La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Les modèles linguistiques à grande échelle représentés par GPT annoncent l'aube de l'intelligence artificielle générale dans l'espace cognitif numérique. Ces modèles démontrent de puissantes capacités de compréhension et de raisonnement en traitant et en générant du langage naturel, et ont montré de larges perspectives d'application dans de multiples domaines. Qu'il s'agisse de génération de contenu, de service client automatisé, d'outils de productivité, de recherche par IA ou dans des domaines tels que l'éducation et les soins médicaux, les modèles linguistiques à grande échelle favorisent constamment l'avancement de la technologie et la vulgarisation des applications.
Cependant, pour promouvoir l'intelligence artificielle générale afin d'explorer le monde physique, la première étape consiste à résoudre le problème de la compréhension visuelle, c'est-à-dire la compréhension multimodale des grands modèles. La compréhension multimodale permet à l’IA de mieux comprendre le monde et d’interagir avec lui en acquérant et en traitant des informations par l’intermédiaire de plusieurs sens, tout comme les humains. Les avancées dans ce domaine permettront à l’intelligence artificielle de progresser davantage en robotique, en conduite autonome, etc., et de véritablement passer du monde numérique au monde physique.
GPT-4V a été lancé en juin de l'année dernière, mais par rapport aux grands modèles de langage, le développement de modèles de compréhension multimodaux semble être plus lent, en particulier dans le domaine chinois. De plus, contrairement au parcours technique et à la sélection de grands modèles de langage qui sont relativement certains, l'industrie n'est pas encore parvenue à un consensus complet sur l'architecture et la sélection des méthodes de formation pour les modèles multimodaux. # dollars dollars dollars dollars dollars dollars Compréhension de pointe des grands modèles. Le modèle a été innovant et profondément optimisé en termes d'architecture, de méthodes de formation et de traitement des données, améliorant considérablement ses performances et prenant en charge la compréhension d'images avec n'importe quel rapport d'aspect et jusqu'à une résolution de 7K. Contrairement à la plupart des modèles multimodaux qui sont principalement adaptés à des benchmarks open source, le modèle multimodal hybride de Tencent accorde davantage d'attention à la polyvalence, à l'aspect pratique et à la fiabilité du modèle et dispose de riches capacités de compréhension de scènes multimodales. Dans l'évaluation de référence SuperCLUE-V des grands modèles multimodaux chinois récemment publiée (août 2024), Tencent Hunyuan s'est classé premier dans le pays, surpassant plusieurs modèles traditionnels à source fermée.

Introduction à la méthode : architecture MoE
Le grand modèle de langage mixte de Tencent est le premier en Chine à adopter l'architecture du modèle expert mixte (MoE). Les performances globales du modèle sont 50 % supérieures à celles du modèle expert mixte (MoE). génération précédente et certaines capacités chinoises. Il s'est associé à GPT-4o et a considérablement amélioré ses performances pour répondre aux questions « actuelles », ainsi qu'en mathématiques, raisonnement et autres capacités. Dès le début de cette année, Tencent Hunyuan a appliqué ce modèle à Tencent Yuanbao.
Tencent Hunyuan estime que l'architecture MoE qui peut résoudre un grand nombre de tâches générales est également le meilleur choix pour les scénarios de compréhension multimodaux. Le MoE peut être mieux compatible avec un plus grand nombre de modalités et de tâches, garantissant que les différentes modalités et tâches se renforcent mutuellement plutôt que de se concurrencer.
S'appuyant sur les capacités du grand modèle de langage de Tencent Hunyuan, Tencent Hunyuan a lancé un grand modèle de compréhension multimodal basé sur l'architecture MoE. Il a apporté des innovations et des optimisations en profondeur en termes d'architecture, de méthodes de formation et de données. Traitement, et ses performances ont été considérablement améliorées. Il s’agit également du premier grand modèle multimodal basé sur l’architecture MoE en Chine.
模 Diagramme schématique de l'architecture du modèle multimodal à éléments mixtes Tencent
Simple et à grande échelle
En plus d'utiliser l'architecture MOE, la conception du modèle multimode à éléments mixtes Tencent également suit des principes simples et raisonnables d'évolutivité :
Prend en charge les résolutions arbitraires natives : par rapport aux méthodes traditionnelles de résolution fixe ou de sous-graphe découpé, le modèle multimodal hybride de Tencent peut traiter des images natives de n'importe quelle résolution. modèle multimodal pour prendre en charge la compréhension des images avec des résolutions supérieures à 7K et n'importe quel rapport hauteur/largeur (par exemple 16:1, voir l'exemple ci-dessous).
-
Utilisation d'un simple adaptateur MLP : par rapport au précédent adaptateur Q-former grand public, l'adaptateur MLP a moins de perte lors de la transmission des informations.
-
Cette conception simple facilite l'expansion et la mise à l'échelle des modèles et des données.
SuperClue-V se classe premier dans la liste nationale
En août 2024, SuperCLUE a publié pour la première fois la liste d'évaluation de la compréhension multimodale - SuperClue-V.
Le benchmark SuperCLUE-V comprend deux directions générales : les capacités de base et les capacités d'application. Il évalue les grands modèles multimodaux sous forme de questions ouvertes, comprenant 8 dimensions de premier niveau et 30 dimensions de deuxième niveau.
Dans cette évaluation, le système de compréhension multimodale Hunyuan, hunyuan-vision, a obtenu un score de 71,95, juste derrière GPT-4o. En termes d'applications multimodales, hunyuan-vision devance Claude3.5-Sonnet et Gemini-1.5-Pro.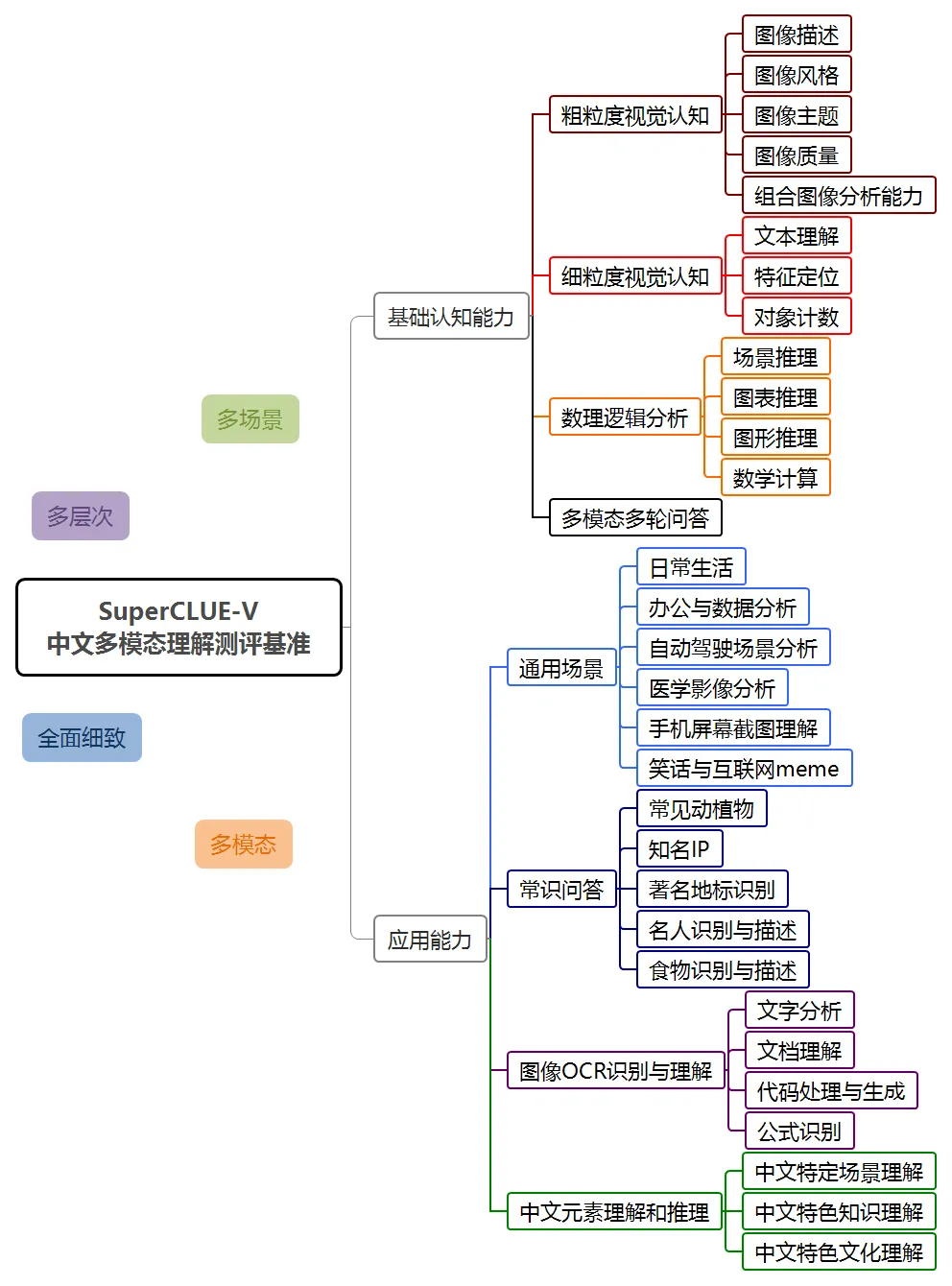
Il convient de noter que les évaluations multimodales précédentes dans l'industrie se concentraient principalement sur la maîtrise de l'anglais et que la plupart des questions d'évaluation étaient des questions à choix multiples ou des questions vrai-faux. L’évaluation SuperCLUE-V se concentre davantage sur l’évaluation des compétences en chinois et se concentre sur les problèmes réels des utilisateurs. De plus, puisqu’il s’agit de la première version, le surapprentissage ne s’est pas encore produit.
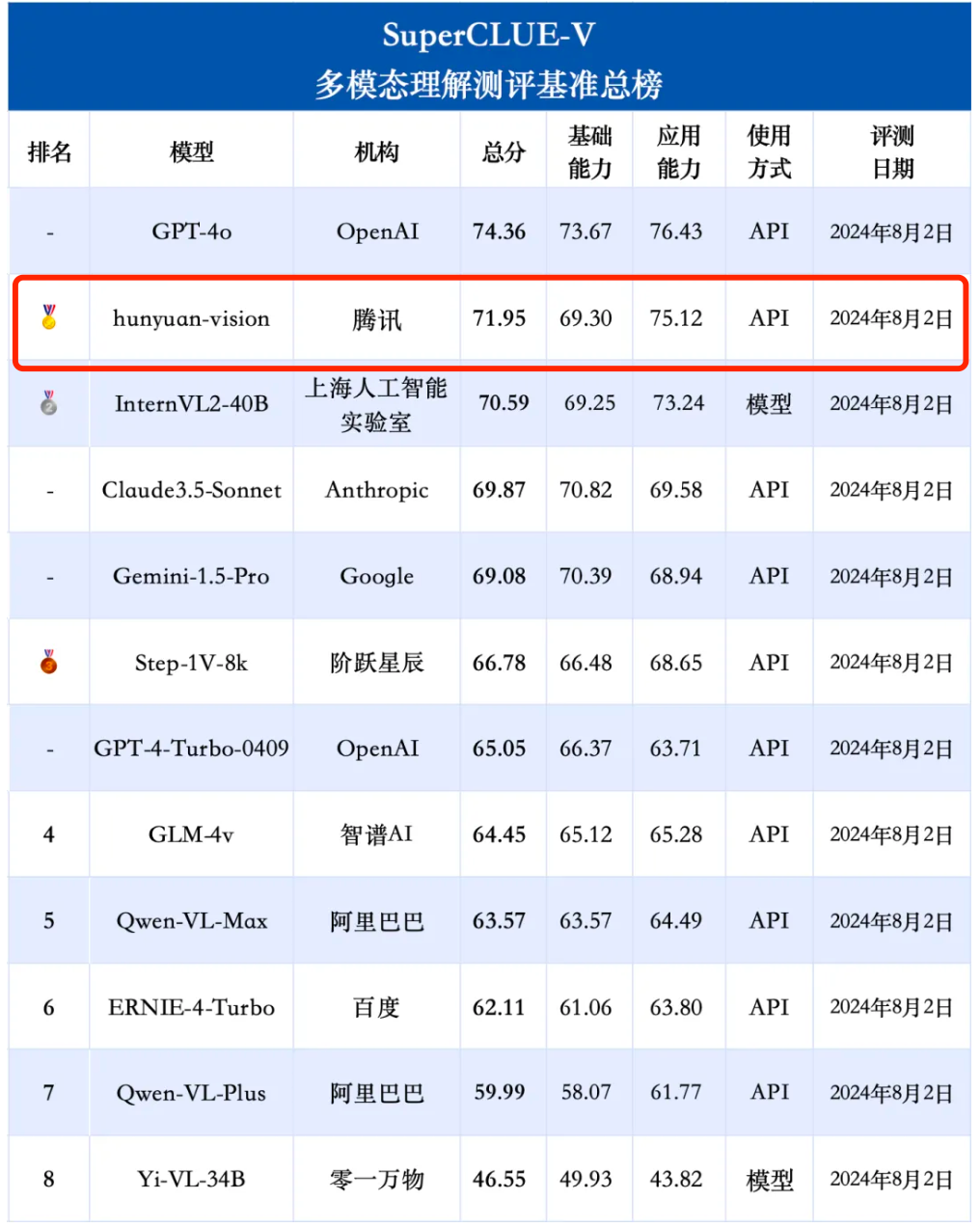
Tencent Hunyuan Graphics and Text Large Model montre de bonnes performances dans plusieurs dimensions telles que les scènes générales, la reconnaissance et la compréhension OCR d'images, ainsi que la compréhension et le raisonnement des éléments chinois, et reflète également le potentiel du modèle dans les applications futures. .
 Destiné aux scénarios d'application généraux
Destiné aux scénarios d'application généraux
Le modèle de compréhension multimodale à éléments mixtes est optimisé pour les scénarios généraux et les applications massives, et a accumulé des dizaines de millions de corpus de questions et réponses connexes, couvrant les bases compréhension d'images, création de contenu, il peut être utilisé dans de nombreux scénarios tels que l'analyse du raisonnement, les questions et réponses de connaissances, l'analyse de documents OCR et la réponse au sujet. Voici quelques exemples d'applications typiques.
Voici des exemples plus typiques :
Convertir une image en tableau texte :
Expliquer un morceau de code :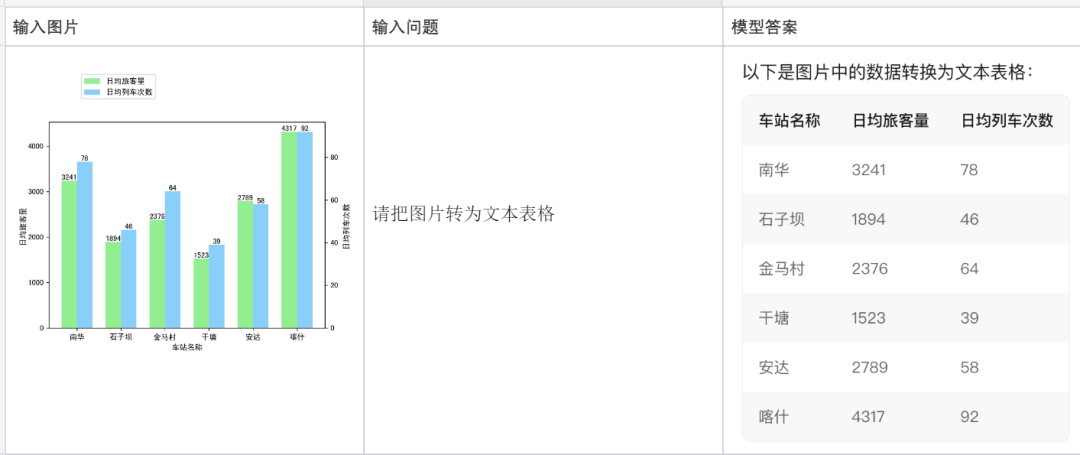
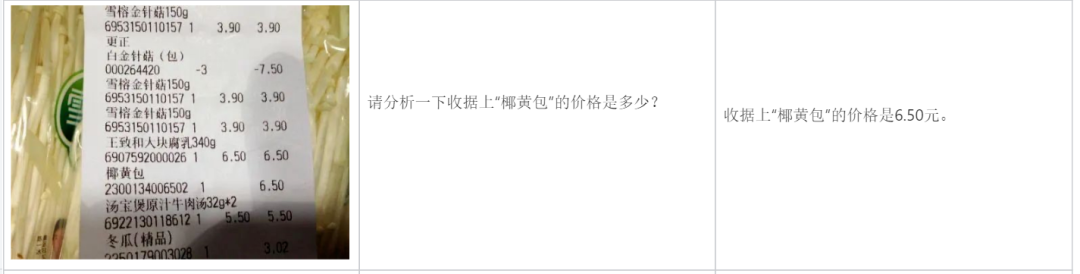
Analyser une facture :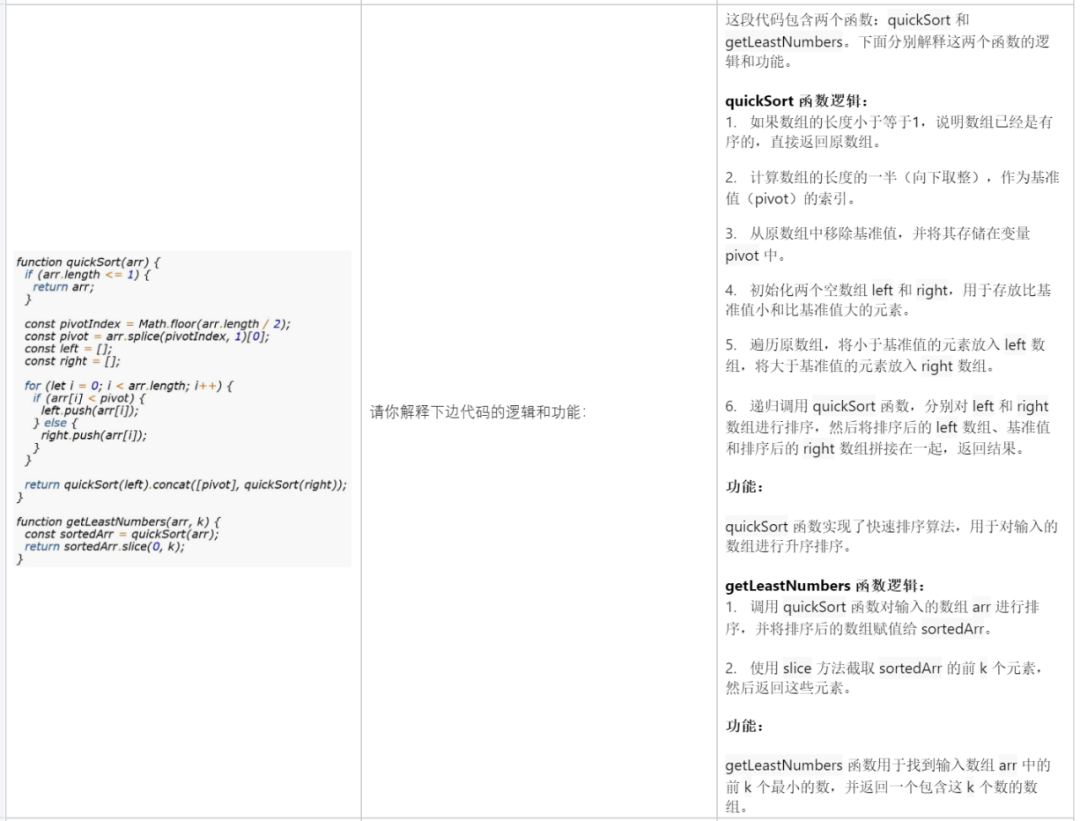
Description Contenu de l'image :
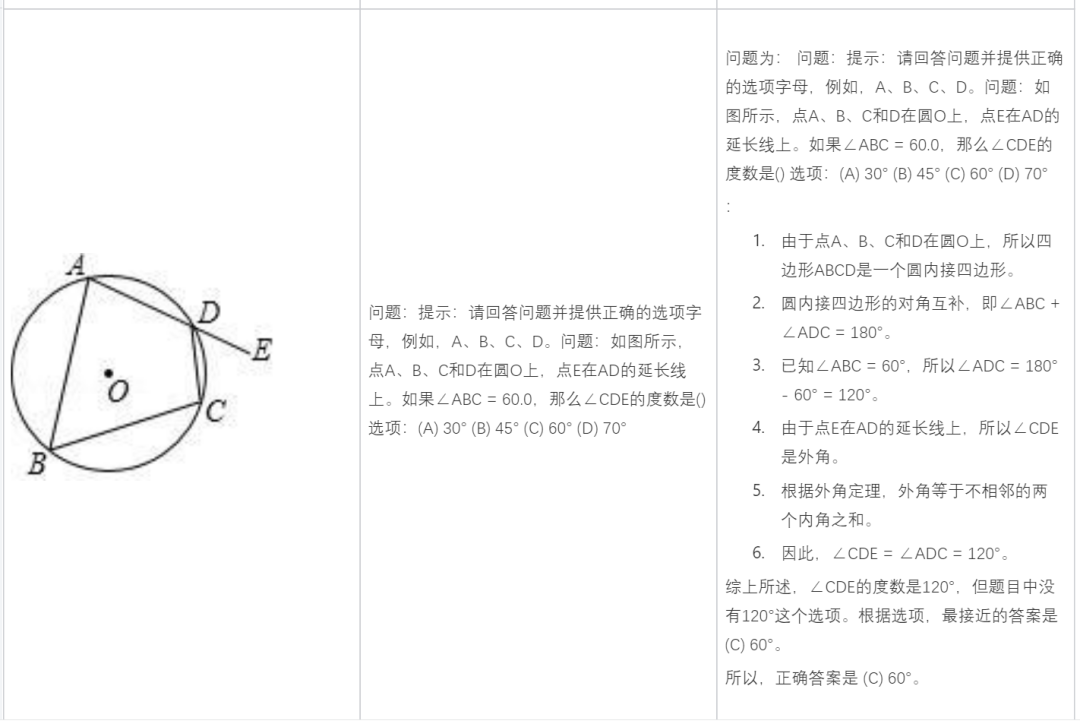
Résoudre des problèmes de mathématiques :

Analyser en fonction du contenu de l'image :
Vous aider à rédiger une copie :

À l'heure actuelle, le grand modèle de compréhension multimodale Hunyuan de Tencent a été lancé dans le produit d'assistant d'IA Tencent Yuanbao et est ouvert aux entreprises et aux développeurs individuels via Tencent Cloud.
Adresse Tencent Yuanbao : https://yuanbao.tencent.com/chat
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




 utilisation de la fonction heure locale
utilisation de la fonction heure locale Que signifie l'intervalle ?
Que signifie l'intervalle ? le bios ne peut pas détecter le disque SSD
le bios ne peut pas détecter le disque SSD Quel est le format du document ?
Quel est le format du document ? tutoriel vb.net
tutoriel vb.net Quelle est la différence entre JD International auto-exploité et JD auto-opéré
Quelle est la différence entre JD International auto-exploité et JD auto-opéré Utilisation de la méthode jQuery hover()
Utilisation de la méthode jQuery hover() Caractéristiques des bases de données relationnelles
Caractéristiques des bases de données relationnelles




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



