


Streamlit est un puissant framework open source qui vous permet de créer des applications Web pour la science des données et l'apprentissage automatique avec seulement quelques lignes de code Python.
Il est simple, intuitif et ne nécessite aucune expérience frontend, ce qui en fait un excellent outil pour les développeurs débutants et expérimentés qui souhaitent déployer rapidement des modèles d'apprentissage automatique.
Dans ce blog, je vais vous guider à travers un processus étape par étape pour créer une application Streamlit de base et un projet d'apprentissage automatique en utilisant l'ensemble de données Iris avec un RandomForestClassifier .
Avant de nous lancer dans le projet, passons en revue quelques fonctionnalités de base de Streamlit pour nous familiariser avec le framework. Vous pouvez installer Streamlit à l'aide de la commande suivante :
pip install streamlit
Une fois installée, vous pouvez démarrer votre première application Streamlit en créant un fichier Python, par exemple app.py, et en l'exécutant en utilisant :
streamlit run app.py
Explorons maintenant les principales fonctionnalités de Streamlit :
1. Écrire des titres et afficher du texte
import streamlit as st
# Writing a title
st.title("Hello World")
# Display simple text
st.write("Displaying a simple text")

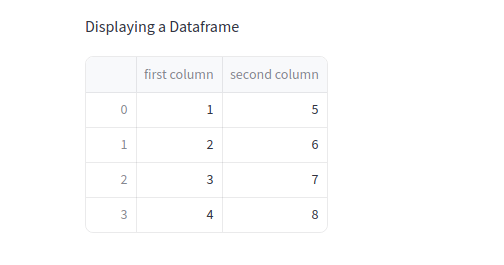
2. Affichage des DataFrames
import pandas as pd
# Creating a DataFrame
df = pd.DataFrame({
"first column": [1, 2, 3, 4],
"second column": [5, 6, 7, 8]
})
# Display the DataFrame
st.write("Displaying a DataFrame")
st.write(df)
3. Visualiser des données avec des graphiques
import numpy as np
# Generating random data
chart_data = pd.DataFrame(
np.random.randn(20, 4), columns=['a', 'b', 'c', 'd']
)
# Display the line chart
st.line_chart(chart_data)

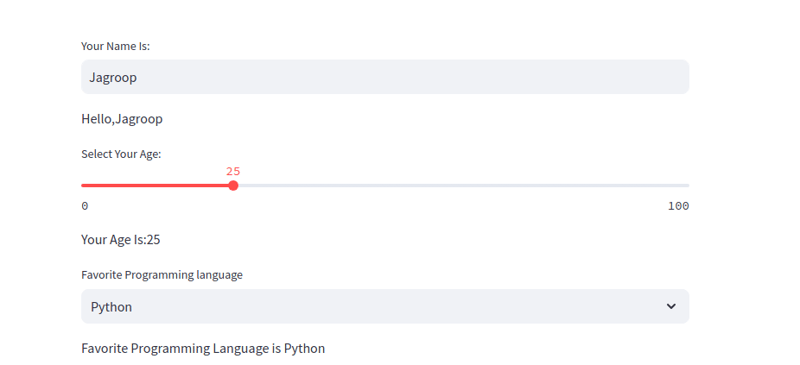
4. Interaction utilisateur : saisie de texte, curseurs et zones de sélection
Streamlit active des widgets interactifs tels que des saisies de texte, des curseurs et des zones de sélection qui se mettent à jour dynamiquement en fonction des entrées de l'utilisateur.
# Text input
name = st.text_input("Your Name Is:")
if name:
st.write(f'Hello, {name}')
# Slider
age = st.slider("Select Your Age:", 0, 100, 25)
if age:
st.write(f'Your Age Is: {age}')
# Select Box
choices = ["Python", "Java", "Javascript"]
lang = st.selectbox('Favorite Programming Language', choices)
if lang:
st.write(f'Favorite Programming Language is {lang}')
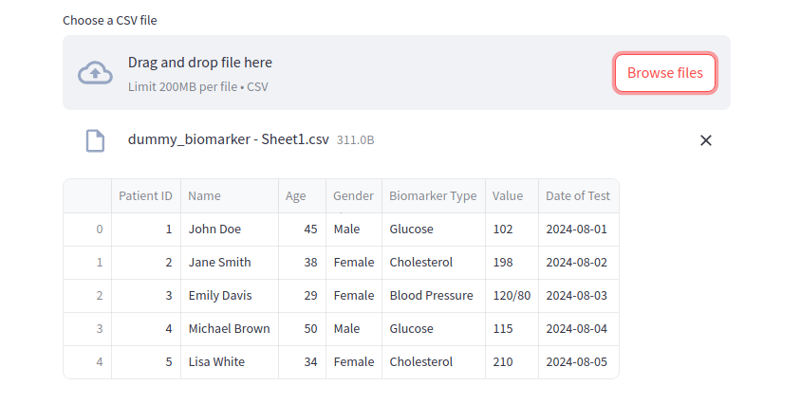
5. Téléchargement de fichiers
Vous pouvez autoriser les utilisateurs à télécharger des fichiers et à afficher leur contenu de manière dynamique dans votre application Streamlit :
# File uploader for CSV files
file = st.file_uploader('Choose a CSV file', 'csv')
if file:
data = pd.read_csv(file)
st.write(data)
Maintenant que vous connaissez les bases, passons à la création d'un projet d'apprentissage automatique. Nous utiliserons le célèbre jeu de données Iris et construirons un modèle de classification simple en utilisant RandomForestClassifier de scikit-learn.
Structure du projet :
1. Installer les dépendances nécessaires
Tout d’abord, installons les bibliothèques nécessaires :
pip install streamlit scikit-learn numpy pandas
2. Importer des bibliothèques et charger des données
Importons les bibliothèques nécessaires et chargeons l'ensemble de données Iris :
import streamlit as st
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.ensemble import RandomForestClassifier
# Cache data for efficient loading
@st.cache_data
def load_data():
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df["species"] = iris.target
return df, iris.target_names
df, target_name = load_data()
3. Former le modèle d'apprentissage automatique
Une fois que nous aurons les données, nous entraînerons un RandomForestClassifier pour prédire l'espèce d'une fleur en fonction de ses caractéristiques :
# Train RandomForestClassifier model = RandomForestClassifier() model.fit(df.iloc[:, :-1], df["species"])
4. Création de l'interface d'entrée
Nous allons maintenant créer des curseurs dans la barre latérale pour permettre aux utilisateurs de saisir des fonctionnalités permettant de faire des prédictions :
# Sidebar for user input
st.sidebar.title("Input Features")
sepal_length = st.sidebar.slider("Sepal length", float(df['sepal length (cm)'].min()), float(df['sepal length (cm)'].max()))
sepal_width = st.sidebar.slider("Sepal width", float(df['sepal width (cm)'].min()), float(df['sepal width (cm)'].max()))
petal_length = st.sidebar.slider("Petal length", float(df['petal length (cm)'].min()), float(df['petal length (cm)'].max()))
petal_width = st.sidebar.slider("Petal width", float(df['petal width (cm)'].min()), float(df['petal width (cm)'].max()))
5. Prédire les espèces
Après avoir obtenu les entrées de l'utilisateur, nous ferons une prédiction à l'aide du modèle entraîné :
# Prepare the input data
input_data = [[sepal_length, sepal_width, petal_length, petal_width]]
# Prediction
prediction = model.predict(input_data)
prediction_species = target_name[prediction[0]]
# Display the prediction
st.write("Prediction:")
st.write(f'Predicted species is {prediction_species}')
Cela ressemblera à :


Enfin,Streamlit facilite incroyablement la création et le déploiement d'une interface Web d'apprentissage automatique avec un minimum d'effort. ? En quelques lignes de code, nous avons construit une application interactive ? qui permet aux utilisateurs de saisir des caractéristiques et de prédire l'espèce d'une fleur ? en utilisant un modèle d’apprentissage automatique. ??
Bon codage ! ?
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelle est la différence entre éclipse et idée ?
Quelle est la différence entre éclipse et idée ?
 Comment fermer le démarrage sécurisé
Comment fermer le démarrage sécurisé
 La différence entre le sommeil et l'hibernation Win10
La différence entre le sommeil et l'hibernation Win10
 Construisez votre propre serveur git
Construisez votre propre serveur git
 je dis
je dis
 Logiciel de création de site internet
Logiciel de création de site internet
 Win11 ignore le didacticiel pour se connecter au compte Microsoft
Win11 ignore le didacticiel pour se connecter au compte Microsoft
 Caractéristiques de l'arithmétique du complément à deux
Caractéristiques de l'arithmétique du complément à deux








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



