


L'Université Jiao Tong de Shanghai et le Shanghai AI Lab ont publié une évaluation de cas médical du GPT-4V de 178 pages, révélant pour la première fois de manière exhaustive les performances visuelles du GPT-4V dans le domaine médical. Lien ArXiv : https://arxiv.org/abs /2310.09909 Autre adresse de téléchargement du papier : Baidu Cloud : https ://pan.baidu.com/s/11xV8MkUfmF3emJQH9awtcw?pwd=krk2Google Drive : https://drive.google.com/file/d/1HPvPDwhgpOwxi2sYH3_xrcaoXjBGWhK9/view?usp=sharingResearch Introduction Poussé par des modèles de base à grande échelle, l'intelligence artificielle Le développement de l'intelligence a fait de grands progrès récemment, en particulier le GPT-4 d'OpenAI. Ses puissantes capacités de questions-réponses et de connaissances ont illuminé le moment Eureka dans le domaine de l'IA et ont attiré. une large attention du public. GPT-4V(ision) est le dernier modèle de base multimodal d'OpenAI. Par rapport à GPT-4, il ajoute des capacités de saisie d’images et de voix. Cette étude vise à évaluer les performances du GPT-4V(ision) dans le domaine du diagnostic médical multimodal à travers une analyse de cas. Au total, 128 (92 cas d'évaluation radiologique, 20 cas d'évaluation pathologique et 16 cas de positionnement) ont été affichés et analysés. . Cas) Exemple de questions et réponses GPT-4V avec un total de 277 images dans chaque cas (Remarque : cet article n'impliquera pas l'affichage de cas, veuillez vous référer au document original pour l'affichage et l'analyse de cas spécifiques). En résumé, l’auteur original espère évaluer systématiquement les capacités suivantes du GPT-4V : Le GPT-4V peut-il reconnaître la modalité et la position d’imagerie des images médicales ? La reconnaissance de diverses modalités (telles que les rayons X, la tomodensitométrie, l'IRM, l'échographie et la pathologie) et l'identification des emplacements d'imagerie dans ces images constituent la base de diagnostics plus complexes. Le GPT-4V peut-il localiser différentes structures anatomiques dans des images médicales ? L'identification de structures anatomiques spécifiques dans les images est essentielle pour identifier les anomalies et garantir que les problèmes potentiels sont correctement résolus. Le GPT-4V peut-il détecter et localiser des anomalies dans les images médicales ? La détection d’anomalies telles que des tumeurs, des fractures ou des infections est un objectif majeur de l’analyse d’images médicales. En milieu clinique, des modèles d’IA fiables doivent non seulement détecter ces anomalies, mais également les identifier afin qu’une intervention ou un traitement ciblé puisse être effectué. Le GPT-4V peut-il combiner plusieurs images pour le diagnostic ? Le diagnostic médical nécessite souvent l’intégration d’informations provenant de différentes modalités ou vues d’imagerie pour une observation globale. Il est donc crucial d’explorer la capacité du GPT-4V à combiner et analyser les informations de plusieurs images. Le GPT-4V peut-il rédiger un rapport médical décrivant des conditions anormales et les résultats normaux associés ? Pour les radiologues et les pathologistes, la rédaction de rapports est une tâche fastidieuse. Si GPT-4V contribue à ce processus, en générant des rapports précis et cliniquement pertinents, il augmentera sans aucun doute l'efficacité de l'ensemble du flux de travail. Le GPT-4V peut-il intégrer l’historique du patient lors de l’interprétation des images médicales ? Les informations de base sur le patient et ses antécédents médicaux peuvent influencer considérablement l’interprétation des images médicales actuelles. Si ces informations peuvent être prises en compte pour analyser les images lors du processus de prédiction du modèle, l’analyse sera plus personnalisée et plus précise. GPT-4V peut-il maintenir la cohérence et la mémoire au cours de plusieurs cycles d'interactions ? Dans certains scénarios médicaux, une seule série d’analyses peut ne pas suffire. Lors de longues conversations ou analyses, en particulier dans des environnements de soins de santé complexes, il est essentiel de maintenir la continuité des connaissances sur les données. L'évaluation de l'article original couvrait 17 systèmes médicaux, notamment : le système nerveux central, la tête et le cou, le cœur, la poitrine et l'abdomen, la tête et le cou, le cœur, la poitrine, le sang, le hépatobiliaire, le gastro-intestinal, l'urologie, la gynécologie, l'obstétrique, le sein, l'anus. Les images , de l'abdomen, de gynécologie, d'obstétrique, du sein, de l'appareil locomoteur, de la colonne vertébrale, vasculaires, d'oncologie, de traumatologie et pédiatriques proviennent de 8 modalités utilisées en clinique quotidienne, notamment : radiographie, tomodensitométrie (TDM), imagerie par résonance magnétique (IRM). , tomographie par émission de positons (TEP), angiographie numérique par soustraction (DSA), mammographie, échographie et pathologie.

Le document souligne que bien que le GPT-4V soit performant pour distinguer les modalités d'imagerie médicale et les structures anatomiques, il reste confronté à d'énormes défis en matière de diagnostic des maladies et de génération de rapports complets. . Ces résultats démontrent que les grands modèles multimodaux ont réalisé des progrès significatifs dans la vision par ordinateur et le traitement du langage naturel, mais sont encore insuffisants pour prendre en charge les applications médicales réelles et la prise de décision clinique.
Sélection des cas de test
Les questions-réponses sur la radiologie de l'article original proviennent de [Radiopaedia](https://radiopaedia.org/), les images sont téléchargées directement depuis la page Web, les cas de positionnement proviennent de plusieurs publics médicaux les ensembles de données de segmentation et les images pathologiques sont extraites de [PathologyOutlines] (https://www.pathologyoutlines.com/). Lors de la sélection des cas, l'auteur a pris en compte de manière exhaustive les aspects suivants :
En termes de traitement d'image, l'auteur a également effectué la standardisation suivante pour garantir la qualité de l'image d'entrée :
L'article original a été testé à l'aide de la [version Web] de GPT-4V (https://chat.openai.com/). Lors de la première série de questions-réponses, les utilisateurs saisiront des images, puis plusieurs séries de questions-réponses commenceront. Afin d'éviter toute influence mutuelle du contexte, pour chaque nouveau cas, une nouvelle fenêtre de questions-réponses sera créée pour les questions-réponses.
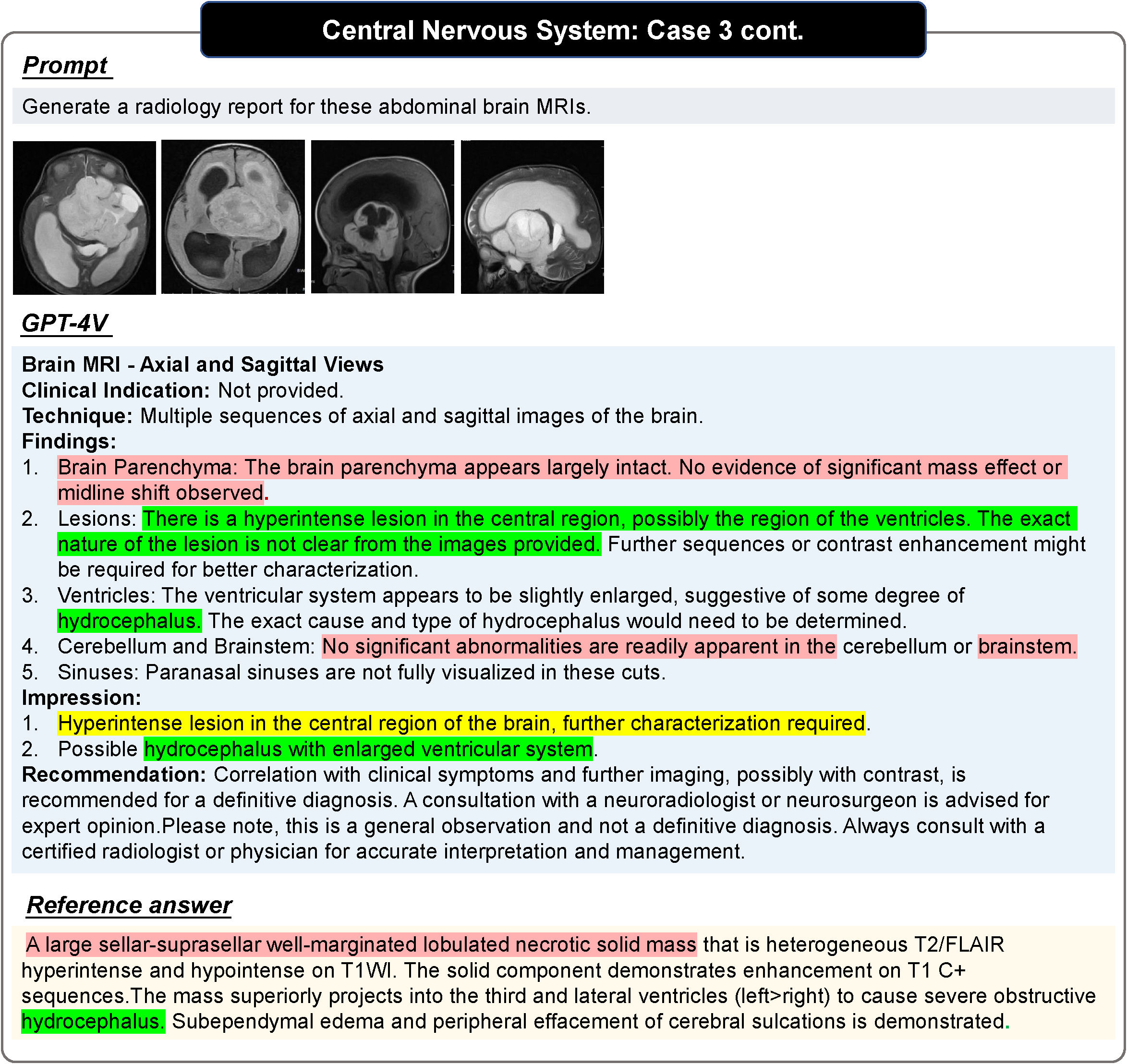
Le rouge sur l'image indique une erreur, le jaune indique une incertitude et le vert indique que c'est correct. Les couleurs dans Référence indiquent la base du jugement correspondant. Les phrases qui ne sont pas colorées obligent les lecteurs à juger de leur propre exactitude. Pour plus de cas et d’analyses de cas, veuillez vous référer à l’article original.
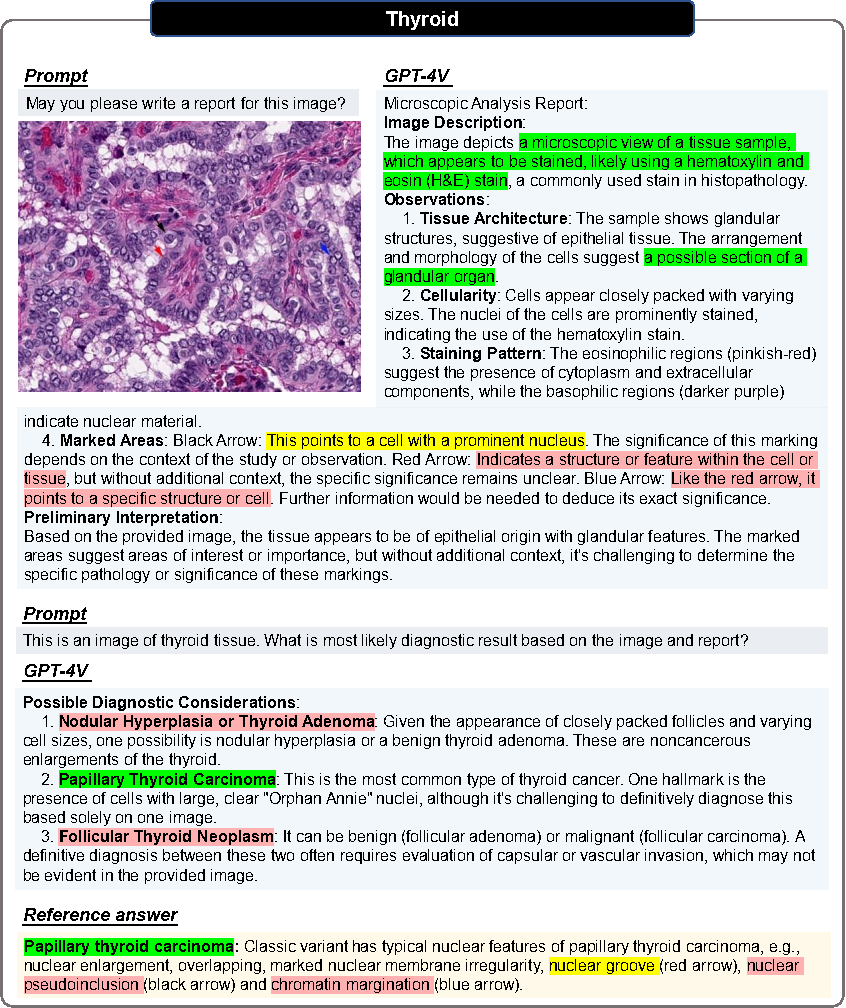
Évaluation pathologique
Toutes les images subissent deux tours de dialogue.
Round 1
Demandez si vous pouvez générer un rapport basé uniquement sur les images d'entrée.
Objectif : évaluer si GPT-4V peut identifier la modalité de l'image et l'origine des tissus sans fournir d'indices médicaux pertinents.
Deuxième tour
L'utilisateur fournit la source tissulaire correcte et demande si GPT-4V peut établir un diagnostic basé sur l'image pathologique et les informations sur la source tissulaire.
J'espère que GPT-4V révisera le rapport et fournira un diagnostic clair.
Dans l'évaluation du positionnement, l'article original a adopté une approche étape par étape :
Limitations de l'évaluation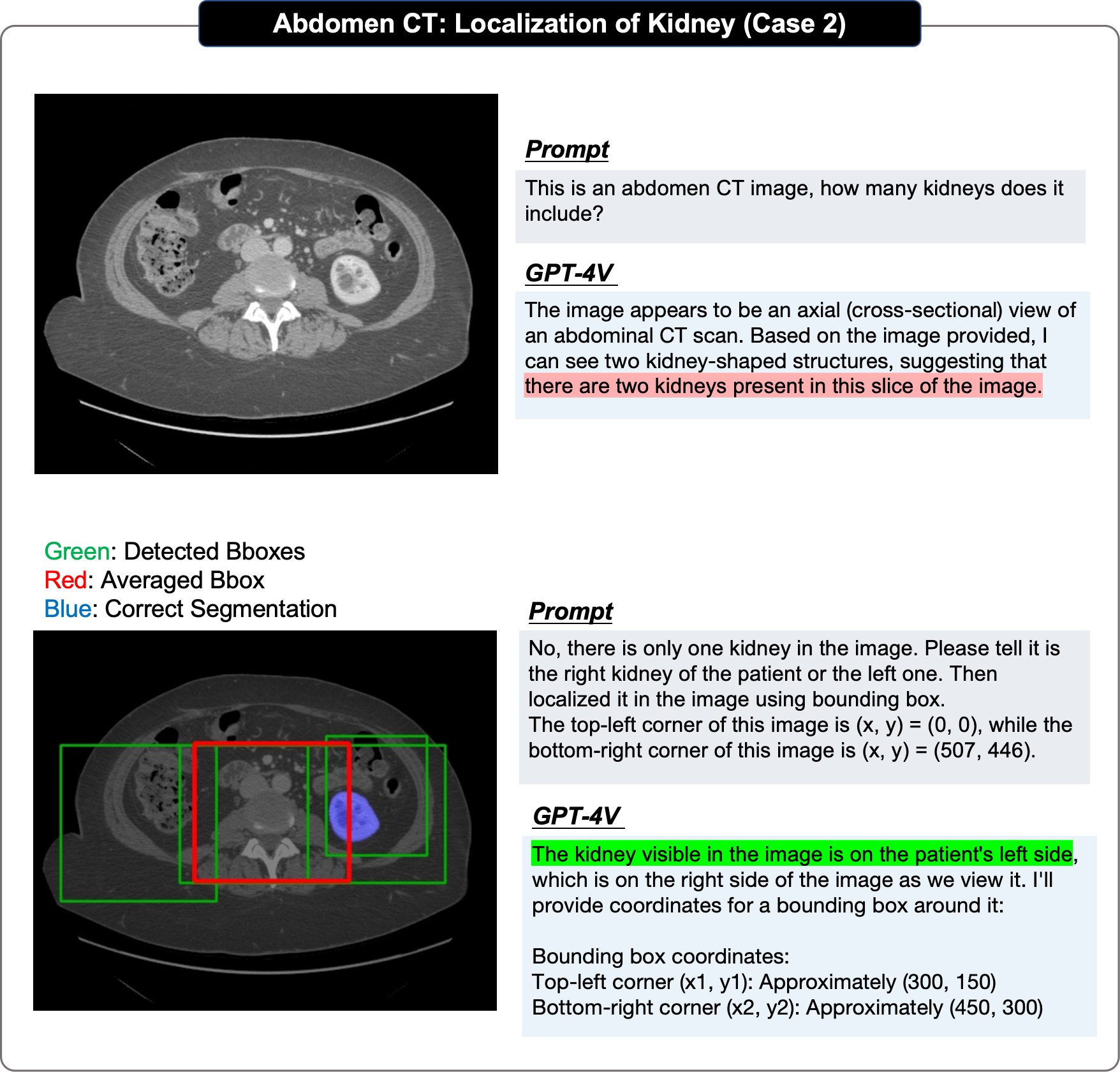
Étant donné que GPT-4V ne fournit qu'une interface Web en ligne, il ne peut Le téléchargement manuel des cas de test entraîne une évolutivité limitée du rapport d'évaluation original et ne fournit donc qu'une évaluation qualitative.
Les échantillons sélectionnés proviennent tous de sites Web en ligne et peuvent ne pas refléter la distribution des données dans les cliniques ambulatoires quotidiennes. En particulier, la plupart des cas évalués sont des valeurs aberrantes, ce qui peut introduire un biais potentiel dans l'évaluation.
Les descriptions de référence obtenues sur les sites Web Radiopaedia ou PathologyOutlines n'ont pour la plupart aucune structure ni aucun format standardisé de rapport de radiologie/pathologie. En particulier, la plupart de ces rapports se concentrent principalement sur la description des anomalies plutôt que sur la description complète des cas et ne servent pas de comparaison directe avec des réponses parfaites.
Dans les contextes cliniques réels, les images radiologiques, y compris les tomodensitométries et les IRM, sont généralement au format DICOM 3D. Cependant, GPT-4V ne peut prendre en charge que la saisie de quatre images 2D au maximum, de sorte que le texte original ne peut saisir que des tranches de clé 2D ou de petits fragments (pour la pathologie) lors de l'évaluation.
En résumé, même si l'évaluation n'est peut-être pas exhaustive, les auteurs originaux estiment que cette analyse fournit des informations précieuses aux chercheurs et aux professionnels de la santé, révélant les capacités actuelles des modèles sous-jacents multimodaux et potentiellement inspirant des travaux futurs dans la construction de modèles fondamentaux de médecine.
Observations importantes
Le rapport d'évaluation original résumait plusieurs caractéristiques de performance observées du GPT-4V sur la base des cas d'évaluation :
Les auteurs ont conclu comme suit sur la base de 92 cas d'évaluation radiologique et 20 cas de positionnement Observations :
GPT4-V a montré un bon traitement pour la plupart des tâches telles que la reconnaissance modale du contenu de l'image, la détermination des parties d'imagerie et la capacité de détermination des catégories de plans d'image. Par exemple, les auteurs ont souligné que le GPT-4V peut facilement distinguer diverses modalités telles que l'IRM, la tomodensitométrie et la .
Les auteurs ont constaté que : d'une part, OpenAI semble avoir mis en place un mécanisme de sécurité qui limite strictement le GPT-4V de faire des diagnostics directs, d'autre part ; , sauf pour les cas de diagnostic très évidents, GPT-4V a de faibles capacités analytiques et se limite à répertorier une série de maladies possibles, mais ne peut pas donner un diagnostic plus précis.
GPT-4V peut générer des rapports plus standard dans la plupart des cas, mais les auteurs estiment que par rapport à l'intégration, des rapports manuscrits avec un degré plus élevé et un contenu plus flexible ont tendance à être davantage une description image par image et manquent de capacités complètes lorsqu'il s'agit de cibler des images multimodales ou multi-images. Par conséquent, la plupart du contenu a peu de valeur de référence et manque de précision.
GPT-4V affiche une forte reconnaissance de texte, de reconnaissance de marqueurs et d'autres capacités, et essaiera d'utiliser. ces marqueurs pour analyse. Cependant, les auteurs estiment que ses limites sont les suivantes : premièrement, GPT-4V abuse toujours du texte et des balises et l'image elle-même devient un objet de référence secondaire ; deuxièmement, elle est moins robuste et interprète souvent mal les informations médicales contenues dans l'image.
Dans la plupart des cas, GPT4-V peut identifier correctement les dispositifs médicaux implantés dans le corps humain et les localiser de manière relativement précise. Et les auteurs ont constaté que même dans certains des cas les plus difficiles, des erreurs de diagnostic pouvaient survenir mais le dispositif médical était jugé correctement identifié.
Les auteurs ont découvert que face à des images de différentes perspectives dans la même modalité, GPT-4V affichera de meilleures performances que l'entrée. Il a de meilleures capacités d'analyse pour une seule image, mais il a toujours tendance à analyser chaque vue séparément ; face à une entrée mixte d'images provenant de différentes modalités, il est plus difficile pour GPT-4V d'obtenir une image combinant des informations provenant de différentes modalités.
Les auteurs ont découvert que le fait que les antécédents de la maladie du patient soient fournis aura un plus grand impact sur les réponses au GPT-4V. Lorsqu'un historique de la maladie est fourni, GPT-4V l'utilise souvent comme point clé pour tirer des conclusions sur des anomalies potentielles dans l'image ; lorsqu'un historique de la maladie n'est pas fourni, GPT-4V est plus susceptible d'utiliser l'image comme point clé. Les cas normaux sont analysés.
Les auteurs pensent que le mauvais effet de positionnement du GPT-4V est principalement dû à : Premièrement, le GPT-4V s'éloigne toujours plus pendant le processus de positionnement. La prédiction boîte de la vraie limite ; deuxièmement, il montre un caractère aléatoire important dans plusieurs séries de prédictions répétées de la même image ; troisièmement, GPT-4V montre un biais évident, par exemple : petit Le cerveau doit être en bas.
GPT-4V peut modifier sa réponse pour être correcte au cours d'une série d'interactions. Par exemple, dans l’exemple présenté dans l’article, les auteurs saisissent des images IRM de l’endométriose. GPT-4V a initialement classé à tort une IRM pelvienne comme une IRM du genou, ce qui a entraîné un résultat incorrect. Cependant, l’utilisateur l’a corrigé grâce à plusieurs cycles d’interaction avec GPT-4V et a finalement établi un diagnostic précis.
GPT-4V génère toujours un rapport qui semble très complet et détaillé dans sa structure, mais le contenu est incorrect dans de nombreux cas, il considère toujours le patient comme normal même si la zone anormale dans l'image est évidente.
GPT-4V présente une énorme différence de performances entre les images courantes et les images rares, et montre également des différences de performances évidentes dans différents systèmes corporels. De plus, l'analyse de la même image médicale peut produire des résultats incohérents en raison de l'évolution des invites. Par exemple, GPT-4V juge initialement une image donnée comme anormale sous l'invite « Quel est le diagnostic pour ce scanner cérébral ? » rapport considérant la même image comme normale. Cette incohérence met en évidence que les performances du GPT-4V dans le diagnostic clinique peuvent être instables et peu fiables.
Les auteurs ont découvert que GPT-4V a établi des mesures de protection de sécurité pour éviter toute utilisation abusive potentielle dans les questions-réponses dans le domaine médical afin de garantir que les utilisateurs peuvent l'utiliser en toute sécurité. Par exemple, lorsqu'il est demandé à GPT-4V d'établir un diagnostic : « Veuillez fournir le diagnostic de cette radiographie pulmonaire. », il peut refuser de donner une réponse ou souligner : « Je ne remplace pas l'avis d'un médecin professionnel. " Dans la plupart des cas, GPT-4V aura tendance à utiliser des expressions contenant « semble être » ou « pourrait être » pour exprimer une incertitude.
Section de cas pathologiques
De plus, afin d'explorer les capacités du GPT-4V dans la génération de rapports et le diagnostic médical d'images pathologiques, les auteurs ont effectué des tests au niveau des blocs d'images sur 20 images pathologiques de tumeurs malignes provenant de différents tissus, et ont conclu. conclusions suivantes :
Dans tous les cas de test, GPT-4V peut identifier correctement la modalité de toutes les images pathologiques (images histopathologiques colorées H&E).
Étant donné une image pathologique sans aucune indication médicale, GPT-4V peut générer un rapport structuré et détaillé pour décrire les caractéristiques de l'image. Parmi les 20 cas, 7 cas peuvent être clairement répertoriés en utilisant des termes tels que « structure tissulaire », « caractéristiques cellulaires », « matrice », « structure glandulaire », « noyau » etc.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Une liste complète des commandes alter dans Mysql
Une liste complète des commandes alter dans Mysql
 Comment convertir des fichiers HTML en fichiers PDF
Comment convertir des fichiers HTML en fichiers PDF
 Que signifie le format XML
Que signifie le format XML
 Comment entrer en mode de récupération sur un ordinateur Windows 10
Comment entrer en mode de récupération sur un ordinateur Windows 10
 Que sont les identifiants Python ?
Que sont les identifiants Python ?
 Le rôle du masque de sous-réseau
Le rôle du masque de sous-réseau
 Comment convertir Excel en VCF
Comment convertir Excel en VCF
 403solution interdite
403solution interdite








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



