

 interface Web
js tutoriel
Libérez MongoDB : pourquoi la pagination basée sur le curseur surpasse à chaque fois la pagination basée sur le décalage !
interface Web
js tutoriel
Libérez MongoDB : pourquoi la pagination basée sur le curseur surpasse à chaque fois la pagination basée sur le décalage !
Libérez MongoDB : pourquoi la pagination basée sur le curseur surpasse à chaque fois la pagination basée sur le décalage !

La
La pagination est un élément essentiel de toute opération de base de données lorsqu'il s'agit de grands ensembles de données. Il vous permet de diviser les données en morceaux gérables, ce qui facilite leur navigation, leur traitement et leur affichage. MongoDB propose deux méthodes de pagination courantes : basée sur le décalage et basée sur le curseur. Bien que les deux méthodes servent le même objectif, elles diffèrent considérablement en termes de performances et de convivialité, en particulier à mesure que l'ensemble de données grandit.
Plongeons dans les deux approches et voyons pourquoi la pagination basée sur le curseur surpasse souvent la pagination basée sur le décalage.
1. Pagination basée sur le décalage
La pagination basée sur le décalage est simple. Il récupère un nombre spécifique d'enregistrements à partir d'un décalage donné. Par exemple, la première page peut récupérer les enregistrements 0 à 9, la deuxième page, les enregistrements 10 à 19, et ainsi de suite.
Cependant, cette méthode présente un inconvénient important : à mesure que vous passez aux pages supérieures, la requête devient plus lente. En effet, la base de données doit ignorer les enregistrements des pages précédentes, ce qui implique de les parcourir.
Voici le code pour la pagination basée sur le décalage :
async function offset_based_pagination(params) {
const { page = 5, limit = 100 } = params;
const skip = (page - 1) * limit;
const results = await collection.find({}).skip(skip).limit(limit).toArray();
console.log(`Offset-based pagination (Page ${page}):`, results.length, "page", page, "skip", skip, "limit", limit);
}
2. Pagination basée sur le curseur
La pagination basée sur un curseur, également connue sous le nom de pagination par jeu de clés, repose sur un identifiant unique (par exemple, un identifiant ou un horodatage) pour paginer dans les enregistrements. Au lieu de sauter un certain nombre d'enregistrements, il utilise le dernier enregistrement récupéré comme point de référence pour récupérer l'ensemble suivant.
Cette approche est plus efficace car elle évite d'avoir à scanner les enregistrements avant la page en cours. Par conséquent, le temps de requête reste cohérent, quelle que soit la profondeur à laquelle vous pénétrez dans l'ensemble de données.
Voici le code pour la pagination basée sur le curseur :
async function cursor_based_pagination(params) {
const { lastDocumentId, limit = 100 } = params;
const query = lastDocumentId ? { documentId: { $gt: lastDocumentId } } : {};
const results = await collection
.find(query)
.sort({ documentId: 1 })
.limit(limit)
.toArray();
console.log("Cursor-based pagination:", results.length);
}
Dans cet exemple, lastDocumentId est l'ID du dernier document de la page précédente. Lors de la requête pour la page suivante, la base de données récupère les documents avec un ID supérieur à cette valeur, garantissant une transition transparente vers l'ensemble d'enregistrements suivant.
3. Comparaison des performances
Voyons comment ces deux méthodes fonctionnent avec un grand ensemble de données.
async function testMongoDB() {
console.time("MongoDB Insert Time:");
await insertMongoDBRecords();
console.timeEnd("MongoDB Insert Time:");
// Create an index on the documentId field
await collection.createIndex({ documentId: 1 });
console.log("Index created on documentId field");
console.time("Offset-based pagination Time:");
await offset_based_pagination({ page: 2, limit: 250000 });
console.timeEnd("Offset-based pagination Time:");
console.time("Cursor-based pagination Time:");
await cursor_based_pagination({ lastDocumentId: 170000, limit: 250000 });
console.timeEnd("Cursor-based pagination Time:");
await client.close();
}
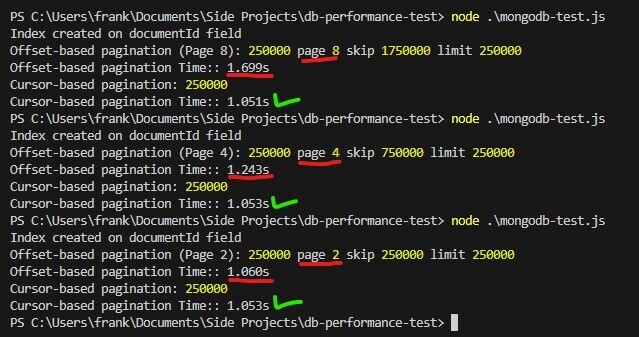
Dans le test de performances, vous remarquerez que la pagination basée sur le décalage prend plus de temps à mesure que le numéro de page augmente, alors que le curseur La pagination basée sur reste cohérente, ce qui en fait le meilleur choix pour les grands ensembles de données. Cet exemple démontre également la puissance de l’indexation. Essayez de supprimer l'index, puis voyez également le résultat !
Pourquoi l'indexation est importante
Sans index, MongoDB devrait effectuer une analyse de collection, ce qui signifie qu'il doit examiner chaque document de la collection pour trouver les données pertinentes. Ceci est inefficace, surtout lorsque votre ensemble de données augmente. Les index permettent à MongoDB de trouver efficacement les documents qui correspondent à vos conditions de requête, accélérant ainsi considérablement les performances des requêtes.
Dans le contexte de la pagination basée sur le curseur, l'index garantit que la récupération de l'ensemble de documents suivant (basé sur documentId) est rapide et ne se dégrade pas en termes de performances à mesure que d'autres documents sont ajoutés à la collection.
Conclusion
Bien que la pagination basée sur l'offset soit facile à mettre en œuvre, elle peut devenir inefficace avec de grands ensembles de données en raison de la nécessité de parcourir les enregistrements. La pagination basée sur le curseur, en revanche, fournit une solution plus évolutive, garantissant des performances cohérentes quelle que soit la taille de l'ensemble de données. Si vous travaillez avec de grandes collections dans MongoDB, cela vaut la peine d'envisager une pagination basée sur le curseur pour une expérience plus fluide et plus rapide.
Voici index.js complet à exécuter localement :
const { MongoClient } = require("mongodb");
const uri = "mongodb://localhost:27017";
const client = new MongoClient(uri);
client.connect();
const db = client.db("testdb");
const collection = db.collection("testCollection");
async function insertMongoDBRecords() {
try {
let bulkOps = [];
for (let i = 0; i < 2000000; i++) {
bulkOps.push({
insertOne: {
documentId: i,
name: `Record-${i}`,
value: Math.random() * 1000,
},
});
// Execute every 10000 operations and reinitialize
if (bulkOps.length === 10000) {
await collection.bulkWrite(bulkOps);
bulkOps = [];
}
}
if (bulkOps.length > 0) {
await collection.bulkWrite(bulkOps);
console.log("? Inserted records till now -> ", bulkOps.length);
}
console.log("MongoDB Insertion Completed");
} catch (err) {
console.error("Error in inserting records", err);
}
}
async function offset_based_pagination(params) {
const { page = 5, limit = 100 } = params;
const skip = (page - 1) * limit;
const results = await collection.find({}).skip(skip).limit(limit).toArray();
console.log(`Offset-based pagination (Page ${page}):`, results.length, "page", page, "skip", skip, "limit", limit);
}
async function cursor_based_pagination(params) {
const { lastDocumentId, limit = 100 } = params;
const query = lastDocumentId ? { documentId: { $gt: lastDocumentId } } : {};
const results = await collection
.find(query)
.sort({ documentId: 1 })
.limit(limit)
.toArray();
console.log("Cursor-based pagination:", results.length);
}
async function testMongoDB() {
console.time("MongoDB Insert Time:");
await insertMongoDBRecords();
console.timeEnd("MongoDB Insert Time:");
// Create an index on the documentId field
await collection.createIndex({ documentId: 1 });
console.log("Index created on documentId field");
console.time("Offset-based pagination Time:");
await offset_based_pagination({ page: 2, limit: 250000 });
console.timeEnd("Offset-based pagination Time:");
console.time("Cursor-based pagination Time:");
await cursor_based_pagination({ lastDocumentId: 170000, limit: 250000 });
console.timeEnd("Cursor-based pagination Time:");
await client.close();
}
testMongoDB();
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!

Outils d'IA chauds

Undress AI Tool
Images de déshabillage gratuites

Undresser.AI Undress
Application basée sur l'IA pour créer des photos de nu réalistes

AI Clothes Remover
Outil d'IA en ligne pour supprimer les vêtements des photos.

Clothoff.io
Dissolvant de vêtements AI

Video Face Swap
Échangez les visages dans n'importe quelle vidéo sans effort grâce à notre outil d'échange de visage AI entièrement gratuit !

Article chaud
Outils chauds

Bloc-notes++7.3.1
Éditeur de code facile à utiliser et gratuit

SublimeText3 version chinoise
Version chinoise, très simple à utiliser

Envoyer Studio 13.0.1
Puissant environnement de développement intégré PHP

Dreamweaver CS6
Outils de développement Web visuel

SublimeText3 version Mac
Logiciel d'édition de code au niveau de Dieu (SublimeText3)
Sujets chauds
 1793
1793
 16
1735
56
1587
29
267
587
16
1735
56
1587
29
267
587

 Comment travailler avec les dates et les heures de JS?
Jul 01, 2025 am 01:27 AM
Comment travailler avec les dates et les heures de JS?
Jul 01, 2025 am 01:27 AM
Les points suivants doivent être notés lors du traitement des dates et du temps dans JavaScript: 1. Il existe de nombreuses façons de créer des objets de date. Il est recommandé d'utiliser les chaînes de format ISO pour assurer la compatibilité; 2. Get and définir des informations de temps peuvent être obtenues et définir des méthodes, et notez que le mois commence à partir de 0; 3. Les dates de mise en forme manuelle nécessitent des chaînes et les bibliothèques tierces peuvent également être utilisées; 4. Il est recommandé d'utiliser des bibliothèques qui prennent en charge les fuseaux horaires, comme Luxon. La maîtrise de ces points clés peut éviter efficacement les erreurs courantes.
 Pourquoi devriez-vous placer des balises au bas du ?
Jul 02, 2025 am 01:22 AM
Pourquoi devriez-vous placer des balises au bas du ?
Jul 02, 2025 am 01:22 AM
PlacertagsatthebottomofablogPostorwebPageSerSpracticalPurpossForseo, userexperience, anddesign.1.ithelpswithseobyallowingsechingenginestoaccesskeyword-elevanttagswithoutcluteringtheaincontent..itimproveserexperceenceegmentyepingthefocusonThearrlUl
 Qu'est-ce que l'événement bouillonne et capture dans le DOM?
Jul 02, 2025 am 01:19 AM
Qu'est-ce que l'événement bouillonne et capture dans le DOM?
Jul 02, 2025 am 01:19 AM
La capture d'événements et la bulle sont deux étapes de la propagation des événements dans DOM. La capture est de la couche supérieure à l'élément cible, et la bulle est de l'élément cible à la couche supérieure. 1. La capture de l'événement est implémentée en définissant le paramètre UseCapture d'AdveventListener sur true; 2. Événement Bubble est le comportement par défaut, UseCapture est défini sur False ou Omise; 3. La propagation des événements peut être utilisée pour empêcher la propagation des événements; 4. Événement Bubbling prend en charge la délégation d'événements pour améliorer l'efficacité du traitement du contenu dynamique; 5. La capture peut être utilisée pour intercepter les événements à l'avance, telles que la journalisation ou le traitement des erreurs. La compréhension de ces deux phases aide à contrôler avec précision le calendrier et comment JavaScript répond aux opérations utilisateur.
 Comment pouvez-vous réduire la taille de la charge utile d'une application JavaScript?
Jun 26, 2025 am 12:54 AM
Comment pouvez-vous réduire la taille de la charge utile d'une application JavaScript?
Jun 26, 2025 am 12:54 AM
Si les applications JavaScript se chargent lentement et ont de mauvaises performances, le problème est que la charge utile est trop grande. Les solutions incluent: 1. Utilisez le fractionnement du code (codes-alliant), divisez le grand bundle en plusieurs petits fichiers via react.lazy () ou construire des outils et le charger au besoin pour réduire le premier téléchargement; 2. Supprimez le code inutilisé (Treeshaking), utilisez le mécanisme du module ES6 pour effacer le "code mort" pour vous assurer que les bibliothèques introduites prennent en charge cette fonction; 3. Comprimer et fusionner les fichiers de ressources, permettre à GZIP / Brotli et Terser de compresser JS, de fusionner raisonnablement des fichiers et d'optimiser les ressources statiques; 4. Remplacez les dépendances lourdes et choisissez des bibliothèques légères telles que Day.js et récupérer
 Un Roundup définitif JS sur les modules JavaScript: modules ES vs CommonJS
Jul 02, 2025 am 01:28 AM
Un Roundup définitif JS sur les modules JavaScript: modules ES vs CommonJS
Jul 02, 2025 am 01:28 AM
La principale différence entre le module ES et CommonJS est la méthode de chargement et le scénario d'utilisation. 1.ComMonJS est chargé de manière synchrone, adapté à l'environnement côté serveur Node.js; 2. Le module ES est chargé de manière asynchrone, adapté aux environnements réseau tels que les navigateurs; 3. Syntaxe, le module ES utilise l'importation / exportation et doit être situé dans la portée de niveau supérieur, tandis que CommonJS utilise require / module.exports, qui peut être appelé dynamiquement au moment de l'exécution; 4.Commonjs est largement utilisé dans les anciennes versions de Node.js et des bibliothèques qui en comptent telles que Express, tandis que les modules ES conviennent aux frameworks frontaux modernes et Node.jsv14; 5. Bien qu'il puisse être mélangé, il peut facilement causer des problèmes.
 Comment faire une demande HTTP dans Node.js?
Jul 13, 2025 am 02:18 AM
Comment faire une demande HTTP dans Node.js?
Jul 13, 2025 am 02:18 AM
Il existe trois façons courantes d'initier des demandes HTTP dans Node.js: utilisez des modules intégrés, Axios et Node-Fetch. 1. Utilisez le module HTTP / HTTPS intégré sans dépendances, ce qui convient aux scénarios de base, mais nécessite un traitement manuel de la couture des données et de la surveillance des erreurs, tels que l'utilisation de https.get () pour obtenir des données ou envoyer des demandes de post via .write (); 2.AXIOS est une bibliothèque tierce basée sur la promesse. Il a une syntaxe concise et des fonctions puissantes, prend en charge l'async / attendre, la conversion JSON automatique, l'intercepteur, etc. Il est recommandé de simplifier les opérations de demande asynchrones; 3.Node-Fetch fournit un style similaire à la récupération du navigateur, basé sur la promesse et la syntaxe simple
 Comment fonctionne la collection Garbage en JavaScript?
Jul 04, 2025 am 12:42 AM
Comment fonctionne la collection Garbage en JavaScript?
Jul 04, 2025 am 12:42 AM
Le mécanisme de collecte des ordures de JavaScript gère automatiquement la mémoire via un algorithme de compensation de balises pour réduire le risque de fuite de mémoire. Le moteur traverse et marque l'objet actif de l'objet racine, et non marqué est traité comme des ordures et effacés. Par exemple, lorsque l'objet n'est plus référencé (comme la définition de la variable sur NULL), il sera publié lors de la prochaine série de recyclage. Les causes courantes des fuites de mémoire comprennent: ① des minuteries ou des auditeurs d'événements non diffusés; ② Références aux variables externes dans les fermetures; ③ Les variables globales continuent de contenir une grande quantité de données. Le moteur V8 optimise l'efficacité du recyclage à travers des stratégies telles que le recyclage générationnel, le marquage incrémentiel, le recyclage parallèle / simultané, et réduit le temps de blocage principal. Au cours du développement, les références globales inutiles doivent être évitées et les associations d'objets doivent être rapidement décorées pour améliorer les performances et la stabilité.
 var vs let vs const: un explicateur de rond JS rapide
Jul 02, 2025 am 01:18 AM
var vs let vs const: un explicateur de rond JS rapide
Jul 02, 2025 am 01:18 AM
La différence entre VAR, LET et const est la portée, la promotion et les déclarations répétées. 1.Var est la portée de la fonction, avec une promotion variable, permettant des déclarations répétées; 2.Lette est la portée au niveau du bloc, avec des zones mortes temporaires, et les déclarations répétées ne sont pas autorisées; 3.Const est également la portée au niveau du bloc et doit être attribuée immédiatement et ne peut pas être réaffectée, mais la valeur interne du type de référence peut être modifiée. Utilisez d'abord Const, utilisez LET lors de la modification des variables et évitez d'utiliser VAR.
