


Dans nos articles précédents, nous avons découvert un certain nombre d'algorithmes de tri tels que le tri à bulles, le tri par sélection ainsi que le tri par insertion. Nous avons appris que même si ces algorithmes de tri sont très faciles à mettre en œuvre, ils ne sont pas efficaces pour les grands ensembles de données, ce qui signifie que nous avons besoin d'un algorithme plus efficace pour gérer le tri des grands ensembles de données, et donc le tri par fusion. Dans cette série, nous verrons comment fonctionne le tri par fusion et comment il peut être implémenté en JavaScript. Tu es prêt ?

Merge Sort Algorithm est un excellent algorithme de tri qui suit le principe diviser pour régner. Contrairement aux algorithmes plus simples comme le tri par sélection et le tri à bulles qui effectuent plusieurs passages dans le tableau en comparant les éléments adjacents, le tri par fusion adopte une approche plus stratégique :
Cette approche surpasse systématiquement les algorithmes O(n²) plus simples tels que le tri par sélection et le tri à bulles lorsqu'il s'agit de jeux de données plus volumineux.
Nous avons vu que le tri par fusion fonctionne en utilisant l'approche populaire diviser pour régner. Vous trouverez ci-dessous une représentation visuelle de son fonctionnement.
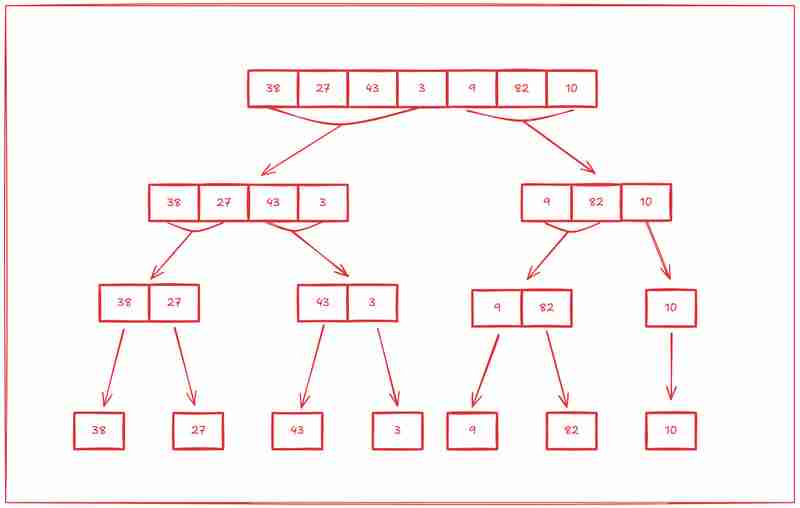
Maintenant que nous avons vu la magie, voyons comment fonctionne l'algorithme de tri par fusion en triant manuellement ce tableau : [38, 27, 43, 3, 9, 82, 10] en utilisant l'approche mentionnée ci-dessus.
La première étape du tri par fusion consiste à diviser le tableau en sous-tableaux, puis à diviser chaque sous-tableau en sous-tableaux, et le sous-tableau en sous-tableaux jusqu'à ce qu'il ne reste qu'un seul élément dans tous les sous-tableaux.
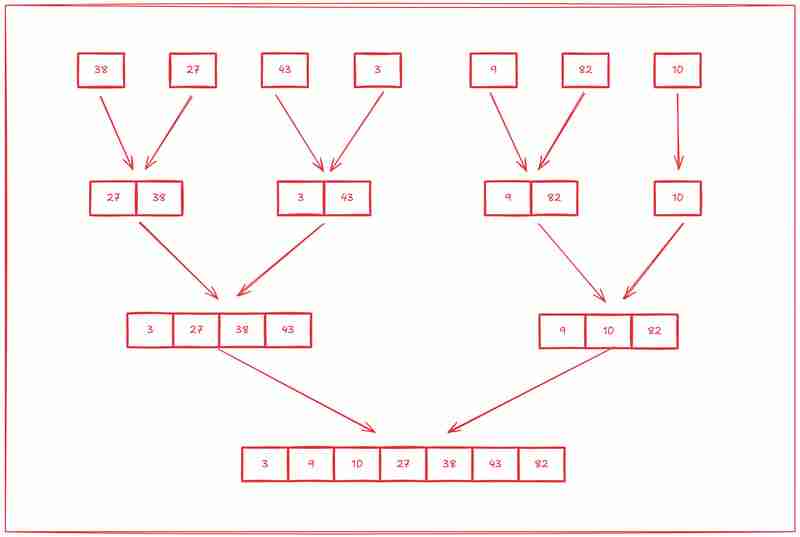
La deuxième étape consiste à commencer à trier ces sous-réseaux à partir de zéro.
Le tri par fusion atteint une complexité temporelle O(n log n) dans tous les cas (meilleur, moyen et pire), ce qui le rend plus efficace que les algorithmes O(n²) pour les ensembles de données plus volumineux.
Voici pourquoi :
Comparez ceci à :
Pour un tableau de 1 000 éléments :
Le tri par fusion nécessite O(n) espace supplémentaire pour stocker les tableaux temporaires pendant la fusion. Bien que ce soit plus que l'espace O(1) nécessaire au tri à bulles ou au tri par sélection, l'efficacité du temps rend généralement ce compromis intéressant dans la pratique.
// The Merge Helper Function
function merge(left, right) {
const result = [];
let leftIndex = 0;
let rightIndex = 0;
while (leftIndex < left.length && rightIndex < right.length) {
if (left[leftIndex] <= right[rightIndex]) {
result.push(left[leftIndex]);
leftIndex++;
} else {
result.push(right[rightIndex]);
rightIndex++;
}
}
// Add remaining elements
while (leftIndex < left.length) {
result.push(left[leftIndex]);
leftIndex++;
}
while (rightIndex < right.length) {
result.push(right[rightIndex]);
rightIndex++;
}
return result;
}
const result = []; let leftIndex = 0; let rightIndex = 0;
while (leftIndex < left.length && rightIndex < right.length) {
if (left[leftIndex] <= right[rightIndex]) {
result.push(left[leftIndex]);
leftIndex++;
} else {
result.push(right[rightIndex]);
rightIndex++;
}
}
while (leftIndex < left.length) {
result.push(left[leftIndex]);
leftIndex++;
}
function mergeSort(arr) {
// Base case
if (arr.length <= 1) {
return arr;
}
// Divide
const middle = Math.floor(arr.length / 2);
const left = arr.slice(0, middle);
const right = arr.slice(middle);
// Conquer and Combine
return merge(mergeSort(left), mergeSort(right));
}
if (arr.length <= 1) {
return arr;
}
const middle = Math.floor(arr.length / 2); const left = arr.slice(0, middle); const right = arr.slice(middle);
return merge(mergeSort(left), mergeSort(right));
Voyons comment ça trie [38, 27, 43, 3] :
// The Merge Helper Function
function merge(left, right) {
const result = [];
let leftIndex = 0;
let rightIndex = 0;
while (leftIndex < left.length && rightIndex < right.length) {
if (left[leftIndex] <= right[rightIndex]) {
result.push(left[leftIndex]);
leftIndex++;
} else {
result.push(right[rightIndex]);
rightIndex++;
}
}
// Add remaining elements
while (leftIndex < left.length) {
result.push(left[leftIndex]);
leftIndex++;
}
while (rightIndex < right.length) {
result.push(right[rightIndex]);
rightIndex++;
}
return result;
}
const result = []; let leftIndex = 0; let rightIndex = 0;
while (leftIndex < left.length && rightIndex < right.length) {
if (left[leftIndex] <= right[rightIndex]) {
result.push(left[leftIndex]);
leftIndex++;
} else {
result.push(right[rightIndex]);
rightIndex++;
}
}
Merge Sort se distingue comme un algorithme de tri très efficace qui fonctionne systématiquement bien sur de grands ensembles de données. Bien qu'il nécessite un espace supplémentaire par rapport aux algorithmes de tri plus simples, sa complexité temporelle O(n log n) en fait un choix incontournable pour de nombreuses applications du monde réel où les performances sont cruciales.
Points clés à retenir :
Pour vous assurer de ne manquer aucune partie de cette série et pour me contacter pour plus de détails
discussions sur le Développement Logiciel (Web, Serveur, Mobile ou Scraping/Automatisation), les données
structures et algorithmes, et d'autres sujets technologiques passionnants, suivez-moi sur :

Restez à l'écoute et bon codage ???
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment utiliser la fonction d'impression en python
Comment utiliser la fonction d'impression en python
 securefx ne peut pas se connecter
securefx ne peut pas se connecter
 Introduction aux équipements de surveillance des stations météorologiques
Introduction aux équipements de surveillance des stations météorologiques
 vscode
vscode
 La différence entre le langage C et Python
La différence entre le langage C et Python
 Google Earth ne parvient pas à se connecter à la solution serveur
Google Earth ne parvient pas à se connecter à la solution serveur
 Comment installer des bibliothèques tierces dans sublime
Comment installer des bibliothèques tierces dans sublime
 Méthode de cryptage des données
Méthode de cryptage des données








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



