



La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Yizuo Diao Haiwen est doctorant à l'Université de technologie de Dalian et son superviseur est le professeur Lu Huchuan. Actuellement en stage à l'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin, l'instructeur est le Dr Wang Xinlong. Ses intérêts de recherche sont la vision et le langage, le transfert efficace de grands modèles, les grands modèles multimodaux, etc. Le co-premier auteur, Cui Yufeng, est diplômé de l'Université de Beihang et est chercheur en algorithmes au Centre de vision de l'Institut de recherche sur l'intelligence artificielle Zhiyuan de Pékin. Ses intérêts de recherche portent sur les modèles multimodaux, les modèles génératifs et la vision par ordinateur, et ses principaux travaux portent sur la série Emu.
Récemment, la recherche sur les grands modèles multimodaux bat son plein, et l'industrie y investit de plus en plus. Des modèles phares ont été lancés à l'étranger, tels que GPT-4o (OpenAI), Gemini (Google), Phi-3V (Microsoft), Claude-3V (Anthropic) et Grok-1.5V (xAI). Dans le même temps, les GLM-4V domestiques (Wisdom Spectrum AI), Step-1.5V (Step Star), Emu2 (Beijing Zhiyuan), Intern-VL (Shanghai AI Laboratory), Qwen-VL (Alibaba), etc. Les modèles fleurissent .
Le modèle de langage visuel (VLM) actuel s'appuie généralement sur l'encodeur visuel (Vision Encoder, VE) pour extraire les caractéristiques visuelles, puis combine les instructions utilisateur avec le grand modèle de langage (LLM) pour le traitement et la réponse. Le principal défi réside. dans l'encodeur visuel et la séparation de formation pour les grands modèles de langage. Cette séparation amène les encodeurs visuels à introduire des problèmes de biais d'induction visuelle lors de l'interface avec de grands modèles de langage, tels qu'une résolution d'image et un rapport hauteur/largeur limités, et des priorités sémantiques visuelles fortes. À mesure que la capacité des encodeurs visuels continue de croître, l’efficacité du déploiement de grands modèles multimodaux dans le traitement des signaux visuels est également fortement limitée. De plus, trouver la configuration de capacité optimale des encodeurs visuels et des grands modèles de langage est devenu de plus en plus complexe et difficile.
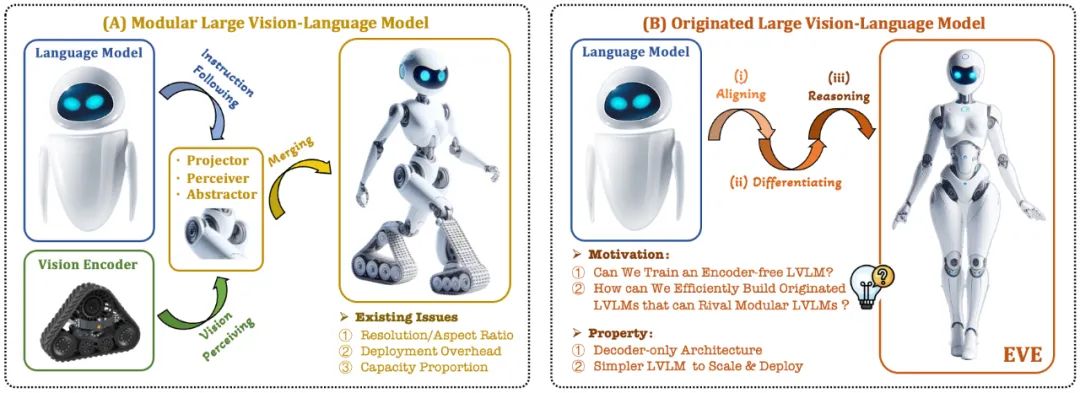
Dans ce contexte, des idées plus avant-gardistes ont rapidement émergé :
Peut-on supprimer l'encodeur visuel, c'est-à-dire construire directement un grand modèle multimodal natif sans encodeur visuel ?
Comment faire évoluer efficacement et en douceur un grand modèle de langage vers un grand modèle multimodal natif sans encodeur visuel ?
Comment combler l'écart de performances entre les cadres multimodaux natifs sans encodeur et les paradigmes multimodaux traditionnels basés sur un encodeur ?
Adept AI a publié le modèle de la série Fuyu fin 2023 et a fait quelques tentatives connexes, mais n'a divulgué aucune stratégie de formation, ressources de données et informations sur l'équipement. Dans le même temps, il existe un écart de performance significatif entre le modèle Fuyu et les algorithmes traditionnels dans les indicateurs d’évaluation de textes visuels publics. Au cours de la même période, certaines expériences pilotes que nous avons menées ont montré que même si l'échelle des données de pré-entraînement est augmentée à grande échelle, le grand modèle multimodal natif sans encodeur reste confronté à des problèmes épineux tels qu'une vitesse de convergence lente et de mauvaises performances.
En réponse à ces défis, l'équipe de vision de l'Institut de recherche Zhiyuan, en collaboration avec l'Université de technologie de Dalian, l'Université de Pékin et d'autres universités nationales, a lancé une nouvelle génération de modèle de langage visuel sans codeur EVE. Grâce à des stratégies de formation raffinées et à une supervision visuelle supplémentaire, EVE intègre la représentation, l'alignement et l'inférence visuo-linguistiques dans une architecture de décodeur pure et unifiée. En utilisant des données accessibles au public, EVE fonctionne bien sur plusieurs tests visuo-linguistiques, rivalisant avec les méthodes multimodales traditionnelles basées sur un encodeur de capacité similaire et surpassant considérablement son compatriote Fuyu-8B. EVE est proposé pour fournir une voie transparente et efficace pour le développement d'architectures multimodales natives pour les décodeurs purs.


Adresse papier : https://arxiv.org/abs/2406.11832
Code du projet : https://github.com/baaivision/EVE
Adresse du modèle : https ://huggingface.co/BAAI/EVE-7B-HD-v1.0
1. Faits saillants techniques
.Modèle de langage visuel natif : brise le paradigme fixe des modèles multimodaux traditionnels, supprime l'encodeur visuel et peut gérer n'importe quel rapport hauteur/largeur d'image. Il surpasse considérablement le même type de modèle Fuyu-8B dans plusieurs tests de langage visuel et est proche de l'architecture de langage visuel basée sur un encodeur visuel grand public.
Faibles coûts de données et de formation : la pré-formation du modèle EVE n'a examiné que les données publiques d'OpenImages, SAM et LAION, et a utilisé 665 000 données d'instructions LLaVA et 1,2 million de données de dialogue visuel supplémentaires pour construire respectivement des données régulières et élevées. versions de résolution d'EVE-7B. La formation prend environ 9 jours sur deux nœuds 8-A100 (40G), ou environ 5 jours sur quatre nœuds 8-A100.
Exploration transparente et efficace : EVE tente d'explorer une voie efficace, transparente et pratique vers le modèle de langage visuel natif, fournissant de nouvelles idées et une expérience précieuse pour le développement d'une nouvelle génération d'architecture de modèle de langage visuel de décodeur pur. des futurs modèles multimodaux ouvre de nouvelles directions d’exploration.
2. Structure du modèle
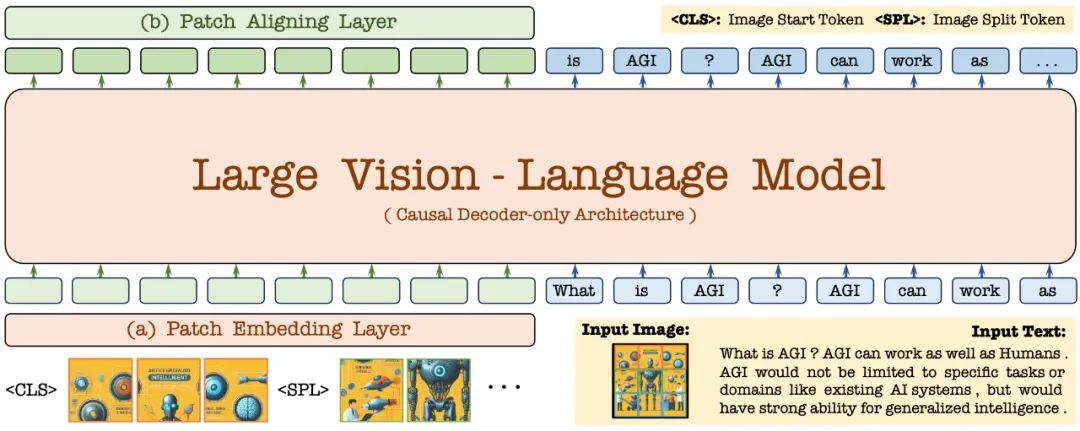
Tout d'abord, il est initialisé via le modèle de langage Vicuna-7B, de sorte qu'il possède une connaissance linguistique riche et de puissantes capacités de suivi des instructions. Sur cette base, l'encodeur visuel profond est supprimé, une couche d'encodage visuel légère est construite, l'entrée d'image est codée de manière efficace et sans perte, et entrée dans un décodeur unifié avec les commandes du langage utilisateur. De plus, la couche d'alignement visuel effectue l'alignement des caractéristiques avec un encodeur visuel général pour améliorer le codage et la représentation fine des informations visuelles.
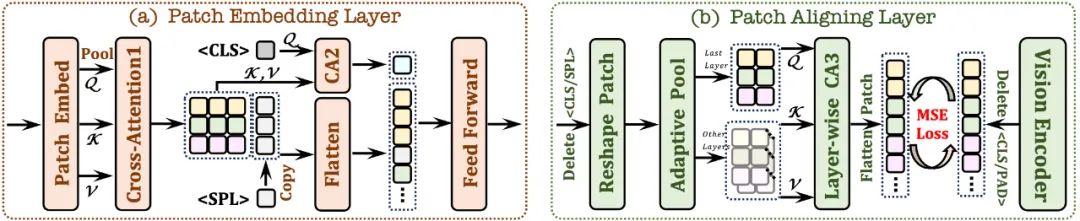
2.1 Couche d'intégration de patch
Utilisez d'abord une seule couche convolutionnelle pour obtenir la carte des caractéristiques 2D de l'image, puis sous-échantillonnez à travers la couche de regroupement moyenne
Utilisez le module d'attention croisée (CA1) ; Interagissez dans un champ de réception limité pour améliorer les fonctionnalités locales de chaque patch ;
utilise le jeton et combiné avec le module d'attention croisée (CA2) pour fournir des informations globales pour chaque fonctionnalité de patch suivante
dans chaque fonctionnalité de patch ; Un jeton apprenable est inséré à la fin de la ligne pour aider le réseau à comprendre la structure spatiale bidimensionnelle de l'image.
2.2 Couche d'alignement des patchs
Enregistrez la forme 2D du patch valide ; jetez les jetons /
grâce à une attention croisée hiérarchique ; Le module (CA3) intègre des fonctionnalités visuelles de réseau multicouche pour obtenir un alignement précis avec la sortie de l'encodeur visuel.
3. Stratégie de formation
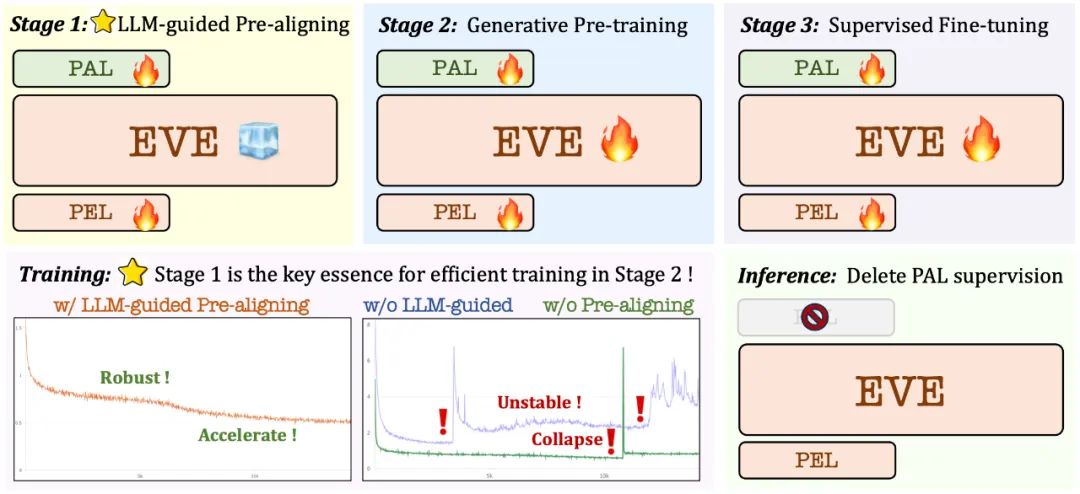
Étape de pré-formation guidée par un grand modèle de langage : établir le lien initial entre la vision et le langage, jetant les bases d'une pré-formation ultérieure à grande échelle, stable et efficace.
Phase de pré-formation générative : améliorer encore la capacité du modèle à comprendre le contenu visuo-linguistique et réaliser une transition en douceur d'un modèle de langage pur à un modèle multimodal
Phase de mise au point supervisée : plus loin ; standardiser le modèle pour suivre les instructions linguistiques et la capacité d'apprendre des modèles de conversation qui répondent aux exigences de diverses références de langage visuel.

Au cours de la phase de pré-formation, 33 millions de données publiques de SA-1B, OpenImages et LAION ont été filtrées, et seuls les échantillons d'images avec une résolution supérieure à 448×448 ont été conservés. En particulier, pour résoudre le problème de la redondance élevée dans les images LAION, 50 000 clusters ont été générés en appliquant le clustering K-means sur les caractéristiques de l'image extraites par EVA-CLIP, et les 300 images les plus proches de chaque centre de cluster ont été sélectionnées, et enfin. sélectionné 15 millions d’échantillons d’images LAION. Par la suite, des descriptions d'images de haute qualité ont été régénérées à l'aide d'Emu2 (17B) et de LLaVA-1.5 (13B).
Dans la phase de réglage fin supervisé, utilisez l'ensemble de données de réglage fin LLaVA-mix-665K pour entraîner la version standard d'EVE-7B et intégrez des données mixtes telles que AI2D, Synthdog, DVQA, ChartQA, DocVQA, Vision-Flan et Bunny-695K Prêts à s'entraîner pour obtenir une version haute résolution d'EVE-7B.
4. Analyse quantitative
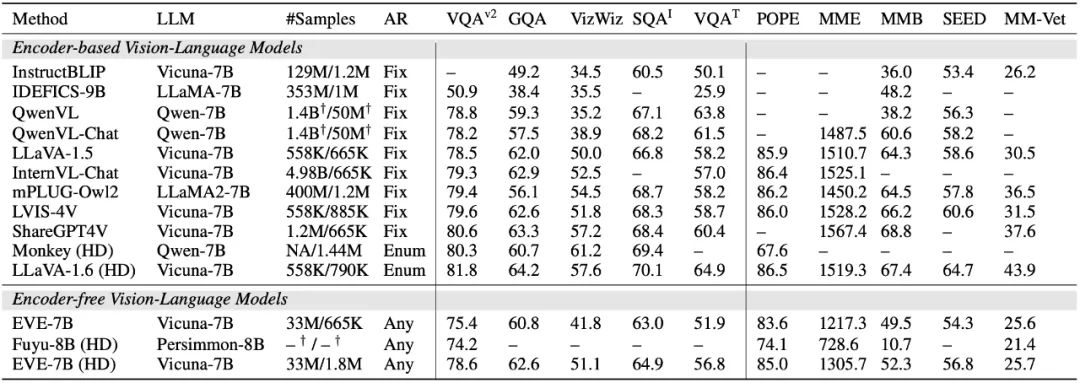
Le modèle EVE surpasse considérablement le modèle similaire Fuyu-8B dans plusieurs tests de langage visuel et fonctionne à égalité avec une variété de modèles de langage visuel traditionnels basés sur un encodeur. Cependant, en raison de l'utilisation d'une grande quantité de données de langage visuel pour la formation, il est difficile de répondre avec précision à des instructions spécifiques, et ses performances dans certains tests de référence doivent être améliorées. Ce qui est passionnant, c'est que grâce à des stratégies de formation efficaces, l'EVE sans encodeur peut atteindre des performances comparables à celles du modèle de langage visuel basé sur un encodeur, résolvant fondamentalement les problèmes de flexibilité de la taille d'entrée, d'efficacité de déploiement et de modalité des modèles traditionnels.
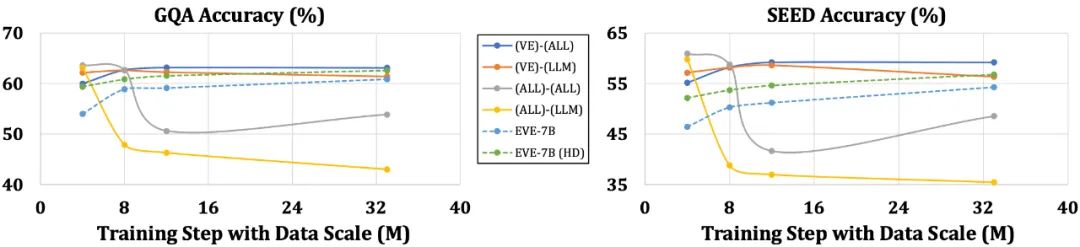
Par rapport aux modèles avec encodeurs, qui sont sensibles à des problèmes tels que la simplification de la structure du langage et la perte de connaissances riches, EVE a montré une amélioration progressive et stable des performances à mesure que la taille des données augmente, se rapprochant progressivement des performances de l'encodeur. niveau de modèles basés sur des modèles. Cela peut être dû au fait que l'encodage et l'alignement des modalités visuelles et linguistiques dans un réseau unifié sont plus difficiles, ce qui rend les modèles sans encodeur moins sujets au surajustement par rapport aux modèles avec encodeurs.
5. Qu'en pensent vos pairs ?
Ali Hatamizadeh, chercheur principal chez NVIDIA, a déclaré qu'EVE est rafraîchissant et tente de proposer un nouveau récit, différent de la construction de normes d'évaluation complexes et des améliorations progressives du modèle de langage visuel.

Armand Joulin, chercheur principal chez Google Deepmind, a déclaré qu'il était passionnant de construire un modèle de langage visuel pur décodeur.

Prince Canuma, ingénieur en apprentissage automatique chez Apple, a déclaré que l'architecture EVE est très intéressante et constitue un bon ajout à l'ensemble du projet MLX VLM.

6. Perspectives d'avenir
En tant que modèle de langage visuel natif sans encodeur, EVE a actuellement obtenu des résultats encourageants. Sur cette voie, il existe quelques directions intéressantes qui méritent d'être explorées à l'avenir :
Amélioration supplémentaire des performances : des expériences ont montré que la pré-entraînement utilisant uniquement des données visuo-linguistiques réduisait considérablement la capacité linguistique du modèle (le score SQA de 65,3 % a chuté à 63,0 %), mais a progressivement amélioré la performance multimodale du modèle. Cela indique qu’il existe un oubli catastrophique interne des connaissances linguistiques lorsque de grands modèles linguistiques sont mis à jour. Il est recommandé d'intégrer de manière appropriée les données de pré-formation linguistique pure ou d'utiliser une stratégie mixte d'experts (MoE) pour réduire l'interférence entre les modalités visuelles et linguistiques.
Imagination d'une architecture sans encodeur : avec des stratégies appropriées et une formation avec des données de haute qualité, les modèles de langage visuel sans encodeur peuvent rivaliser avec les modèles avec encodeurs. Alors, avec la même capacité de modèle et des données de formation massives, quelle est la performance des deux ? Nous pensons qu'en augmentant la capacité du modèle et la quantité de données d'entraînement, l'architecture sans encodeur peut atteindre ou même surpasser l'architecture basée sur un encodeur, car la première entre les images presque sans perte et évite le biais a priori de l'encodeur visuel.
Construction de modèles multimodaux natifs : EVE démontre complètement comment construire des modèles multimodaux natifs de manière efficace et stable, ce qui ouvre la transparence pour l'intégration ultérieure de davantage de modalités (telles que l'audio, la vidéo, l'imagerie thermique, la profondeur, etc.) et des parcours pratiques. L'idée principale est de pré-aligner ces modalités via un grand modèle de langage gelé avant d'introduire une formation unifiée à grande échelle, et d'utiliser les encodeurs monomodaux correspondants et l'alignement des concepts de langage pour la supervision.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Explication détaillée de la commande nohup
Explication détaillée de la commande nohup
 Comment acheter et vendre du Bitcoin sur okex
Comment acheter et vendre du Bitcoin sur okex
 Raisons pour lesquelles phpstudy ne peut pas être ouvert
Raisons pour lesquelles phpstudy ne peut pas être ouvert
 Utilisation de la fonction urlencode
Utilisation de la fonction urlencode
 À quel point Dimensity 9000 équivaut-il à Snapdragon ?
À quel point Dimensity 9000 équivaut-il à Snapdragon ?
 Comment configurer Douyin pour empêcher tout le monde de voir l'œuvre
Comment configurer Douyin pour empêcher tout le monde de voir l'œuvre
 SQL dans l'utilisation de l'opérateur
SQL dans l'utilisation de l'opérateur
 Quel est le format du papier A5
Quel est le format du papier A5








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



