


Graph Retrieval Enhanced Generation (Graph RAG) devient progressivement populaire et est devenu un complément puissant aux méthodes de recherche vectorielles traditionnelles. Cette méthode tire parti des caractéristiques structurelles des bases de données graphiques pour organiser les données sous forme de nœuds et de relations, améliorant ainsi la profondeur et la pertinence contextuelle des informations récupérées. Les graphiques présentent un avantage naturel dans la représentation et le stockage d’informations diverses et interdépendantes, et peuvent facilement capturer des relations et des propriétés complexes entre différents types de données. Les bases de données vectorielles sont incapables de gérer ce type d'informations structurées et se concentrent davantage sur le traitement de données non structurées représentées par des vecteurs de grande dimension. Dans les applications RAG, la combinaison de données graphiques structurées et de recherche de vecteurs de texte non structuré nous permet de profiter des avantages des deux en même temps, ce dont discutera cet article.
Créer un graphe de connaissances est souvent l'étape la plus difficile pour exploiter la puissance de la représentation graphique des données. Cela nécessite de collecter et d’organiser des données, ce qui nécessite une compréhension approfondie des connaissances du domaine et de la modélisation graphique. Afin de simplifier ce processus, vous pouvez vous référer à des projets existants ou utiliser LLM pour créer un graphe de connaissances, puis vous concentrer sur la récupération et le rappel pour améliorer la phase de génération de LLM. Pratiquons le code pertinent ci-dessous.
Afin de stocker des données de graphe de connaissances, vous devez d'abord créer une instance Neo4j. Le moyen le plus simple est de lancer une instance gratuite sur Neo4j Aura, qui fournit une version cloud de la base de données Neo4j. Bien sûr, vous pouvez également en démarrer un localement via Docker, puis importer les données graphiques dans la base de données Neo4j.
Ce qui suit est un exemple d'exécution de docker localement :
docker run -d \--restart always \--publish=7474:7474 --publish=7687:7687 \--env NEO4J_AUTH=neo4j/000000 \--volume=/yourdockerVolume/neo4j:/data \neo4j:5.19.0
Dans la démonstration, nous pouvons utiliser la page Wikipédia d'Elizabeth I. Utilisez le chargeur LangChain pour obtenir et diviser des documents de Wikipédia, puis stockez-les dans la base de données Neo4j. Afin de tester l'effet en chinois, nous avons importé le graphe de connaissances médicales de ce projet (QASystemOnMedicalKG) sur Github, qui contient près de 35 000 nœuds et 300 000 ensembles de triplets. Nous avons obtenu grossièrement les résultats suivants :
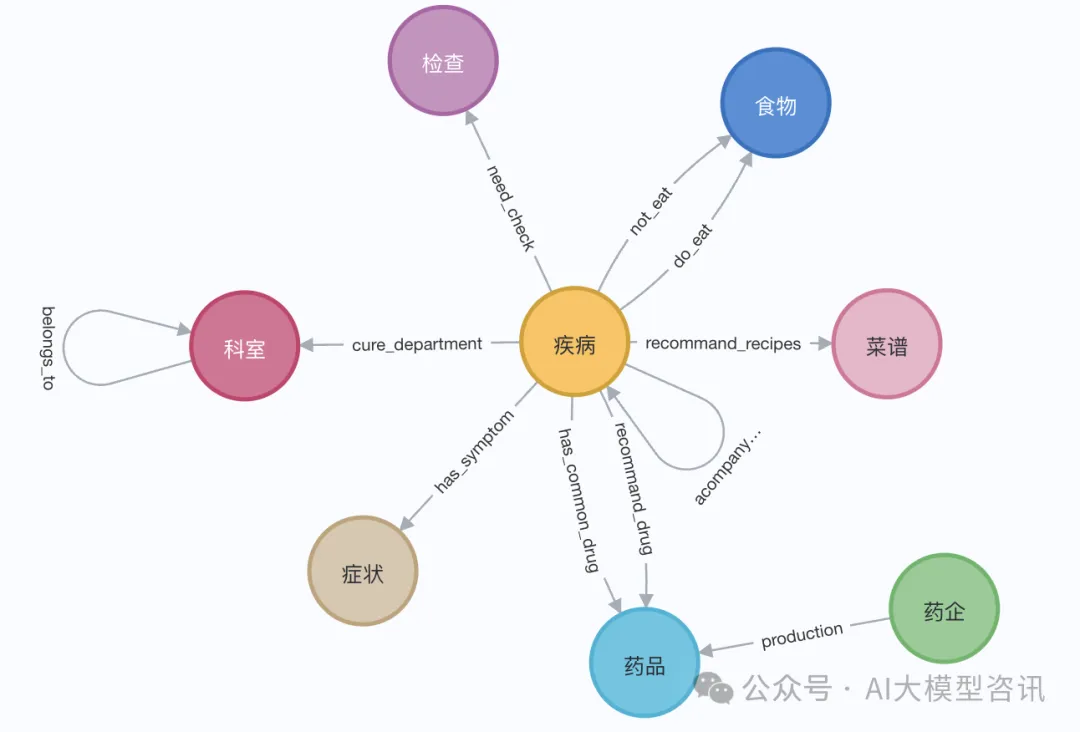 Pictures
Pictures
. Ou utilisez le chargeur LangChainLangChain pour obtenir et diviser des documents à partir de Wikipédia, à peu près comme indiqué dans les étapes suivantes :
# 读取维基百科文章raw_documents = WikipediaLoader(query="Elizabeth I").load()# 定义分块策略text_splitter = TokenTextSplitter(chunk_size=512, chunk_overlap=24)documents = text_splitter.split_documents(raw_documents[:3])llm=ChatOpenAI(temperature=0, model_name="gpt-4-0125-preview")llm_transformer = LLMGraphTransformer(llm=llm)# 提取图数据graph_documents = llm_transformer.convert_to_graph_documents(documents)# 存储到 neo4jgraph.add_graph_documents(graph_documents, baseEntityLabel=True, include_source=True)
Avant de récupérer le graphe de connaissances, les entités et les attributs associés doivent être intégrés et stockés de manière vectorielle. Dans la base de données Neo4j :
class GraphRag(object):def __init__(self):"""Any embedding function implementing `langchain.embeddings.base.Embeddings` interface."""self._database = 'neo4j'self.label = 'Med'self._driver = neo4j.GraphDatabase.driver(uri=os.environ["NEO4J_URI"],auth=(os.environ["NEO4J_USERNAME"],os.environ["NEO4J_PASSWORD"]))self.embeddings_zh = HuggingFaceEmbeddings(model_name=os.environ["EMBEDDING_MODEL"])self.vectstore = Neo4jVector(embedding=self.embeddings_zh, username=os.environ["NEO4J_USERNAME"], password=os.environ["NEO4J_PASSWORD"], url=os.environ["NEO4J_URI"], node_label=self.label, index_name="vector" )def query(self, query: str, params: dict = {}) -> List[Dict[str, Any]]:"""Query Neo4j database."""from neo4j.exceptions import CypherSyntaxErrorwith self._driver.session(database=self._database) as session:try:data = session.run(query, params)return [r.data() for r in data]except CypherSyntaxError as e:raise ValueError(f"Generated Cypher Statement is not valid\n{e}")def add_embeddings(self):"""Add embeddings to Neo4j database."""# 查询图中所有节点,并且根据节点的描述和名字生成embedding,添加到该节点上query = """MATCH (n) WHERE not (n:{}) RETURN ID(n) AS id, labels(n) as labels, n""".format(self.label)print("qurey node...")data = self.query(query)ids, texts, embeddings, metas = [], [], [], []for row in tqdm(data,desc="parsing node"):ids.append(row['id'])text = row['n'].get('name','') + row['n'].get('desc','')texts.append(text)metas.append({"label": row['labels'], "context": text})self.embeddings_zh.multi_process = Falseprint("node embeddings...")embeddings = self.embeddings_zh.embed_documents(texts)print("adding node embeddings...")ids_ret = self.vectstore.add_embeddings(ids=ids,texts=texts,embeddings=embeddings,metadatas=metas)return ids_ret# Fulltext index querydef structured_retriever(self, query, limit=3, simlarity=0.9) -> str:"""Collects the neighborhood of entities mentioned in the question"""# step1 从图谱中检索与查询相关的实体。docs_with_score = self.vectstore.similarity_search_with_score(query, k=topk)entities = [item[0].page_content for item in data if item[1] > simlarity] # scoreself.vectstore.query("CREATE FULLTEXT INDEX entity IF NOT EXISTS FOR (e:Med) ON EACH [e.context]")result = ""for entity in entities:qry = entity# step2 从全局索引中查出entity label,query1 =f"""CALL db.index.fulltext.queryNodes('entity', '{qry}') YIELD node, score return node.label as label,node.context as context, node.id as id, score LIMIT {limit}"""data1 = self.vectstore.query(query1)# step3 根据label在相应的节点中查询邻居节点路径for item in data1:node_type = item['label']node_type = item['label'] if type(node_type) == str else node_type[0]node_id = item['id']query2 = f"""match (node:{node_type})-[r]-(neighbor) where ID(node) = {node_id} RETURN type(r) as rel, node.name+' - '+type(r)+' - '+neighbor.name as output limit 50"""data2 = self.vectstore.query(query2)# step4 为了保持多样性,对关系进行筛选rel_dict = defaultdict(list)if len(data2) > 3*limit:for item1 in data2:rel_dict[item1['rel']].append(item1['output'])if rel_dict:rel_dict = {k:random.sample(v, 3) if len(v)>3 else v for k,v in rel_dict.items()}result += "\n".join(['\n'.join(el) for el in rel_dict.values()]) +'\n'else:result += "\n".join([el['output'] for el in data2]) +'\n'return result
Enfin, un grand modèle de langage (LLM) est utilisé pour générer la réponse finale basée sur les informations structurées extraites du graphe de connaissances. Dans le code suivant, nous prenons comme exemple le grand modèle de langage de Tongyi Qianwen open source :
from langchain import HuggingFacePipelinefrom transformers import pipeline, AutoTokenizer, AutoModelForCausalLMdef custom_model(model_name, branch_name=None, cache_dir=None, temperature=0, top_p=1, max_new_tokens=512, stream=False):tokenizer = AutoTokenizer.from_pretrained(model_name, revision=branch_name, cache_dir=cache_dir)model = AutoModelForCausalLM.from_pretrained(model_name,device_map='auto',torch_dtype=torch.float16,revision=branch_name,cache_dir=cache_dir)pipe = pipeline("text-generation",model = model,tokenizer = tokenizer,torch_dtype = torch.bfloat16,device_map = 'auto',max_new_tokens = max_new_tokens,do_sample = True)llm = HuggingFacePipeline(pipeline = pipe,model_kwargs = {"temperature":temperature, "top_p":top_p,"tokenizer":tokenizer, "model":model})return llmtongyi_model = "Qwen1.5-7B-Chat"llm_model = custom_model(model_name=tongyi_model)tokenizer = llm_model.model_kwargs['tokenizer']model = llm_model.model_kwargs['model']
final_data = self.get_retrieval_data(query)prompt = ("请结合以下信息,简洁和专业的来回答用户的问题,若信息与问题关联紧密,请尽量参考已知信息。\n""已知相关信息:\n{context} 请回答以下问题:{question}".format(cnotallow=final_data, questinotallow=query))messages = [{"role": "system", "content": "你是**开发的智能助手。"},{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(self.device)generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512)generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]print(response)
Une question de requête a été testée séparément. Par rapport à la situation où seul LLM est utilisé pour générer des réponses sans RAG, avec GraphRAG, le modèle LLM répond à une plus grande quantité d'informations et est plus précis.
Ce qui précède est le contenu détaillé de. pour plus d'informations, suivez d'autres articles connexes sur le site Web de PHP en chinois!
 Le but de memcpy en c
Le but de memcpy en c Sites Web d'analyse de données recommandés
Sites Web d'analyse de données recommandés Comment exécuter des tâches planifiées en Java
Comment exécuter des tâches planifiées en Java Comment résoudre l'erreur « NTLDR est manquant » sur votre ordinateur
Comment résoudre l'erreur « NTLDR est manquant » sur votre ordinateur La relation entre la bande passante et la vitesse du réseau
La relation entre la bande passante et la vitesse du réseau Comment utiliser le code source d'une page Web PHP
Comment utiliser le code source d'une page Web PHP Comment résoudre le problème de l'impossibilité de créer un nouveau dossier dans Win7
Comment résoudre le problème de l'impossibilité de créer un nouveau dossier dans Win7 Que faire si l'icône du bureau de l'ordinateur ne peut pas être ouverte
Que faire si l'icône du bureau de l'ordinateur ne peut pas être ouverte




















![[Web front-end] Démarrage rapide de Node.js](https://img.php.cn/upload/course/000/000/067/662b5d34ba7c0227.png)



