


Lorsque vous explorez des sites Web avec Scrapy, vous rencontrerez rapidement toutes sortes de scénarios qui vous obligent à faire preuve de créativité ou à interagir avec la page que vous essayez de gratter. L'un de ces scénarios est celui où vous devez explorer une page à défilement infini. Ce type de page de site Web charge plus de contenu à mesure que vous faites défiler la page, comme un flux de médias sociaux.
Il existe certainement plusieurs façons d'explorer ce type de pages. Une façon dont j'ai récemment abordé ce problème était de continuer à faire défiler jusqu'à ce que la longueur de la page cesse d'augmenter (c'est-à-dire faire défiler vers le bas). Cet article décrit ce processus.
Cet article suppose que vous avez un projet Scrapy configuré, en cours d'exécution et un Spider que vous pouvez modifier et exécuter.
Cette intégration utilise le plugin scrapy-playwright pour intégrer Playwright for Python avec Scrapy. Playwright est une bibliothèque d'automatisation de navigateur sans tête utilisée pour interagir avec les pages Web et extraire des données.
J'utilise uv pour l'installation et la gestion des packages Python.
Ensuite, j'utilise des environnements virtuels directement depuis uv avec :
uv venv source .venv/bin/activate
Installez le plugin scrapy-playwright et Playwright avec la commande suivante dans votre environnement virtuel :
uv pip install scrapy-playwright
Installez le navigateur que vous souhaitez utiliser avec Playwright. Par exemple, pour installer Chromium, vous pouvez exécuter la commande suivante :
playwright install chromium
Vous pouvez également installer d'autres navigateurs comme Firefox si nécessaire.
Remarque : Le code Scrapy ci-dessous et l'intégration de Playwright n'ont été testés qu'avec Chromium.
Mettez à jour le fichier settings.py ou l'attribut custom_settings dans l'araignée pour inclure les paramètres DOWNLOAD_HANDLERS et PLAYWRIGHT_LAUNCH_OPTIONS.
# settings.py
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
DOWNLOAD_HANDLERS = {
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
}
PLAYWRIGHT_LAUNCH_OPTIONS = {
# optional for CORS issues
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
# optional for debugging
"headless": False,
},
Pour PLAYWRIGHT_LAUNCH_OPTIONS, vous pouvez définir l'option sans tête sur False pour ouvrir l'instance du navigateur et regarder le processus s'exécuter. C'est bon pour le débogage et la construction du grattoir initial.
Je transmets les arguments supplémentaires pour désactiver la sécurité Web et isoler les origines. Ceci est utile lorsque vous explorez des sites présentant des problèmes CORS.
Par exemple, il peut y avoir des situations où les ressources JavaScript requises ne sont pas chargées ou où les requêtes réseau ne sont pas effectuées à cause de CORS. Vous pouvez isoler cela plus rapidement en vérifiant les erreurs dans la console du navigateur si certaines actions de la page (comme cliquer sur un bouton) ne fonctionnent pas comme prévu mais que tout le reste fonctionne.
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
}
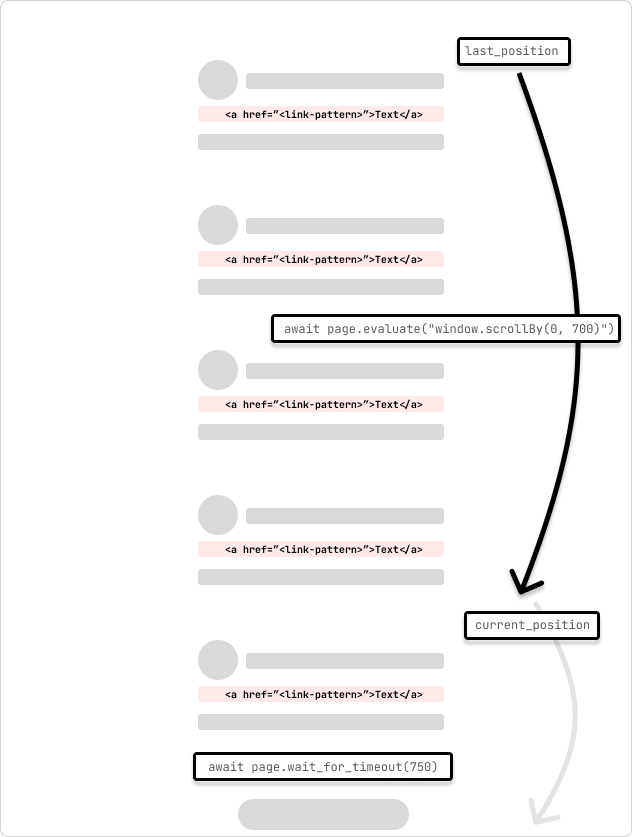
Ceci est un exemple d'araignée qui explore une page à défilement infini. L'araignée fait défiler la page de 700 pixels et attend 750 ms pour que la requête soit terminée. L'araignée continuera à défiler jusqu'à ce qu'elle atteigne le bas de la page indiqué par la position de défilement qui ne change pas au fur et à mesure qu'elle parcourt la boucle.
Je modifie les paramètres dans le spider lui-même en utilisant custom_settings pour conserver les paramètres au même endroit. Vous pouvez également ajouter ces paramètres au fichier settings.py.
# /<project>/spiders/infinite_scroll.py
import scrapy
from scrapy.spiders import CrawlSpider
from scrapy.selector import Selector
class InfinitePageSpider(CrawlSpider):
"""
Spider to crawl an infinite scroll page
"""
name = "infinite_scroll"
allowed_domains = ["<allowed_domain>"]
start_urls = ["<start_url>"]
custom_settings = {
"TWISTED_REACTOR": "twisted.internet.asyncioreactor.AsyncioSelectorReactor",
"DOWNLOAD_HANDLERS": {
"https": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
"http": "scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler",
},
"PLAYWRIGHT_LAUNCH_OPTIONS": {
"args": [
"--disable-web-security",
"--disable-features=IsolateOrigins,site-per-process",
],
"headless": False,
},
"LOG_LEVEL": "INFO",
}
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
async def parse(
self,
response,
):
page = response.meta["playwright_page"]
page.set_default_timeout(10000)
await page.wait_for_timeout(5000)
try:
last_position = await page.evaluate("window.scrollY")
while True:
# scroll by 700 while not at the bottom
await page.evaluate("window.scrollBy(0, 700)")
await page.wait_for_timeout(750) # wait for 750ms for the request to complete
current_position = await page.evaluate("window.scrollY")
if current_position == last_position:
print("Reached the bottom of the page.")
break
last_position = current_position
except Exception as error:
print(f"Error: {error}")
pass
print("Getting content")
content = await page.content()
print("Parsing content")
selector = Selector(text=content)
print("Extracting links")
links = selector.xpath("//a[contains(@href, '/<link-pattern>/')]//@href").getall()
print(f"Found {len(links)} links...")
print("Yielding links")
for link in links:
yield {"link": link}
Une chose que j'ai apprise est qu'il n'y a pas deux pages ou deux sites identiques, vous devrez donc peut-être ajuster la quantité de défilement et le temps d'attente pour tenir compte de la page ainsi que de toute latence dans les allers-retours du réseau pour les requêtes. complet. Vous pouvez ajuster cela de manière dynamique par programme en vérifiant la position de défilement et le temps nécessaire à l'exécution de la demande.
Au chargement de la page, j'attends un peu plus longtemps que les ressources se chargent et que la page s'affiche. La page Playwright est transmise à la méthode de rappel Parse dans l'objet Response.meta. Ceci est utilisé pour interagir avec la page et faire défiler la page. Ceci est spécifié dans les arguments scrapy.Request avec les options playwright=True et playwright_include_page=True.
def start_requests(self):
yield scrapy.Request(
url=f"{self.start_urls[0]}",
meta=dict(
playwright=True,
playwright_include_page=True,
),
callback=self.parse,
)
Cette araignée fera défiler la page avec page.evaluate et la méthode JavaScript scrollBy() de 700 pixels, puis attendra 750 ms pour que la requête se termine. Ensuite, le contenu de la page Playwright est copié dans un sélecteur Scrapy et extrait les liens de la page. Les liens sont ensuite transmis au pipeline Scrapy pour poursuivre le traitement.
Dans les situations où les requêtes de page commencent à charger du contenu en double, vous pouvez ajouter une vérification pour voir si le contenu a déjà été chargé, puis sortir de la boucle. Ou, si vous avez une idée du nombre de chargements de scrolls, vous pouvez ajouter un compteur pour sortir de la boucle après un certain nombre de scrolls plus/moins un buffer.
It's also possible that the page may have an element that you can scroll to (i.e. "Load more") that will trigger the next set of content to load. You can use the page.evaluate method to scroll to the element and then click it to load the next set of content.
...
try:
while True:
button = page.locator('//button[contains(., "Load more")]')
await button.wait_for()
if not button:
print("No 'Load more' button found.")
break
is_disabled = await button.is_disabled()
if is_disabled:
print("Button is disabled.")
break
await button.scroll_into_view_if_needed()
await button.click()
await page.wait_for_timeout(750)
except Exception as error:
print(f"Error: {error}")
pass
...
This method is useful when you know the page has a button that will load the next set of content. You can also use this method to click on other elements that will trigger the next set of content to load. The scroll_into_view_if_needed method will scroll the button or element into view if it is not already visible on the page. This is one of those scenarios when you will want to double-check the page actions with headless=False to see if the button is being clicked and the content is being loaded as expected before running a full crawl.
Note: As mentioned above, confirm that the page assets(.js) are loading correctly and that the network requests are being made so that the button (or element) is mounted and clickable.
Web crawling is a case-by-case scenario and you will need to adjust the code to fit the page that you are trying to scrape. The above code is a starting point to get you going with crawling infinite scroll pages with Scrapy and Playwright.
Hopefully, this helps to get you unblocked! ?
Subscribe to get my latest content by email -> Newsletter
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



