre mise en page soit assemblée, le navigateur effectuera quelques étapes avant d'avoir le DOM.
Ces étapes sont :

Dans cette étape, le navigateur lit les données brutes du réseau ou d'un disque et les convertit en caractères en fonction de l'encodage spécifié dans le fichier, par exemple UTF-8.
Fondamentalement, c'est l'étape dans laquelle le navigateur transforme les octets en code au format que nous écrivons dans notre vie quotidienne.

A ce stade, le navigateur convertit les chaînes de caractères en petites unités appelées jetons. Chaque début, fin de balise et contenu sont comptés, de plus, chaque jeton a un ensemble de règles spécifiques.
Par exemple, la balise a des attributs différents de ceux de la balise
Sans cette étape, nous n'aurons qu'un tas de texte sans signification pour le navigateur et à la fin de ce processus, notre code HTML de base serait tokenisé comme ceci :
➔ Jeton : StartTag, Nom : p

Un jeton est un mot ou un symbole individuel dans un texte. La « tokenisation » est le processus de division du texte en mots, phrases ou symboles plus petits.

L'étape de lexing (analyse lexicale) est chargée de convertir les jetons en objets, mais ce n'est pas encore le DOM. En ce moment, le navigateur génère des parties isolées du DOM, où chaque balise sera transformée en un objet avec des attributs qui apportent des informations relatives aux attributs, balises parents, balises enfants, etc.
Le résultat après lexing de notre tag
ce serait quelque chose comme ça :
<!doctype html>
<html>
<head>
<title>Um título</title>
</head>
<body>
<a href="#">Um link</a>
<h1>Um cabeçalho</h1>
</body>
</html>

Nous avons enfin atteint le stade de la construction des DOM !
À ce stade, le navigateur considérera les relations entre les balises html et joindra les nœuds dans une structure de données arborescente qui représente ces relations de manière hiérarchique. Par exemple : l'objet html est le parent de l'objet body, le body est le parent de l'objet paragraphe, jusqu'à ce que la représentation entière du document soit créée.
En fin de construction, notre exemple html devient un arbre d'objets comme celui-ci :
3C21646F63747970652068746D6C3E0A3C68746D6C3E0A20203C686561643E0A202020203C7469746C653E556D2074C3AD74756C6F3C2F7469746C653E0A20203C2F686561643E0A20203C626F64793E0A202020203C6120687265663D2223223E556D206C696E6B3C2F613E0A202020203C68313E556D2063616265C3A7616C686F3C2F68313E0A20203C2F626F64793E0A3C2F68746D6C3E
Le processus de construction du DOM est complexe et se déroule selon les étapes suivantes :
Un processus similaire a également lieu pour CSSOM, composé de conversion, de tokenisation et de lexing.
Vous devez vous demander où vous allez appliquer ces connaissances tout au long de votre développement quotidien...
Il est vrai que ce type d'informations ne sera pas demandé fréquemment, mais il est important de comprendre comment fonctionnent essentiellement les navigateurs, principal outil de travail frontend.
Ces connaissances seront également très précieuses pour comprendre les prochains sujets que nous aborderons ici : Peindre, repeindre, couler et refusionner.
Merci d'être venu !
J'espère que vous avez appris quelque chose de nouveau tout au long de cette lecture.
À la prochaine fois !
Construction du modèle objet
Déconstruire le Web : le rendu des pages
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 mysqlmot de passe oublié
mysqlmot de passe oublié
 Quels sont les composants d'un système Linux ?
Quels sont les composants d'un système Linux ?
 Comment éteindre votre ordinateur rapidement
Comment éteindre votre ordinateur rapidement
 Qu'est-ce que le fil coin ?
Qu'est-ce que le fil coin ?
 Tutoriel de configuration du mot de passe de démarrage de Windows 10
Tutoriel de configuration du mot de passe de démarrage de Windows 10
 Qu'est-ce que la programmation de socket
Qu'est-ce que la programmation de socket
 Vérifier la taille du dossier sous Linux
Vérifier la taille du dossier sous Linux
 js sous-chaîne
js sous-chaîne








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



