


À la pointe de la technologie logicielle, le groupe de l'UIUC Zhang Lingming, en collaboration avec des chercheurs de l'organisation BigCode, a récemment annoncé le modèle de grand code StarCoder2-15B-Instruct.
Cette réalisation innovante a réalisé une percée significative dans la tâche de génération de code, dépassant avec succès CodeLlama-70B-Instruct et atteignant le sommet de la liste des performances de génération de code.

La particularité de StarCoder2-15B-Instruct est sa pure stratégie d'auto-alignement. L'ensemble du processus de formation est ouvert, transparent et complètement autonome et contrôlable.
Le modèle génère des milliers d'instructions via StarCoder2-15B et affine le modèle de base StarCoder-15B en réponse. Il n'a pas besoin de s'appuyer sur une annotation manuelle coûteuse des données, ni d'obtenir des données auprès de grandes entreprises commerciales. des modèles tels que GPT4, évitant ainsi les problèmes potentiels de droits d'auteur.
Dans le test HumanEval, StarCoder2-15B-Instruct s'est démarqué avec un score Pass@1 de 72,6 %, qui a été amélioré par rapport aux 72,0 % de CodeLlama-70B-Instruct.
Dans l'évaluation sur l'ensemble de données LiveCodeBench, ce modèle auto-aligné a même surpassé les modèles similaires formés sur les données générées par GPT-4. Ce résultat démontre qu'un grand modèle peut également apprendre efficacement à s'aligner de la même manière que les humains en utilisant des données au sein de sa propre distribution, sans s'appuyer sur la distribution biaisée du grand modèle provenant d'un enseignant externe.
La mise en œuvre réussie de ce projet a reçu le fort soutien du groupe de recherche d'Arjun Guha de la Northeastern University, de l'Université de Californie à Berkeley, de ServiceNow et de Hugging Face ainsi que d'autres institutions.
Le processus de génération de données de StarCoder2-Instruct comprend principalement trois étapes principales :
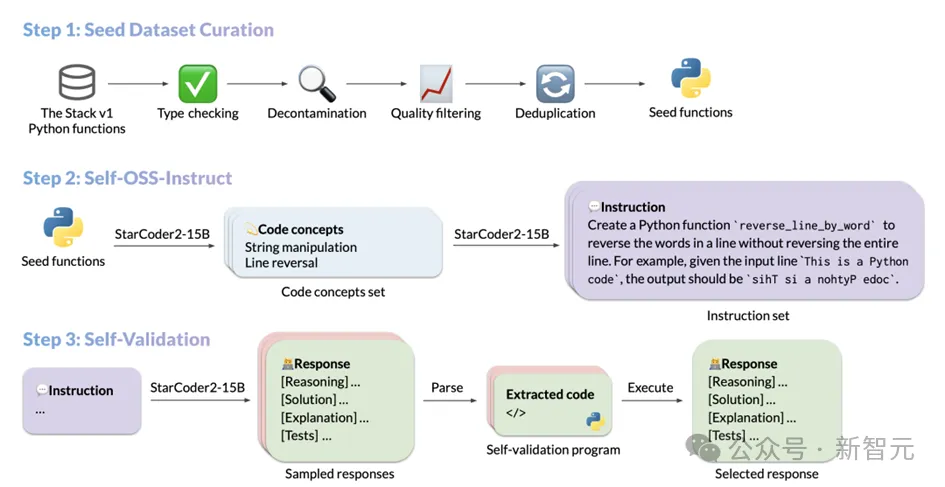
1. Collecte d'extraits de code de départ : L'équipe de The Stack v. 1 Filtrez des fonctions de départ diverses et de haute qualité à partir d’un corpus massif de codes sources sous licence. Grâce à un filtrage et une sélection stricts, la qualité et la diversité des codes de départ sont garanties ;
2. Génération d'instructions diverses : Basé sur différents concepts de programmation dans la fonction de départ, StarCoder2-15B-Instruct peut créer des instructions diverses et variées. instructions de code réalistes. Ces instructions couvrent un large éventail de scénarios de programmation, de la désérialisation des données à la concaténation de listes, en passant par la récursivité, etc.
3. Génération de réponses de haute qualité : Pour chaque instruction, le modèle adopte une compilation et une exécution. méthode d'auto-vérification guidée, garantissant que les réponses générées sont exactes et de haute qualité.
Les opérations spécifiques de chaque étape sont les suivantes :
Afin d'améliorer la capacité du modèle de code à suivre les instructions, le modèle doit avoir une exposition approfondie et apprendre différents principes de programmation avec des opérations pratiques. StarCoder2-15B-Instruct s'inspire d'OSS-Instruct et s'inspire d'extraits de code open source, en particulier des fonctions de départ Python bien formatées et clairement structurées dans The Stack V1.
Lors de la construction de son ensemble de données de base, StarCoder2-15B-Instruct a mené une exploration approfondie de The Stack V1, sélectionné toutes les fonctions Python avec des instructions documentées, et analysé et déduit automatiquement les fonctions requises par ces fonctions à l'aide de la fonction d'importation automatique Dépendances.
Afin de garantir la pureté et la haute qualité de l'ensemble de données, StarCoder2-15B-Instruct a soigneusement filtré et examiné toutes les fonctions sélectionnées.
Tout d'abord, une vérification de type stricte est effectuée via le vérificateur de type Pyright, excluant toutes les fonctions susceptibles de produire des erreurs statiques, garantissant ainsi l'exactitude et la fiabilité des données.
Ensuite, grâce à une technologie précise de correspondance de chaînes, les codes et les indices potentiellement liés à l'ensemble de données d'évaluation sont identifiés et éliminés pour éviter la contamination des données. En termes de qualité de document, StarCoder2-15B-Instruct adopte un mécanisme de filtrage unique.
Il utilise ses propres capacités d'évaluation pour afficher 7 exemples d'invites au modèle, permettant au modèle de juger si la qualité du document de chaque fonction répond à la norme, décidant ainsi de l'inclure ou non dans l'ensemble de données final.
Cette méthode basée sur l'auto-jugement du modèle améliore non seulement l'efficacité et la précision du filtrage des données, mais garantit également la haute qualité et la cohérence de l'ensemble de données.
Enfin, afin d'éviter la redondance et la duplication des données, StarCoder2-15B-Instruct utilise MinHash et des algorithmes de hachage sensibles à la localité pour dédupliquer les fonctions dans l'ensemble de données. En définissant un seuil de similarité Jaccard de 0,5, les fonctions en double présentant une similarité élevée sont efficacement supprimées, garantissant ainsi l'unicité et la diversité de l'ensemble de données.
Après cette série de criblage et de filtration fins, StarCoder2-15B-Instruct a finalement sélectionné 250 000 fonctions de haute qualité parmi 5 millions de fonctions Python avec des documents comme ensemble de données de départ. Cette approche est fortement inspirée du processus de collecte de données MultiPL-T.
Lorsque StarCoder2-15B-Instruct complète la collection de fonctions de départ, il utilise la technologie Self-OSS-Instruct pour créer diverses instructions de programmation. Le cœur de cette technologie est de permettre au modèle de base StarCoder2-15B de générer de manière autonome les instructions correspondantes pour un fragment de code source donné grâce à l'apprentissage contextuel.
Pour atteindre cet objectif, StarCoder2-15B-Instruct a soigneusement conçu 16 exemples, chaque exemple suit la structure de (extraits de code, concepts, instructions). Le processus de génération d'instructions est subdivisé en deux étapes :
Identification du concept de code : dans cette étape, StarCoder2-15B effectuera une analyse approfondie de chaque fonction de départ et générera une liste contenant les concepts de code clés de la fonction. Ces concepts couvrent largement les principes et techniques de base dans le domaine de la programmation, tels que la correspondance de modèles, la conversion de types de données, etc., qui présentent une valeur pratique extrêmement élevée pour les développeurs.
Création d'instructions : basé sur le concept de code reconnu, StarCoder2-15B générera en outre les instructions de tâche de codage correspondantes. Ce processus est conçu pour garantir que les instructions générées reflètent avec précision les fonctionnalités et les exigences de base du fragment de code.
Grâce au processus ci-dessus, StarCoder2-15B-Instruct a finalement généré avec succès jusqu'à 238 000 instructions, enrichissant considérablement son ensemble de données de formation et fournissant un solide support pour ses performances dans les tâches de programmation.
Après avoir obtenu les instructions générées par Self-OSS-Instruct, la tâche clé de StarCoder2-15B-Instruct est de faire correspondre une réponse de haute qualité pour chaque instruction .
Traditionnellement, les gens ont tendance à s'appuyer sur des modèles d'enseignants plus puissants tels que GPT-4 pour obtenir ces réponses, mais non seulement cette approche peut se heurter à des difficultés de licence de droits d'auteur, mais les modèles externes ne sont pas toujours à portée de main ou précis. Plus important encore, le recours à des modèles externes peut introduire des différences de répartition entre les enseignants et les élèves, ce qui peut affecter l'exactitude des résultats finaux.
Pour surmonter ces défis, StarCoder2-15B-Instruct introduit un mécanisme d'auto-vérification. L'idée principale de ce mécanisme est de permettre au modèle StarCoder2-15B de créer lui-même des cas de test correspondants après avoir généré une réponse en langage naturel. Ce processus est similaire au processus d'auto-test qu'un développeur suit après avoir écrit du code.
Plus précisément, pour chaque instruction, StarCoder2-15B générera 10 échantillons contenant des réponses en langage naturel et des cas de test correspondants. StarCoder2-15B-Instruct exécute ensuite ces cas de test dans un environnement sandbox pour vérifier la validité des réponses. Tous les échantillons qui échouent lors de l’exécution du test seront filtrés.
Après ce processus de sélection strict, StarCoder2-15B-Instruct en sélectionnera au hasard une parmi les réponses testées de chaque instruction et l'ajoutera à l'ensemble de données SFT final. Tout au long du processus, StarCoder2-15B-Instruct a généré un total de 2,4 millions d'échantillons de réponses (10 échantillons par instruction) pour 238 000 instructions. Après avoir adopté une stratégie d'échantillonnage de 0,7, 500 000 échantillons ont réussi le test d'exécution.
Afin de garantir la diversité et la qualité de l'ensemble de données, StarCoder2-15B-Instruct effectue également un traitement de déduplication. Au final, il restait 50 000 commandes, chacune avec une réponse de haute qualité sélectionnée au hasard, testée et vérifiée. Ces réponses constituent l'ensemble de données SFT final de StarCoder2-15B-Instruct, fournissant une base solide pour la formation et l'application ultérieures du modèle.
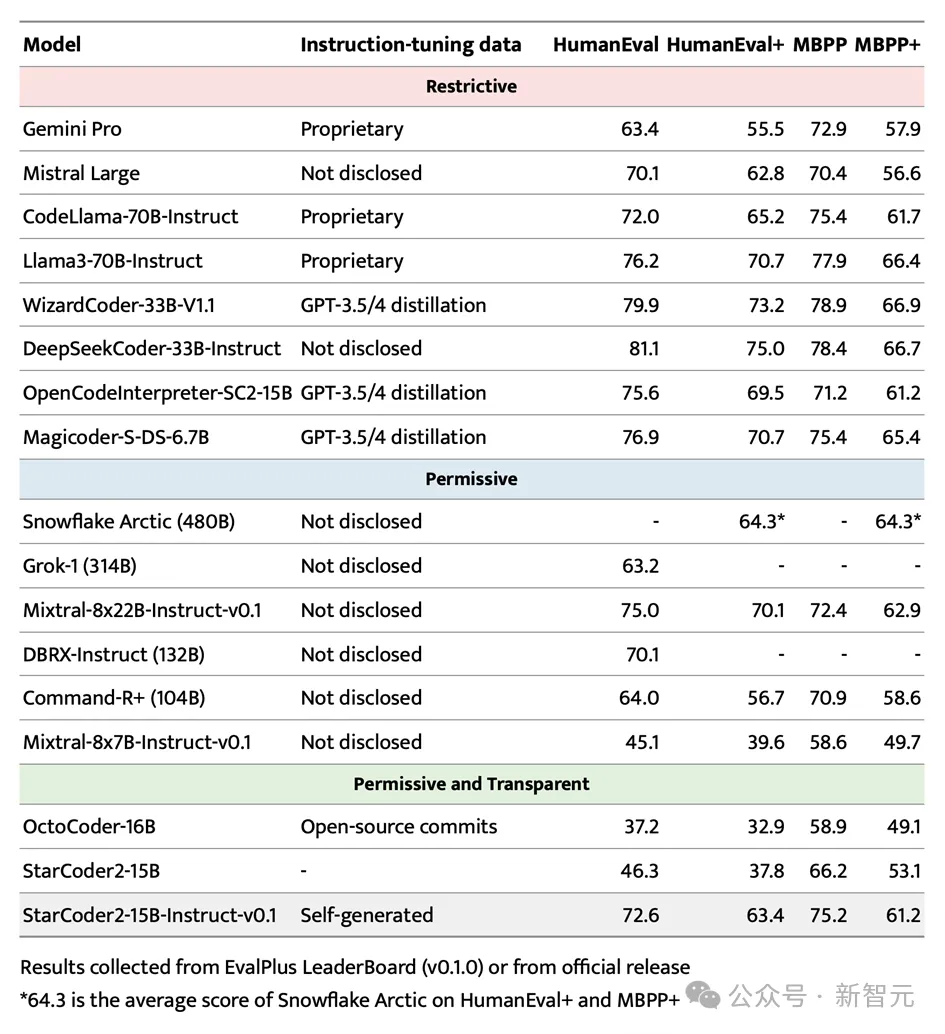
Dans le test de référence très médiatisé EvalPlus, StarCoder2-15B-Instruct s'est démarqué avec succès et est devenu le système autonome le plus performant en raison de ses avantages d'échelle . Grands modèles contrôlables.
Non seulement il surpasse les plus grands Grok-1 Command-R+ et DBRX, mais il correspond également aux leaders de l'industrie tels que Snowflake Arctic 480B et Mixtral-8x22B-Instruct.
Il convient de mentionner que StarCoder2-15B-Instruct est le premier grand modèle de code indépendant à obtenir un score de 70+ au benchmark HumanEval. Son processus de formation est totalement transparent et l'utilisation des données et des méthodes est conforme aux lois et réglementations. .
Dans le domaine des grands modèles de code contrôlable indépendant, StarCoder2-15B-Instruct a largement dépassé le précédent leader OctoCoder, prouvant sa position de leader dans ce domaine.
Même comparé aux modèles grands et puissants avec des licences restreintes tels que Gemini Pro et Mistral Large, StarCoder2-15B-Instruct affiche toujours d'excellentes performances et est à égalité avec CodeLlama-70B-Instruct. Ce qui est encore plus remarquable, c'est que StarCoder2-15B-Instruct s'appuie entièrement sur des données auto-générées pour la formation, mais ses performances sont comparables à celles d'OpenCodeInterpreter-SC2-15B basées sur le réglage fin des données GPT-3.5/4.
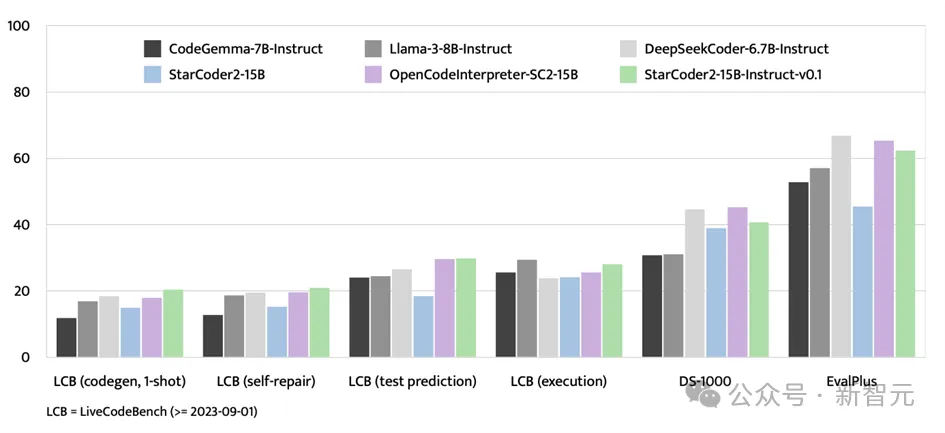
En plus du test de référence EvalPlus, StarCoder2-15B-Instruct a également montré une forte solidité sur les plateformes d'évaluation telles que LiveCodeBench et DS-1000.
LiveCodeBench se concentre sur l'évaluation des défis de codage émergents après le 1er septembre 2023, et StarCoder2-15B-Instruct obtient les meilleurs résultats sur cette référence et devance constamment OpenCodeInterpreter affiné à l'aide des données GPT-4 -SC2-15B
Bien que DS-1000 se concentre sur les tâches de science des données, StarCoder2-15B-Instruct fonctionne toujours très bien sur ce benchmark, montrant relativement peu de problèmes de science des données dans les données de formation.
La sortie de StarCoder2-15B-Instruct-v0.1 marque les progrès des chercheurs dans l'auto-réglage du modèle de code Une étape importante a été franchie dans le domaine de l’excellence. La pratique réussie de ce modèle brise la limitation précédente consistant à devoir s'appuyer sur de puissants modèles d'enseignants externes tels que GPT-4, et démontre que des modèles de code offrant d'excellentes performances peuvent également être construits grâce à l'auto-ajustement.
Le cœur de StarCoder2-15B-Instruct-v0.1 réside dans l'application réussie de sa stratégie d'auto-alignement dans le domaine de l'apprentissage du code. Cette stratégie améliore non seulement les performances du modèle, mais plus important encore, elle donne au modèle une plus grande transparence et interprétabilité. Cela contraste fortement avec d'autres grands modèles tels que Snowflake-Arctic, Grok-1, Mixtral-8x22B, DBRX et CommandR+, qui, bien que puissants, limitent souvent leur portée et leur fiabilité en raison d'un manque de transparence.
Ce qui est encore plus gratifiant, c'est que StarCoder2-15B-Instruct-v0.1 a rendu son ensemble de données et l'ensemble de son processus de formation - y compris la collecte de données et le processus de formation - entièrement open source. Cette décision démontre non seulement l'esprit ouvert des chercheurs, mais pose également une base solide pour la recherche et le développement futurs dans ce domaine.
Il y a des raisons de croire que la pratique réussie de StarCoder2-15B-Instruct-v0.1 incitera davantage de chercheurs à investir dans la recherche dans le domaine de l'auto-réglage des modèles de code et favorisera le progrès technologique et l'expansion des applications dans ce domaine. champ. Dans le même temps, nous espérons également que des résultats plus innovants continueront à émerger dans ce domaine, donnant un nouvel élan au développement intelligent de la société humaine.
Le professeur Zhang Lingming de l'UIUC est un universitaire avec de profondes connaissances à l'intersection du génie logiciel, du langage de programmation et de l'apprentissage automatique. Le groupe de recherche qu’il dirige s’engage depuis longtemps dans la recherche sur la synthèse, la réparation et la vérification automatiques de logiciels basés sur de grands modèles d’IA, ainsi que sur l’amélioration de la fiabilité des systèmes d’apprentissage automatique.
Récemment, l'équipe a publié un certain nombre de grands modèles de code innovants et d'ensembles de données de référence de test, et a pris les devants en proposant une série de grandes technologies de test et de réparation de logiciels basées sur des modèles. Dans le même temps, des milliers de nouveaux défauts et failles ont été découverts avec succès dans plusieurs systèmes logiciels réels, contribuant ainsi de manière significative à l'amélioration de la qualité des logiciels.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Comment connecter PHP à la base de données mssql
Comment connecter PHP à la base de données mssql
 Quels sont les outils de développement asp ?
Quels sont les outils de développement asp ?
 référencement wordpress
référencement wordpress
 Maximiser la page Web
Maximiser la page Web
 Quelles sont les nouvelles fonctionnalités de Hongmeng 3.0 ?
Quelles sont les nouvelles fonctionnalités de Hongmeng 3.0 ?
 Que faire si le système d'installation ne trouve pas le disque dur
Que faire si le système d'installation ne trouve pas le disque dur
 mesures de protection de la sécurité du serveur cdn
mesures de protection de la sécurité du serveur cdn
 Comment intégrer l'idée avec Tomcat
Comment intégrer l'idée avec Tomcat








![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



