La rubrique AIxiv est une rubrique où des contenus académiques et techniques sont publiés sur ce site. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Shuai Xincheng, le premier auteur de cet article, étudie actuellement pour un doctorat au laboratoire FVL de l'université de Fudan et est diplômé de l'université Jiao Tong de Shanghai avec un baccalauréat. Ses principaux intérêts de recherche incluent le montage d’images et de vidéos et l’apprentissage multimodal.
Cet article propose un cadre unifié pour résoudre les tâches d'édition générales ! Récemment, des chercheurs du laboratoire FVL de l’université de Fudan et de l’université technologique de Nanyang ont résumé et examiné des algorithmes d’édition d’images guidées multimodaux basés sur de grands modèles de graphes vincentiens. La revue couvre plus de 300 études pertinentes, et le dernier modèle étudié date de juin de cette année ! Cette revue étend la discussion sur les conditions de contrôle (langage naturel, images, interfaces utilisateur) et les tâches d'édition (manipulation d'objet/attribut, transformation spatiale, inpainting, transfert de style, traduction d'image, personnalisation de sujet/attribut) à une discussion plus nouvelle et complète de méthodes d’édition dans une perspective plus générale. En outre, cette revue propose un cadre unifié qui représente le processus d'édition comme une combinaison de différentes familles d'algorithmes, et illustre les caractéristiques de diverses combinaisons ainsi que des scénarios d'adaptation à travers des expériences qualitatives et quantitatives complètes. Le framework fournit un espace de conception convivial pour répondre aux différents besoins des utilisateurs et fournit une certaine référence aux chercheurs pour développer de nouveaux algorithmes. L'édition d'images est conçue pour éditer une image synthétique ou réelle donnée selon les besoins spécifiques de l'utilisateur. En tant que domaine prometteur et stimulant dans le domaine du contenu généré par l’intelligence artificielle (AIGC), l’édition d’images a été largement étudiée. Récemment, le modèle de diffusion image vers infrarouge (T2I) à grande échelle a stimulé le développement de la technologie d’édition d’images. Ces modèles génèrent des images basées sur des invites textuelles, démontrant des capacités génératives étonnantes et devenant un outil courant pour l'édition d'images. Le procédé d'édition d'images basé sur T2I améliore considérablement les performances d'édition et fournit aux utilisateurs une interface pour la modification de contenu à l'aide d'un guidage de conditions multimodal. Nous proposons une revue complète des techniques d’édition d’images guidées multimodales basées sur des modèles de diffusion T2I. Tout d’abord, nous définissons la portée des tâches d’édition d’images d’un point de vue plus général et décrivons en détail divers signaux de commande et scénarios d’édition. Nous proposons ensuite un cadre unifié pour formaliser le processus d'édition, le représentant comme une combinaison de deux familles d'algorithmes. Ce cadre offre aux utilisateurs un espace de conception pour atteindre des objectifs spécifiques. Ensuite, nous avons procédé à une analyse approfondie de chaque composant du cadre, en étudiant les caractéristiques et les scénarios applicables de différentes combinaisons. Étant donné que les méthodes basées sur la formation apprennent directement à mapper les images sources aux images cibles, nous discutons de ces méthodes séparément et introduisons des schémas d'injection d'images sources dans différents scénarios. De plus, nous examinons l'application des techniques 2D dans le montage vidéo, en nous concentrant sur la résolution des incohérences inter-images. Enfin, nous discutons également des défis ouverts dans le domaine et proposons de futures orientations de recherche potentielles. 
- Titre de l'article : A Survey of Multimodal-Guided Image Editing with Text-to-Image Diffusion Models
- Unité de publication : Fudan University FVL Laboratory, Nanyang Technological University
- Adresse de l'article : https://arxiv . org/abs/2406.14555
- Adresse du projet : https://github.com/xinchengshuai/Awesome-Image-Editing
1. Motivation de la recherche1.1. Dans la vraie vie, les gens ont une demande croissante d'outils d'édition d'images intelligents contrôlables et de haute qualité. Par conséquent, il est nécessaire de résumer et de comparer systématiquement les méthodes et les caractéristiques techniques dans cette direction. 1.2, les algorithmes d'édition actuels et les révisions associées limitent le scénario d'édition à conserver la plupart des informations sémantiques de bas niveau dans l'image qui ne sont pas liées à l'édition. Pour cette raison, il est nécessaire d'élargir la portée de la tâche d'édition. et discutez de l'édition dans une perspective plus générale. 1.3, En raison de la diversité des besoins et des scénarios, il est nécessaire de formaliser le processus d'édition dans un cadre unifié et de fournir aux utilisateurs un espace de conception pour s'adapter aux différents objectifs d'édition. 2. En quoi les points saillants de la revue diffèrent-ils de la revue éditoriale actuelle ? 2.1 La définition et la portée de la discussion sur les tâches d'édition. Par rapport aux algorithmes existants et aux revues d’édition précédentes, cet article définit la tâche d’édition d’images de manière plus large. Plus précisément, cet article divise les tâches d'édition en groupes de scènes sensibles au contenu et sans contenu. Les scènes du groupe sensible au contenu sont les principales tâches discutées dans la littérature précédente. Leur point commun est de conserver certaines caractéristiques sémantiques de bas niveau dans l'image, telles que l'édition du contenu en pixels des zones non pertinentes ou de la structure de l'image. De plus, nous avons été pionniers dans l'inclusion de tâches de personnalisation dans le groupe de scénarios sans contenu, en utilisant ce type de tâche qui conserve une sémantique de haut niveau (telle que les informations sur l'identité du sujet ou d'autres attributs à granularité fine) en complément des scénarios d'édition réguliers. .Réapprovisionner. 
. En raison de la diversité des scénarios d’édition, les algorithmes existants ne peuvent pas répondre correctement à tous les besoins. Nous formalisons donc le processus d'édition existant dans un cadre unifié, exprimé comme une combinaison de deux familles d'algorithmes. En outre, nous avons également analysé les caractéristiques et les scénarios d'adaptation de différentes combinaisons à travers des expériences qualitatives et quantitatives, offrant aux utilisateurs un bon espace de conception pour s'adapter aux différents objectifs d'édition. Dans le même temps, ce cadre fournit également aux chercheurs une meilleure référence pour concevoir des algorithmes plus performants.
2.3 exhaustivité de la discussion. Nous avons recherché plus de 300 articles connexes et expliqué systématiquement et de manière complète l'application de divers modes de signaux de contrôle dans différents scénarios. Pour les méthodes d'édition basées sur la formation, cet article fournit également des stratégies pour injecter des images sources dans les modèles T2I dans divers scénarios. En outre, nous avons également discuté de l'application de la technologie d'édition d'images dans le domaine vidéo, permettant aux lecteurs de comprendre rapidement le lien entre les algorithmes d'édition dans différents domaines. 3. Un cadre unifié pour les algorithmes d'édition généraux
3.1 Algorithme d'inversion. L'algorithme d'inversion encode l'ensemble d'images source
dans un espace de fonctionnalités ou de paramètres spécifique, obtient la représentation correspondante  (indice d'inversion) et utilise la description du texte source correspondant
(indice d'inversion) et utilise la description du texte source correspondant 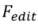 comme identifiant de l'image source. Y compris deux types d'algorithmes d'inversion : basés sur le réglage
comme identifiant de l'image source. Y compris deux types d'algorithmes d'inversion : basés sur le réglage et basés sur l'avant
. Cela peut être formalisé comme :
Inversion basée sur le réglage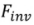 L'ensemble d'images source est implanté dans la distribution de génération du modèle de diffusion via le processus d'entraînement à la diffusion d'origine. Le processus de formalisation est le suivant :
L'ensemble d'images source est implanté dans la distribution de génération du modèle de diffusion via le processus d'entraînement à la diffusion d'origine. Le processus de formalisation est le suivant : 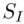
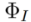
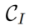
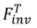
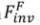 où
où est le paramètre apprenable introduit, et
. 

 L'inversion basée sur l'avant
L'inversion basée sur l'avant
est utilisée pour restaurer le bruit dans un certain chemin aller (
) dans le processus inverse (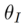 ) du modèle de diffusion. Le processus de formalisation est :
) du modèle de diffusion. Le processus de formalisation est : 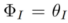
où 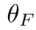 est le paramètre introduit dans la méthode, utilisé pour minimiser
est le paramètre introduit dans la méthode, utilisé pour minimiser 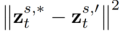 , où
, où 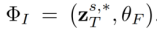 . 3.2.Algorithme d'édition. L'algorithme d'édition
. 3.2.Algorithme d'édition. L'algorithme d'édition 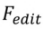 génère le résultat d'édition final
génère le résultat d'édition final 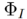 basé sur
basé sur 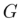 et l'ensemble de conseils multimodaux
et l'ensemble de conseils multimodaux 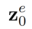 . Algorithmes d'édition, notamment basés sur l'attention
. Algorithmes d'édition, notamment basés sur l'attention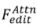 , basés sur le mélange
, basés sur le mélange , basés sur les scores
, basés sur les scores et basés sur l'optimisation
et basés sur l'optimisation . Il peut être formalisé comme :
. Il peut être formalisé comme : 
En particulier, pour chaque étape du processus inverse, 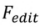 effectue les opérations suivantes :
effectue les opérations suivantes : 
où les opérations en 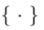 représentent l'intervention de l'algorithme d'édition dans l'échantillonnage du modèle de diffusion processus
représentent l'intervention de l'algorithme d'édition dans l'échantillonnage du modèle de diffusion processus  , utilisé pour assurer la cohérence de l'image éditée
, utilisé pour assurer la cohérence de l'image éditée  avec l'ensemble d'images source
avec l'ensemble d'images source  , et pour refléter la transformation visuelle spécifiée par les conditions de guidage dans
, et pour refléter la transformation visuelle spécifiée par les conditions de guidage dans  . Plus précisément, nous traitons le processus d'édition sans intervention comme une version normale de l'algorithme d'édition
. Plus précisément, nous traitons le processus d'édition sans intervention comme une version normale de l'algorithme d'édition . Il est formalisé ainsi :
. Il est formalisé ainsi :
Le processus formel de Édition basée sur l'attention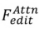 : Le processus formel de
: Le processus formel de 
Édition basée sur le mélange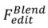 : Le processus formel de
: Le processus formel de 
Édition basée sur la partition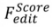 :
: 
Édition basée sur l'optimisation Le processus de formalisation de  :
: 
3.3 Méthode d'édition basée sur la formation. Contrairement aux méthodes sans formation, les algorithmes basés sur la formation apprennent directement le mappage des ensembles d'images sources aux images modifiées dans des ensembles de données spécifiques à une tâche. Ce type d'algorithme peut être considéré comme une extension de l'inversion basée sur le réglage, qui code l'image source dans une distribution générative via des paramètres supplémentaires introduits. Dans ce type d'algorithme, le plus important est de savoir comment injecter l'image source dans le modèle T2I. Voici les schémas d'injection pour différents scénarios d'édition. Schéma d'injection de tâches sensible au contenu : 
Solution d'injection de tâches sans contenu : . Figure 3. Schéma d'injection de tâches sans contenu 
4. Application du cadre unifié dans les tâches d'édition multimodales Cet article illustre l'application de chaque combinaison dans les tâches d'édition multimodales à travers des expériences qualitatives : Figure 4. À propos de l'application d'édition basée sur l'attention de combinaison d'algorithmes de 
Application de la combinaison d'algorithmes
 Figure 6. Application d'une combinaison d'algorithmes pour l'édition basée sur les scores Veuillez vous référer à l'article original pour une analyse détaillée.
Figure 6. Application d'une combinaison d'algorithmes pour l'édition basée sur les scores Veuillez vous référer à l'article original pour une analyse détaillée.  5. Comparaison de différentes combinaisons dans des scénarios d'édition guidée par texte
5. Comparaison de différentes combinaisons dans des scénarios d'édition guidée par texte

Pour les tâches courantes d'édition guidée par texte, cet article a conçu plusieurs expériences qualitatives difficiles pour illustrer les scénarios d'édition adaptés à différentes combinaisons. En outre, cet article collecte également des ensembles de données difficiles et de haute qualité pour illustrer quantitativement les performances d'algorithmes avancés dans diverses combinaisons dans différents scénarios.  Pour les tâches sensibles au contenu, nous considérons principalement les opérations sur les objets (ajout/suppression/remplacement), les modifications d'attributs et la migration de style. En particulier, nous considérons des contextes expérimentaux difficiles : 1. Édition multi-objectifs. 2. Cas d'utilisation qui ont un plus grand impact sur la disposition sémantique des images. Nous collectons également des images de haute qualité de ces scènes complexes et effectuons une comparaison quantitative complète d’algorithmes de pointe dans différentes combinaisons. Fr Figure 8. La comparaison qualitative de chaque combinaison dans la mission Content-AWARE De gauche à droite, les résultats sont analysés et plus de résultats expérimentaux, veuillez vous référer aux articles originaux.
Pour les tâches sensibles au contenu, nous considérons principalement les opérations sur les objets (ajout/suppression/remplacement), les modifications d'attributs et la migration de style. En particulier, nous considérons des contextes expérimentaux difficiles : 1. Édition multi-objectifs. 2. Cas d'utilisation qui ont un plus grand impact sur la disposition sémantique des images. Nous collectons également des images de haute qualité de ces scènes complexes et effectuons une comparaison quantitative complète d’algorithmes de pointe dans différentes combinaisons. Fr Figure 8. La comparaison qualitative de chaque combinaison dans la mission Content-AWARE De gauche à droite, les résultats sont analysés et plus de résultats expérimentaux, veuillez vous référer aux articles originaux.
Pour les tâches sans contenu, nous envisageons principalement des tâches personnalisées axées sur le sujet. Et considère une variété de scénarios, tels que le changement d'arrière-plan, l'interaction avec des objets, les changements de comportement et les changements de style. Nous avons également défini un grand nombre de modèles de texte d'orientation et mené une analyse quantitative de la performance globale de chaque méthode. Sur c Figure 9. La comparaison qualitative de chaque combinaison dans la mission Content-free De gauche à droite, les résultats des résultats sont analysés et des résultats plus expérimentaux, veuillez vous référer à l'article original. 6. Orientations qui peuvent être recherchées à l'avenir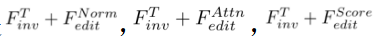 De plus, cet article fournit également une analyse des orientations futures de la recherche. Nous prenons ici comme exemple les défis rencontrés par les tâches sensibles au contenu et les tâches sans contenu. 6.1. Défis des tâches sensibles au contenu. Pour relever le défi des tâches d'édition sensibles au contenu, les méthodes existantes ne peuvent pas gérer simultanément plusieurs scénarios d'édition et signaux de contrôle. Cette limitation oblige les applications à basculer les algorithmes backend appropriés entre différentes tâches. De plus, certaines méthodes avancées ne sont pas conviviales. Certaines méthodes nécessitent que l'utilisateur ajuste des paramètres clés pour obtenir des résultats optimaux, tandis que d'autres nécessitent des entrées fastidieuses telles que des indications de source et de cible ou des masques auxiliaires.
De plus, cet article fournit également une analyse des orientations futures de la recherche. Nous prenons ici comme exemple les défis rencontrés par les tâches sensibles au contenu et les tâches sans contenu. 6.1. Défis des tâches sensibles au contenu. Pour relever le défi des tâches d'édition sensibles au contenu, les méthodes existantes ne peuvent pas gérer simultanément plusieurs scénarios d'édition et signaux de contrôle. Cette limitation oblige les applications à basculer les algorithmes backend appropriés entre différentes tâches. De plus, certaines méthodes avancées ne sont pas conviviales. Certaines méthodes nécessitent que l'utilisateur ajuste des paramètres clés pour obtenir des résultats optimaux, tandis que d'autres nécessitent des entrées fastidieuses telles que des indications de source et de cible ou des masques auxiliaires.
6.2.Défi de tâches sans contenu. Pour les tâches d'édition sans contenu, les méthodes existantes nécessitent de longs processus de réglage lors des tests et souffrent de problèmes de surajustement. Certaines études visent à atténuer ce problème en optimisant un petit nombre de paramètres ou de modèles d'entraînement à partir de zéro. Cependant, ils perdent souvent des détails qui individualisent le sujet ou font preuve d’une faible capacité de généralisation. De plus, les méthodes actuelles ne parviennent pas non plus à extraire des concepts abstraits à partir d’un petit nombre d’images et ne peuvent pas séparer complètement les concepts souhaités des autres éléments visuels.
Pour en savoir plus sur l'orientation de la recherche, vous pouvez consulter l'article original. Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!




 avec l'ensemble d'images source
avec l'ensemble d'images source  , et pour refléter la transformation visuelle spécifiée par les conditions de guidage dans
, et pour refléter la transformation visuelle spécifiée par les conditions de guidage dans  Comment pycharm exécute les fichiers python
Comment pycharm exécute les fichiers python
 Comment restaurer le navigateur IE pour accéder automatiquement à EDGE
Comment restaurer le navigateur IE pour accéder automatiquement à EDGE
 Comment lire des données Excel en HTML
Comment lire des données Excel en HTML
 Utilisation de l'annotation de vitesse
Utilisation de l'annotation de vitesse
 Convertir des fichiers PDF en dessins CAO
Convertir des fichiers PDF en dessins CAO
 Port 1433
Port 1433
 Comment utiliser la fonction plot en Python
Comment utiliser la fonction plot en Python
 Supprimer les informations exif
Supprimer les informations exif








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



