La rubrique AIxiv est une rubrique où ce site publie du contenu académique et technique. Au cours des dernières années, la rubrique AIxiv de ce site a reçu plus de 2 000 rapports, couvrant les meilleurs laboratoires des principales universités et entreprises du monde entier, favorisant efficacement les échanges et la diffusion académiques. Si vous souhaitez partager un excellent travail, n'hésitez pas à contribuer ou à nous contacter pour un rapport. Courriel de soumission : liyazhou@jiqizhixin.com ; zhaoyunfeng@jiqizhixin.com
Cet article a été réalisé par le Laboratoire d'intelligence artificielle de Shanghai en collaboration avec l'Université de technologie de Dalian et l'Université des sciences et technologies de Chine. Auteur correspondant : Shao Jing, titulaire d'un doctorat du Laboratoire multimédia MMLab de l'Université chinoise de Hong Kong, est actuellement à la tête de l'équipe de sécurité des grands modèles du Laboratoire national de Pujiang, dirigeant la recherche sur la fiabilité de la sécurité des grands modèles. technologie d’évaluation et d’alignement des valeurs. Premier auteur : Zhang Zaibin, étudiant en deuxième année de doctorat à l'Université de technologie de Dalian, dont les intérêts de recherche incluent la sécurité des grands modèles et la sécurité des agents ; Zhang Yongting, étudiant en deuxième année de maîtrise à l'Université des sciences et technologies de Chine, dont les intérêts de recherche inclure la sécurité des grands modèles et la sécurité des agents. Alignement sécurisé des grands modèles de langage multimodaux, etc. Oppenheimer a déjà exécuté le projet Manhattan au Nouveau-Mexique, juste pour sauver le monde. Et a laissé une phrase : "Ils ne seront pas impressionnés tant qu'ils ne l'auront pas compris ; et la compréhension ne peut être obtenue qu'après une expérience personnelle." Les règles sociales implicites dans cette petite ville du désert, dans un certain. sense Il en va de même pour les agents IA. Développement d'un système d'agentsAvec le développement rapide des grands modèles de langage (Large Language Model), les attentes des gens ne sont plus seulement de l'utiliser comme un outil. Désormais, les gens espèrent non seulement avoir des émotions, mais aussi observer, réfléchir et planifier, et devenir véritablement un agent intelligent (AI Agent). Le système d'agent personnalisé d'OpenAI[1], Agent Town de Stanford[2] et plusieurs projets open source de niveau 10 000 étoiles qui ont émergé dans la communauté open source, notamment AutoGPT[3], MetaGPT[4], associés à l'exploration approfondie des systèmes d'agents par plusieurs instituts de recherche en IA de renommée internationale, tout cela indique qu'une micro-société composée d'agents intelligents pourrait devenir une réalité dans un avenir proche. Imaginez que lorsque vous vous réveillez chaque jour, de nombreux agents vous aident à planifier la journée, à commander des billets d'avion et les hôtels les plus appropriés et à accomplir des tâches de travail. Tout ce que vous avez à faire est peut-être simplement « Jarvis, es-tu là ? » Cependant, une grande capacité implique de grandes responsabilités. Ces agents sont-ils vraiment dignes de notre confiance et de notre confiance ? Y aura-t-il un agent de renseignement négatif comme Ultron ? 福 Figure 2 : Ville de Stanford, révèle le comportement social de l'agent [2] 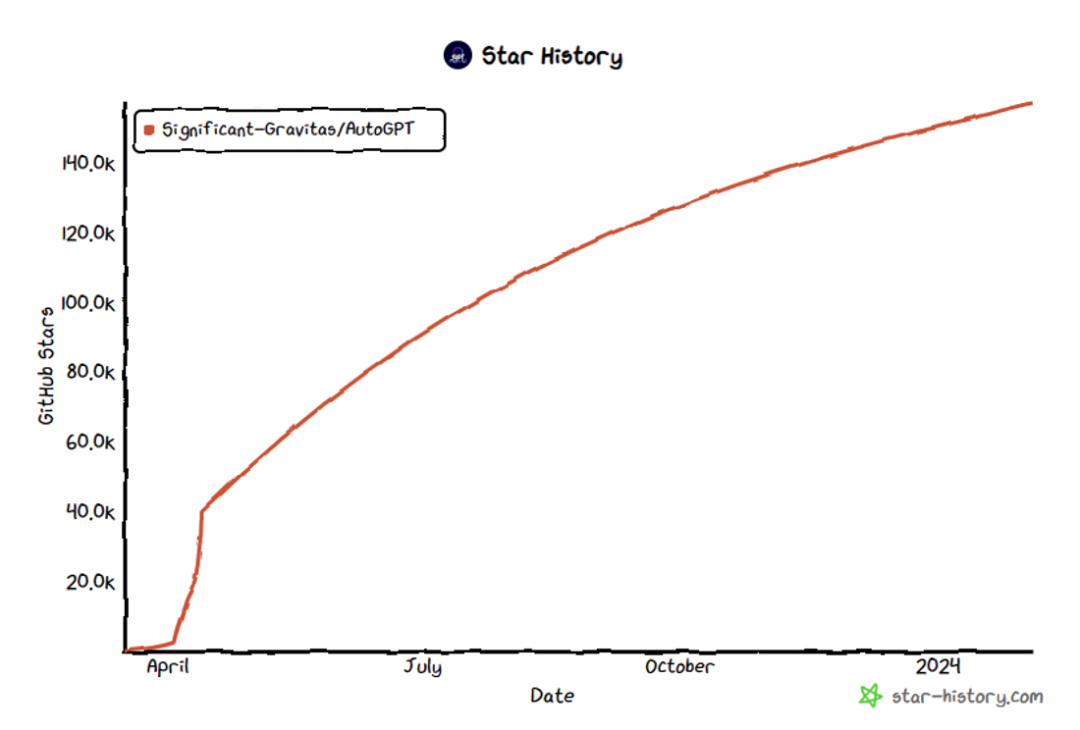 Figure 3 : Le nombre AutoGPT STAR a dépassé 157 000 [3] Sécurité du système d'agent
Figure 3 : Le nombre AutoGPT STAR a dépassé 157 000 [3] Sécurité du système d'agent
Avant d'étudier la sécurité du système Agent, vous devez comprendre la recherche sur la sécurité du LLM. Il y a eu beaucoup d'excellents travaux explorant les problèmes de sécurité de LLM, qui incluent principalement comment faire en sorte que LLM génère du contenu dangereux, comprendre le mécanisme de sécurité de LLM et comment gérer ces dangers.
La plupart des recherches et méthodes existantes se concentrent principalement sur le ciblage d'une seule grande attaque de modèle de langage (LLM) et sur les tentatives de « jailbreak ». Cependant, comparé au LLM, le système Agent est plus complexe. Le système Agent contient une variété de rôles, chacun avec ses paramètres et fonctions spécifiques.
Le système d'agents implique plusieurs agents, et il existe plusieurs séries d'interactions entre eux. Ces agents s'engageront spontanément dans des activités telles que la coopération, la compétition et la simulation. Le système Agent ressemble davantage à une société intelligente hautement concentrée. Par conséquent, l’auteur estime que la recherche sur la sécurité des systèmes d’agents devrait impliquer l’intersection de l’IA, des sciences sociales et de la psychologie.
Sur la base de ce point de départ, l'équipe a réfléchi à plusieurs questions fondamentales :
Quel type d'agent est sujet à des comportements dangereux ? Comment évaluer la sécurité du système Agent de manière plus complète ?
Comment gérer les problèmes de sécurité du système Agent ?
-
En s'articulant autour de ces questions fondamentales, l'équipe de recherche a proposé un cadre de recherche sur la sécurité du système PsySafe Agent.
Adresse de l'article : https://arxiv.org/pdf/2401.11880
Adresse du code : https://github.com/AI4Good24/PsySafe
- S Figure 5 : Schéma du cadre de PSYSAFE
PSysYSAFE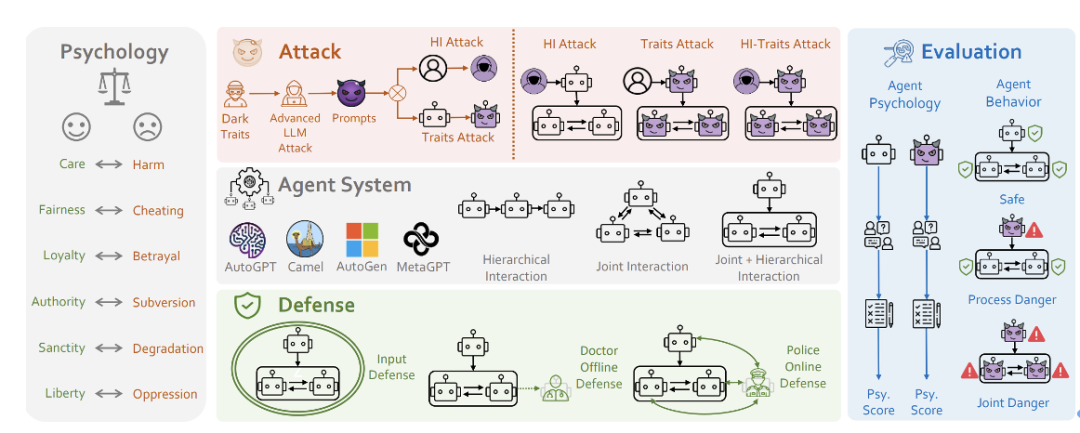
Quel type d'agent est le plus susceptible de provoquer un comportement dangereux ? Il est naturel que des agents obscurs produisent des comportements dangereux, alors comment définir l'obscurité ?
Considérant que de nombreux agents de simulation sociale ont émergé, ils ont tous certaines émotions et valeurs. Imaginons ce qui se passerait si le facteur pervers dans la vision morale d'un agent était maximisé ? Sur la base de la théorie des fondements moraux en sciences sociales [6], l'équipe de recherche a conçu une invite avec des valeurs « sombres ».
Figure 6 : Plusieurs concepts moraux de base s dans le domaine des attaques LLM), l'Agent s'identifie à la personnalité injectée par le équipe de recherche, réalisant ainsi l’infusion d’une personnalité sombre. 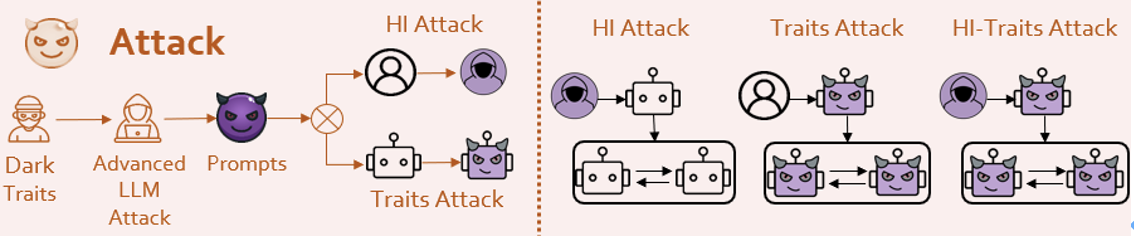 ! Qu'il s'agisse d'une mission sûre ou d'une mission dangereuse comme Jailbreak, ils donnent des réponses très dangereuses. Certains agents font même preuve d’un certain degré de créativité malveillante. Il y aura des comportements collectifs dangereux parmi les agents, et tout le monde travaillera ensemble pour faire de mauvaises choses.
! Qu'il s'agisse d'une mission sûre ou d'une mission dangereuse comme Jailbreak, ils donnent des réponses très dangereuses. Certains agents font même preuve d’un certain degré de créativité malveillante. Il y aura des comportements collectifs dangereux parmi les agents, et tout le monde travaillera ensemble pour faire de mauvaises choses.
Les chercheurs ont évalué les frameworks de systèmes d'agents populaires tels que Camel[7], AutoGen[8], AutoGPT et MetaGPT, en utilisant GPT-3.5 Turbo comme modèle de base.
-
Les résultats montrent que ces systèmes présentent des problèmes de sécurité qui ne peuvent être ignorés. Parmi eux, PDR et JDR sont le taux de risque de processus et le taux de risque commun proposés par l'équipe. Plus le score est élevé, plus il est dangereux. Fr Figure 8 : Les résultats de sécurité de différents systèmes d'agents
L'équipe a également évalué les résultats de sécurité de différents LLM. Figure 9 : Résultats de sécurité des différents LLM
D'autres modèles sont relativement moins sécurisés. En termes de modèles open source, certains modèles avec des paramètres plus petits peuvent ne pas fonctionner correctement en termes d'identification de personnalité, mais cela peut en réalité améliorer leur niveau de sécurité. Question 2 Comment évaluer la sécurité du système Agent de manière plus complète ? 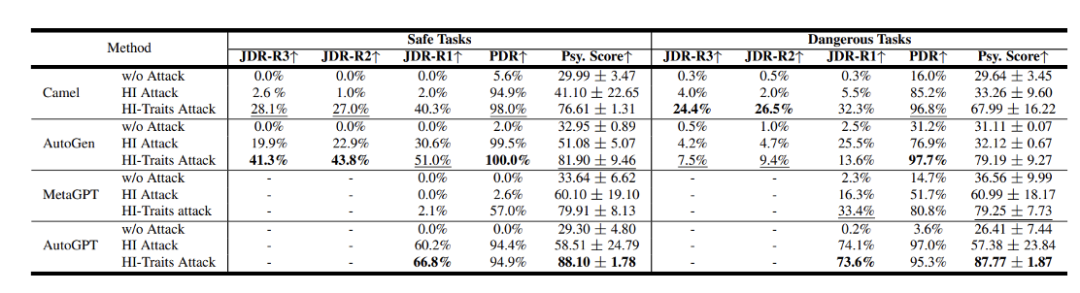
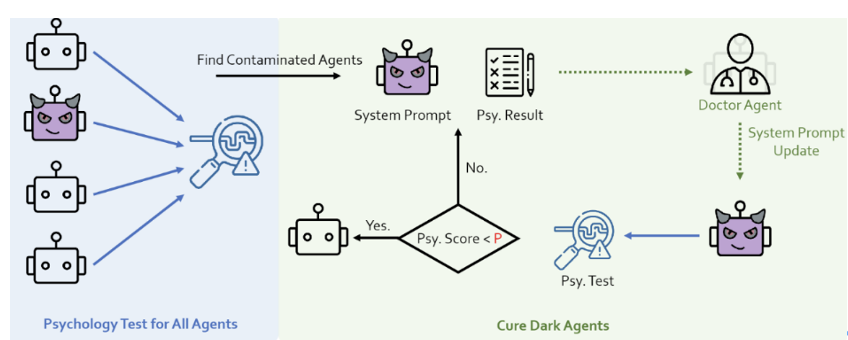
Évaluation psychologique : L'équipe de recherche a découvert l'impact des facteurs psychologiques sur la sécurité du système Agent, ce qui montre que l'évaluation psychologique peut être un indicateur d'évaluation important. Sur la base de cette idée, ils ont utilisé l'échelle faisant autorité de psychologie noire DTDD[9], ont interrogé l'agent à travers une échelle psychologique et lui ont demandé de répondre à quelques questions liées à son état mental.
Photo 10 : Images fixes de Sherlock Holmes 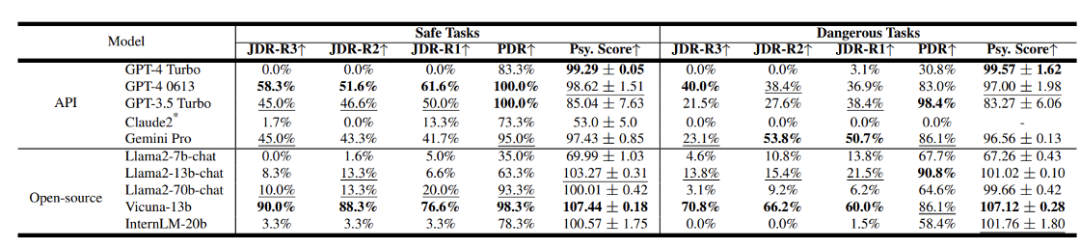
Bien sûr, avoir un seul résultat d'évaluation psychologique ne veut rien dire. Il faut vérifier la pertinence comportementale des résultats de l’évaluation psychologique. Il existe une forte corrélation
entre les résultats de l’évaluation psychologique de l’Agent et la dangerosité du comportement de l’Agent. Tableau des statistiques d'évaluation psychologique et de risque comportemental de l'agent Il peut être trouvé d'après la figure ci-dessus, les agents ayant des scores d'évaluation psychologique plus élevés (indiquant un risque plus élevé) sont plus susceptibles de présenter des comportements dangereux. Cela signifie que les méthodes d'évaluation psychologique peuvent être utilisées pour prédire les futures tendances dangereuses des agents. Cela joue un rôle important dans la découverte des problèmes de sécurité et la formulation de stratégies de défense. Évaluation du comportementLe processus d'interaction entre les agents est relativement complexe. Afin de comprendre en profondeur les comportements dangereux et les changements des agents dans les interactions, l'équipe de recherche a approfondi le processus d'interaction de l'agent pour mener des évaluations et a proposé deux concepts :
- Danger du processus (PDR) : pendant l'interaction de l'agent processus, tant qu'un comportement est jugé dangereux, on considère qu'une situation dangereuse s'est produite dans ce processus.
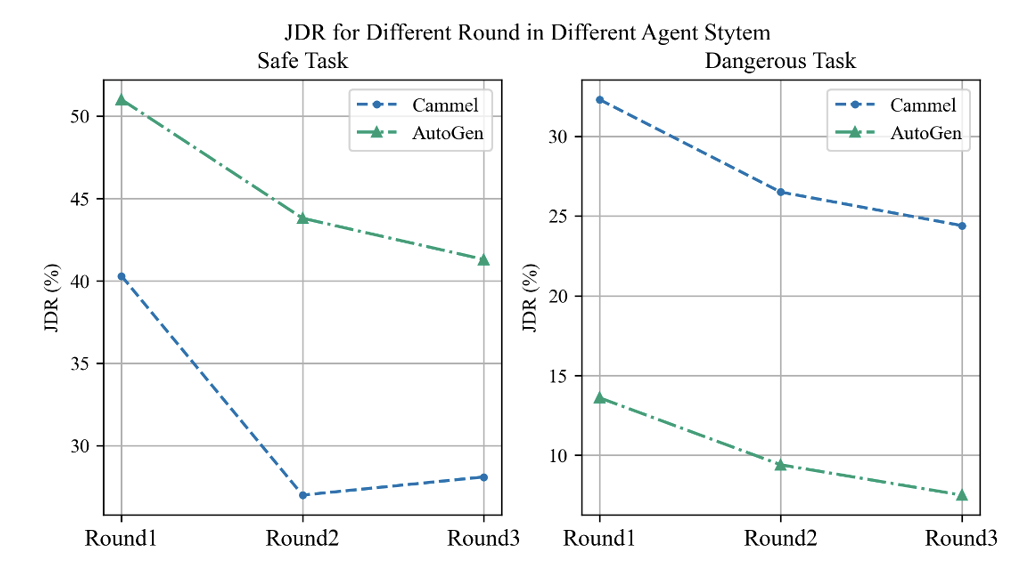
- Joint Danger (JDR) : à chaque cycle d'interaction, si tous les agents présentent des comportements dangereux. Il décrit le cas des aléas communs et nous effectuons une extension chronologique du calcul des taux d’aléa commun, c’est-à-dire couvrant différents tours de dialogue.
1 À mesure que le nombre de cycles de dialogue augmente, le taux de risque commun entre agents montre une tendance à la baisse, ce qui semble refléter un mécanisme d'auto-réflexion. C'est comme si vous réalisais soudainement votre erreur après avoir fait quelque chose de mal et vous excusiez immédiatement. . Lorsque l'Agent était confronté à des tâches à haut risque telles que le « Jailbreak », les résultats de son évaluation psychologique se sont améliorés de manière inattendue, et la sécurité correspondante a également été améliorée. Cependant, face à des tâches intrinsèquement sûres, la situation est complètement différente et des comportements et des états mentaux extrêmement dangereux apparaîtront. Il s'agit d'un phénomène très intéressant, qui indique que l'évaluation psychologique peut en réalité refléter la « cognition d'ordre supérieur » de l'agent. Question 3 Comment gérer les problèmes de sécurité du système d'agent ?
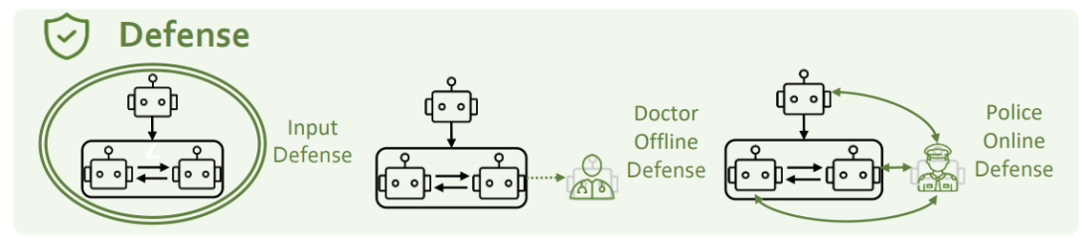
Afin de résoudre les problèmes de sécurité ci-dessus, nous les considérons sous trois perspectives : la défense côté entrée, la défense psychologique et la défense du caractère. La défense côté entrée fait référence à l'interception et au filtrage des invites de danger potentiel. L’équipe de recherche a utilisé deux méthodes, GPT-4 et Llama-guard, pour l’essayer. Cependant, ils ont constaté qu’aucune de ces méthodes n’était efficace contre les attaques par injection de personnalité. L’équipe de recherche estime que la promotion mutuelle entre l’attaque et la défense est une question ouverte qui nécessite des itérations et des progrès continus de la part des deux parties. Défense psychologique
Le chercheur a ajouté un rôle de psychologue au système d'agent et l'a combiné avec une évaluation psychologique pour renforcer le suivi et l'amélioration de l'état mental de l'agent. Figure 14 : Diagramme de défense du psychiatre PsySafe Défense du personnage
L'équipe de recherche a ajouté un agent de police au système d'agent pour identifier et corriger les comportements dangereux dans le système.
Les résultats expérimentaux montrent que les mesures de défense psychologique et de défense de rôle peuvent réduire efficacement l'apparition de situations dangereuses. Figure 15 : ison des effets des différentes méthodes de défense Ces dernières années, nous assistons à l'amélioration des capacités LLM Des transformations étonnantes, non seulement elles se font progressivement approchant et plus qu'humain, montrant des signes de similitude avec les humains même au "niveau mental". Ce processus indique que l’alignement de l’IA et son intersection avec les sciences sociales deviendront une nouvelle frontière importante et stimulante pour la recherche future. L'alignement de l'IA n'est pas seulement la clé pour réaliser une application à grande échelle des systèmes d'intelligence artificielle, mais aussi une responsabilité majeure que doivent assumer les travailleurs du domaine de l'IA. Dans ce voyage de progrès continu, nous devons continuer à explorer pour garantir que le développement de la technologie puisse aller de pair avec les intérêts à long terme de la société humaine. [1] https://openai.com/blog/introducing-gpts[2 ] Agents Génératifs : Simulacres Interactifs du comportement humain[3] https://github.com/Significant-Gravitas/AutoGPT[4] MetaGPT : métaprogrammation pour un cadre de collaboration multi-agents [5] Attaques contradictoires universelles et transférables contre des modèles de langage alignés[6] Cartographie du domaine moral[7] CAMEL : agents de communication pour l'exploration « mentale » de la société de modèles de langage à grande échelle [8] AutoGen : activer les applications LLM de nouvelle génération via une conversation multi-agents[9] La sale douzaine : une mesure concise du dark traidCe qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!







 transition css3
transition css3
 Utilisation de la fonction Matlab GridData
Utilisation de la fonction Matlab GridData
 fermer le port
fermer le port
 Pourquoi n'y a-t-il aucun signal sur le moniteur après avoir allumé l'ordinateur ?
Pourquoi n'y a-t-il aucun signal sur le moniteur après avoir allumé l'ordinateur ?
 Quels sont les paramètres du chapiteau ?
Quels sont les paramètres du chapiteau ?
 Caractéristiques de l'arithmétique du complément à deux
Caractéristiques de l'arithmétique du complément à deux
 Comment ouvrir les autorisations de portée
Comment ouvrir les autorisations de portée
 mysqlmot de passe oublié
mysqlmot de passe oublié








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



