Concepts de base
- Index de clé primaire / Index secondaire
- Index clusterisé / Index non clusterisé
- Recherche de table / couverture d'index
- Index déroulant
- Index composite / correspondance de préfixe le plus à gauche
- Index des préfixes
- Expliquez
1. [Définition de l'index]
1. Définition de l'index
Outre les données elles-mêmes, le système de base de données maintient également des structures de données qui satisfont des algorithmes de recherche spécifiques. Ces structures référencent (pointent vers) les données d'une certaine manière, permettant d'implémenter sur celles-ci des algorithmes de recherche avancés. Ces structures de données sont des index.
2. Structures de données des index
- Arbre B-tree / B+ (le moteur InnoDB de MySQL utilise l'arbre B+ comme structure d'index par défaut)
- Table de HASH
- Tableau trié
3. Pourquoi choisir l'arbre B+ plutôt que l'arbre B
- Structure B-tree : les enregistrements sont stockés dans les nœuds de l'arborescence.
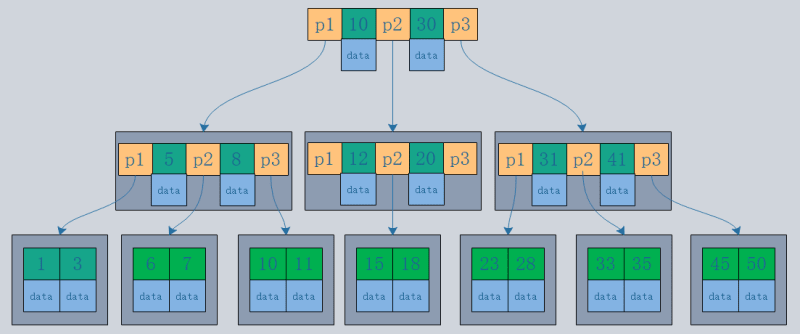
- Structure arborescente B+ : les enregistrements sont stockés uniquement dans les nœuds feuilles de l'arborescence.
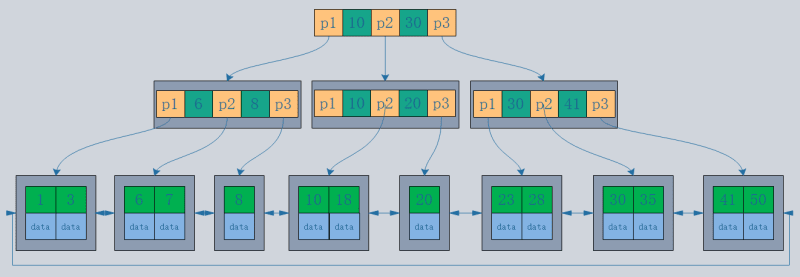
- En supposant une taille de données de 1 Ko et une taille d'index de 16 B, avec la base de données utilisant des pages de données de disque et une taille de page de disque par défaut de 16 Ko, les trois mêmes opérations d'E/S donneront :
B-tree peut récupérer 16*16*16=4096 enregistrements.
L'arbre B+ peut récupérer 1000*1000*1000=1 milliard enregistrements.
2. [Types d'index]
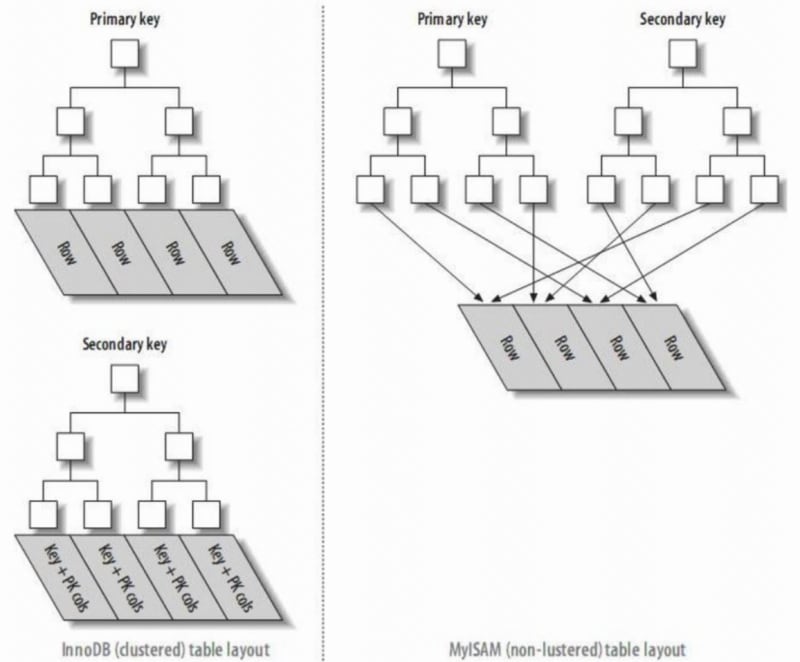
1. Index de clé primaire et index secondaire
-
Index de clé primaire : Les nœuds feuilles de l'index sont des lignes de données.
-
Index secondaire : Les nœuds feuilles de l'index sont des champs KEY plus un index de clé primaire. Par conséquent, lors d'une requête via un index secondaire, il trouve d'abord la valeur de la clé primaire, puis InnoDB trouve le bloc de données correspondant via l'index de la clé primaire.
-
Dans InnoDB, le fichier d'index primaire stocke directement la ligne de données, appelé index clusterisé, tandis que les index secondaires pointent vers la référence de clé primaire.
-
Dans MyISAM, les index primaires et secondaires pointent vers des lignes physiques (positions des disques).
2. Index clusterisé et index non clusterisé
- Un index clusterisé réorganise les données réelles sur le disque pour les trier selon une ou plusieurs valeurs de colonne spécifiées. La caractéristique est que l'ordre de stockage des données et l'ordre d'indexation sont cohérents. Généralement, la clé primaire créera par défaut un index clusterisé, et une table n'autorise qu'un seul index clusterisé (raison : les données ne peuvent être stockées que dans un seul ordre). Comme le montre l'image, les index primaires et secondaires d'InnoDB sont des index clusterisés.
- Par rapport aux nœuds feuilles d'un index clusterisé qui sont des enregistrements de données, les nœuds feuilles d'un index non clusterisé sont des pointeurs vers les enregistrements de données. La plus grande différence est que l'ordre des enregistrements de données ne correspond pas à l'ordre de l'index.
3. Avantages et inconvénients de l'index clusterisé
- Avantage : lors de l'interrogation d'entrées par clé primaire, il n'est pas nécessaire d'effectuer une recherche dans la table (les données se trouvent sous le nœud de clé primaire).
- Inconvénient : des fractionnements de pages fréquents peuvent se produire en cas d'insertion irrégulière de données.
3. [Concepts d'index étendus]
1. Recherche de table
Le concept de recherche de table implique la différence entre les requêtes d'index de clé primaire et les requêtes d'index de clé non primaire.
- Si la requête est select * from T où ID=500, une requête de clé primaire n'a besoin que de rechercher dans l'arborescence des ID.
- Si la requête est select * from T où k=5, une requête d'index de clé non primaire doit d'abord rechercher dans l'arborescence d'index k pour obtenir la valeur d'ID de 500, puis rechercher à nouveau dans l'arborescence d'index d'ID.
- Le processus de passage de l'index de clé non primaire à l'index de clé primaire est appelé recherche de table.
Les requêtes basées sur des index de clé non primaire nécessitent l'analyse d'une arborescence d'index supplémentaire. Par conséquent, nous devrions essayer d'utiliser des requêtes de clé primaire dans les applications. Du point de vue de l'espace de stockage, étant donné que les nœuds feuilles de l'arborescence d'index de clé non primaire stockent les valeurs de clé primaire, il est conseillé de garder les champs de clé primaire aussi courts que possible. De cette façon, les nœuds feuilles de l’arborescence d’index de clé non primaire sont plus petits et l’index de clé non primaire occupe moins d’espace. Généralement, il est recommandé de créer une clé primaire à incrémentation automatique pour minimiser l'espace occupé par les index de clé non primaire.
2. Couverture d'index
- Si une condition de clause WHERE est un index de clé non primaire, la requête localisera d'abord l'index de clé primaire via l'index de clé non primaire (la clé primaire est située aux nœuds feuilles du arbre de recherche d'index clé), puis localisez le contenu de la requête via l'index de clé primaire. Dans ce processus, le retour à l'arborescence d'index de clé primaire est appelé recherche de table.
- Cependant, lorsque le contenu de notre requête est la valeur de la clé primaire, nous pouvons directement fournir le résultat de la requête sans recherche de table. En d'autres termes, l'index de clé non primaire a déjà "couvert" nos exigences de requête dans cette requête, c'est pourquoi on l'appelle un index de couverture.
-
Un index de couverture peut obtenir directement les résultats de requête de l'index auxiliaire sans recherche de table vers l'index primaire, réduisant ainsi le nombre de recherches (pas besoin de passer de l'arborescence d'index auxiliaire à l'arborescence d'index clusterisé) ou réduisant Opérations IO (l'arborescence d'index auxiliaire peut charger plus de nœuds du disque à la fois), améliorant ainsi les performances.
3. Indice composite
Un index composite fait référence à l'indexation de plusieurs colonnes d'une table.
Scénario 1 :
Un index composite (a, b) est trié par a, b (d'abord trié par a, si a est le même puis trié par b). Par conséquent, les instructions suivantes peuvent utiliser directement l'index composite pour obtenir des résultats (en fait, il utilise le principe du préfixe le plus à gauche) :
- sélectionnez… parmi xxx où a=xxx;
- sélectionnez… à partir de xxx où a=xxx commandez par b;
Les instructions suivantes ne peuvent pas utiliser de requêtes composites :
- sélectionnez… parmi xxx où b=xxx;
Scénario 2 :
Pour un index composite (a, b, c), les instructions suivantes peuvent obtenir directement des résultats via l'index composite :
- sélectionnez… à partir de xxx où a=xxx commandez par b;
- sélectionnez… à partir de xxx où a=xxx et b=xxx commandez par c;
Les instructions suivantes ne peuvent pas utiliser l'index composite et nécessitent une opération de tri de fichiers :
- sélectionnez… à partir de xxx où a=xxx commandez par c;
Résumé :
En utilisant l'index composite (a, b, c) comme exemple, créer un tel index équivaut à créer des index a, ab et abc. Avoir un index remplaçant trois index est certainement bénéfique, car chaque index supplémentaire augmente la surcharge des opérations d'écriture et de l'utilisation de l'espace disque.
4. Principe du préfixe le plus à gauche
- À partir de l'exemple d'index composite ci-dessus, nous pouvons comprendre le principe du préfixe le plus à gauche.
-
Pas seulement la définition complète de l'index, tant qu'il correspond au préfixe le plus à gauche, il peut être utilisé pour accélérer la récupération. Ce préfixe le plus à gauche peut être les N champs les plus à gauche de l'index composite ou les caractères M les plus à gauche de l'index de chaîne. Utilisez le principe du "préfixe le plus à gauche" de l'index pour localiser les enregistrements et éviter les définitions d'index redondantes.
- Par conséquent, sur la base du principe du préfixe le plus à gauche, il est crucial de prendre en compte l'ordre des champs au sein de l'index lors de la définition des index composites ! Le critère d'évaluation est la réutilisabilité de l'index. Par exemple, quand il existe déjà un index sur (a, b), il n'est généralement pas nécessaire de créer un index séparé sur a.
5. Index déroulant
MySQL 5.6 a introduit l'optimisation du pushdown d'index, qui peut filtrer les enregistrements qui ne remplissent pas les conditions en fonction des champs inclus dans l'index lors du parcours d'index, réduisant ainsi le nombre de recherches de table.
CREATE TABLE `test` (
`id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'Auto-increment primary key',
`age` int(11) NOT NULL DEFAULT '0',
`name` varchar(255) CHARACTER SET utf8 NOT NULL DEFAULT '',
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci;
Copier après la connexion
-
SELECT * de l'utilisateur dont le nom est comme 'Chen%' Principe du préfixe le plus à gauche, en frappant l'index idx_name_age
-
SELECT * de l'utilisateur dont le nom est comme 'Chen%' et l'âge = 20
- Avant la version 5.6, il correspondait d'abord à 2 enregistrements en fonction de l'index de nom (en ignorant la condition age=20 à ce stade), trouvait les 2 identifiants correspondants, effectuait des recherches dans les tables, puis filtrait en fonction de l'âge=20.
- Après la version 5.6, le pushdown d'index est introduit. Après avoir fait correspondre 2 enregistrements en fonction du nom, il n'ignorera pas la condition age=20 avant d'effectuer des recherches dans la table, en filtrant en fonction de l'âge avant la recherche dans la table. Ce refoulement d'index peut réduire le nombre de recherches de tables et améliorer les performances des requêtes.
6. Index des préfixes
Lorsque un index est une longue séquence de caractères, il peut prendre beaucoup de mémoire et être lent. Dans ce cas, des index de préfixes peuvent être utilisés. Au lieu d'indexer la valeur entière, nous indexons les premiers caractères pour économiser de l'espace et obtenir de bonnes performances. L'index préfixe utilise les premières lettres de l'index. Cependant, pour réduire le taux de duplication de l'index, nous devons évaluer l'unicité de l'index du préfixe.
- Tout d'abord, calculez le taux d'unicité du champ de chaîne actuel : sélectionnez 1,0*count(nom distinct)/count(*) dans le test
- Ensuite, calculez le taux d'unicité pour différents préfixes :
-
sélectionnez 1.0*count(distinct left(name,1))/count(*) from test pour le premier caractère du nom comme index de préfixe
-
sélectionnez 1.0*count(distinct left(name,2))/count(*) from test pour les deux premiers caractères du nom comme index de préfixe
- ...
- Lorsque left(str, n) n'augmente pas de manière significative, sélectionnez n comme valeur seuil de l'indice de préfixe.
- Créez l'index alter table test add key(name(n));
4. [Affichage des index]
Après avoir ajouté des index, comment pouvons-nous les visualiser ? Ou, si les instructions sont lentes à s'exécuter, comment pouvons-nous résoudre les problèmes ?
Expliquer est couramment utilisé pour vérifier si un index est efficace.
Après avoir obtenu le journal des requêtes lentes, observez quelles instructions sont lentes. Ajoutez expliquer avant l'instruction et exécutez-la à nouveau. Explain définit un indicateur sur la requête, l'amenant à renvoyer des informations sur chaque étape du plan d'exécution au lieu d'exécuter l'instruction. Il renvoie une ou plusieurs lignes d'informations montrant chaque partie du plan d'exécution et l'exécution. commande.
Champs importants renvoyés par expliquer :
-
type : affiche la méthode de recherche (analyse complète de la table ou analyse d'index)
- clé : Le champ d'index utilisé, nul si non utilisé
Expliquez le champ de type :
- TOUS : Analyse complète du tableau
- index : analyse complète de l'index
- plage : analyse de la plage d'index
- réf : Analyse d'index non unique
- eq_ref : Analyse d'index unique
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!



















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



