


J'adore les émojis. Qui ne le fait pas ?
J'étais en train de peaufiner un post X très intellectuel il y a quelques jours quand j'ai réalisé quelque chose.
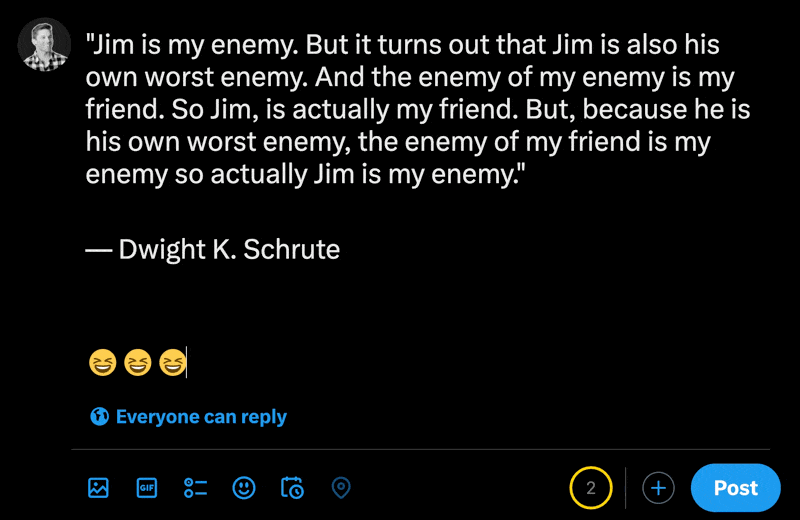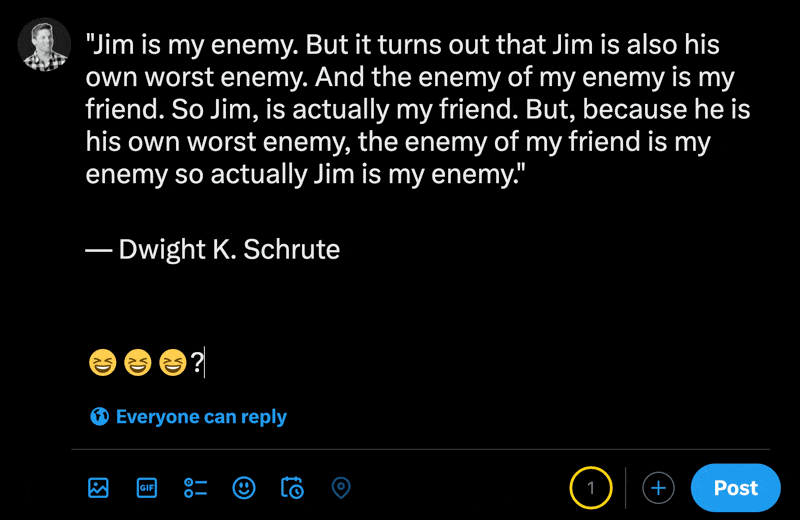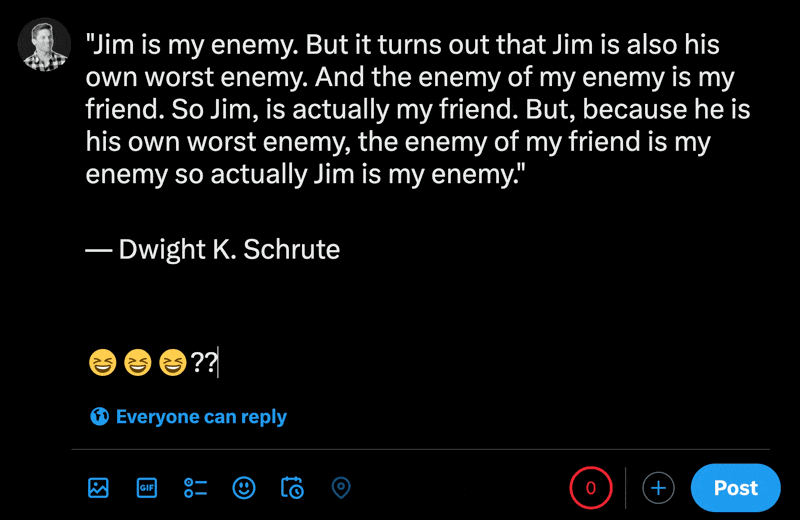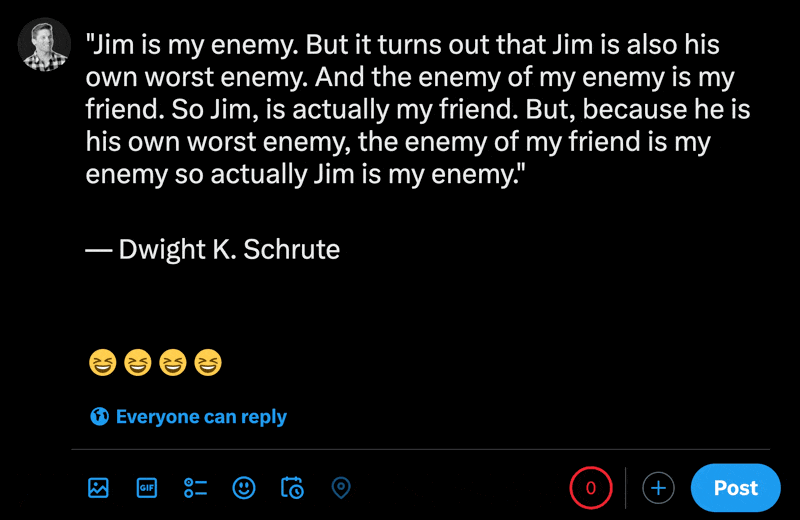
Lorsque vous tapez des emojis dans la nouvelle section de message de X, vous pouvez voir à quel point les caractères normaux comptent moins que les emojis.
Après une recherche rapide, j'ai découvert que cela avait quelque chose à voir avec la façon dont ils sont codés dans le système Unicode.
Essentiellement, les emojis sont constitués de plusieurs points de code, et la longueur ne compte que les points de code, pas les caractères.
Quelle que soit la raison pour laquelle cela se produit, j'ai pensé à tous les compteurs de texte que j'ai créés et au nombre qui existe dans le monde SaaS.
Les emojis ne reçoivent pas leur juste part ?.
Le simple fait de prendre la longueur de la chaîne n’est pas un décompte précis. Prenez, par exemple, quelque chose comme ceci :
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return text.length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
Il s'agit d'un simple composant React qui suit les caractères saisis dans un champ de texte. Il s'agit de l'implémentation la plus courante de cette fonctionnalité.
Mais le résultat nous pose le même problème que mon post X :

Vous pouvez utiliser un objet intégré appelé Intl.Segmenter.
Il existe un cas d'utilisation beaucoup plus large pour l'objet, mais il décompose essentiellement les chaînes en éléments plus significatifs comme des mots et des phrases en fonction des paramètres régionaux que vous fournissez. Il offre plus de granularité que la simple utilisation de points de code.
Pour corriger notre exemple ci-dessus, il suffit de mettre à jour notre fonction countString comme ceci :
import { useState } from "react";
export default function App() {
const [text, setText] = useState("");
function countString() {
return Array.from(new Intl.Segmenter().segment(text)).length;
}
function handleChange(e) {
setText(e.target.value);
}
return (
<div className="App">
<h1>Make the emojis count ?</h1>
<textarea value={text} onChange={handleChange} />
<small>Characters: {countString()}</small>
</div>
);
}
Nous créons une nouvelle instance de l'objet Intl.Segmenter et lui transmettons notre texte. Nous mettons cette sortie dans un tableau, puis prenons finalement la longueur, ce qui sera bien plus précis que de simplement prendre la longueur de la chaîne d'origine.
Voici le résultat :

Réponse courte : je n’en ai aucune idée.
Je programme depuis trop longtemps pour me leurrer en pensant qu'il existe une réponse simple.
Mais Intl.Segmenter a une bonne prise en charge du navigateur, et toute contrainte de performances ou de mémoire serait négligeable.
Ma meilleure hypothèse est que la base de code est si volumineuse et si ancienne qu'elle ne vaut pas les effets secondaires d'un refactor.
Je serais heureux d'en savoir plus si quelqu'un a une meilleure idée à ce sujet.
J'espère que cela aide ?.
Bon codage ?.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Quelles sont les instructions de mise à jour MySQL ?
Quelles sont les instructions de mise à jour MySQL ?
 win10 se connecte à une imprimante partagée
win10 se connecte à une imprimante partagée
 Comment vérifier l'utilisation du processeur sous Linux
Comment vérifier l'utilisation du processeur sous Linux
 paramètres de taille adaptative des graphiques
paramètres de taille adaptative des graphiques
 Comment supprimer mon adresse WeChat
Comment supprimer mon adresse WeChat
 supprimer le dossier sous Linux
supprimer le dossier sous Linux
 Le numéro virtuel reçoit le code de vérification
Le numéro virtuel reçoit le code de vérification
 l'utilisation du processeur
l'utilisation du processeur





















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



