Après avoir subi une « fuite accidentelle » deux jours à l’avance, Llama 3.1 a finalement été officiellement publié hier soir. Llama 3.1 étend la longueur du contexte à 128 Ko et est disponible en versions 8B, 70B et 405B, élevant une fois de plus à lui seul la barre de la compétition sur les pistes de grands modèles. Pour la communauté IA, l'importance la plus importante de Llama 3.1 405B est qu'il rafraîchit la limite supérieure des capacités du modèle de base open source. Les responsables de Meta ont déclaré que dans une série de tâches, ses performances sont comparables aux meilleures fermées. modèle source. Le tableau ci-dessous montre les performances des modèles actuels de la série Llama 3 sur des critères clés. On constate que les performances du modèle 405B sont très proches de celles du GPT-4o.
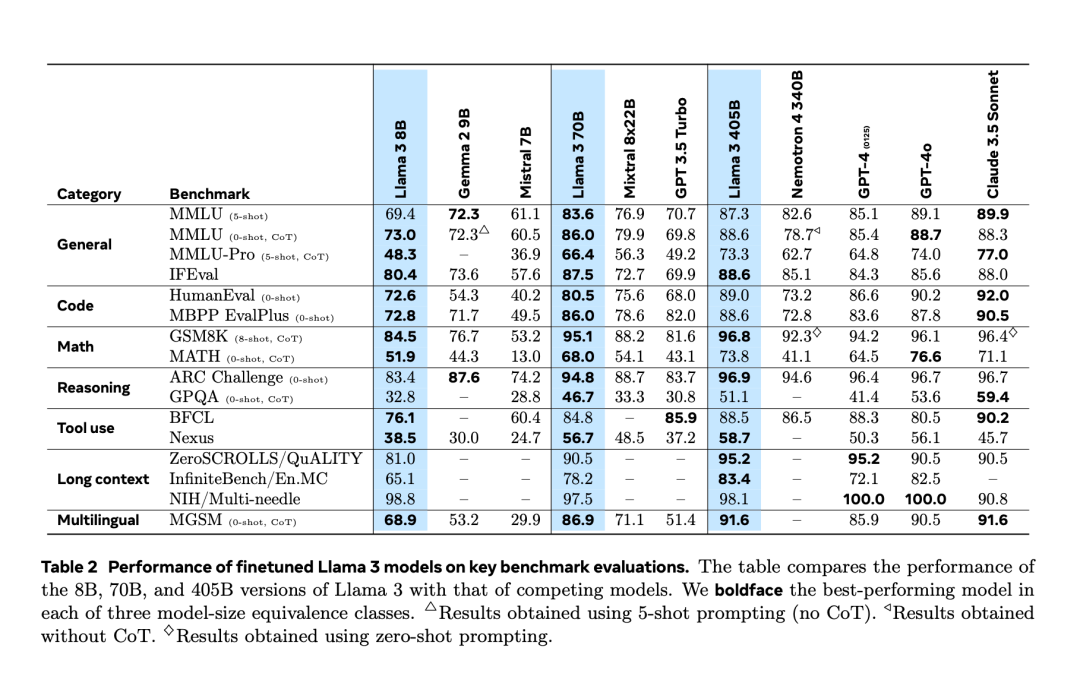
Dans le même temps, Meta a publié l'article "The Llama 3 Herd of Models", révélant les détails de la recherche sur les modèles de la série Llama 3 jusqu'à présent. # à B utilise une longueur de contexte de 8 K Après la pré-formation, la formation continue est effectuée avec une longueur de contexte de 128 K, prenant en charge plusieurs langues et l'utilisation d'outils.
 Meta améliore le prétraitement du modèle Llama et les pipelines de conservation des données de pré-formation, ainsi que les méthodes d'assurance qualité et de filtrage des données de post-formation.
Meta améliore le prétraitement du modèle Llama et les pipelines de conservation des données de pré-formation, ainsi que les méthodes d'assurance qualité et de filtrage des données de post-formation.
Meta estime qu'il existe trois leviers clés pour le développement de modèles sous-jacents de haute qualité : la gestion des données, de l'échelle et de la complexité.
Données : - Meta a amélioré à la fois la quantité et la qualité des données pré-entraînement et post-entraînement par rapport aux versions précédentes de Llama. Llama 3 est pré-entraîné sur un corpus d'environ 15 000 milliards de jetons multilingues, tandis que Llama 2 n'utilise que 1 800 milliards de jetons.
- Échelle :
Les modèles entraînés sont beaucoup plus grands que les modèles Llama précédents : le modèle de langage phare utilise 3,8 x 10^25 opérations à virgule flottante (FLOP) pour le pré-entraînement, dépassant de près de 50 fois la plus grande version de Llama 2.
Gestion de la complexité : - Selon la loi de mise à l'échelle, le modèle phare de Meta a calculé approximativement la taille optimale, mais le temps d'entraînement des modèles plus petits a largement dépassé le temps optimal calculé. Les résultats montrent que ces modèles plus petits surpassent les modèles informatiques optimaux pour le même budget d'inférence. Dans la phase post-formation, Meta utilise le modèle phare 405B pour améliorer encore la qualité des modèles plus petits tels que le 70B et le 8B.
- Pour prendre en charge l'inférence de production à grande échelle de modèles 405B, Meta quantifie 16 bits (BF16) en 8 bits (FP8), réduisant ainsi les exigences de calcul et permettant au modèle de s'exécuter sur un seul nœud de serveur. La pré-formation de 405B sur 15,6T de jetons (3,8x10^25 FLOP) était un défi majeur, Meta a optimisé l'ensemble de la pile de formation et a utilisé plus de 16 000 GPU H100.
- Comme l'a dit Soumith Chintala, fondateur de PyTorch et ingénieur distingué Meta, le document Llama3 révèle de nombreux détails intéressants, dont la construction de l'infrastructure.
1. Pendant la formation, Meta améliore le modèle de chat grâce à plusieurs cycles d'alignement, y compris le réglage fin supervisé (SFT), l'échantillonnage de rejet et l'optimisation directe des préférences. La plupart des échantillons SFT sont générés à partir de données synthétiques.
- Les chercheurs ont fait plusieurs choix dans la conception pour maximiser l'évolutivité du processus de développement du modèle. Par exemple, une architecture de modèle Transformer dense standard a été choisie avec seulement des ajustements mineurs plutôt qu'un mélange d'experts pour maximiser la stabilité de la formation. De même, une procédure post-formation relativement simple est adoptée, basée sur un réglage fin supervisé (SFT), un échantillonnage de rejet (RS) et une optimisation des préférences directes (DPO), plutôt que des algorithmes d'apprentissage par renforcement plus complexes, qui ont tendance à être moins stables. et une extension plus difficile.
- Dans le cadre du processus de développement de Llama 3, l'équipe Meta a également développé des extensions multimodales du modèle, lui donnant des capacités de reconnaissance d'images, de reconnaissance vidéo et de compréhension de la parole. Ces modèles sont encore en cours de développement et ne sont pas encore prêts à être publiés, mais l'article présente les résultats d'expériences préliminaires avec ces modèles multimodaux.
- Meta a mis à jour sa licence pour permettre aux développeurs d'utiliser la sortie des modèles Llama pour améliorer d'autres modèles.
- À la fin de cet article, nous avons également vu une longue liste de contributeurs : fenye1. Cette série de facteurs a finalement créé la série Llama 3 aujourd'hui.
- Bien sûr, pour les développeurs ordinaires, comment utiliser le modèle Llama à l'échelle 405B est un défi et nécessite beaucoup de ressources informatiques et d'expertise.
- Après le lancement, l'écosystème de Llama 3.1 est prêt, avec plus de 25 partenaires proposant des services qui fonctionnent avec le dernier modèle, notamment Amazon Cloud Technologies, NVIDIA, Databricks, Groq, Dell, Azure, Google Cloud, Snowflake, et plus encore.

Pour plus de détails techniques, veuillez vous référer au document original.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



 Solution contre le virus de l'exe de dossier
Solution contre le virus de l'exe de dossier
 java configurer les variables d'environnement jdk
java configurer les variables d'environnement jdk
 exception nullpointerexception
exception nullpointerexception
 Requête de temps Internet
Requête de temps Internet
 Comment restaurer le navigateur IE pour accéder automatiquement à EDGE
Comment restaurer le navigateur IE pour accéder automatiquement à EDGE
 méthode de suppression de fichier hiberfil
méthode de suppression de fichier hiberfil
 Plusieurs façons de capturer des données
Plusieurs façons de capturer des données
 Quel logiciel est ouvert ?
Quel logiciel est ouvert ?








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



